概述
Spark on MaxCompute是MaxCompute提供的兼容開源Spark的計算服務(wù)。它在統(tǒng)一的計算資源和數(shù)據(jù)集權(quán)限體系之上,提供Spark計算框架,支持您以熟悉的開發(fā)使用方式提交運行Spark作業(yè),滿足更豐富的數(shù)據(jù)處理分析需求。
使用限制
Spark on MaxCompute支持如下場景:
離線計算場景,例如GraphX、Mllib、RDD、Spark-SQL、PySpark等。
讀寫MaxCompute Table。
引用MaxCompute中的文件資源。
讀寫VPC環(huán)境下的服務(wù)。例如,RDS、Redis、HBase、ECS上部署的服務(wù)等。
讀寫OSS非結(jié)構(gòu)化存儲。
讀OSS、Hologres以及HBase外部表。
Spark on MaxCompute暫不支持如下場景:
交互式和流計算類需求,例如Spark-Shell、Spark-SQL-Shell、PySpark-Shell、Spark Streaming等。
不支持訪問MaxCompute除OSS、Hologres以及HBase外部表之外的外部表、內(nèi)建函數(shù)和自定義函數(shù)(MaxCompute UDF)。
不支持在使用按量計費開發(fā)者版資源的項目中執(zhí)行Spark作業(yè)。按量計費開發(fā)者版僅支持MaxCompute SQL(支持使用UDF)、PyODPS作業(yè)。
不支持Checkpoint功能。
關(guān)鍵特性
支持原生多版本Spark作業(yè)。
MaxCompute支持社區(qū)原生Spark、完全兼容Spark的API,同時支持多個Spark版本同時運行。Spark on MaxCompute提供原生的Spark WebUI供您查看。
統(tǒng)一的計算資源。
Spark on MaxCompute類似MaxCompute SQL、MapReduce等作業(yè)類型,運行在MaxCompute項目統(tǒng)一開通的計算資源中。
統(tǒng)一的數(shù)據(jù)和權(quán)限管理。
完全遵循MaxCompute項目的權(quán)限體系,在訪問用戶權(quán)限范圍內(nèi)安全地查詢數(shù)據(jù)。
與開源系統(tǒng)相同的使用體驗。
Spark on MaxCompute與社區(qū)開源Spark保持相同的體驗(例如開源應(yīng)用的UI界面、在線交互等),完全符合Spark用戶使用習慣。開源應(yīng)用的調(diào)試過程中需要使用開源UI,Spark on MaxCompute提供原生的開源實時UI和查詢歷史日志的功能。其中,對于部分開源應(yīng)用還支持交互式體驗,在后臺引擎運行后即可進行實時交互。
系統(tǒng)結(jié)構(gòu)
Spark on MaxCompute是阿里云通過Spark on MaxCompute的解決方案,讓原生Spark能夠在MaxCompute中運行。
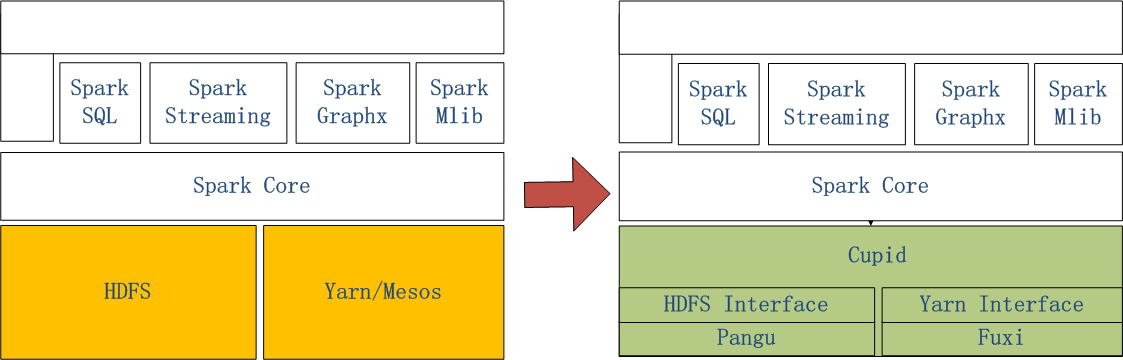
左側(cè)是原生Spark的架構(gòu)圖,右側(cè)的Spark on MaxCompute運行在阿里云自研的Cupid平臺之上,該平臺可以原生支持開源社區(qū)Yarn所支持的計算框架。