如果您在創建工作空間時選擇了參加數據開發(Data Studio)(新版)公測,則還需為該工作空間創建計算資源,綁定計算資源后,即可在工作空間開發和調度計算資源的相關任務。
前提條件
已創建工作空間,并且創建工作空間時選中了參加數據開發(Data Studio)(新版)公測,詳情請參見創建工作空間。
您可以在工作空間列表頁,找到目標工作空間,單擊操作列的快速進入,區分是否參加了新版數據開發公測:
未參加新版數據開發公測
參加新建數據開發公測
單擊操作列的快速進入,選擇數據開發,進入數據開發頁面。
未參加新版數據開發公測時,數據開發界面如下:
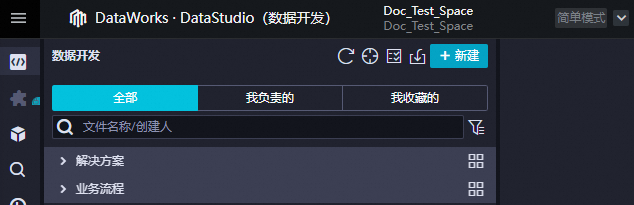
DataStudio(數據開發)的更多信息,請參見數據開發概述。
單擊操作列的快速進入,選擇數據開發(新版),進入數據開發頁面。
參加新版數據開發公測時,數據開發界面如下:
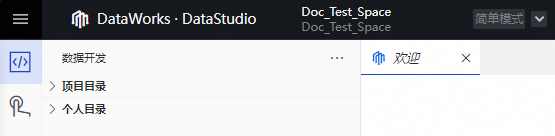
新版數據開發Data Studio的更多信息,請參見Data Studio概述。
已具備相關的計算資源服務,DataWorks綁定計算資源僅是將您已有的計算資源關聯至DataWorks,計算資源的存儲、數據以及計費均歸屬于對應計算資源。
開通DataWorks服務時,已自動購買了按量付費的Serverless資源組(不使用不計費),并綁定至默認工作空間,如您在新工作空間完成本文操作,則請將資源組綁定至新工作空間,具體操作,請參見為工作空間綁定資源組。
綁定的計算資源,需確保與Serverless資源組的連通性,詳情請參見網絡連通方案。
相關概念
計算資源
計算資源是計算引擎用于執行數據處理和分析任務的資源實例,如MaxCompute項目(Quota組)、Hologres實例等。例如,在大數據處理場景下,使用阿里云MaxCompute時,你可以通過設置Quota組來管理你的計算任務所使用的計算資源量。
一個工作空間支持添加多種計算資源。為工作空間綁定MaxCompute、Hologres、AnalyticDB for PostgreSQL、AnalyticDB for MySQL 3.0、ClickHouse、E-MapReduce、CDH、OpenSearch、Serverless Spark、Serverless StarRocks和全托管 Flink后,即可在工作空間開發和調度計算資源的相關任務。
數據源
數據源用于連接不同的數據存儲服務,它包含了連接到該數據庫所需的所有信息(如用戶名、密碼、主機地址等)。在數據開發前,您需要先定義好數據源信息,以便在執行節點任務時,能夠通過選擇數據源名稱來確定數據讀取和寫入的數據庫。一個工作空間支持添加多種數據源實例。
數據目錄
數據目錄是一個結構化的列表或地圖,用來展示一個組織內部所有的數據資產,包括但不限于數據庫、表、文件等。對于DataWorks這樣的平臺而言,數據目錄記錄了關于這些數據資產的元數據信息。
計算資源、數據源、數據目錄之間的關系
三者是獨立的對象,但存在關聯關系,具體關系如下:
綁定計算資源時,可關聯創建出數據源和數據目錄。
創建數據源時,可關聯創建出數據目錄。
創建數據目錄時,無法關聯創建出數據源或計算資源。
綁定計算資源
DataWorks支持多種方式為工作空間綁定計算資源,您可選擇其一創建即可。
創建工作空間時綁定計算資源
完成創建工作空間相關參數配置后,單擊創建工作空間,將自動進入綁定計算資源步驟,您可以按需選擇您的計算資源,完成綁定操作。
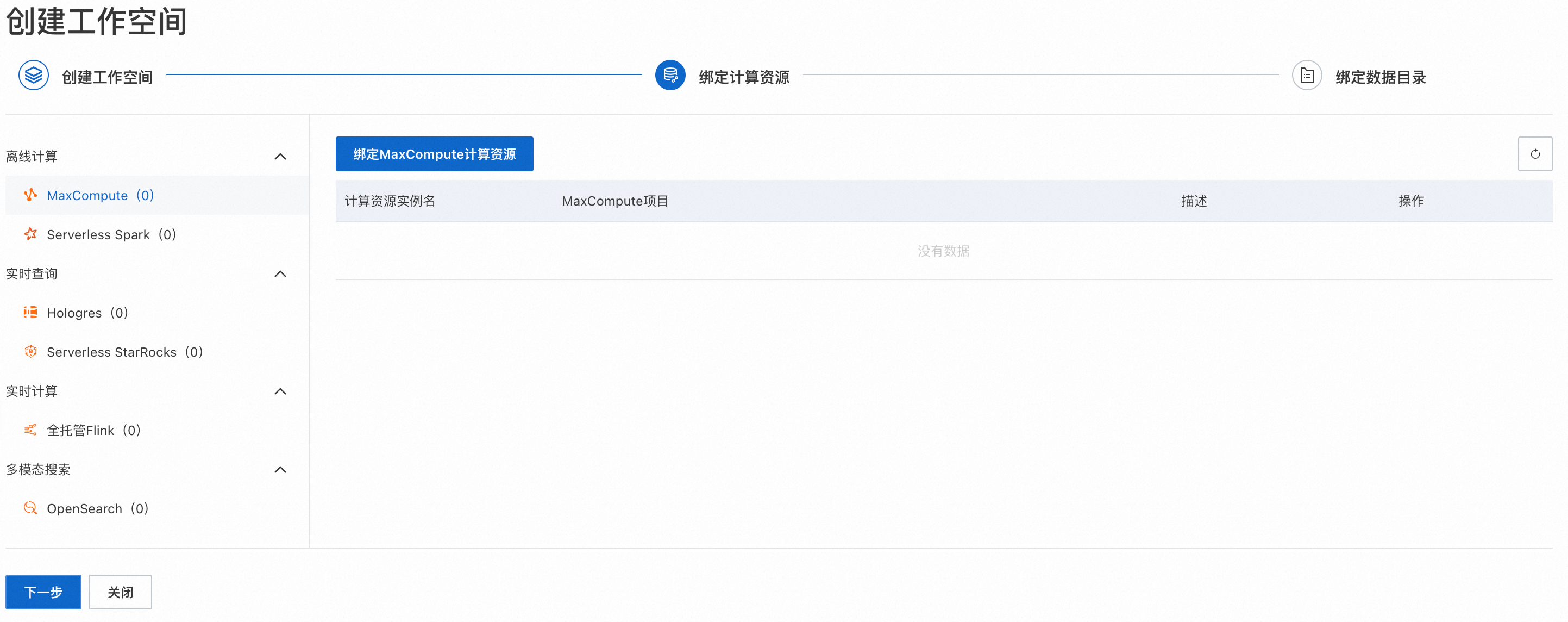
DataWorks在選擇參與新版數據開發公測后,進入綁定計算資源引導時,支持綁定多種計算資源,具體綁定說明如下:
分類 | 計算資源 | 綁定說明 | 綁定計算資源參數說明 |
離線計算 | MaxCompute | DataWorks無法直連到MaxCompute的Quota上,只能綁定到MaxCompute項目上。綁定MaxCompute計算資源后,會同步創建MaxCompute的數據源、綁定MaxCompute數據目錄。 | |
Serverless Spark | 綁定Spark工作空間。Spark計算資源無需綁定數據目錄。 | ||
實時查詢 | Hologres | DataWorks無法直連到Hologres的計算組,需要綁定到Hologres的Database上。綁定Hologres計算資源后,會同步創建Hologres數據源、綁定Hologres數據目錄。 | |
Serverless StarRocks | DataWorks無法直連到StarRocks的隊列,需要綁定到StarRocks的實例(Instance)。綁定StarRocks計算資源,會同步創建StarRocks的數據源、綁定StarRocks的數據目錄。 | ||
全托管 | 全托管Flink | 綁定Flink項目空間。Flink計算資源無需綁定數據目錄。 | |
多模態搜索 | OpenSearch | 綁定OpenSearch實例。綁定OpenSearch計算資源后,會同步創建OpenSearch數據源。該計算資源無需綁定數據目錄。 |
工作空間詳情頁綁定計算資源
如果您在創建工作空間時未立即綁定計算資源,您還可以在工作空間詳情頁為工作空間綁定計算資源。
登錄DataWorks控制臺,切換至目標地域后,單擊左側導航欄的工作空間,進入工作空間列表頁面。
找到已創建的工作空間,單擊操作列的詳情,進入工作空間詳情頁。
在左側導航欄選擇計算資源,單擊綁定計算資源,您可以按需選擇您的計算資源,然后配置相關參數,參數詳情請參見綁定計算資源參考,完成后續綁定操作。
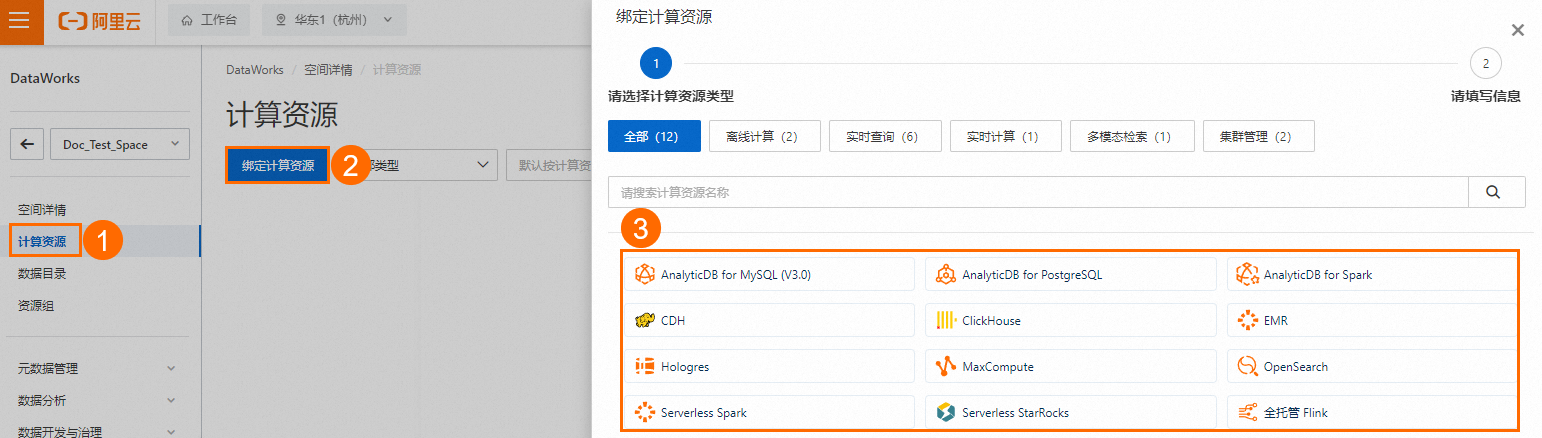
配置完成后,單擊確認按鈕保存計算資源。
管理中心綁定計算資源
如果您在創建工作空間時未立即綁定計算資源,您還可以在管理中心為工作空間綁定計算資源。
登錄DataWorks控制臺,切換至目標地域后,單擊左側導航欄的,在下拉框中選擇對應工作空間后單擊進入管理中心。
在左側導航欄單擊計算資源。
在計算資源頁面,單擊綁定計算資源,選擇需要綁定的計算資源類型,然后配置相關參數,參數詳情可參見:綁定計算資源參考。
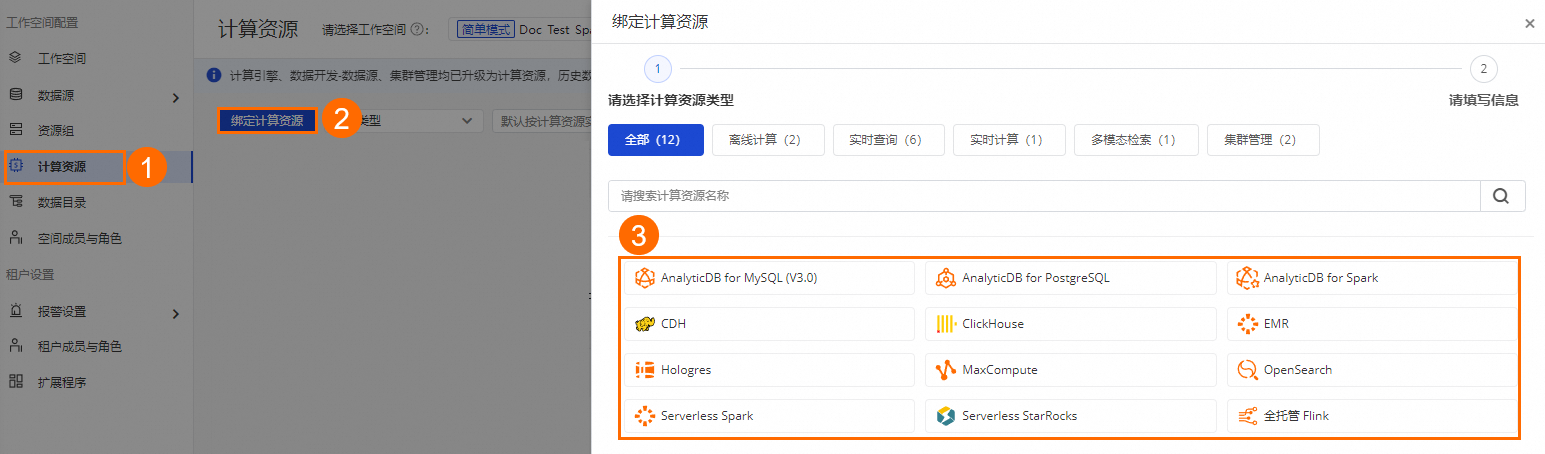
綁定計算資源參考
MaxCompute
選擇MaxCompute,進入綁定MaxCompute計算資源配置頁面,MaxCompute詳情可參見:什么是MaxCompute。
配置如下參數。
參數
說明
MaxCompute項目
選擇需要綁定的MaxCompute項目,您也可以在下拉菜單中單擊新建,直接創建MaxCompute項目后,選擇新創建的MaxCompute項目。
說明如果在創建工作空間時選擇了隔離生產、開發環境,則此處需要分別為生產和開發環境選擇MaxCompute項目,生產和開發環境不支持選擇相同的MaxCompute項目。
MaxCompute計算資源計費詳情,請參見計費項與計費方式。
MaxCompute項目創建詳情,請參見創建MaxCompute項目。
默認訪問身份
定義在當前工作空間下,用什么身份訪問該數據源。
開發環境:當前僅支持使用執行者身份訪問。
生產環境:支持使用阿里云主賬號、阿里云RAM子賬號和阿里云RAM角色訪問。
計算資源實例名
用于標識該計算資源,在任務運行時,通過計算資源實例名稱來選擇任務運行的計算資源。
連接配置
連接MaxCompute計算引擎的資源組,可在此處測試連通性。如當前工作空間暫無已綁定的資源組,可不選擇。
說明如無可用的資源組,您可以創建資源組并綁定工作空間之后,再到工作空間的詳情中測試與計算資源的連通性。具體請參見新增和使用Serverless資源組。
單擊確認,完成MaxCompute計算資源配置。
說明綁定MaxCompute計算資源后,會同步創建MaxCompute的數據源、綁定MaxCompute數據目錄。
您也可以在創建完成后,在數據目錄中查看詳情,具體請參見查看數據目錄。
Serverless Spark
選擇Serverless Spark,進入綁定Serverless Spark計算資源的配置頁面,Serverless Spark詳情可參見:什么是EMR Serverless Spark。
配置如下參數:
參數
說明
Spark工作空間
選擇需要綁定的Spark工作空間,您也可以在下拉菜單中單擊新建,前往EMR Serverless Spark控制臺進行創建,然后再回到DataWorks空間中選擇新創建的Spark工作空間。
說明如果在創建工作空間時選擇了隔離生產、開發環境,則此處需要分別為生產和開發環境選擇Spark工作空間。
如何創建Spark工作空間,請參見創建Spark工作空間。
角色授權
為了DataWorks能夠正常獲取EMR Serverless Spark集群的信息,首次選擇Spark工作空間后,請單擊添加服務關聯角色作為工作空間管理員。
重要創建服務關聯角色后,請勿在E-MapReduce Serverless Spark工作空間中移除DataWorks服務關聯角色
AliyunServiceRoleForDataWorksOnEmr和AliyunServiceRoleForDataworksEngine的管理員角色。默認引擎版本
在Data Studio中新建EMR Spark任務時,將會默認使用此處配置的引擎版本、消息隊列和SQL Compute。如需面向不同任務設置不同的引擎版本、資源隊列或SQL Compute,請在Spark任務編輯窗口的高級設置中進行定義。
默認消息隊列
默認SQL Compute
默認訪問身份
定義在當前工作空間下,用什么身份訪問該數據源。
開發環境:當前僅支持使用執行者身份訪問。
生產環境:支持使用阿里云主賬號、阿里云RAM子賬號和任務責任人。
計算資源實例名
用于標識該計算資源,在任務運行時,通過計算資源實例名稱來選擇任務運行的計算資源。
單擊確認,完成Serverless Spark計算資源配置。
說明Spark無需綁定數據目錄。
Hologres
選擇Hologres,進入綁定Hologres計算資源的配置頁面,Hologres詳情可參見什么是實時數倉Hologres。
配置如下參數:
參數
說明
Hologres實例
選擇需要綁定的Hologres實例,您也可以在下拉菜單中單擊新建,前往Hologres購買頁創建,然后再回到DataWorks空間中選擇新創建的Hologres實例。
說明如果在創建工作空間時選擇了隔離生產、開發環境,則此處需要分別為生產和開發環境選擇Hologres實例。
如何創建Hologres實例,請參見購買Hologres。
Hologres計算組
當前Hologres實例支持配置計算組,需要為其設置計算組實例,詳情可以參考計算組管理。
數據庫名稱
選擇Hologres實例中的數據庫,如果未創建數據庫,您也可以在下拉菜單中單擊新建。Hologres創建數據庫相關參數解釋,請參見創建數據庫。
默認訪問身份
定義在當前工作空間下,用什么身份訪問該數據源。
開發環境:當前僅支持使用執行者身份訪問。
生產環境:支持使用阿里云主賬號、阿里云RAM子賬號和阿里云RAM角色訪問。
計算資源實例名
用于標識該計算資源,在任務運行時,通過計算資源實例名稱來選擇任務運行的計算資源。
連接配置
連接Hologres實例的資源組,可在此處測試連通性。如當前工作空間暫無已綁定的資源組,可不選擇。
說明如無可用的資源組,您可以創建資源組并綁定工作空間之后,再到工作空間的詳情中測試與計算資源的連通性。具體請參見新增和使用Serverless資源組。
單擊確認,完成Hologres計算資源配置。
說明Spark無需綁定數據目錄。
Serverless StarRocks
選擇Serverless StarRocks,進入綁定Serverless StarRocks計算資源的配置頁面,Serverless StarRocks詳情可參見:什么是EMR Serverless StarRocks。
配置如下參數:
參數
說明
StarRocks實例
選擇需要綁定的StarRocks實例,您也可以在下拉菜單中單擊新建,前往EMR StarRocks控制臺創建,然后再回到DataWorks空間中選擇新創建的StarRocks實例。
說明如果在創建工作空間時選擇了隔離生產、開發環境,則此處需要分別為生產和開發環境選擇StarRocks實例。
如何創建StarRocks實例,請參見創建Serverless StarRocks實例。
數據庫名稱
選擇StarRocks實例中的數據庫。如果未創建數據庫,您需要先在StarRocks實例中創建數據庫,詳情請參見創建數據庫。
用戶名
密碼
創建StarRock實例時設置的賬號和密碼,賬號默認為
admin。計算資源實例名
用于標識該計算資源,在任務運行時,通過計算資源實例名稱來選擇任務運行的計算資源。
連接配置
連接StarRocks實例的資源組,可在此處測試連通性。如當前工作空間暫無已綁定的資源組,可不選擇。
說明如無可用的資源組,您可以創建資源組并綁定工作空間之后,再到工作空間的詳情中測試與計算資源的連通性。具體請參見新增和使用Serverless資源組。
單擊確認,完成Serverless StarRocks計算資源配置。
說明綁定StarRock計算資源后,會同步創建StarRock數據源、綁定StarRock數據目錄。
您也可以在創建完成后,在數據目錄中查看詳情,具體請參見查看數據目錄。
全托管Flink
選擇全托管Flink,進入綁定全托管Flink計算資源的配置頁面,全托管Flink詳情可參見:什么是阿里云實時計算Flink版。
配置如下參數:
參數
說明
Flink工作空間
選擇需要綁定的Flink工作空間,您也可以在下拉菜單中單擊新建,前往全托管Flink購買頁創建,然后再回到DataWorks空間中選擇新創建的Flink工作空間。
說明如果在創建工作空間時選擇了隔離生產、開發環境,則此處需要分別為生產和開發環境選擇Flink工作空間。
如何創建Flink工作空間,請參見開通實時計算Flink版。
Flink項目空間
選擇Flink工作空間內的項目空間,工作空間創建完成會創建默認項目空間,您也可以在Flink控制臺手動添加其他項目空間后,再在此處選擇。創建Flink項目空間,詳情可參見:管理項目空間。
默認部署目標
選擇默認部署目標,在Data Studio中新建Flink任務時,將會默認使用此處配置的部署目標。
計算資源實例名
用于標識該計算資源,在任務運行時,通過計算資源實例名稱來選擇任務運行的計算資源。
單擊確認,完成全托管Flink計算資源配置。
說明Flink無需綁定數據目錄。
OpenSearch
選擇OpenSearch,進入綁定OpenSearch計算資源的配置頁面,詳情請參見:什么是智能開放搜索OpenSearch。
配置如下參數。
參數
說明
OpenSearch實例
選擇需要綁定的OpenSearch實例,您也可以在下拉菜單中單擊新建,前往開放搜索購買頁創建,然后再回到DataWorks空間中選擇新創建的OpenSearch實例。
說明如果在創建工作空間時選擇了隔離生產、開發環境,則此處需要分別為生產和開發環境選擇OpenSearch實例。
如何創建OpenSearch實例,請參見購買OpenSearch向量檢索版實例。
用戶名
密碼
填寫創建OpenSearch實例時設置的用戶名和密碼。
計算資源實例名
用于標識該計算資源,在任務運行時,通過計算資源實例名稱來選擇任務運行的計算資源。
單擊確認,完成OpenSearch計算資源配置。
說明OpenSearch無需綁定數據目錄。
AnalyticDB for MySQL (V3.0)
選擇AnalyticDB for MySQL (V3.0),進入綁定AnalyticDB for MySQL (V3.0)計算資源的配置頁面,AnalyticDB for MySQL (V3.0)詳情請參見:什么是云原生數據倉庫AnalyticDB MySQL版。
配置如下參數:
參數
說明
配置模式
僅支持阿里云實例模式。
所屬云賬號
僅支持當前阿里云賬號。
地域
AnalyticDB for MySQL (V3.0)實例所在地域。
說明若選擇的地域與當前工作空間地域不一致,則創建數據源后,該數據源不支持在數據開發(DataStudio)綁定,即此類數據源不能用于數據開發或周期性調度任務,僅可用于數據集成模塊進行數據同步。
實例
選擇需要綁定該工作空間的實例。
說明如果在創建工作空間時選擇了隔離生產、開發環境,則此處需要分別為生產和開發環境選擇不同的實例或數據庫。
數據庫名稱
填寫AnalyticDB for MySQL (V3.0)實例中創建的數據庫名稱,詳情可參見:創建數據庫。
用戶名
填寫擁有數據庫權限的用戶名。
密碼
填寫用戶名密碼。
計算資源實例名
用于標識該計算資源,在任務運行時,通過計算資源實例名稱來選擇任務運行的計算資源。
連接配置
連接AnalyticDB for MySQL (V3.0)計算引擎的資源組,可在此處測試連通性。如當前工作空間暫無已綁定的資源組,可不選擇。
說明如無可用的資源組,您可以創建資源組并綁定工作空間之后,再到工作空間的詳情中測試與計算資源的連通性。具體請參見新增和使用Serverless資源組。
單擊確認,完成AnalyticDB for MySQL (V3.0)計算資源配置。
AnalyticDB for PostgreSQL
選擇AnalyticDB for PostgreSQL ,進入綁定AnalyticDB for PostgreSQL計算資源的配置頁面,AnalyticDB for PostgreSQL詳情請參見AnalyticDB for PostgreSQL產品概述。
配置如下參數:
參數
說明
配置模式
僅支持阿里云實例模式。
所屬云賬號
僅支持當前阿里云賬號。
地域
AnalyticDB for PostgreSQL實例所在地域。
說明若選擇的地域與當前工作空間地域不一致,則創建數據源后,該數據源不支持在數據開發(Data Studio)中使用,即不能用于數據開發或周期性調度任務,僅可用于數據集成模塊進行數據同步。
實例
選擇需要綁定該工作空間的實例。
數據庫名稱
填寫AnalyticDB for PostgreSQL實例中創建的數據庫名稱,詳情請參見:數據庫管理。
用戶名
填寫擁有數據庫權限的用戶名。
密碼
填寫用戶名密碼。
計算資源實例名
用于標識該計算資源,在任務運行時,通過計算資源實例名稱來選擇任務運行的計算資源。
連接配置
連接AnalyticDB for PostgreSQL計算引擎的資源組,可在此處測試連通性。如當前工作空間暫無已綁定的資源組,可不選擇。
說明如無可用的資源組,您可以創建資源組并綁定工作空間之后,再到工作空間的詳情中測試與計算資源的連通性。具體請參見新增和使用Serverless資源組。
單擊確認,完成AnalyticDB for PostgreSQL計算資源配置。
AnalyticDB for Spark
注冊AnalyticDB for Spark所使用的阿里云實例為AnalyticDB for MySQL 企業版實例,詳情可參見:Spark計算引擎。
選擇AnalyticDB for Spark,進入綁定AnalyticDB for Spark計算資源的配置頁面。
配置如下參數:
參數
說明
配置模式
僅支持阿里云實例模式。
所屬云賬號
僅支持當前阿里云賬號。
地域
AnalyticDB for MySQL實例所在地域。
說明若選擇的地域與當前工作空間地域不一致,則創建數據源后,該數據源不支持在數據開發(Data Studio)中使用,即不能用于數據開發或周期性調度任務,僅可用于數據集成模塊進行數據同步。
實例
選擇需要綁定該工作空間的實例。
數據庫名稱
填寫AnalyticDB for MySQL實例中創建的數據庫名稱,詳情可參見:創建數據庫。
默認訪問身份
默認任務責任人。
計算資源實例名
用于標識該計算資源,在任務運行時,通過計算資源實例名稱來選擇任務運行的計算資源。
連接配置
連接AnalyticDB for Spark計算引擎的資源組,可在此處測試連通性。如當前工作空間暫無已綁定的資源組,可不選擇。
說明如無可用的資源組,您可以創建資源組并綁定工作空間之后,再到工作空間的詳情中測試與計算資源的連通性。具體請參見新增和使用Serverless資源組。
單擊確認,完成AnalyticDB for Spark計算資源配置。
CDH
選擇CDH ,進入綁定CDH計算資源的配置頁面。
配置如下參數:
CDH集群的基本信息
參數
說明
集群版本
選擇注冊的集群版本。
DataWorks提供的CDH5.16.2、CDH6.1.1、CDH6.2.1、CDH6.3.2、CDP7.1.7版本您可直接選擇,該類集群版本配套的組件版本固定。若該類集群版本不滿足您的業務需要,您可選擇自定義版本,并按需配置組件版本。
集群名稱
用于確定當前所注冊集群的配置信息來源。可選擇其他工作空間已注冊的集群或新建集群:
已注冊集群:當前所注冊集群的配置信息,直接引用其他工作空間已注冊集群的配置信息。
新建集群:當前注冊集群的配置信息需您自行配置。
計算資源實例名
用于標識該計算資源,在任務運行時,通過計算資源實例名稱來選擇任務運行的計算資源。
CDH配置句群鏈接信息
參數
說明
Hive連接信息
按照集群版本選擇集群Hive版本,并填寫HiveServer2的JDBC地址以及Metastore地址。
Impala連接信息
按照集群版本選擇集群Impala版本,并填寫Impala的JDBC地址。
Spark連接信息
按照集群版本選擇集群Spark版本。
Yarn連接信息
按照集群版本選擇集群Yarn版本,并填寫
Yarn.resourcemanager.address地址以及jobhistory.webapp.address地址。MapReduce連接信息
按照集群版本選擇集群MapReduce版本。
Presto
按照集群版本選擇集群Presto版本,并填寫JDBC地址。
CDH添加集群配置文件
配置文件
描述
應用場景
Core-Site文件
包含Hadoop Core庫的全局配置。例如,HDFS和MapReduce常用的I/O設置。
運行Spark或MapReduce任務,需上傳該文件。
Hdfs-Site文件
包含HDFS的相關配置。例如,數據塊大小、備份數量、路徑名稱等。
Mapred-Site文件
用于配置MapReduce相關的參數。例如,配置MapReduce作業的執行方式和調度行為。
運行MapReduce任務,需上傳該文件。
Yarn-Site文件
包含了與YARN守護進程相關的所有配置。例如,資源管理器、節點管理器和應用程序運行時的環境配置。
運行Spark或MapReduce任務,或賬號映射類型選擇Kerberos時,需上傳該文件。
Hive-Site文件
包含了用于配置Hive的各項參數。例如,數據庫連接信息、Hive Metastore的設置和執行引擎等。
賬號映射類型選擇Kerberos時,需上傳該文件。
Spark-Defaults文件
用于指定Spark作業執行時應用的默認配置。您可通過
spark-defaults.conf文件預先設定一系列參數(例如,內存大小、CPU核數),Spark應用程序在運行時將采用該參數配置。運行Spark任務,需上傳該文件。
Config.Properties文件
包含Presto服務器的相關配置。例如,設置Presto集群中協調器節點和工作節點的全局屬性。
使用Presto組件,且賬號映射類型選擇OPEN LDAP或Kerberos時,需上傳該文件。
Presto.Jks文件
用于存儲安全證書,包括私鑰和頒發給應用程序的公鑰證書。在Presto數據庫查詢引擎中,
presto.jks文件用于為Presto進程啟用SSL/TLS加密通信,確保數據傳輸的安全。
單擊確認,完成CDH計算資源配置。
ClikcHouse
選擇ClickHouse ,進入綁定ClickHouse計算資源的配置頁面。
配置如下參數:
配置
說明
配置模式
目前支持通過連接串模式增ClickHouse集群。
JDBC URL
連接ClickHouse的JDBC URL信息。您可登錄云數據庫ClickHouse控制臺,獲取相關數據庫及端口信息。
用戶名
訪問ClickHouse集群的用戶名。
密碼
訪問ClickHouse集群的用戶密碼。
認證選項
選擇后續訪問ClickHouse集群時是否需要SSL認證。開啟該認證服務后,ClickHouse數據源不支持用于數據開發或周期性調度任務。
計算資源實例名
用于標識該計算資源,在任務運行時,通過計算資源實例名稱來選擇任務運行的計算資源。
連接配置
連接ClickHouse計算引擎的資源組,可在此處測試連通性。如當前工作空間暫無已綁定的資源組,可不選擇。
說明如無可用的資源組,您可以創建資源組并綁定工作空間之后,再到工作空間的詳情中測試與計算資源的連通性。具體請參見新增和使用Serverless資源組。
單擊確認,完成ClickHouse計算資源配置。
EMR
選擇EMR ,進入綁定EMR計算資源的配置頁面,EMR詳情請參見:什么是EMR on ECS。
配置如下參數:
當前阿里云主賬號
當集群所屬云賬號選擇當前阿里云主賬號時,您還需要配置如下參數:
配置項
說明
集群類型
選擇需要注冊的EMR集群類型。目前DataWorks可注冊的集群類型請參見使用限制。
集群
選擇當前賬號下需要注冊至DataWorks的EMR集群。
說明若集群類型選擇EMR Serverless Spark,您需按照界面指引及參考說明選擇相應的E-MapReduce工作空間(即要注冊的集群)、默認引擎版本、默認資源隊列等信息。
默認訪問身份
定義在當前工作空間下,使用什么身份訪問該EMR集群。
開發環境:可選擇使用集群賬號
hadoop,或任務執行者所映射的集群賬號。生產環境:可選擇使用集群賬號
hadoop,任務責任人、阿里云主賬號或阿里云子賬號所映射的集群賬號。
說明當默認訪問身份選擇任務責任人、阿里云主賬號或阿里云子賬號所映射的集群賬號時,您可以參考設置集群身份映射手動配置DataWorks租戶成員與EMR集群指定賬號的映射關系。通過該映射的集群賬號在DataWorks執行EMR任務,未配置DataWorks租戶成員與集群賬號映射的情況下,DataWorks處理策略如下:
若使用RAM用戶(子賬號)執行任務:我們將默認按照與當前操作人同名的EMR集群系統賬號執行任務。若集群開啟LDAP或者Kerberos認證,任務執行將失敗。
若使用阿里云主賬號執行任務:DataWorks任務執行將報錯。
傳遞Proxy User信息
用于配置是否傳遞Proxy User信息。
說明當開啟LDAP/Kerberos等認證方式時,集群會為每個普通用戶都頒發一個認證憑證,該操作比較麻煩。為方便統一管理用戶權限,您可通過某個超級用戶(Real User)去代理普通用戶(Proxy User)進行權限認證,此時,通過Proxy User訪問集群時,實際使用的是超級用戶的身份認證信息。您只需添加用戶為Proxy User即可。
傳遞:在EMR集群中運行任務時,根據Proxy User進行數據訪問權限的校驗及控制。
DataStudio(數據開發)、數據分析:將動態傳遞任務執行者的阿里云賬號名稱,即Proxy User信息為任務執行者的信息。
運維中心:將固定傳遞注冊集群時配置的默認訪問身份的阿里云賬號名稱,即Proxy User信息作為默認訪問身份的信息。
不傳遞:在EMR集群中運行任務時,根據注冊集群時配置的賬號認證方式進行數據訪問權限的校驗及控制。
不同類型的EMR任務,傳遞Proxy User信息的方式如下:
EMR Kyuubi任務:通過
hive.server2.proxy.user配置項傳遞。EMR Spark任務及非JDBC模式的EMR Spark SQL任務:通過
-proxy-user配置項傳遞。
配置文件
當集群類型選擇HADOOP時,您可以前往EMR控制臺獲取配置文件。詳情請參見導出和導入服務配置。導出后請根據產品界面要上傳的配置文件,修改文件名稱。
此外,您還可以登錄EMR集群,通過以下路徑獲取相關配置文件。
/etc/ecm/hadoop-conf/core-site.xml /etc/ecm/hadoop-conf/hdfs-site.xml /etc/ecm/hadoop-conf/mapred-site.xml /etc/ecm/hadoop-conf/yarn-site.xml /etc/ecm/hive-conf/hive-site.xml /etc/ecm/spark-conf/spark-defaults.conf /etc/ecm/spark-conf/spark-env.sh計算資源實例名
用于標識該計算資源,在任務運行時,通過計算資源實例名稱來選擇任務運行的計算資源。
其他阿里云主賬號
當集群所屬云賬號選擇其他阿里云主賬號時,您還需要配置如下參數:
配置項
說明
對方阿里云主賬號UID
需添加的EMR集群所屬的云賬號UID。
對方RAM角色
訪問該EMR集群的RAM角色。該角色需滿足如下條件:
對方阿里云主賬號中已創建RAM角色。
對方阿里云主賬號的RAM角色已授權訪問當前賬號的DataWorks服務。
對方EMR集群類型
選擇需要注冊的EMR集群類型。目前跨賬號注冊EMR集群場景下僅支持
EMR on ECS:DataLake集群、EMR on ECS:Hadoop集群及EMR on ECS:自定義集群。對方EMR集群
選擇該賬號下需要注冊至DataWorks的EMR集群。
配置文件
請在產品界面按照提示配置各項配置文件。獲取配置文件詳情請參見導出和導入服務配置。導出后請根據產品界面要上傳的配置文件,修改文件名稱。
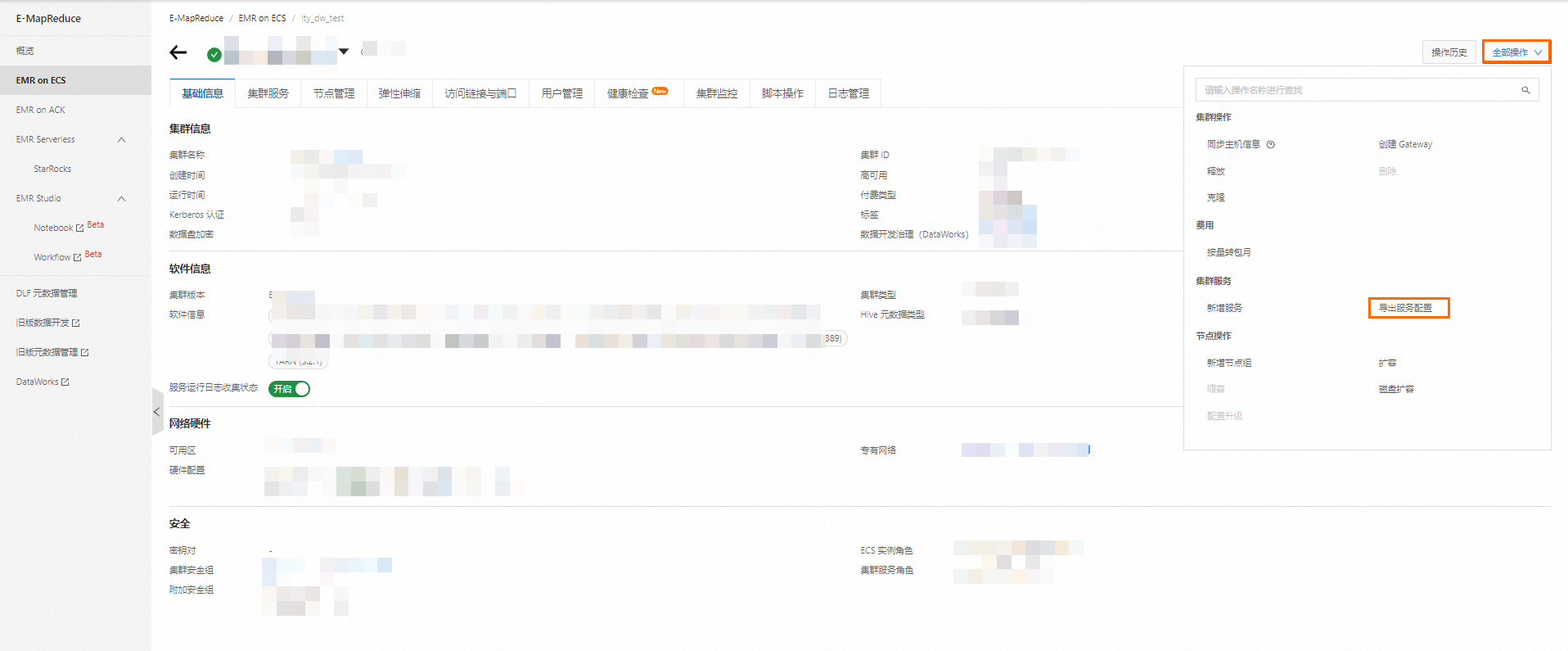
此外,您還可以登錄EMR集群,通過以下路徑獲取相關配置文件。
/etc/ecm/hadoop-conf/core-site.xml /etc/ecm/hadoop-conf/hdfs-site.xml /etc/ecm/hadoop-conf/mapred-site.xml /etc/ecm/hadoop-conf/yarn-site.xml /etc/ecm/hive-conf/hive-site.xml /etc/ecm/spark-conf/spark-defaults.conf /etc/ecm/spark-conf/spark-env.sh默認訪問身份
定義在當前工作空間下,用什么身份訪問該EMR集群。
開發環境:可選擇統一使用集群賬號:hadoop,或任務責任人所映射的集群賬號。
生產環境:可選擇統一使用集群賬號:hadoop、任務責任人、阿里云主賬號或阿里云子賬號所映射的集群賬號。
說明當默認訪問身份選擇任務責任人、阿里云主賬號或阿里云子賬號所映射的集群賬號時,您可以參考設置集群身份映射手動配置DataWorks租戶成員與EMR集群指定賬號的映射關系。通過該映射的集群賬號在DataWorks執行EMR任務,未配置DataWorks租戶成員與集群賬號映射的情況下,DataWorks處理策略如下:
若使用RAM用戶(子賬號)執行任務:我們將默認按照與當前操作人同名的EMR集群系統賬號執行任務。若集群開啟LDAP或者Kerberos認證,任務執行將失敗。
若使用阿里云主賬號執行任務:DataWorks任務執行將報錯。
傳遞Proxy User信息
用于配置是否傳遞Proxy User信息。
說明當開啟LDAP/Kerberos等認證方式時,集群會為每個普通用戶都頒發一個認證憑證,該操作比較麻煩。為方便統一管理用戶權限,您可通過某個超級用戶(Real User)去代理普通用戶(Proxy User)進行權限認證,此時,通過Proxy User訪問集群時,實際使用的是超級用戶的身份認證信息。您只需添加用戶為Proxy User即可。
傳遞:在EMR集群中運行任務時,根據Proxy User進行數據訪問權限的校驗及控制。
DataStudio(數據開發)、數據分析:將動態傳遞任務執行者的阿里云賬號名稱,即Proxy User信息為任務執行者的信息。
運維中心:將固定傳遞注冊集群時配置的默認訪問身份的阿里云賬號名稱,即Proxy User信息為默認訪問身份的信息。
不傳遞:在EMR集群中運行任務時,根據注冊集群時配置的賬號認證方式進行數據訪問權限的校驗及控制。
不同類型的EMR任務,傳遞Proxy User信息的方式如下:
EMR Kyuubi任務:通過
hive.server2.proxy.user配置項傳遞。EMR Spark任務及非JDBC模式的EMR Spark SQL任務:通過
-proxy-user配置項傳遞。
計算資源實例名
用于標識該計算資源,在任務運行時,通過計算資源實例名稱來選擇任務運行的計算資源。
單擊確認,完成EMR計算資源配置。
后續步驟
除綁定計算資源參考中部分計算資源會同步綁定對應數據目錄外,您也可以單獨綁定DLF Catalog、MaxCompute、Hologres、StarRocks類型的數據目錄,用于在新版數據開發中可視化查看和管理。綁定數據目錄操作詳情請參見:從管理中心、工作空間詳情頁綁定數據目錄。
綁定數據目錄成功后,您可前往數據開發中查看和管理數據目錄中的詳細表信息,具體操作,請參見數據目錄管理。
綁定計算資源后,即可執行后續數據開發、數據分析、使用運維中心周期性調度運行相關任務等操作,詳情請參見Data Studio概述、數據分析概述、運維中心入門。