Kafka插件基于Kafka SDK實時讀取Kafka數據。
背景信息
支持阿里云Kafka,以及>=0.10.2且<=2.2.x的自建Kafka版本。
對于<0.10.2版本Kafka,由于Kafka不支持檢索分區數據offset,且Kafka數據結構可能不支持時間戳,因此會引發同步任務延時統計錯亂,造成無法正確重置同步位點。
kafka數據源配置詳情請參考:配置Kafka數據源。
操作步驟
進入數據開發頁面。
登錄DataWorks控制臺,切換至目標地域后,單擊左側導航欄的,在下拉框中選擇對應工作空間后單擊進入數據開發。
鼠標懸停至
 圖標,單擊。
圖標,單擊。 您也可以展開業務流程,右鍵單擊目標業務流程,選擇。
在新建節點對話框中,選擇同步方式為單表(Topic)到單表(Topic)ETL,輸入名稱,并選擇路徑。
重要節點名稱必須是大小寫字母、中文、數字、下劃線(_)以及英文句號(.),且不能超過128個字符。
單擊確認。
在實時同步節點的編輯頁面,鼠標單擊并拖拽至編輯面板。
單擊Kafka節點,在節點配置對話框中,配置各項參數。
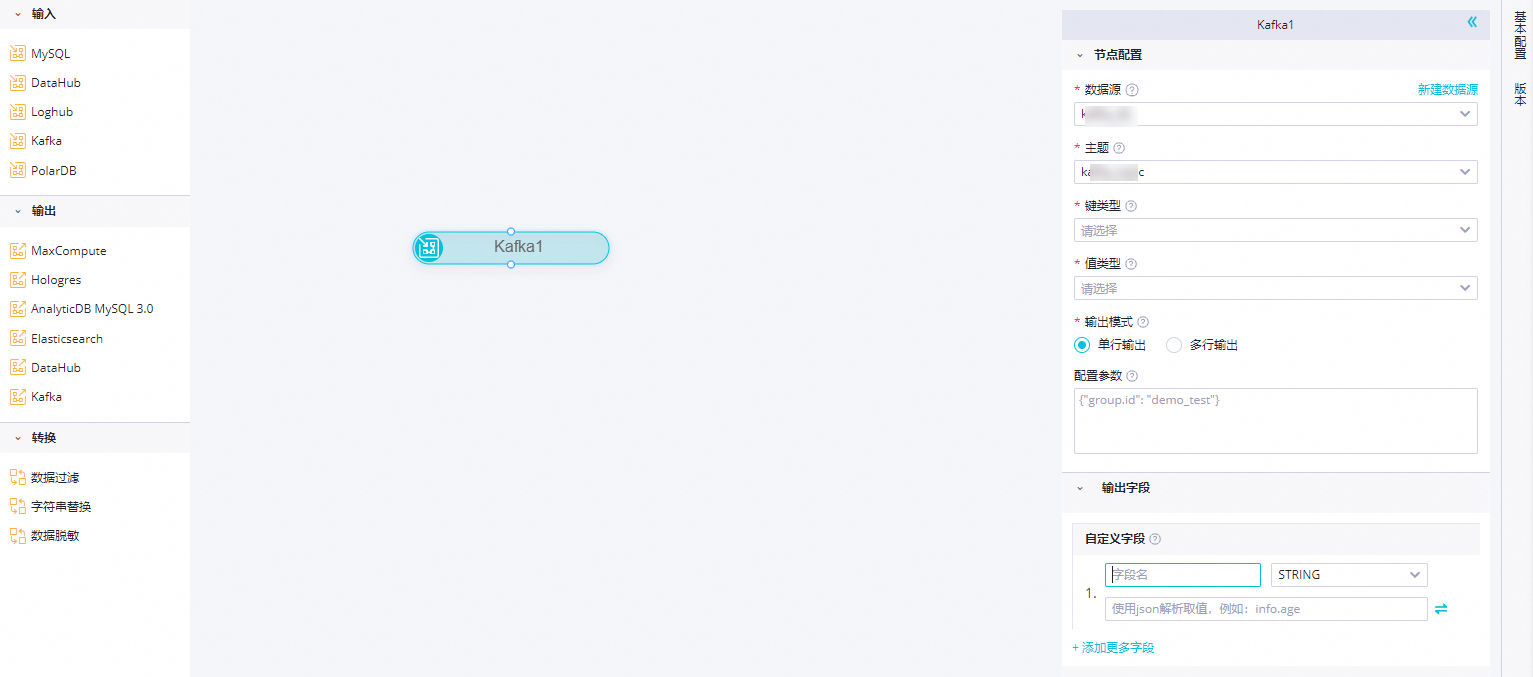
參數
描述
數據源
選擇已經配置好的Kafka數據源,此處僅支持Kafka數據源。如果未配置數據源,請單擊右側的新建數據源,跳轉至 頁面進行新建。詳情請參見:配置Kafka數據源。
主題
Kafka的Topic名稱,是Kafka處理資源的消息源的不同分類。
每條發布至Kafka集群的消息都有一個類別,該類別被稱為Topic,一個Topic是對一組消息的歸納。
說明一個Kafka輸入僅支持一個Topic。
鍵類型
Kafka的Key的類型,決定了初始化KafkaConsumer時的key.deserializer配置,可選值包括STRING、BYTEARRAY、DOUBLE、FLOAT、INTEGER、LONG和SHORT。
值類型
Kafka的Value的類型,決定了初始化KafkaConsumer時的value.deserializer配置,可選值包括STRING、BYTEARRAY、DOUBLE、FLOAT、INTEGER、LONG和SHORT。
輸出模式
定義解析kafka記錄的方式
單行輸出:以無結構字符串或者JSON對象解析kafka記錄,一個kafka記錄解析出一個輸出記錄。
多行輸出:以JSON數組解析Kafka記錄,一個JSON數組元素解析出一個輸出記錄,因此一個Kafka記錄可能解析出多個輸出記錄。
說明目前只在部分地域支持該配置項,如發現無該配置項請耐心等待功能在對應地域發布。
數組所在位置路徑
當輸出模式設置為多行輸出時,指定JSON數組在kafka記錄value中的路徑,路徑支持以
a.a1的格式引用特定JSON對象中的字段或者以a[0].a1的格式引用特定JSON數組中的字段,如果該配置項為空,則將整個kafka記錄value作為一個JSON數組解析。注意解析的目標JSON數組必須是對象數組,例如
[{"a":"hello"},{"b":"world"}],不能是數值或字符串數組,例如["a","b"]。配置參數
創建Kafka數據消費客戶端KafkaConsumer 可以指定擴展參數,例如,bootstrap.servers、auto.commit.interval.ms、session.timeout.ms等,各版本Kafka集群支持的KafkaConsumer 參數可以參考Kafka官方文檔,您可以基于kafkaConfig控制KafkaConsumer讀取數據的行為。實時同步Kafka輸入節點,KafkaConsumer默認使用隨機字符串設置
group.id,如果希望同步位點上傳到Kafka集群指定群組,可以在配置參數中手動指定group.id。實時同步Kafka輸入節點不依賴Kafka服務端維護的群組信息管理位點,所以對配置參數中group.id的設置不會影響同步任務啟動、重啟、Failover等場景下的讀取位點。輸出字段
您可以自定義Kafka數據對外輸出的字段名:
單擊添加更多字段,輸入字段名,并選擇類型,即可新增自定義字段。
取值方式支持從kafka記錄中取得字段值的方式,單擊右側
 按鈕可以在兩類取值方式間切換。
按鈕可以在兩類取值方式間切換。預置取值方式:提供6種可選預置從kafka記錄中取值的方式:
value:消息體
key:消息鍵
partition:分區號
offset:偏移量
timestamp:消息的毫秒時間戳
headers:消息頭
JSON解析取值:可以通過.(獲取子字段)和[](獲取數組元素)兩種語法,獲取復雜JSON格式的內容,同時為了兼容歷史邏輯,支持在選擇JSON解析取值時使用例如__value__這樣以兩個下劃線開頭的字符串獲取kafka記錄的特定內容作為字段值。Kafka的數據示例如下。
{ "a": { "a1": "hello" }, "b": "world", "c":[ "xxxxxxx", "yyyyyyy" ], "d":[ { "AA":"this", "BB":"is_data" }, { "AA":"that", "BB":"is_also_data" } ] }不同情況下,輸出字段的取值為:
如果同步Kafka記錄value,取值方式填寫__value__。
如果同步Kafka記錄key,取值方式填寫__key__。
如果同步Kafka記錄partition,取值方式填寫__partition__。
如果同步Kafka記錄offset,取值方式填寫__offset__。
如果同步Kafka記錄timestamp,取值方式填寫__timestamp__。
如果同步Kafka記錄headers,取值方式填寫__headers__。
如果同步a1的數據"hello",取值方式填寫a.a1。
如果同步b的數據"world,取值方式填寫b。
如果同步c的數據"yyyyyyy",取值方式填寫c[1]。
如果同步AA的數據"this",取值方式填寫d[0].AA。
鼠標懸停至相應字段,單擊顯示的
 圖標,即可刪除該字段。
圖標,即可刪除該字段。
場景示例:在輸出模式選擇多行輸出情況下,將先根據數組所在位置路徑指定的JSON路徑解析出JSON數組,然后取出JSON數組中的每一個JSON對象,再根據定義的字段名和取值方式解析組成輸出字段,取值方式的定義與單行輸出模式一樣,可以通過.(獲取子字段)和[](獲取數組元素)兩種語法,獲取復雜JSON格式的內容。Kafka實例數據如下:
{ "c": { "c0": [ { "AA": "this", "BB": "is_data" }, { "AA": "that", "BB": "is_also_data" } ] } }當數組所在位置路徑填寫
c.c0,輸出字段定義兩個字段,一個字段名為AA,取值方式為AA,一個字段名為BB,取值方式為BB,那么該條Kafka記錄將解析得到如下兩條記錄:
單擊工具欄中的
 圖標。說明
圖標。說明一個Kafka輸入僅支持一個Topic。