數據集成提供向導式的開發引導,您無需編寫任何代碼,通過在界面勾選數據來源與去向,并結合DataWorks調度參數,實現將源端單表或分庫分表的全量或增量數據周期性同步至目標數據表。本文為您介紹向導模式配置離線同步任務的常規配置,各數據源配置存在一定差異,請以具體數據源配置文檔為準。
背景信息
數據集成離線同步,為您提供數據讀取(Reader)和寫入插件(Writer)實現數據的讀取與寫入,您可通過向導模式和腳本模式配置離線同步任務,實現源端單表同步至目標端單表、源端分庫分表同步至目標端單表兩類數據同步場景。詳情請參見離線同步能力說明。
使用說明
部分數據源不支持使用向導模式配置離線同步任務,您可以選擇數據源后,根據界面提示,若當前數據源不支持向導模式編輯任務,則單擊工具欄中的
 圖標切換至腳本模式繼續配置任務。詳情請參見通過腳本模式配置離線同步任務。
圖標切換至腳本模式繼續配置任務。詳情請參見通過腳本模式配置離線同步任務。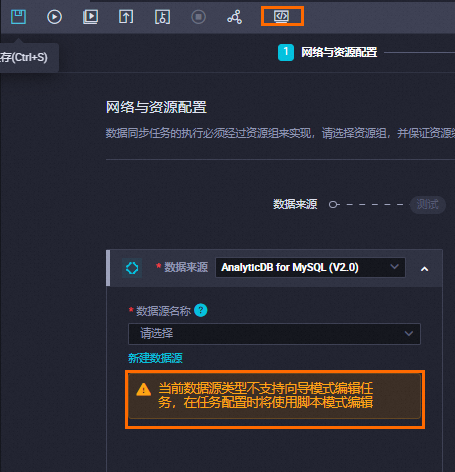
向導模式的學習成本低,但向導模式無法支持部分高級功能。如果您需要實現更精細化的配置管理,您可以單擊工具欄中的轉換腳本圖標,切換到腳本模式配置離線同步任務。
前提條件
已完成數據源配置。在設置數據集成同步任務之前,請確保已在DataWorks的數據源管理中配置好所需的源數據庫和目標數據庫。數據源配置詳情請參見數據源列表。
說明離線同步支持的數據源及其配置詳情請參見支持的數據源與讀寫插件。
數據源相關能力介紹詳情請參見:數據源概述。
已購買合適規格的獨享數據集成資源組。詳情請參見:新增和使用獨享數據集成資源組。
獨享數據集成資源組與數據源網絡已打通。詳情請參見:網絡連通方案。
進入數據開發界面
進入數據開發頁面。
登錄DataWorks控制臺,切換至目標地域后,單擊左側導航欄的,在下拉框中選擇對應工作空間后單擊進入數據開發。
開發流程
步驟一:新建離線同步節點
創建業務流程。詳情請參見:創建業務流程。
創建離線同步節點。
你可以通過以下兩種方式創建離線同步節點:
方式一:展開業務流程,右鍵單擊。
方式二:雙擊業務流程名稱,將數據集成目錄下的離線同步節點直接拖拽至右側業務流程編輯面板。
根據界面提示創建離線同步節點。
步驟二:配置同步網絡鏈接
選擇離線同步任務的數據來源和數據去向,以及用于執行同步任務的資源組,并測試連通性。
還支持同步源端分庫分表數據至目標單表,詳情請參見:場景:配置分庫分表離線同步任務。
若數據源與資源組網絡不通,請參考界面提示或文檔進行網絡連通配置。詳情請參見:網絡連通方案。
步驟三:配置數據來源與去向
在選擇數據源區域,配置任務讀取與寫入的表,及同步的數據范圍。
各插件配置存在一定差異,以下內容僅以常見配置為例進行說明,各插件是否支持相關配置以及配置的具體實現,請以具體插件配置文檔為準。詳情請參見支持的數據源與讀寫插件。
讀取端
操作
說明
配置同步范圍
當您在數據過濾文本框配置過濾條件時,執行同步任務時將只同步滿足過濾條件的數據。同時,過濾條件可以結合調度參數使用,實現過濾條件隨任務調度時間的動態變化,進而實現增量數據的同步。不同插件增量同步配置與實現方式不同,關于增量數據同步配置詳情請參見:場景:配置增量數據離線同步任務。
說明在數據過濾和目標表相關配置中定義的變量,當單擊下一步,配置調度屬性時,您可以為此處定義的變量賦值。實現增量或全量數據寫入目標表對應時間分區等功能,關于調度參數的使用詳情請參見:調度參數支持的格式。
增量同步過濾條件的語法與數據庫語法基本一致,同步時,離線同步將拼接為完整SQL向對應數據源抽取數據。
當不配置數據過濾條件時,默認同步該表全量數據。
關系型數據庫配置切分鍵
定義將源端待同步數據基于源端哪一個字段進行切分,同步任務執行時將根據該字段切分為多個task,以便并發、分批讀取數據。
說明推薦splitPk用戶使用表主鍵,因為表主鍵通常情況下比較均勻,因此切分出來的分片也不容易出現數據熱點。
目前splitPk僅支持整型數據切分,不支持字符串、浮點和日期等其他類型 。如果您指定其他非支持類型,忽略splitPk功能,使用單通道進行同步。
如果不填寫splitPk,包括不提供splitPk或者splitPk值為空,數據同步視作使用單通道同步該表數據 。
并非所有插件均支持指定切分鍵配置任務切分邏輯,以上僅為示例,請以具體插件說明為準。詳情請參見支持的數據源與讀寫插件。
寫入端
操作
說明
配置同步前后執行語句
部分數據源支持在同步前(數據寫入目標端數據源前)與同步完成后(數據寫入目標端后),在目標端執行相關數據庫SQL。
示例:MySQL Writer支持配置preSql與postSql,即在數據寫入MySQL前或后,可以執行一些MySQL命令。例如在MySQL Writer端導入前準備語句(preSql)配置項中配置MySQL清空表命令
truncate table tablename,實現同步前(寫入MySQL數據前)先清空表中的舊數據的操作。定義沖突時的寫入模式
定義路徑或主鍵等場景沖突時以何種方式寫入目標端。該配置根據數據源本身特性及writer插件支持情況,此處配置不同。您需要參考具體writer插件進行配置。
步驟四:配置字段映射關系
選擇數據來源和數據去向后,需要指定讀取端和寫入端列的映射關系,配置字段映射關系后,任務將根據字段映射關系,將源端字段寫入目標端對應類型的字段中。
同步過程中可能存在源端與目標端字段類型不匹配,產生臟數據,導致數據無法正常寫入目標端,同步過程中關于臟數據的容忍條數,請參考下一步通道控制進行配置。
當源端某字段未與目標端字段進行映射時,源端該字段數據將不會同步到目標端。
支持同名映射、同行映射。在使用過程中,您還可以:
為目標字段賦值:通過添加一行的方式,為目標表添加常量、調度參數、內置變量。例如,'123','${調度參數}', '#{內置變量}#' 。
說明當單擊下一步,配置調度時,可以為調度參數賦值。關于調度參數的使用詳情請參見:調度參數支持的格式。
您可以通過手動添加內置變量,映射到目標字段,將內置變量輸出到下游。
各個插件可用內置變量如下:
內置變量
變量說明
支持插件
'#{DATASOURCE_NAME_SRC}#'
來源數據源名稱
MySQL Reader
MySQL(分庫分表) Reader
PolarDB Reader
PolarDB(分庫分表) Reader
PostgreSQL Reader
'#{DB_NAME_SRC}#'
來源表所在的數據庫名稱
MySQL Reader
MySQL(分庫分表) Reader
PolarDB Reader
PolarDB(分庫分表) Reader
PostgreSQL Reader
'#{SCHEMA_NAME_SRC}#'
來源表所在的模式名稱
PolarDB Reader
PolarDB(分庫分表) Reader
PostgreSQL Reader
'#{TABLE_NAME_SRC}#'
來源表名稱
MySQL Reader
MySQL(分庫分表) Reader
PolarDB Reader
PolarDB(分庫分表) Reader
PostgreSQL Reader
編輯源端字段:您可以通過單擊類型右側的
 圖標實現如下功能:
圖標實現如下功能:使用源端數據庫支持的函數,對字段進行函數處理,例如,通過Max(id)控制僅同步最大值。
在字段映射未拉取全部字段的情況下,手動編輯源端字段。
說明MaxCompute Reader暫不支持使用函數。
步驟五:配置通道
您可通過通道配置,控制數據同步過程相關屬性。
參數 | 描述 |
任務期望最大并發數 | 用于定義當前任務從源端并行讀取或并行寫入目標端的最大線程數。 說明
|
同步速率 | 用于控制同步速率。
說明 流量度量值是數據集成本身的度量值,不代表實際網卡流量。通常,網卡流量是通道流量膨脹的1至2倍,實際流量膨脹取決于具體的數據存儲系統傳輸序列化情況。 |
錯誤記錄數控制(臟數據控制) | 用于定義臟數據閾值,及對任務的影響。 重要 當臟數據過多時,會影響同步任務的整體同步速度。
說明 臟數據認定標準:臟數據是對業務沒有意義,格式非法或者同步過程中出現問題的數據。單條數據寫入目標數據源過程中發生了異常,則此條數據為臟數據。 因此只要是寫入失敗的數據均被歸類于臟數據。 例如,源端是VARCHAR類型的數據寫到INT類型的目標列中,則會因為轉換不合理導致臟數據不會成功寫入目的端。您可以在同步任務配置時,控制同步過程中是否允許臟數據產生,并且支持控制臟數據條數,即當臟數據超過指定條數時,任務失敗退出。 |
分布式處理能力 | 用于控制是否開啟分布式模式來執行當前任務。
如果您對于同步性能有比較高的訴求可以使用分布式模式。 另外分布式模式也可以使用機器的碎片資源,對資源利用率友好。 重要
|
任務整體同步速度除受到上述配置影響外,還受源端數據源性能,同步網絡環境等多方面影響,關于同步速率說明與調優,詳情請參見離線同步提速或限速。
步驟六:配置調度屬性
周期性調度的離線同步任務需要配置任務自動調度時的相關屬性,此步驟為您介紹如何配置調度相關屬性。您可以進入離線同步節點的編輯頁面,單擊右側的調度配置,下文將為您介紹如何在同步任務中配置節點調度屬性。調度參數使用說明請參見數據集成使用調度參數的相關說明。
配置節點調度屬性:用于為任務配置階段使用的變量賦值調度參數,您在上述配置中定義的變量均可以在此處進行賦值,支持賦值常量與變量。
時間屬性配置說明:用于定義任務在生產環境的周期調度方式。您可以在調度配置的時間屬性區域,配置任務生成周期實例的方式、調度類型、調度周期等屬性。
配置資源屬性:用于定義調度場景下,將當前任務下發至數據集成任務執行資源時所使用的調度資源組,您可以在調度配置的資源屬性區域,選擇任務調度運行時需要使用的資源組。
說明數據集成離線任務通過調度資源組下發至對應的數據集成任務執行資源組上運行,會產生調度相關費用,關于任務下發機制說明,請參見DataWorks資源組概述。
步驟七:提交并發布任務
若任務需要進行周期性調度運行,您需要將任務發布至生產環境。關于任務發布,詳情請參見:發布任務。
后續步驟
任務發布至生產環境后,您可進入生產環境運維中心查看該調度任務,關于離線同步任務的運行與管理、狀態監控、資源組運維等操作詳情請參見:離線同步任務運維。