離線同步并發(fā)和限流之間的關(guān)系
本文可以幫助您理解和配置任務(wù)通道控制參數(shù),降低誤配的數(shù)量和答疑。本文將為您介紹離線同步并發(fā)和限流之間的關(guān)系。
實(shí)踐內(nèi)容
并發(fā)數(shù)
閱讀此部分,您可以解決和理解如下問題:
問題一:如何配置數(shù)據(jù)同步任務(wù)的并發(fā)數(shù)?
問題二:為什么我的數(shù)據(jù)同步任務(wù)跑的比較慢,實(shí)際運(yùn)行的并發(fā)數(shù)不夠?
問題三:為什么我的同步任務(wù)并發(fā)數(shù)配置的很高,但是任務(wù)運(yùn)行速度仍然很慢,為什么我的獨(dú)享資源組經(jīng)常等待資源?
并發(fā)數(shù)是指數(shù)據(jù)同步任務(wù)中,可以從源端并行讀取和向目標(biāo)存儲(chǔ)端并行寫出數(shù)據(jù)的最大線程數(shù)。為了提高數(shù)據(jù)同步的效率,可以適當(dāng)調(diào)整任務(wù)的并發(fā)數(shù),以縮短數(shù)據(jù)搬遷需要的時(shí)間。在產(chǎn)品中配置位置如圖所示: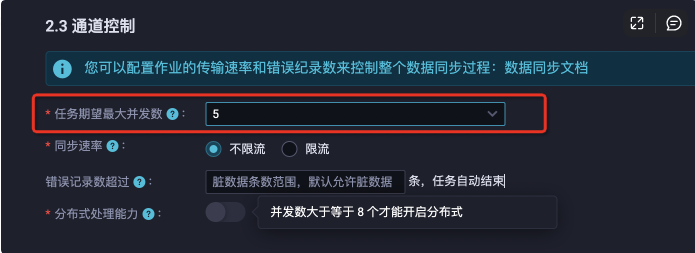 文件類型(OSS、FTP、HDFS、S3)數(shù)據(jù)讀取,主要基于文件粒度并發(fā)讀取,待讀取的文件數(shù)量少于任務(wù)配置并發(fā)數(shù)。上面任務(wù)期望最大并發(fā)數(shù):即是任務(wù)配置的并發(fā)數(shù),由于數(shù)據(jù)集成資源組或者任務(wù)本身特性等原因,任務(wù)實(shí)際執(zhí)行的并發(fā)數(shù)可能小于等于任務(wù)配置并發(fā)數(shù),如涉及任務(wù)并發(fā)數(shù)計(jì)費(fèi)場景(數(shù)據(jù)集成調(diào)試資源組)會(huì)按照任務(wù)實(shí)際并發(fā)數(shù)計(jì)費(fèi)。數(shù)據(jù)集成會(huì)嘗試保障任務(wù)執(zhí)行并發(fā)數(shù)符合配置并發(fā)數(shù),常見的任務(wù)實(shí)際執(zhí)行并發(fā)數(shù)小于配置并發(fā)數(shù)的場景有:
文件類型(OSS、FTP、HDFS、S3)數(shù)據(jù)讀取,主要基于文件粒度并發(fā)讀取,待讀取的文件數(shù)量少于任務(wù)配置并發(fā)數(shù)。上面任務(wù)期望最大并發(fā)數(shù):即是任務(wù)配置的并發(fā)數(shù),由于數(shù)據(jù)集成資源組或者任務(wù)本身特性等原因,任務(wù)實(shí)際執(zhí)行的并發(fā)數(shù)可能小于等于任務(wù)配置并發(fā)數(shù),如涉及任務(wù)并發(fā)數(shù)計(jì)費(fèi)場景(數(shù)據(jù)集成調(diào)試資源組)會(huì)按照任務(wù)實(shí)際并發(fā)數(shù)計(jì)費(fèi)。數(shù)據(jù)集成會(huì)嘗試保障任務(wù)執(zhí)行并發(fā)數(shù)符合配置并發(fā)數(shù),常見的任務(wù)實(shí)際執(zhí)行并發(fā)數(shù)小于配置并發(fā)數(shù)的場景有:
關(guān)系數(shù)據(jù)庫(如MySQL、Polardb、SQLServer、PostgreSQL、Oracle等等)讀取,沒有配置切分鍵splitPk(切分列支持整型數(shù)字類型,Oracle在整型之外額外支持時(shí)間類型)或切分鍵配置無效,導(dǎo)致任務(wù)無法將數(shù)據(jù)表數(shù)據(jù)拆分,進(jìn)而無法并行數(shù)據(jù)讀取。
PolarDB-X(DRDS)是基于邏輯表的物理拓?fù)溥M(jìn)行分片拆分讀取,物理分表數(shù)少于任務(wù)配置并發(fā)數(shù)。
文件類型(OSS、FTP、HDFS、S3)數(shù)據(jù)讀取,主要基于文件粒度并發(fā)讀取,待讀取的文件數(shù)量少于任務(wù)配置并發(fā)數(shù)。
在源端數(shù)據(jù)分布極不均衡的場景,會(huì)導(dǎo)致部分?jǐn)?shù)據(jù)分片執(zhí)行耗時(shí)較久(其他分片已經(jīng)完成傳輸),在任務(wù)執(zhí)行后期階段任務(wù)實(shí)際并發(fā)數(shù)會(huì)少于配置并發(fā)數(shù)。
任務(wù)并發(fā)數(shù)配置最佳實(shí)踐:
任務(wù)并發(fā)數(shù)越大,任務(wù)運(yùn)行需要搶占的資源越多,DataWorks數(shù)據(jù)集成任務(wù)的資源隊(duì)列是FIFO(先進(jìn)先出),即前面提交任務(wù)先搶占資源運(yùn)行,后提交的任務(wù)后搶占資源運(yùn)行。建議您合理配置任務(wù)并發(fā)數(shù),避免大并發(fā)任務(wù)長時(shí)間運(yùn)行,進(jìn)而阻塞后續(xù)任務(wù)獲得資源得到執(zhí)行。
小數(shù)據(jù)量的數(shù)據(jù)表建議配置小并發(fā),小并發(fā)需要的執(zhí)行資源比較少,有利于任務(wù)快速搶占碎片資源得到運(yùn)行。由于數(shù)據(jù)量比較小執(zhí)行耗時(shí)可以控制在合理的范圍內(nèi)。
同一個(gè)數(shù)據(jù)源上同步任務(wù),建議錯(cuò)峰運(yùn)行,一方面可以均衡資源組的使用水位,另外也可以降低對數(shù)據(jù)源訪問的并發(fā)壓力。
同步速率
閱讀此部分,您可以解決和理解如下問題:
問題一:如何配置數(shù)據(jù)同步速率,如何理解任務(wù)限速、或不限速?
問題二:為什么有時(shí)候數(shù)據(jù)同步限速不生效?
問題三:為什么數(shù)據(jù)同步任務(wù)運(yùn)行速率有時(shí)候相較限速閾值有較大差距?
同步速率:數(shù)據(jù)同步速率和任務(wù)期望最大并發(fā)數(shù)是比較強(qiáng)相關(guān)的參數(shù),兩者結(jié)合在一起可以保護(hù)數(shù)據(jù)來源和數(shù)據(jù)去向端的讀寫壓力,以避免數(shù)據(jù)同步任務(wù)對數(shù)據(jù)源帶來較大壓力,影響數(shù)據(jù)源的穩(wěn)定性。
同步速率(不限流)是指按照用戶配置的任務(wù)期望最大并發(fā)數(shù)執(zhí)行任務(wù)(假設(shè)實(shí)際運(yùn)行并發(fā)為ActualConcurrent),每個(gè)并發(fā)分片執(zhí)行則不做限速(假設(shè)分片實(shí)際執(zhí)行速度為Speed),則任務(wù)實(shí)際執(zhí)行的總體速度為ActualConcurrent * Speed。在不限流的情況下,數(shù)據(jù)集成會(huì)提供現(xiàn)有任務(wù)配置(并發(fā)、內(nèi)存)、硬件環(huán)境(數(shù)據(jù)源規(guī)格、網(wǎng)絡(luò)、)下最大的傳輸性能。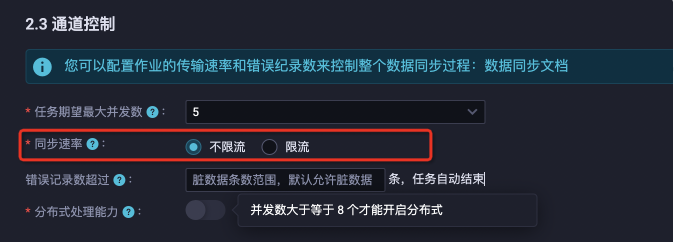
同步速率(限流)是指按照用戶配置的作業(yè)整體速度限制、以及任務(wù)最大并發(fā)數(shù)來運(yùn)行任務(wù)。數(shù)據(jù)集成在編排執(zhí)行計(jì)劃時(shí),每個(gè)并發(fā)分片的速率是(作業(yè)速率 / 作業(yè)并發(fā)數(shù),計(jì)算的分片速度向上取整),分片限速下限是 1MB/s。故任務(wù)實(shí)際運(yùn)行的速率上限是任務(wù)實(shí)際并發(fā)數(shù) * 每個(gè)分片的實(shí)際限速。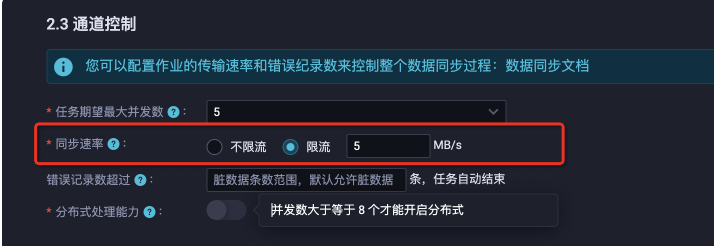 針對限流場景,舉幾個(gè)常見案例介紹如下:
針對限流場景,舉幾個(gè)常見案例介紹如下:
用戶配置并發(fā)數(shù)為5,任務(wù)限速為5MB/s,則任務(wù)會(huì)嘗試切分為5個(gè)分片并發(fā)執(zhí)行,每個(gè)分片執(zhí)行限制速率為1MB/s。
如果任務(wù)實(shí)際并發(fā)為5,則作業(yè)的最終速度上限為5MB/s,小于等于任務(wù)速度上限。
任務(wù)實(shí)際執(zhí)行并發(fā)受限于數(shù)據(jù)源具體情況,實(shí)際并發(fā)可能小于配置5并發(fā)(請參見:任務(wù)期望最大并發(fā)數(shù))。如果實(shí)際運(yùn)行并發(fā)為1,則作業(yè)的最終速度上限為1MB/s,小于等于任務(wù)速度上限。
用戶配置并發(fā)數(shù)為5,任務(wù)限速為3MB/s,則任務(wù)會(huì)嘗試切分為5個(gè)分片并發(fā)執(zhí)行,每個(gè)分片執(zhí)行速率為3 / 5 向上取整為1MB/s。
如果任務(wù)實(shí)際執(zhí)行并發(fā)為5,則作業(yè)的最終速度上限為 5MB/s,超出任務(wù)速度上限。
如果任務(wù)實(shí)際執(zhí)行并發(fā)為1,則作業(yè)的最終速度上限為 1MB/s,小于等于任務(wù)速度上限。
用戶配置并發(fā)數(shù)為5,任務(wù)限速為10MB/s,則任務(wù)會(huì)嘗試切分為5個(gè)分片并發(fā)執(zhí)行,每個(gè)分片執(zhí)行速率為10 / 5為2MB/s。
如果任務(wù)實(shí)際執(zhí)行并發(fā)為5,則作業(yè)的最終速度上限為10MB/s,小于等于任務(wù)速度上限。
如果任務(wù)實(shí)際執(zhí)行并發(fā)為1,則作業(yè)的最終速度上限為2MB/s,小于等于任務(wù)速度上限。
分布式處理能力
閱讀此部分,您可以解決和理解如下問題:
問題一:什么場景下需要配置分布式模式運(yùn)行同步作業(yè)?
問題二:為什么使用分布式模式運(yùn)行同步作業(yè),任務(wù)速率還是跑的慢?
不開啟分布式時(shí),配置的并發(fā)數(shù)僅僅是單機(jī)上的進(jìn)程并發(fā),無法利用多機(jī)聯(lián)合計(jì)算。分布式執(zhí)行模式可以將您的任務(wù)切片分散到多臺(tái)執(zhí)行節(jié)點(diǎn)上并發(fā)執(zhí)行,進(jìn)而做到同步速度隨執(zhí)行集群規(guī)模做水平擴(kuò)展,突破單機(jī)執(zhí)行瓶頸。如果您對于同步性能有比較高的訴求可以使用分布式模式,另外分布式模式也可以使用機(jī)器的碎片資源,對資源利用率友好。
限制和最佳實(shí)踐:
分布式執(zhí)行模式下,配置較大任務(wù)并發(fā)度可能會(huì)對您的數(shù)據(jù)存儲(chǔ)產(chǎn)生較大的訪問壓力,請?jiān)u估數(shù)據(jù)存儲(chǔ)的訪問負(fù)載。
如果您的獨(dú)享資源組機(jī)器臺(tái)數(shù)為1,不建議使用分布式執(zhí)行模式,因?yàn)閳?zhí)行進(jìn)程仍然分布在一臺(tái)Worker節(jié)點(diǎn)上,無法最大化享受分布式多機(jī)的好處。
小數(shù)據(jù)量的同步任務(wù),不建議配置分布式,建議配置單機(jī)小并發(fā)任務(wù)。
并發(fā)數(shù)大于等于8個(gè)才能開啟分布式。
臟數(shù)據(jù)限制
閱讀此部分,您可以解決和理解如下問題:
問題一:什么是數(shù)據(jù)同步的臟數(shù)據(jù)?
問題二:如何配置數(shù)據(jù)同步任務(wù)臟數(shù)據(jù)限制?
問題三:數(shù)據(jù)同步速率和臟數(shù)據(jù)有哪些關(guān)聯(lián)關(guān)系?
臟數(shù)據(jù)限制能力用來控制任務(wù)在遇到臟數(shù)據(jù)時(shí)的行為,所謂臟數(shù)據(jù)是指數(shù)據(jù)條目在寫入目標(biāo)數(shù)據(jù)源過程中發(fā)生了異常,則此條數(shù)據(jù)被視為臟數(shù)據(jù)。由于各類異構(gòu)系統(tǒng)對數(shù)據(jù)處理的復(fù)雜和差異性,目前策略是寫入失敗的數(shù)據(jù)均被歸類于臟數(shù)據(jù)。在一些數(shù)據(jù)同步場景,臟數(shù)據(jù)的出現(xiàn)會(huì)導(dǎo)致任務(wù)同步效率下降,以關(guān)系數(shù)據(jù)庫寫出為例,默認(rèn)是執(zhí)行batch批量寫出模式,在遇到臟數(shù)據(jù)時(shí)會(huì)退化為單條寫出模式(以找出batch批次數(shù)據(jù)具體哪一條是臟數(shù)據(jù),保障正常數(shù)據(jù)正常寫出),但單條寫出效率會(huì)遠(yuǎn)低于batch寫出模式,故遇到大量臟數(shù)據(jù)時(shí)會(huì)拖慢任務(wù)運(yùn)行的最終效率。
目前數(shù)據(jù)集成絕大多數(shù)通道支持臟數(shù)據(jù)閾值限制能力,對于支持臟數(shù)據(jù)閾值限制的通道,常見配置場景介紹如下:
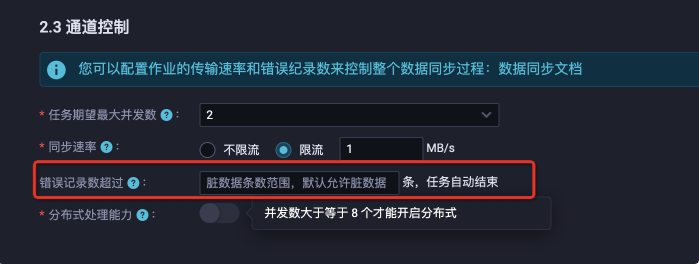
不配置臟數(shù)據(jù)限制:表示容忍所有出現(xiàn)的臟數(shù)據(jù),遇到臟數(shù)據(jù)不會(huì)導(dǎo)致任務(wù)失敗,任務(wù)配置errorLimit留空。
配置臟數(shù)據(jù)限制為0:表示不容忍任何臟數(shù)據(jù),在出現(xiàn)超出1條臟數(shù)據(jù)時(shí),任務(wù)會(huì)失敗退出。
配置臟數(shù)據(jù)限制為一個(gè)正整數(shù)N:表示最多容忍N(yùn)條臟數(shù)據(jù),在臟數(shù)據(jù)超過N條時(shí),任務(wù)會(huì)失敗退出。
最佳實(shí)踐:
關(guān)系數(shù)據(jù)庫(MySQL、SQL Server、PostgreSQL、Oracle、Polardb、Polardb-X等)、Hologres、ClickHouse、AnalyticDB for MySQL等對于數(shù)據(jù)要求比較敏感的場景,建議配置臟數(shù)據(jù)限制為0,以及時(shí)發(fā)現(xiàn)數(shù)據(jù)質(zhì)量風(fēng)險(xiǎn)。
對于數(shù)據(jù)要求不敏感的場景,建議不配置臟數(shù)據(jù)限制,或者配置一個(gè)業(yè)務(wù)上合理的臟數(shù)據(jù)閾值上限,以降低您日常臟數(shù)據(jù)處理運(yùn)維負(fù)擔(dān)。
關(guān)鍵任務(wù)配置任務(wù)失敗和延遲告警,以及時(shí)發(fā)現(xiàn)線上問題。
可重跑的任務(wù)建議配置任務(wù)失敗自動(dòng)重跑,以降低偶發(fā)環(huán)境問題對任務(wù)的影響。
數(shù)據(jù)源連接數(shù)Quota限制
閱讀此部分,您可以解決和理解如下問題:
問題一:什么是數(shù)據(jù)源連接數(shù)(Quota)限制,以及如何合理配置連接數(shù)限制?
問題二:為什么數(shù)據(jù)同步解決方案中的離線全量任務(wù)跑的慢,長時(shí)間任務(wù)處于Submit狀態(tài)?
數(shù)據(jù)源連接數(shù)限制功能,是指:
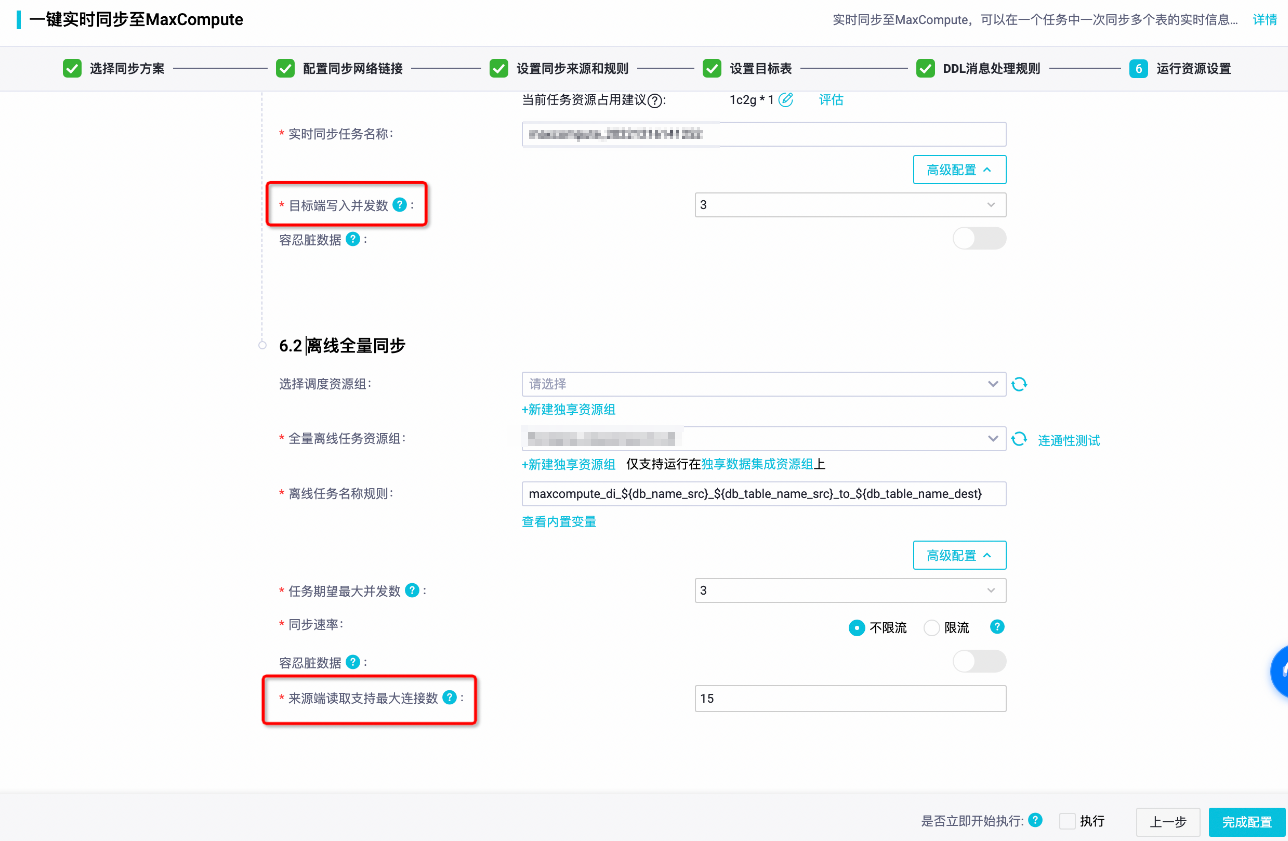
目標(biāo)端寫入并發(fā)數(shù):在實(shí)時(shí)數(shù)據(jù)同步任務(wù)內(nèi),向目標(biāo)端寫入數(shù)據(jù)的最大線程數(shù)。需要根據(jù)資源組大小和目標(biāo)端實(shí)際規(guī)模合理設(shè)置。目前可配置的上限為32,默認(rèn)值為3。
來源端讀取支持最大連接數(shù):同步解決方案的離線全量數(shù)據(jù)初始化階段,會(huì)基于JDBC建立到數(shù)據(jù)庫連接并讀取全量歷史數(shù)據(jù)。此連接數(shù)即用來控制數(shù)據(jù)來源端支持的最大JDBC連接數(shù),避免大量任務(wù)同時(shí)啟動(dòng)打滿數(shù)據(jù)庫連接池,影響數(shù)據(jù)庫的穩(wěn)定性。請根據(jù)數(shù)據(jù)庫資源的實(shí)際情況合理配置,默認(rèn)為15。如果您發(fā)現(xiàn)任務(wù)長時(shí)間處于Submit狀態(tài),一般是因?yàn)閿?shù)據(jù)源最大連接數(shù)限制導(dǎo)致(可以嘗試任務(wù)錯(cuò)峰運(yùn)行、評(píng)估增加最大連接數(shù)限制)。
數(shù)據(jù)源連接數(shù)Quota限制,功能入口(數(shù)據(jù)同步解決方案)如下圖所示: