Spark是一個通用的大數據分析引擎,具有高性能、易用和普遍性等特點,可用于進行復雜的內存分析,構建大型、低延遲的數據分析應用。DataWorks為您提供EMR Spark節點,便于您在DataWorks上進行Spark任務的開發和周期性調度。本文為您介紹如何創建EMR Spark節點,并通過詳細的應用示例,為您介紹EMR Spark節點的功能。
前提條件
已注冊EMR集群至DataWorks。操作詳情請參見注冊EMR集群至DataWorks。
(可選,RAM賬號需要)進行任務開發的RAM賬號已被添加至對應工作空間中,并具有開發或空間管理員(權限較大,謹慎添加)角色權限,添加成員的操作詳情請參見為工作空間添加空間成員。
已購買資源組完成資源組配置。包括綁定工作空間、網絡配置等。詳情請參見新增和使用Serverless資源組。
已創建業務流程。數據開發(DataStudio)基于業務流程對不同開發引擎進行具體開發操作,所以您創建節點前需要先新建業務流程,操作詳情請參見創建業務流程。
如果您在開發任務時,需要特定的開發環境支持,可使用DataWorks提供的自定義鏡像功能,定制化構建任務執行所需的組件鏡像。更多信息,請參見鏡像管理。
使用限制
僅支持使用Serverless資源組(推薦)或獨享調度資源組運行該類型任務。
DataLake或自定義集群若要在DataWorks管理元數據,需先在集群側配置EMR-HOOK。若未配置,則無法在DataWorks中實時展示元數據、生成審計日志、展示血緣關系、開展EMR相關治理任務。配置EMR-HOOK,詳情請參見配置Spark SQL的EMR-HOOK。
EMR on ACK類型的Spark集群及EMR Serverless Spark集群不支持血緣。
EMR on ACK 類型的Spark集群及EMR Serverless Spark集群僅支持通過OSS REF的方式直接引用OSS資源、上傳資源到OSS,不支持上傳資源到HDFS。
DataLake集群、自定義集群支持通過OSS REF的方式直接引用OSS資源、上傳資源到OSS及上傳資源到HDFS。
準備工作:開發Spark任務并獲取JAR包
在使用DataWorks調度EMR Spark任務前,您需要先在EMR中開發Spark任務代碼并完成任務代碼的編譯,生成編譯后的任務JAR包,EMR Spark任務的開發指導詳情請參見Spark概述。
后續您需要將任務JAR包上傳至DataWorks,在DataWorks中周期性調度EMR Spark任務。
步驟一:創建EMR Spark節點
進入數據開發頁面。
登錄DataWorks控制臺,切換至目標地域后,單擊左側導航欄的,在下拉框中選擇對應工作空間后單擊進入數據開發。
新建EMR Spark節點。
右鍵單擊目標業務流程,選擇。
說明您也可以鼠標懸停至新建,選擇。
在新建節點對話框中,輸入名稱,并選擇引擎實例、節點類型及路徑。單擊確認,進入EMR Spark節點編輯頁面。
說明節點名稱支持大小寫字母、中文、數字、下劃線(_)和小數點(.)。
步驟二:開發Spark任務
在EMR Spark節點編輯頁面雙擊已創建的節點,進入任務開發頁面,您可以根據不同場景需求選擇適合您的操作方案:
(推薦)先從本地上傳資源至DataStudio,再引用資源。詳情請參見方案一:先上傳資源后引用EMR JAR資源。
使用OSS REF方式引用OSS資源,詳情請參見方案二:直接引用OSS資源。
方案一:先上傳資源后引用EMR JAR資源
DataWorks也支持您從本地先上傳資源至DataStudio,再引用資源。EMR Spark任務編譯完成后,您需獲取編譯后的JAR包,建議根據JAR包大小選擇不同方式存儲JAR包資源。
上傳JAR包資源,創建為DataWorks的EMR資源并提交,或直接存儲在EMR的HDFS存儲中(EMR on ACK 類型的Spark集群及EMR Serverless Spark集群不支持上傳資源到HDFS)。
JAR包小于200MB時
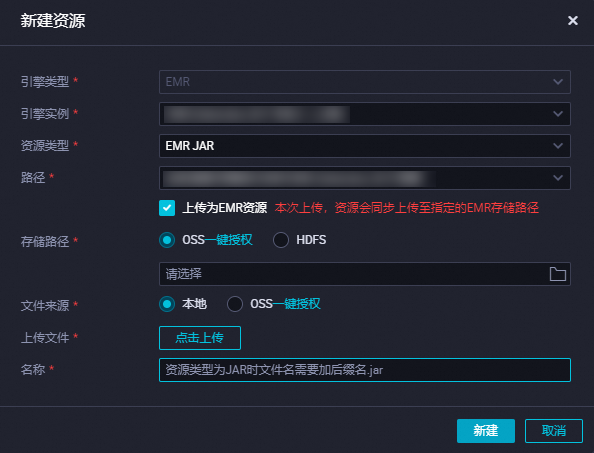
創建EMR JAR資源。
JAR包小于200MB時,可將JAR包通過本地上傳的方式上傳為DataWorks的EMR JAR資源,便于后續在DataWorks控制臺進行可視化管理,創建完成資源后需進行提交,操作詳情請參見創建和使用EMR資源。
 說明
說明首次創建EMR資源時,如果您希望JAR包上傳后存儲在OSS中,您需要先參考界面提示進行授權操作。
引用EMR JAR資源。
雙擊創建的EMR Spark節點,打開EMR Spark 節點的代碼編輯頁面。
在節點下,找到上述步驟中已上傳的EMR JAR資源,右鍵選擇引用資源。
選擇引用資源后,當前打開的EMR Spark節點的編輯頁面會自動添加資源引用代碼,引用代碼示例如下。
##@resource_reference{"spark-examples_2.12-1.0.0-SNAPSHOT-shaded.jar"} spark-examples_2.12-1.0.0-SNAPSHOT-shaded.jar如果成功自動添加上述引用代碼,表明資源引用成功。其中,spark-examples_2.12-1.0.0-SNAPSHOT-shaded.jar為您實際上傳的EMR JAR資源名稱。
改寫EMR Spark節點代碼,補充spark submit命令,改寫后的示例如下。
說明EMR Spark節點編輯代碼時不支持注釋語句,請務必參考如下示例改寫任務代碼,不要隨意添加注釋,否則后續運行節點時會報錯。
##@resource_reference{"spark-examples_2.11-2.4.0.jar"} spark-submit --class org.apache.spark.examples.SparkPi --master yarn spark-examples_2.11-2.4.0.jar 100其中:
org.apache.spark.examples.SparkPi:為您實際編譯的JAR包中的任務主Class。
spark-examples_2.11-2.4.0.jar:為您實際上傳的EMR JAR資源名稱。
其他參數可參考以上示例不做修改,您也可執行以下命令查看
spark submit的使用幫助,根據需要修改spark submit命令。說明若您需要在Spark節點中使用
spark submit命令簡化的參數,您需要在代碼中自行添加,例如,--executor-memory 2G。Spark節點僅支持使用Yarn的Cluster提交作業。
spark submit方式提交的任務,deploy-mode推薦使用cluster模式,不建議使用client模式。
spark-submit --help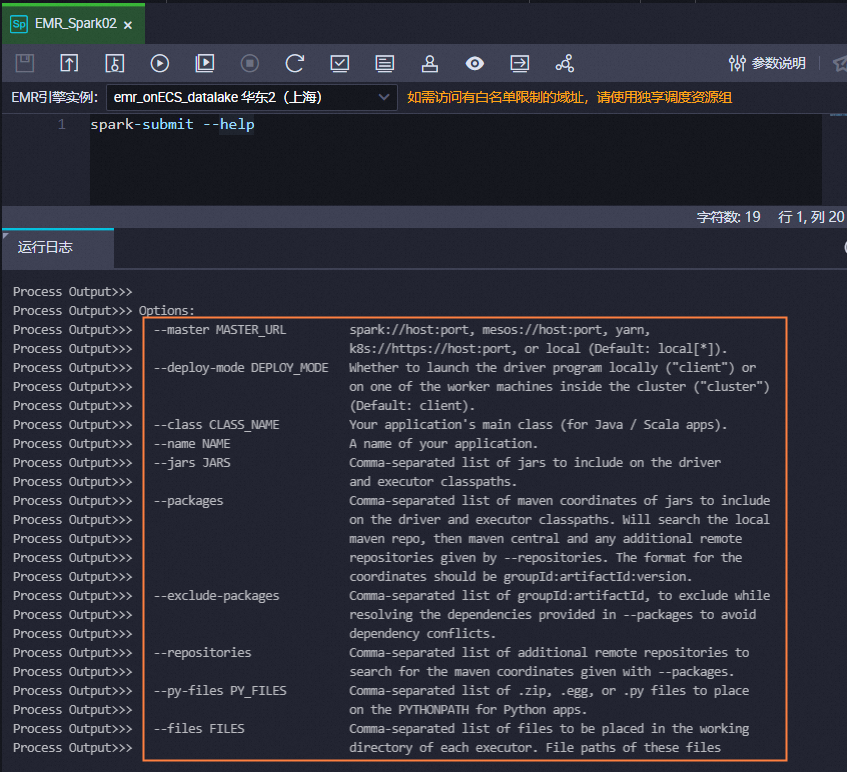
JAR包大于等于200MB時
創建EMR JAR資源。
JAR包大于等于200MB時,無法通過本地上傳的方式直接上傳為DataWorks的資源,建議直接將JAR包存儲在EMR的HDFS中,并記錄下JAR包的存儲路徑,以便后續在DataWorks調度Spark任務時引用該路徑。
引用EMR JAR資源。
JAR包存儲在HDFS時,您可以直接在EMR Spark節點中通過代碼指定JAR包路徑的方式引用JAR包。
雙擊創建的EMR Spark節點,打開EMR Spark 節點的代碼編輯頁面。
編寫spark submit命令,示例如下。
spark-submit --master yarn --deploy-mode cluster --name SparkPi --driver-memory 4G --driver-cores 1 --num-executors 5 --executor-memory 4G --executor-cores 1 --class org.apache.spark.examples.JavaSparkPi hdfs:///tmp/jars/spark-examples_2.11-2.4.8.jar 100其中:
hdfs:///tmp/jars/spark-examples_2.11-2.4.8.jar:為JAR包實際在HDFS中的路徑。
org.apache.spark.examples.JavaSparkPi:為您實際編譯的JAR包中的任務主class。
其他參數為實際EMR集群的參數,需根據實際情況進行修改配置。您也可以執行以下命令查看spark submit的使用幫助,根據需要修改spark submit命令。
重要若您需要在Spark節點中使用Spark-submit命令簡化的參數,您需要在代碼中自行添加,例如,
--executor-memory 2G。Spark節點僅支持使用Yarn的Cluster提交作業。
spark-submit方式提交的任務,deploy-mode推薦使用cluster模式,不建議使用client模式。
spark-submit --help
方案二:直接引用OSS資源
當前節點可直接通過OSS REF的方式引用OSS資源,在運行EMR節點時,DataWorks會自動加載代碼中的OSS資源至本地使用。該方式常用于“需要在EMR任務中運行JAR依賴”、“EMR任務需依賴腳本”等場景。
開發JAR資源。
代碼依賴準備。
您可前往EMR集群,在集群master節點的
/usr/lib/emr/spark-current/jars/路徑下查看您所需的代碼依賴。下面以Spark3.4.2版本為例,您需在打開已創建的IDEA項目添加pom依賴并引用相關插件。添加pom依賴
<dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>3.4.2</version> </dependency> <!-- Apache Spark SQL --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.12</artifactId> <version>3.4.2</version> </dependency> </dependencies>引用相關插件
<build> <sourceDirectory>src/main/scala</sourceDirectory> <testSourceDirectory>src/test/scala</testSourceDirectory> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.2</version> <configuration> <recompileMode>incremental</recompileMode> </configuration> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> <configuration> <args> <arg>-dependencyfile</arg> <arg>${project.build.directory}/.scala_dependencies</arg> </args> </configuration> </execution> </executions> </plugin> </plugins> </build>編寫代碼示例。
package com.aliyun.emr.example.spark import org.apache.spark.sql.SparkSession object SparkMaxComputeDemo { def main(args: Array[String]): Unit = { // 創建 SparkSession val spark = SparkSession.builder() .appName("HelloDataWorks") .getOrCreate() // 打印Spark版本 println(s"Spark version: ${spark.version}") } }將代碼打包成JAR文件。
編輯保存Scala代碼后,將Scala代碼打包成JAR文件。示例生成的JAR包為
SparkWorkOSS-1.0-SNAPSHOT-jar-with-dependencies.jar。
上傳JAR資源。
完成代碼開發后,您需登錄OSS管理控制臺,單擊所在地域左側導航欄的Bucket列表。
單擊目標Bucket名稱,進入文件管理頁面。
本文示例使用的Bucket為
onaliyun-bucket-2。單擊新建目錄,創建JAR資源的存放目錄。
配置目錄名為
emr/jars,創建JAR資源的存放目錄。上傳JAR資源至JAR資源的存放目錄。
進入存放目錄,單擊上傳文件,在待上傳文件區域單擊掃描文件,添加
SparkWorkOSS-1.0-SNAPSHOT-jar-with-dependencies.jar文件至Bucket,單擊上傳文件。
引用JAR資源。
編輯引用JAR資源代碼。
在已創建的EMR Spark節點編輯頁面,編輯引用JAR資源代碼。
spark-submit --class com.aliyun.emr.example.spark.SparkMaxComputeDemo --master yarn ossref://onaliyun-bucket-2/emr/jars/SparkWorkOSS-1.0-SNAPSHOT-jar-with-dependencies.jar引用參數說明:
參數
參數說明
class運行的主類全名稱。
masterSpark應用程序的運行模式。
ossref文件路徑格式為
ossref://{endpoint}/{bucket}/{object}endpoint:OSS對外服務的訪問域名。Endpoint為空時,僅支持使用與當前訪問的EMR集群同地域的OSS,即OSS的Bucket需要與EMR集群所在地域相同。
Bucket:OSS用于存儲對象的容器,每一個Bucket有唯一的名稱,登錄OSS管理控制臺,可查看當前登錄賬號下所有Bucket。
object:存儲在Bucket中的一個具體的對象(文件名稱或路徑)。
運行EMR Spark節點任務。
編輯完成后您可單擊
 圖標,選擇您所創建的Serverless資源組運行EMR Spark節點。待任務執行完成后,記錄控制臺打印的
圖標,選擇您所創建的Serverless資源組運行EMR Spark節點。待任務執行完成后,記錄控制臺打印的applicationIds,例如application_1730367929285_xxxx。結果查看。
創建EMR Shell節點并在EMR Shell節點執行
yarn logs -applicationId application_1730367929285_xxxx命令查看運行結果:
(可選)配置高級參數
您可在節點高級設置處配置Spark特有屬性參數。更多Spark屬性參數設置,請參考Spark Configuration。不同類型EMR集群可配置的高級參數存在部分差異,具體如下表。
DataLake集群/自定義集群:EMR on ECS
高級參數 | 配置說明 |
queue | 提交作業的調度隊列,默認為default隊列。 如果您在注冊EMR集群至DataWorks工作空間時,配置了工作空間級的YARN資源隊列:
關于EMR YARN說明,詳情請參見隊列基礎配置,注冊EMR集群時的隊列配置詳情請參見設置全局YARN資源隊列。 |
priority | 優先級,默認為1。 |
FLOW_SKIP_SQL_ANALYZE | SQL語句執行方式。取值如下:
說明 該參數僅支持用于數據開發環境測試運行流程。 |
USE_GATEWAY | 不支持。 |
其他 |
|
Hadoop集群:EMR on ECS
高級參數 | 配置說明 |
queue | 提交作業的調度隊列,默認為default隊列。 如果您在注冊EMR集群至DataWorks工作空間時,配置了工作空間級的YARN資源隊列:
關于EMR YARN說明,詳情請參見隊列基礎配置,注冊EMR集群時的隊列配置詳情請參見設置全局YARN資源隊列。 |
priority | 優先級,默認為1。 |
FLOW_SKIP_SQL_ANALYZE | SQL語句執行方式。取值如下:
說明 該參數僅支持用于數據開發環境測試運行流程。 |
USE_GATEWAY | 設置本節點提交作業時,是否通過Gateway集群提交。取值如下:
說明 如果本節點所在的集群未關聯Gateway集群,此處手動設置參數取值為 |
其他 |
|
Spark集群:EMR ON ACK
高級參數 | 配置說明 |
queue | 不支持。 |
priority | 不支持。 |
FLOW_SKIP_SQL_ANALYZE | SQL語句執行方式。取值如下:
說明 該參數僅支持用于數據開發環境測試運行流程。 |
USE_GATEWAY | 不支持。 |
其他 |
|
EMR Serverless Spark集群
相關參數設置請參見提交Spark任務參數設置。
高級參數 | 配置說明 |
queue | 提交作業的調度隊列,默認為dev_queue隊列。 |
priority | 優先級,默認為1。 |
FLOW_SKIP_SQL_ANALYZE | SQL語句執行方式。取值如下:
說明 該參數僅支持用于數據開發環境測試運行流程。 |
USE_GATEWAY | 不支持。 |
SERVERLESS_RELEASE_VERSION | Spark引擎版本,默認使用管理中心的集群管理中集群配置的默認引擎版本。如需為不同任務設置不同的引擎版本,您可在此進行設置。 |
SERVERLESS_QUEUE_NAME | 指定資源隊列,默認使用管理中心的集群管理中集群配置的默認資源隊列。如有資源隔離和管理需求,可通過添加隊列實現。詳情請參見管理資源隊列。 |
其他 |
|
執行SQL任務
步驟三:配置節點調度
如您需要周期性執行創建的節點任務,可單擊節點編輯頁面右側的調度配置,根據業務需求配置該節點任務的調度信息。配置詳情請參見任務調度屬性配置概述。
您需要設置節點的重跑屬性和依賴的上游節點,才可以提交節點。
步驟四:發布節點任務
節點任務配置完成后,需執行提交發布操作,提交發布后節點即會根據調度配置內容進行周期性運行。
單擊工具欄中的
 圖標,保存節點。
圖標,保存節點。單擊工具欄中的
 圖標,提交節點任務。
圖標,提交節點任務。提交時需在提交對話框中輸入變更描述,并根據需要選擇是否在節點提交后執行代碼評審。
說明您需設置節點的重跑屬性和依賴的上游節點,才可提交節點。
代碼評審可對任務的代碼質量進行把控,防止由于任務代碼有誤,未經審核直接發布上線后出現任務報錯。如進行代碼評審,則提交的節點代碼必須通過評審人員的審核才可發布,詳情請參見代碼評審。
如您使用的是標準模式的工作空間,任務提交成功后,需單擊節點編輯頁面右上方的發布,將該任務發布至生產環境執行,操作請參見發布任務。
后續步驟
任務提交發布后,會基于節點的配置周期性運行,您可單擊節點編輯界面右上角的運維,進入運維中心查看周期任務的調度運行情況。詳情請參見查看并管理周期任務。