基于Lindorm計(jì)算引擎進(jìn)行任務(wù)開發(fā)
Lindorm計(jì)算引擎兼容CDH(Cloudera's Distribution Including Apache Hadoop)。您可在DataWorks上通過注冊(cè)CDH集群并配置Lindorm計(jì)算引擎連接信息的方式,在DataWorks上基于Lindorm計(jì)算引擎進(jìn)行交互式SQL查詢、SQL任務(wù)開發(fā)、JAR任務(wù)執(zhí)行等。本文為您介紹如何在DataWorks通過注冊(cè)CDH集群來訪問Lindorm計(jì)算引擎,并基于Lindorm計(jì)算引擎進(jìn)行各類任務(wù)的開發(fā)、調(diào)度及運(yùn)維。
背景信息
Lindorm計(jì)算引擎是基于云原生架構(gòu)的分布式計(jì)算服務(wù),支持社區(qū)版計(jì)算模型、兼容Spark接口、深度融合Lindorm存儲(chǔ)引擎特性;能夠利用底層數(shù)據(jù)存儲(chǔ)特征及索引能力,高效地完成分布式作業(yè)任務(wù);可用于海量數(shù)據(jù)生產(chǎn)、交互式分析、計(jì)算學(xué)習(xí)和圖計(jì)算等場(chǎng)景。
前提條件
在DataWorks基于Lindorm計(jì)算引擎進(jìn)行任務(wù)開發(fā)前,您需完成以下操作:
已創(chuàng)建Lindorm實(shí)例并開通Lindorm計(jì)算引擎。DataWorks需基于該引擎執(zhí)行相關(guān)任務(wù)開發(fā)操作。詳情請(qǐng)參見開通計(jì)算引擎。
已創(chuàng)建CDH集群并注冊(cè)至DataWorks。DataWorks通過注冊(cè)CDH集群的方式,訪問Lindorm計(jì)算引擎數(shù)據(jù)。詳情請(qǐng)參見注冊(cè)CDH或CDP集群至DataWorks。
注冊(cè)CDH集群時(shí),集群連接信息需要配置為L(zhǎng)indorm計(jì)算引擎的鏈接信息,且集群版本選擇為6.3.2版本,您只需正確填寫HiveServer2以及Metastore的配置信息即可,其他配置可以留空。
 說明
說明若您希望將作業(yè)提交至特定的Lindorm資源組,可執(zhí)行如下操作:
在登錄Lindorm管理控制臺(tái)。創(chuàng)建ETL資源組(名稱例如:mycomputegroup)。操作詳情請(qǐng)參見創(chuàng)建和管理資源組。
在DataWorks注冊(cè)計(jì)算引擎時(shí),
JDBC地址(即HiveServer2參數(shù)的輸入內(nèi)容)后需添加參數(shù)compute-group=<compute_group_name>。例如,jdbc:hive2://ld-abcd123xyz-proxy-ldps.lindorm.aliyuncs.com:10009/;?token=aaaa-bbb-ccc-ddd;compute-group=mycomputegroup。
已創(chuàng)建業(yè)務(wù)流程。DataWorks的數(shù)據(jù)開發(fā)(DataStudio)基于業(yè)務(wù)流程執(zhí)行不同引擎的具體開發(fā)操作,您可在業(yè)務(wù)流程中按需編排任務(wù)流,以直觀查看任務(wù)間的依賴關(guān)系。詳情請(qǐng)參見創(chuàng)建業(yè)務(wù)流程。
步驟一:開發(fā)Lindorm計(jì)算引擎任務(wù)
本文為您介紹使用SQL方式及JAR方式進(jìn)行任務(wù)開發(fā)。
SQL方式(單擊即可展開查看詳情)
編排任務(wù)流
雙擊已創(chuàng)建的業(yè)務(wù)流程,將所需節(jié)點(diǎn)拖拽至業(yè)務(wù)流程面板,配置節(jié)點(diǎn)基礎(chǔ)信息并通過連線方式規(guī)劃節(jié)點(diǎn)的上下游依賴。本文示例編排的任務(wù)流如下。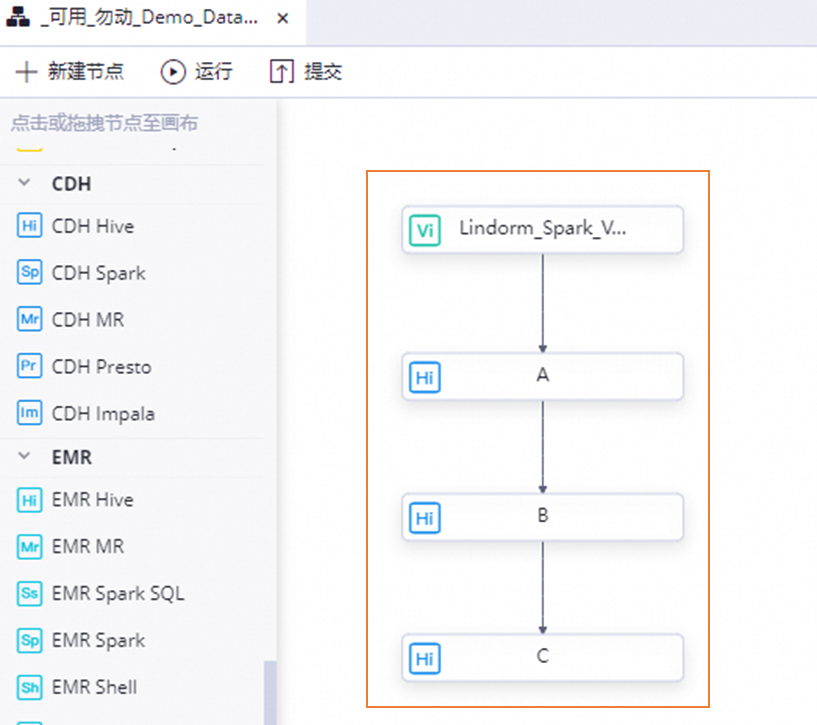
虛擬節(jié)點(diǎn)(Vi):作為業(yè)務(wù)流程中任務(wù)的起始節(jié)點(diǎn),統(tǒng)一調(diào)起業(yè)務(wù)流程中的任務(wù)。
CDH Hive節(jié)點(diǎn):本文用于基于Lindorm計(jì)算引擎執(zhí)行SQL任務(wù)。
編寫任務(wù)代碼
示例在CDH Hive節(jié)點(diǎn)使用Spark SQL語法開發(fā)SQL作業(yè)。
支持Serverless資源組(推薦)或舊版獨(dú)享調(diào)度資源組運(yùn)行CDH Hive任務(wù)。
雙擊業(yè)務(wù)流程中的CDH Hive節(jié)點(diǎn),進(jìn)入節(jié)點(diǎn)編輯頁面。
本文需依次單擊創(chuàng)建的A、B、C三個(gè)節(jié)點(diǎn),配置節(jié)點(diǎn)任務(wù)。
(可選)配置引擎參數(shù)。
Lindorm計(jì)算引擎支持自定義常用的Spark配置項(xiàng),包括資源配置項(xiàng)、執(zhí)行配置項(xiàng)和監(jiān)控配置項(xiàng)。例如,
SET spark.executor.cores=2;,您可根據(jù)業(yè)務(wù)需要配置相關(guān)參數(shù)。詳細(xì)參數(shù)介紹,請(qǐng)參見作業(yè)配置說明。說明引擎參數(shù)配置語句必須寫在SQL任務(wù)語句之前。
編寫任務(wù)代碼。
開發(fā)SQL代碼:簡(jiǎn)單示例
在CDH Hive節(jié)點(diǎn)的SQL編輯區(qū)域輸入任務(wù)代碼,示例如下。更多Lindorm支持的SQL語法,請(qǐng)參見Spark SQL。
CREATE TABLE test ( id INT ,name STRING ); INSERT INTO test VALUES (1,'jack'); SELECT * from test;開發(fā)SQL代碼:使用調(diào)度參數(shù)示例
DataWorks提供調(diào)度參數(shù),可實(shí)現(xiàn)調(diào)度場(chǎng)景下代碼動(dòng)態(tài)入?yún)ⅲ稍诠?jié)點(diǎn)中通過
${變量名}的方式定義代碼中的變量,并在調(diào)度配置>參數(shù)處,為該變量賦值。調(diào)度參數(shù)支持的格式,詳情請(qǐng)參見調(diào)度參數(shù)支持的格式。
更多Lindorm支持的SQL語法,請(qǐng)參見Spark SQL。
select '${var}'; --可以結(jié)合調(diào)度參數(shù)使用。本文任務(wù)示例代碼
節(jié)點(diǎn)A的任務(wù)代碼如下。
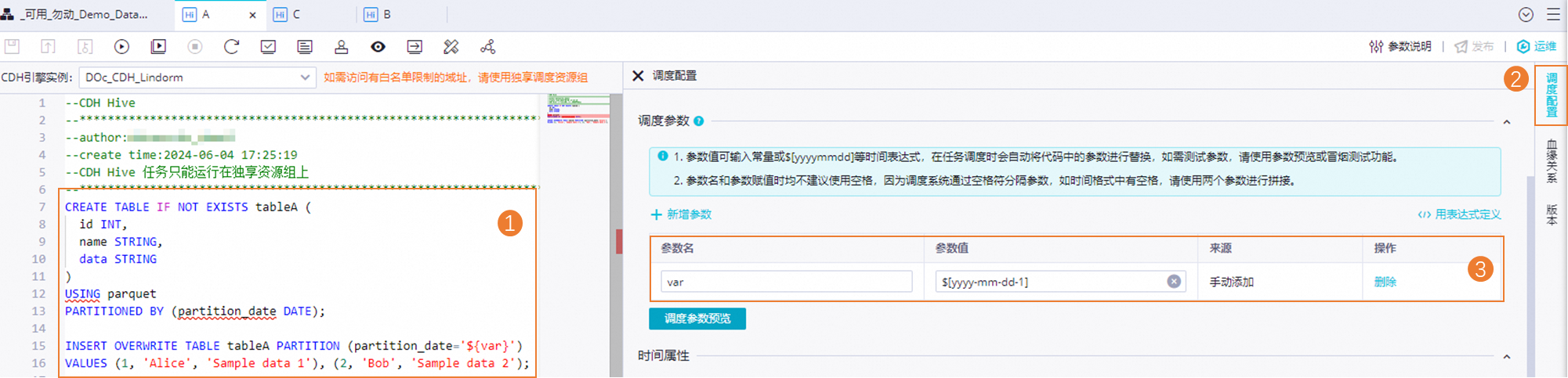
CREATE TABLE IF NOT EXISTS tableA ( id INT, name STRING, data STRING ) USING parquet PARTITIONED BY (partition_date DATE); INSERT OVERWRITE TABLE tableA PARTITION (partition_date='${var}') VALUES (1, 'Alice', 'Sample data 1'), (2, 'Bob', 'Sample data 2');節(jié)點(diǎn)B的任務(wù)代碼如下。
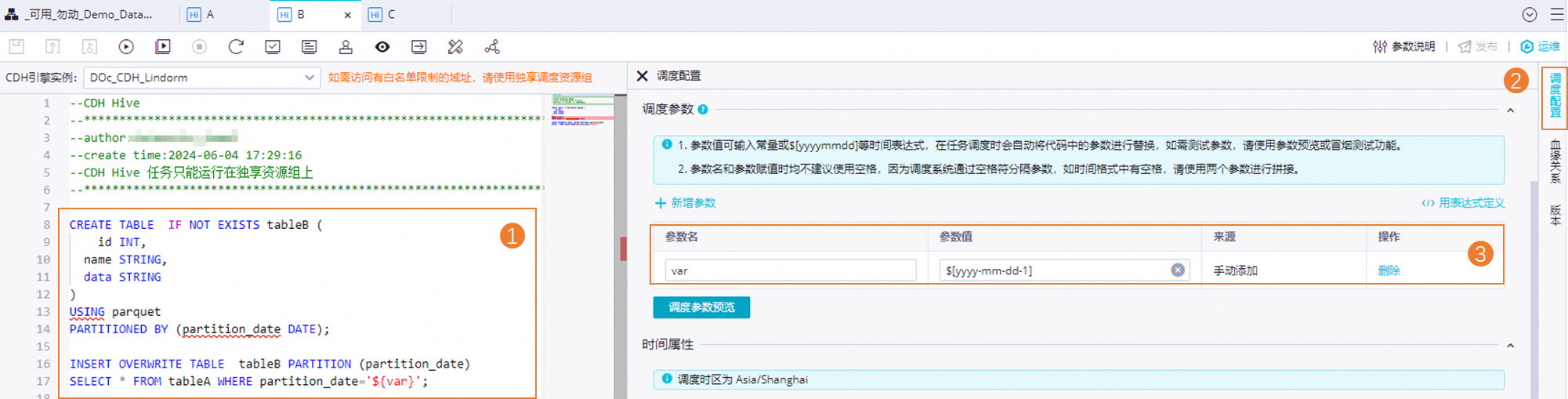
CREATE TABLE IF NOT EXISTS tableB ( id INT, name STRING, data STRING ) USING parquet PARTITIONED BY (partition_date DATE); INSERT OVERWRITE TABLE tableB PARTITION (partition_date) SELECT * FROM tableA WHERE partition_date='${var}';節(jié)點(diǎn)C的任務(wù)代碼如下。
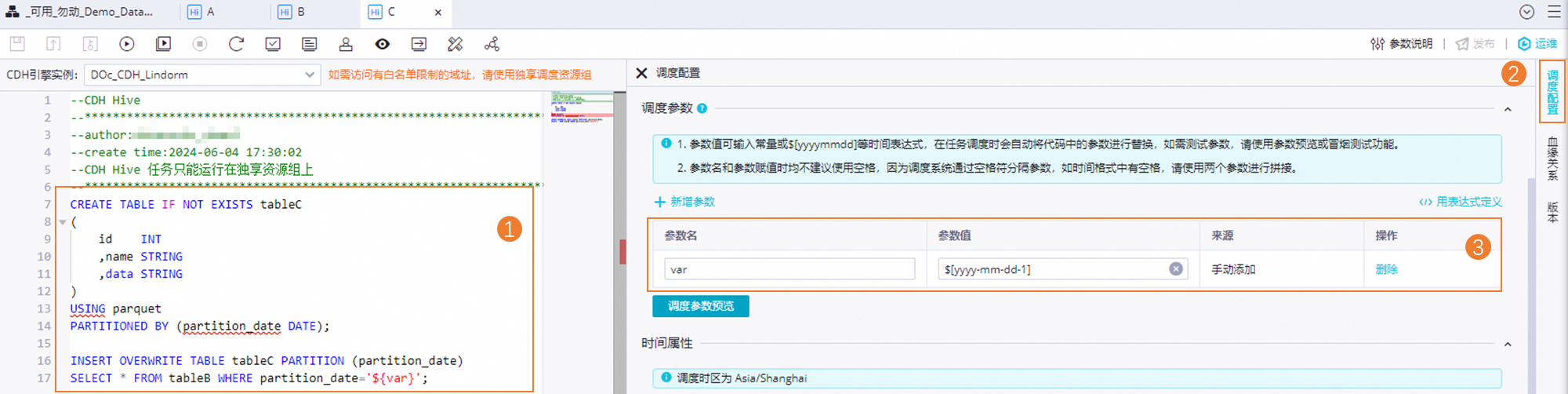
CREATE TABLE IF NOT EXISTS tableC ( id INT ,name STRING ,data STRING ) USING parquet PARTITIONED BY (partition_date DATE); INSERT OVERWRITE TABLE tableC PARTITION (partition_date) SELECT * FROM tableB WHERE partition_date='${var}';
JAR方式(單擊即可展開查看詳情)
示例在DataWorks Shell節(jié)點(diǎn)內(nèi)通過Curl的方式將JAR作業(yè)提交至Lindorm Spark計(jì)算引擎上執(zhí)行。
JAR作業(yè)模板
# 在Lindorm服務(wù)上提交一個(gè)作業(yè)。
curl --location --request POST 'http://ld-uf6y6d74hooeb****-proxy-ldps.lindorm.aliyuncs.com:10099/api/v1/lindorm/jobs/xxxxxx' --header 'Content-Type:application/json' --data '{
"owner":"root",
"name":"LindormSQL",
"mainResourceKind":"jar",
"mainClass":"your_project_main_class",
"mainResource":"hdfs:///ldps-user-resource/ldps-ldps-lindorm-spark-examples-1.0-SNAPSHOT.jar",
"mainArgs":[],
"conf":{
}
}' 核心參數(shù)說明如下。
參數(shù) | 描述 |
URL | 計(jì)算引擎的JAR地址。可進(jìn)入Lindorm管理控制臺(tái)獲取,詳情請(qǐng)參見查看連接地址。 示例格式為:
|
mainClass | JAR作業(yè)的程序入口類。 |
mainResource | JAR包存儲(chǔ)在HDFS的路徑。 |
mainArgs | 傳入mainClass參數(shù)。 |
conf | Spark系統(tǒng)參數(shù)配置。詳情請(qǐng)參見作業(yè)配置說明。 |
JAR作業(yè)示例
開發(fā)JAR作業(yè)。
您可參考JAR作業(yè)開發(fā)實(shí)踐進(jìn)行JAR作業(yè)開發(fā)。同時(shí),平臺(tái)也為您提供了已打包好的JAR作業(yè)ldps-lindorm-spark-examples-1.0-SNAPSHOT.jar,您可直接獲取進(jìn)行任務(wù)測(cè)試。
上傳JAR包至HDFS。
進(jìn)入Lindorm控制臺(tái),將上述JAR包上傳至HDFS,詳情請(qǐng)參見通過控制臺(tái)上傳文件。
在DataWorks提交及查看作業(yè)。
創(chuàng)建Shell節(jié)點(diǎn)。
右鍵單擊創(chuàng)建的業(yè)務(wù)流程,選擇,配置節(jié)點(diǎn)名稱,單擊確認(rèn)。
在節(jié)點(diǎn)編輯頁面編寫任務(wù)代碼。
通過Curl提交作業(yè)。示例代碼如下。
curl --location --request POST http://ld-bp19xymdrwxxxxx-proxy-ldps-pub.lindorm.aliyuncs.com:10099/api/v1/lindorm/jobs/xxxx --header "Content-Type:application/json" --data '{ "owner":"root", "name":"LindormSQL", "mainResourceKind":"jar", "mainClass":"com.aliyun.lindorm.ldspark.examples.SimpleWordCount", "mainResource":"hdfs:///ldps-user-resource/ldps-lindorm-spark-examples-1.0-SNAPSHOT.jar", "mainArgs":[], "conf":{ } }'查看作業(yè)信息。示例代碼如下。
curl --request GET 'http://ld-bp19xymdrwxxxxx-proxy-ldps-pub.lindorm.aliyuncs.com:10099/api/v1/lindorm/jobs/xxxx'
步驟二:配置任務(wù)調(diào)度
如您需周期性執(zhí)行創(chuàng)建的節(jié)點(diǎn)任務(wù),可單擊節(jié)點(diǎn)編輯頁面右側(cè)的調(diào)度配置,根據(jù)業(yè)務(wù)需求配置該節(jié)點(diǎn)任務(wù)的調(diào)度信息。詳情請(qǐng)參見任務(wù)調(diào)度屬性配置概述。
您需要設(shè)置節(jié)點(diǎn)的重跑屬性和依賴的上游節(jié)點(diǎn),才可提交節(jié)點(diǎn)。
步驟三:調(diào)試任務(wù)代碼
根據(jù)需要執(zhí)行如下操作,查看任務(wù)是否符合預(yù)期。
您也可在業(yè)務(wù)流程面板,單擊![]() 圖標(biāo),調(diào)試整個(gè)業(yè)務(wù)流任務(wù)。
圖標(biāo),調(diào)試整個(gè)業(yè)務(wù)流任務(wù)。
(可選)選擇運(yùn)行資源組、賦值自定義參數(shù)取值。
單擊工具欄的
 圖標(biāo),在參數(shù)對(duì)話框選擇調(diào)試運(yùn)行需使用的調(diào)度資源組。
圖標(biāo),在參數(shù)對(duì)話框選擇調(diào)試運(yùn)行需使用的調(diào)度資源組。如您的任務(wù)代碼中有使用調(diào)度參數(shù)變量,可在此處為變量賦值,用于調(diào)試。參數(shù)賦值邏輯,詳情請(qǐng)參見任務(wù)調(diào)試流程。
保存并運(yùn)行任務(wù)代碼。
單擊工具欄的
 圖標(biāo),保存編寫的任務(wù)代碼,單擊
圖標(biāo),保存編寫的任務(wù)代碼,單擊 圖標(biāo),運(yùn)行創(chuàng)建的任務(wù)。
圖標(biāo),運(yùn)行創(chuàng)建的任務(wù)。(可選)冒煙測(cè)試。
如您希望在開發(fā)環(huán)境進(jìn)行冒煙測(cè)試,查看調(diào)度節(jié)點(diǎn)任務(wù)的執(zhí)行是否符合預(yù)期,則可在節(jié)點(diǎn)提交時(shí),或節(jié)點(diǎn)提交后執(zhí)行冒煙測(cè)試,操作詳情請(qǐng)參見執(zhí)行冒煙測(cè)試。
步驟四:提交發(fā)布任務(wù)
節(jié)點(diǎn)任務(wù)配置完成后,需執(zhí)行提交發(fā)布操作,提交發(fā)布后,節(jié)點(diǎn)會(huì)根據(jù)調(diào)度配置內(nèi)容進(jìn)行周期性運(yùn)行。
您也可在業(yè)務(wù)流程面板,單擊![]() 圖標(biāo),提交整個(gè)業(yè)務(wù)流任務(wù)。
圖標(biāo),提交整個(gè)業(yè)務(wù)流任務(wù)。
單擊工具欄中的
圖標(biāo),保存節(jié)點(diǎn)。單擊工具欄中的
 圖標(biāo),提交節(jié)點(diǎn)任務(wù)。
圖標(biāo),提交節(jié)點(diǎn)任務(wù)。提交時(shí)需在提交對(duì)話框中輸入變更描述,并根據(jù)需要選擇是否在節(jié)點(diǎn)提交后執(zhí)行代碼評(píng)審。
說明您需設(shè)置節(jié)點(diǎn)的重跑屬性和依賴的上游節(jié)點(diǎn),才可提交節(jié)點(diǎn)。
代碼評(píng)審可對(duì)任務(wù)的代碼質(zhì)量進(jìn)行把控,防止由于任務(wù)代碼有誤,未經(jīng)審核直接發(fā)布上線后出現(xiàn)任務(wù)報(bào)錯(cuò)。如進(jìn)行代碼評(píng)審,則提交的節(jié)點(diǎn)代碼必須通過評(píng)審人員的審核才可發(fā)布,詳情請(qǐng)參見代碼評(píng)審。
如您使用的是標(biāo)準(zhǔn)模式的工作空間,任務(wù)提交成功后,需單擊節(jié)點(diǎn)編輯頁面右上方的發(fā)布,將該任務(wù)發(fā)布至生產(chǎn)環(huán)境執(zhí)行,操作請(qǐng)參見發(fā)布任務(wù)。
后續(xù)操作
任務(wù)運(yùn)維
任務(wù)提交發(fā)布后,會(huì)基于節(jié)點(diǎn)的配置周期性運(yùn)行,您可單擊節(jié)點(diǎn)編輯界面右上角的運(yùn)維,進(jìn)入DataWorks的運(yùn)維中心查看周期任務(wù)的調(diào)度運(yùn)行情況。詳情請(qǐng)參見查看并管理周期任務(wù)。
數(shù)據(jù)管理
您可在DataWorks的數(shù)據(jù)地圖,將通過Lindorm計(jì)算引擎創(chuàng)建的表元數(shù)據(jù)采集至DataWorks進(jìn)行統(tǒng)一管理。
采集元數(shù)據(jù):在數(shù)據(jù)地圖查看元數(shù)據(jù)前,您需要先創(chuàng)建元數(shù)據(jù)采集器,詳情請(qǐng)參見CDH Hive數(shù)據(jù)抽樣采集器。
查看元數(shù)據(jù):在數(shù)據(jù)地圖,您可查看元數(shù)據(jù)的基礎(chǔ)信息、字段信息等,詳情請(qǐng)參見查看表詳情。