全增量實時同步方案為您先進行全量數據遷移,然后再實時同步增量數據至目標端。本文為您介紹如何創建全增量實時同步至Hologres任務。
前提條件
已完成數據源配置。您需要在數據集成同步任務配置前,配置好您需要同步的源端和目標端數據庫,以便在同步任務配置過程中,可通過選擇數據源名稱來控制同步任務的讀取和寫入數據庫。同步任務支持的數據源及其配置詳情請參見支持的數據源及同步方案。
說明數據源相關能力介紹詳情請參見:數據源概述。
已完成數據源環境準備。您可以基于您需要進行的同步配置,在同步任務執行前,授予數據源配置的賬號在數據庫進行相應操作的權限。詳情請參見:數據庫環境準備概述。
背景信息
全增量實時同步至Hologres為一鍵實時同步至Hologres的2.0版本,目前還未完全上線,敬請期待。
方案屬性 | 說明 |
讀寫表個數 |
|
任務組成 | 當前方案將分別創建用于全量數據初始化的離線同步子任務,和用于增量數據實時同步的數據集成實時同步子任務,方案產生的離線同步子任務個數與源端讀取的表數量有關。 |
數據寫入 | 支持寫入分區表與非分區表,分為以下三階段:
|
注意事項
同步數據至Hologres時,目前僅支持將數據寫入分區表子表,暫不支持寫入數據至分區表父表。
操作流程
步驟一:選擇同步方案
在此步驟中,您需要進入數據集成頁面配置同步解決方案。
進入數據集成頁面。
登錄DataWorks控制臺,切換至目標地域后,單擊左側導航欄的,在下拉框中選擇對應工作空間后單擊進入數據集成。
在數據集成同步任務頁任務列表中單擊請創建,進入同步方案配置頁面。
數據來源與去向:選擇待同步的源端數據源類型,目標端數據源選擇Hologres。
新任務名稱:配置當前方案名稱。
同步類型:選擇整庫實時。
同步步驟:按需選擇。
步驟二:網絡與資源配置
在此步驟中,選擇當前任務需要同步的數據來源數據源與數據去向數據源,以及用于執行同步任務的資源組,并測試連通性。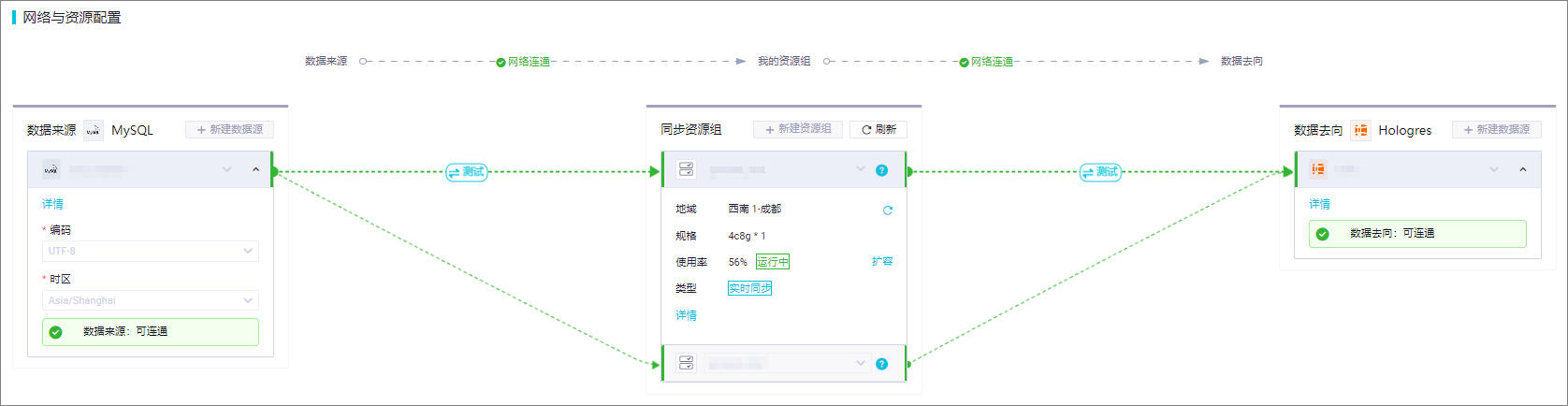
您需要在數據來源區域根據業務需要定義讀取源端數據庫所使用的編碼格式,及源端數據庫讀取數據時所使用的時區。
步驟三:選擇要同步的表
此步驟中,您可以在源端庫表區域選擇源端數據源下需要同步的表,并單擊 圖標,將其移動至已選庫表。同時,支持通過正則表達式過濾庫與表。
圖標,將其移動至已選庫表。同時,支持通過正則表達式過濾庫與表。
步驟四:目標表映射
在上一步驟選擇完需要同步的表后,將自動在此界面展示當前待同步的表,但目標表的相關屬性默認為待映射狀態,需要您定義并確認源表與目標表映射關系,即數據的讀取與寫入關系,然后單擊刷新映射后才可進入下一步操作。您可以直接刷新映射,或自定義目標表規則后,再刷新映射。
您可以選中待同步表后,單擊批量刷新映射,未配置映射規則時,默認根據源表所在庫和表,寫入至與源庫同名的Hologres schema;與源表同名的Hologres表,若目標端不存在同名庫與表時,將自動新建。
在進行自定義目標schema、表名和表字段等操作時,若在表格中未找到相關信息列,您可以單擊表格右上方
 按鈕自定義表格的顯示列。
按鈕自定義表格的顯示列。
定義目標schema名與表名
定義目標schema名與表名映射規則。
需求
配置入口
配置
自定義目標Schema名映射規則
在目標Schema名映射自定義列,單擊編輯按鈕。
可以使用內置變量和手動輸入的字符串拼接成為最終目標Schema名。其中,支持您編輯內置變量,例如,做字符串替換。
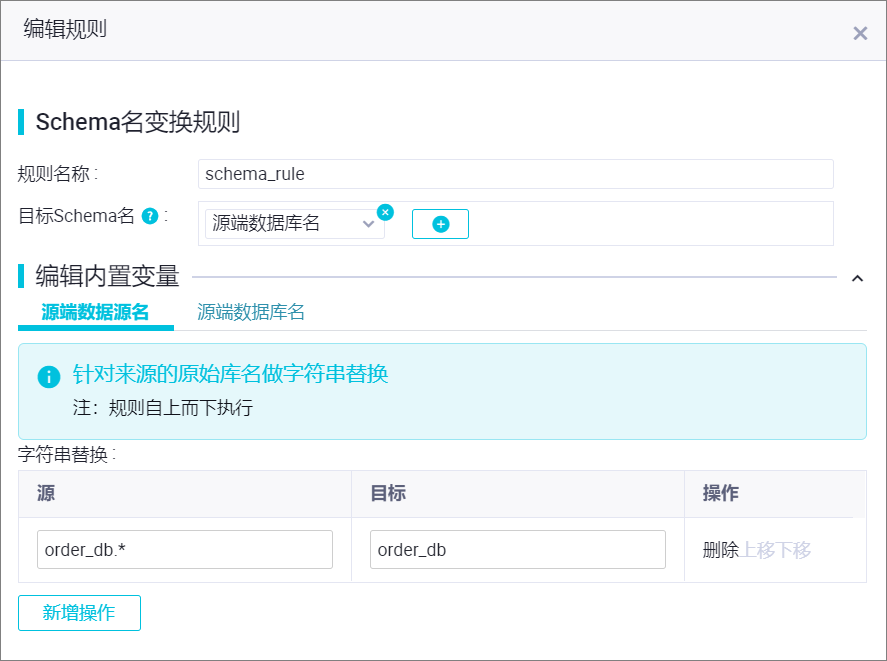
如上圖所示,使用源端數據庫名將源端數據庫名作為目標schema名稱,并且將所有滿足
order_db.*正則表達式的源庫寫入目標Hologres名為order_db的schema中。自定義目標表名映射規則
在目標表名映射自定義列,單擊編輯按鈕。
可以使用內置變量和手動輸入的字符串拼接成為最終目標表名。其中,支持您編輯內置變量,例如,做字符串替換。
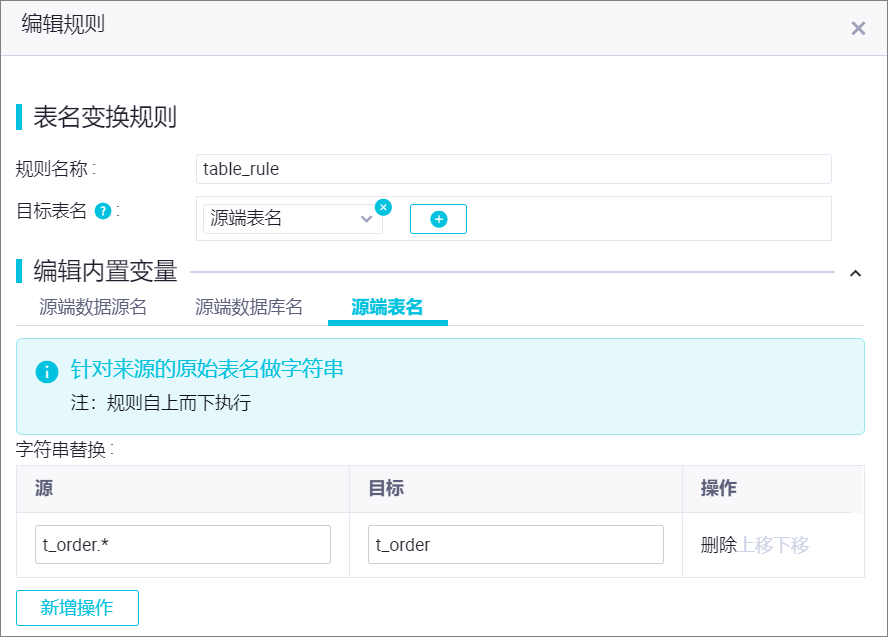
如上圖所示,使用源端表名將源端表名作為目標表名稱,并且將源端表名中符合
t_order.*正則表達式的表數據寫入到Hologres名為t_order表中。應用目標schema名與表名映射規則。
選中待同步的所有表,單擊批量修改>目標Schema名映射自定義或批量修改>目標表名映射自定義,并分別選擇已創建的規則,使規則生效。
編輯字段類型映射
同步任務存在默認的源端字段類型與目標端字段類型映射,您可以單擊表格右上角的編輯字段類型映射,自定義源端表與目標端表字段類型映射關系,配置完后單擊應用并刷新映射。
編輯目標表結構并添加字段。
當目標Hologres表為待建立狀態時,您可以為目標表在原有表結構基礎上新增字段。操作如下:
為目標表添加字段。
單表新增字段:單擊目標表名列的
 按鈕添加字段。
按鈕添加字段。批量新增字段:在表格底部選擇批量修改>目標表結構_批量修改和新增字段。
為字段賦值。
您可以通過以下操作為上述步驟中新增的字段賦值。
單表賦值:單擊目標表字段賦值列的編輯按鈕,為目標表字段賦值。
批量賦值:在列表底部選擇批量修改>目標表字段賦值為目標表中相同的字段批量賦值。
說明在賦值時支持賦值常量與變量,您可通過
 圖標切換賦值模式。
圖標切換賦值模式。
配置DML規則
數據集成提供默認DML處理規則,同時,您可以根據業務需要在此界面對寫入Hologres的DML命令定義處理規則。
單表定義規則:單擊表格列DML規則配置>配置DML,對目標表單獨定義DML規則。
批量定義規則:在列表底部選擇批量修改>DML規則配置。
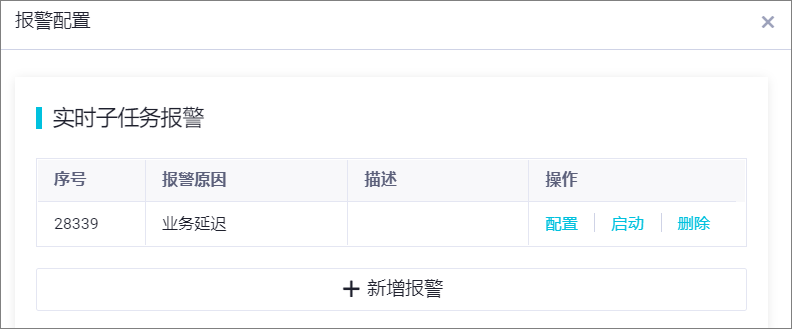
步驟五:報警配置
為避免任務出錯導致業務數據同步延遲,您可以對實時同步子任務設置不同的報警策略。操作如下:
單擊頁面右上方的報警設置,進入實時同步子任務報警設置頁面。
單擊新增報警,配置報警規則。
說明此處定義的報警規則,將對該任務產生的實時同步子任務生效,您可在任務配置完成后,進入實時同步任務界面查看并修改該實時同步子任務的監控報警規則。
管理報警規則。
對于已創建的報警規則,您可以通過報警開關控制報警規則是否開啟,同時,您可以根據報警級別報警給不同的人員。
步驟六:高級參數配置
數據集成提供數據庫最大連接數,并發度等配置的默認值,如果需要對任務做精細化配置,達到自定義同步需求,您可對參數值進行修改,例如通過最大連接數上限限制,避免當前同步方案對數據庫造成過大的壓力從而影響生產。操作如下:
請在完全了解對應參數含義情況下再進行修改,以免產生不可預料的錯誤或者數據質量問題。
單擊界面右上方的高級參數配置,進入高級參數配置頁面。
在高級參數配置頁面基于業務需要與資源組、數據庫實際情況配置各項參數。
配置區域
參數
說明
讀端配置
離線任務源端最大連接數
支持您通過該參數控制當前同步方案所產生的所有離線子同步任務可占用的源端數據庫連接數,即同一時間內,當前同步解決方案所產生的所有離線子同步任務讀取數據庫的并發數上限。
說明實際執行時,當前任務同時運行的離線子任務并發度將不會超過此值。
配置運行時配置中的離線同步任務并發數時請參考該值。
寫端配置
實時任務寫端最大連接數
支持通過該參數控制當前同步方案所產生的所有實時子任務可占用的寫端數據庫最大連接數。
說明實際執行時,當前任務所產生的實時同步子任務并發度將不會超過此值。
配置運行時配置中的實時任務并發數時請參考該值。
離線任務寫端最大連接數
支持通過該參數控制當前同步方案所產生的單個離線同步子任務可占用的寫端數據庫最大連接數。
運行時配置
離線同步任務并發度
單個離線同步子任務的并發數,建議按照對應規格的資源組支持的最大并發數合理分配。
說明因為離線同步任務個體配置差異較大,實際執行時不一定可以達到此處配置的并發數。收費將按照實際執行的并發數收費。詳情請參見:性能指標。
離線任務是否開啟限流
提供限流功能控制同步流量。
不限流:默認不限流,在不限流的情況下,任務將在所配置的并發數的限制基礎上,提供現有硬件環境下最大的傳輸性能。
限流:考慮到速度過高可能對數據庫造成過大的壓力從而影響生產,數據集成同時提供了限速選項,您可以通過限流控制同步速率,從而保護讀取端數據庫,避免抽取速度過大,給數據庫造成太大的壓力。限速最小配置為1MB/S,最高上限為30MB/s。
離線任務限流大小
當開啟限流場景下,您可以在此配置單個離線子任務流量大小。
說明流量度量值是數據集成本身的度量值,不代表實際網卡流量。通常,網卡流量往往是通道流量膨脹的1至2倍,實際流量膨脹取決于具體的數據存儲系統傳輸序列化情況。
實時任務并發度
單個實時同步子任務并發數。
是否支持自動創建Schema
定義當前任務是否允許自動創建Hologres Schema。
步驟七:DDL能力配置
來源數據源會包含許多DDL操作,您可以根據業務需求,單擊界面右上方DDL能力配置,進入DDL能力配置頁面對不同的DDL消息設置同步至目標端的處理策略。不同DDL消息處理策略請參見:DDL消息處理規則。
步驟八:資源組配置
運行當前同步解決方案將產生多個離線同步子任務和一個實時同步子任務,您可以單擊界面右上方的資源組配置,查看并切換當前的任務所使用的離線同步資源組和實時同步資源組。
離線和實時同步任務推薦使用不同的資源組,以便任務分開執行。如果選擇同一個資源組,任務混跑會帶來資源搶占、運行態互相影響等問題。例如,CPU、內存、網絡等互相影響,可能會導致離線任務變慢或實時任務延遲等問題,甚至在資源不足的極端情況下,可能會出現任務被OOM KILLER殺掉等問題。
步驟九:執行同步解決方案任務
進入界面,找到已創建的同步方案。
單擊操作列的啟動/提交執行按鈕,啟動同步的運行。
單擊操作列的執行詳情,查看任務的詳細執行過程。
后續步驟
完成任務配置后,您可以對已創建的任務進行管理、執行加減表操作,或對任務配置監控報警,并查看任務運行的關鍵指標等。詳情請參見:全增量同步任務運維。