創(chuàng)建同步MaxCompute
同步數(shù)據(jù)到MaxCompute
準備工作
1.創(chuàng)建MaxCompute表
DataHub支持將數(shù)據(jù)同步到MaxCompute對應的數(shù)據(jù)表中,同時支持分區(qū)表和非分區(qū)表,一般情況下推薦用戶使用分區(qū)表進行數(shù)據(jù)同步以方便MaxCompute數(shù)據(jù)處理。
目前DataHub支持將TUPLE和BLOB的數(shù)據(jù)同步到MaxCompute數(shù)據(jù)表中。
1)針對TUPLE類型topic,MaxCompute目標表數(shù)據(jù)類型需要和DataHub數(shù)據(jù)類型相匹配,具體的數(shù)據(jù)類型映射關系如下:
MaxCompute | DataHub |
BIGINT | BIGINT |
STRING | STRING |
BOOLEAN | BOOLEAN |
DOUBLE | DOUBLE |
DATETIME | TIMESTAMP |
DECIMAL | DECIMAL |
TINYINT | TINIINT |
SMALLINT | SMALLINT |
INT | INTEGER |
FLOAT | FLOAT |
MAP | 不支持 |
ARRAY | 不支持 |
由于目前DataHub并不能完全支持MaxCompute所有的數(shù)據(jù)類型,請用戶盡量根據(jù)DataHub數(shù)據(jù)類型創(chuàng)建MaxCompute表結構。
2)針對BLOB數(shù)據(jù)類型,需要要求MaxCompute表結構僅需要包含一列STRING類型的column即可,DataHub默認會將數(shù)據(jù)同步到該column中。
DataHub | MaxCompute |
BLOB | STRING |
3)同時為了方便數(shù)據(jù)追蹤和問題排查,建議用戶在創(chuàng)建MaxCompute表結構時,增加一列__rowkey__ STRING字段,DataHub會自動將DataHub對應數(shù)據(jù)的trace信息同步到該列中,以方便后續(xù)數(shù)據(jù)排查。
2.準備同步任務賬號并授權
1)新建同步MaxCompute任務時,需要用戶手動填寫訪問MaxCompute表的賬號信息,請用戶確保填入有效的賬號信息(一般情況下采用MaxCompute子賬號即可)。
2)需要給該賬號授予訪問MaxCompute表的響應權限,具體權限包括CreateInstance、Describe、Alter以及Update權限。
用戶可以使用DataWorks管控臺進行MaxCompute對應表的權限管理,參考MaxCompute高級配置,也可以選擇使用MaxCompute的命令行工具進行授權,參考MaxCompute使用及授權管理。
3.確認TimestampUnit單位
1) Connector中TimestampUnit的作用,就是將數(shù)據(jù)中TIMESTAMP類型的數(shù)據(jù)(如果有),以TimestampUnit為單位進行轉(zhuǎn)換后寫入到下游系統(tǒng)的日期類型(如datetime類型)。
2)如果TIMESTAMP列寫入的是以秒為單位的值,那新建Connector的時候TimestampUnit就選擇“SECOND”;如果寫入的是以毫秒為單位的值,那就選擇“MILLISECOND”;如果寫入的是以微秒為單位的值,那就選擇“MICROSECOND”
注意事項
由于MaxCompute目前的寫入標準原因,分區(qū)數(shù)越多就會導致DataHub同步數(shù)據(jù)越慢。因此,在創(chuàng)建MaxCompute同步任務時,請盡可能的控制分區(qū)數(shù),尤其是
USER_DEFINE同步模式。同一分區(qū)的數(shù)據(jù)越連續(xù)越好,不要頻繁的分區(qū)跳變。
同步模式控制創(chuàng)建分區(qū)時,請不要創(chuàng)建過多的分區(qū)數(shù)。
創(chuàng)建同步任務
依次進入
項目列表/Project詳情/Topic詳情頁面。點擊右上角的
+ 同步按鈕進行同步任務創(chuàng)建。
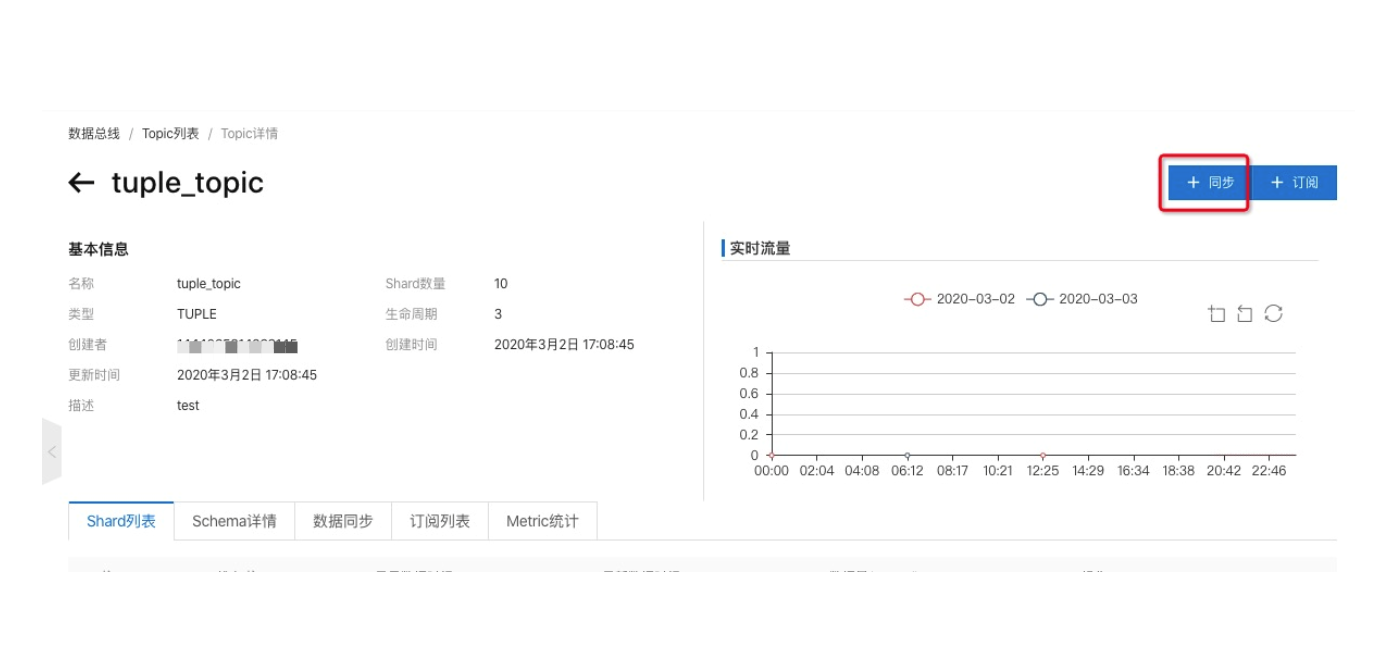
選擇MaxCompute類型作業(yè),如下圖所示:
1)TUPLE類型同步
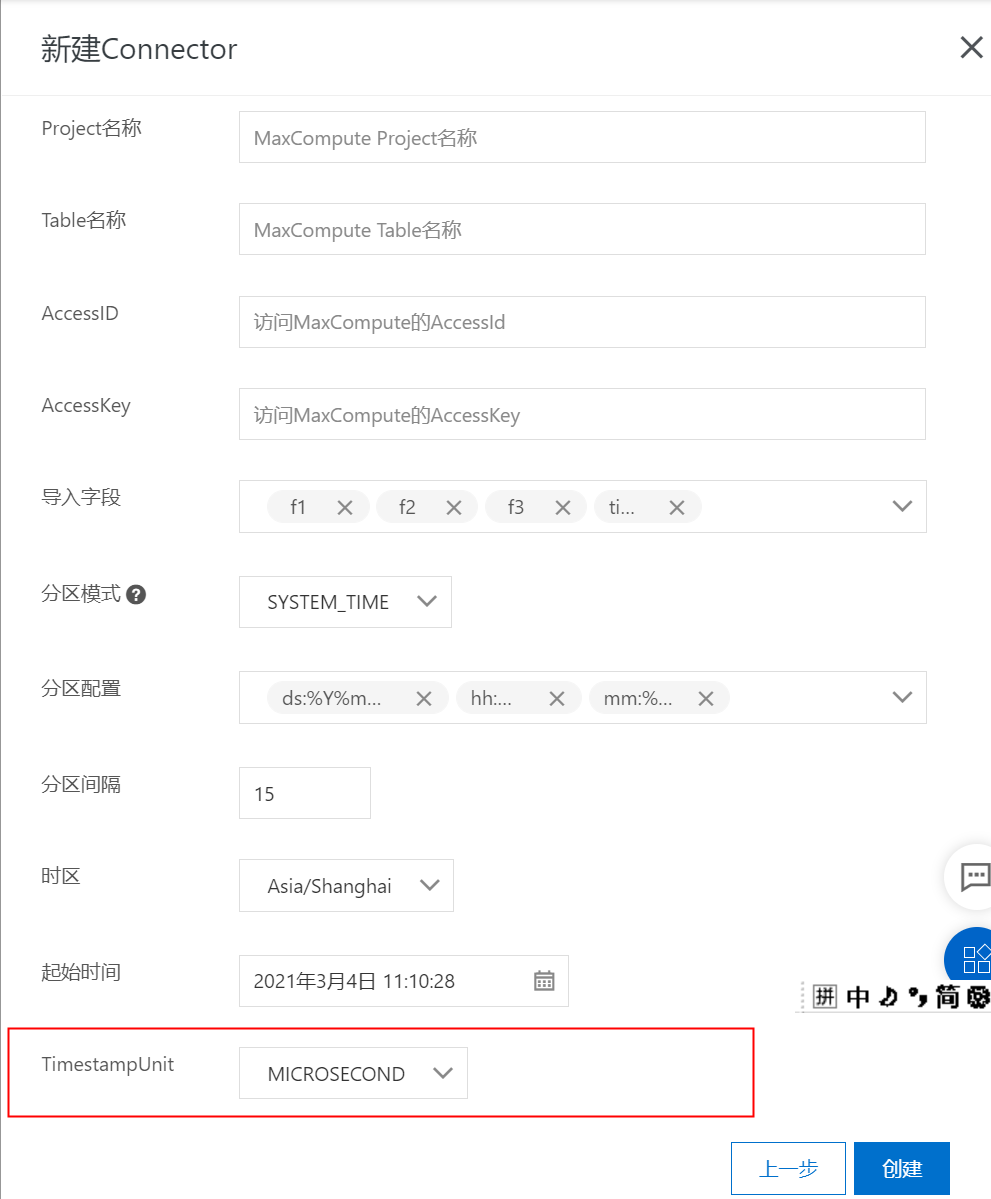 2)BLOB類型同步
2)BLOB類型同步
 部分配置說明:
部分配置說明:
下面羅列了部分管控臺創(chuàng)建同步任務的配置說明,更多更靈活的操作請參考SDK使用。
導入字段
DataHub可以根據(jù)用戶設置將部分column內(nèi)容同步到MaxCompute表中。
分區(qū)模式
分區(qū)模式?jīng)Q定了將數(shù)據(jù)寫入到MaxCompute哪個分區(qū)中,目前DataHub支持以下分區(qū)方式:
分區(qū)模式 | 分區(qū)依據(jù) | 支持Topic類型 | 說明 |
USER_DEFINE | Record中的分區(qū)列(和MaxCompute的分區(qū)字段同名)的value值 | TUPLE | (1). DataHub schema中必須包含MaxCompute分區(qū)字段 (2). 該列值必須為 |
SYSTEM_TIME | Record寫入DataHub的時間 | TUPLE / BLOB | (1). 分區(qū)配置中設置MaxCompute分區(qū)的時間轉(zhuǎn)換Format格式 (2). 設置時區(qū)信息 |
EVENT_TIME | Record中的 | TUPLE | (1). 分區(qū)配置中設置MaxCompute分區(qū)的時間轉(zhuǎn)換Format格式 (2). 設置時區(qū)信息 |
META_TIME | Record的屬性字段 | TUPLE / BLOB | (1). 分區(qū)配置中設置MaxCompute分區(qū)的時間轉(zhuǎn)換Format格式 (2). 設置時區(qū)信息 |
其中SYSTEM_TIME、EVENT_TIME和META_TIME均是根據(jù)時間Timestamp和時區(qū)配置來進行MaxCompute分區(qū)的轉(zhuǎn)換過程,單位默認為微秒。
分區(qū)配置決定了根據(jù)時間戳轉(zhuǎn)換MaxCompute分區(qū)時的相關配置。目前管控臺默認固定的MaxCompute分區(qū)格式,分區(qū)配置對應為
分區(qū) | 時間Format | 說明 |
ds | %Y%m%d | day |
hh | %H | hour |
mm | %M | minute |
分區(qū)間隔決定了根據(jù)時間戳轉(zhuǎn)換MaxCompute分區(qū)時所采用的時間間隔。時間范圍是
15分鐘 ~ 1440分鐘(1天),跳變間隔15分鐘。時區(qū)信息(TimeZone)時區(qū)信息決定了根據(jù)時間戳轉(zhuǎn)換MaxCompute分區(qū)時所采用的轉(zhuǎn)換時區(qū)。
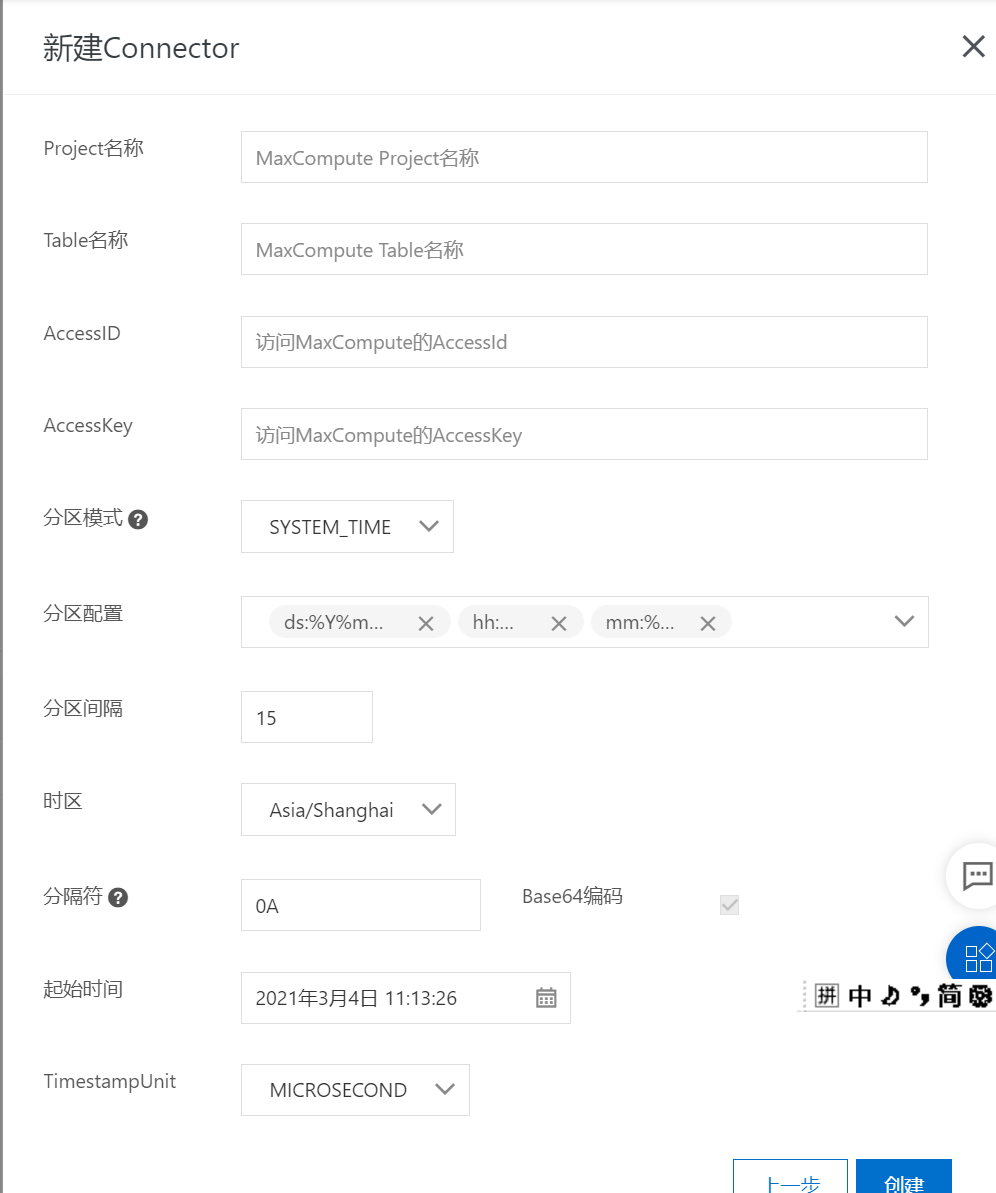
分隔符BLOB數(shù)據(jù)同步時,可以指定16進制分隔符來決定是否對BLOB數(shù)據(jù)分割后再同步MaxCompute,比如
0A表示\n(換行符)。Base64編碼DataHub BLOB默認存儲二進制數(shù)據(jù),而MaxCompute對應的同步列為STRING類型,因此管控臺創(chuàng)建同步任務時,默認采用base64編碼后進行同步,更多定制化需求請參考SDK實現(xiàn)。
查看同步任務
可以點擊對應connector的詳情頁面查看同步任務的運行狀態(tài)和點位等信息, 包含同步點位、同步狀態(tài)以及重啟和停止等操作,如下圖所示: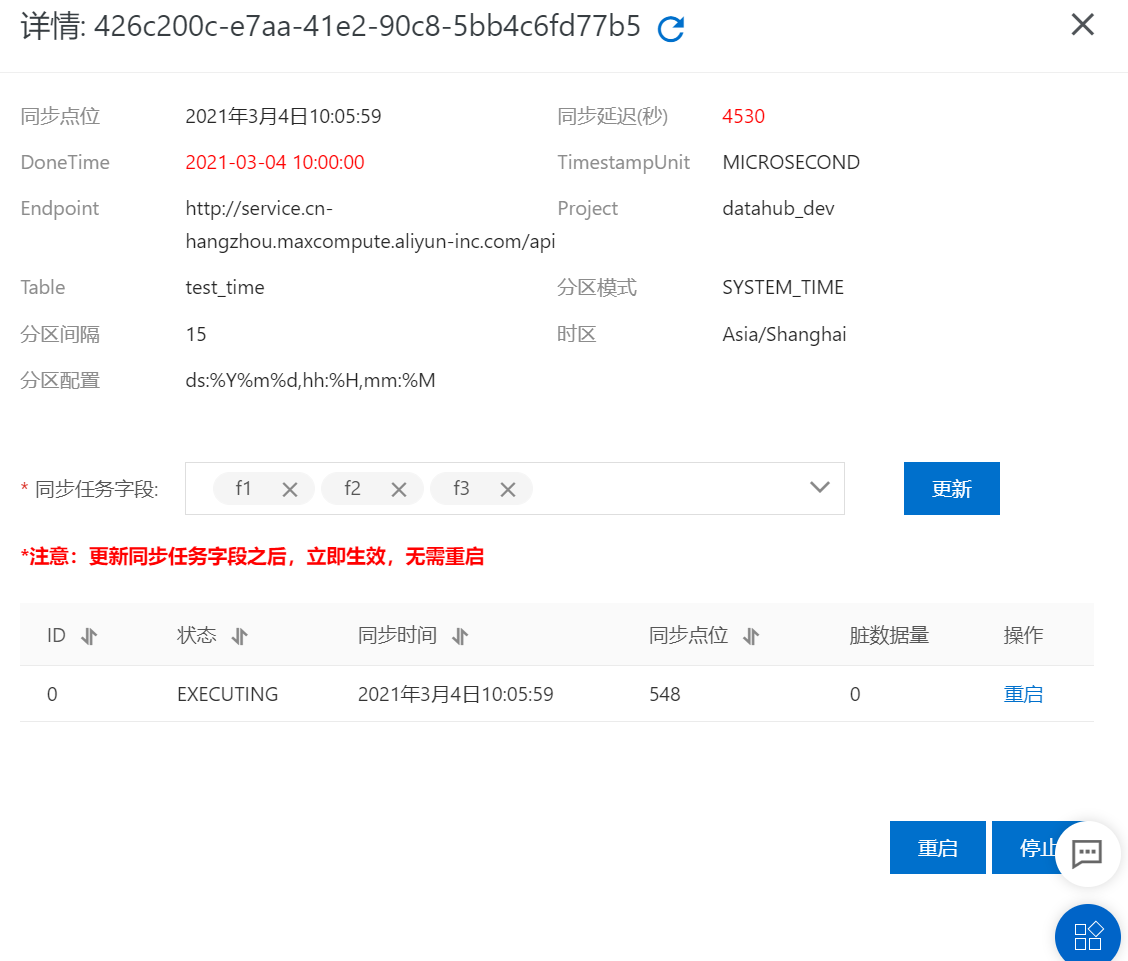
同步示例
1. USER_DEFINE同步模式
建立DataHub Topic
備注: topic schema中必須需要包含MaxCompute分區(qū)字段,類型為STRING,如下圖所示:
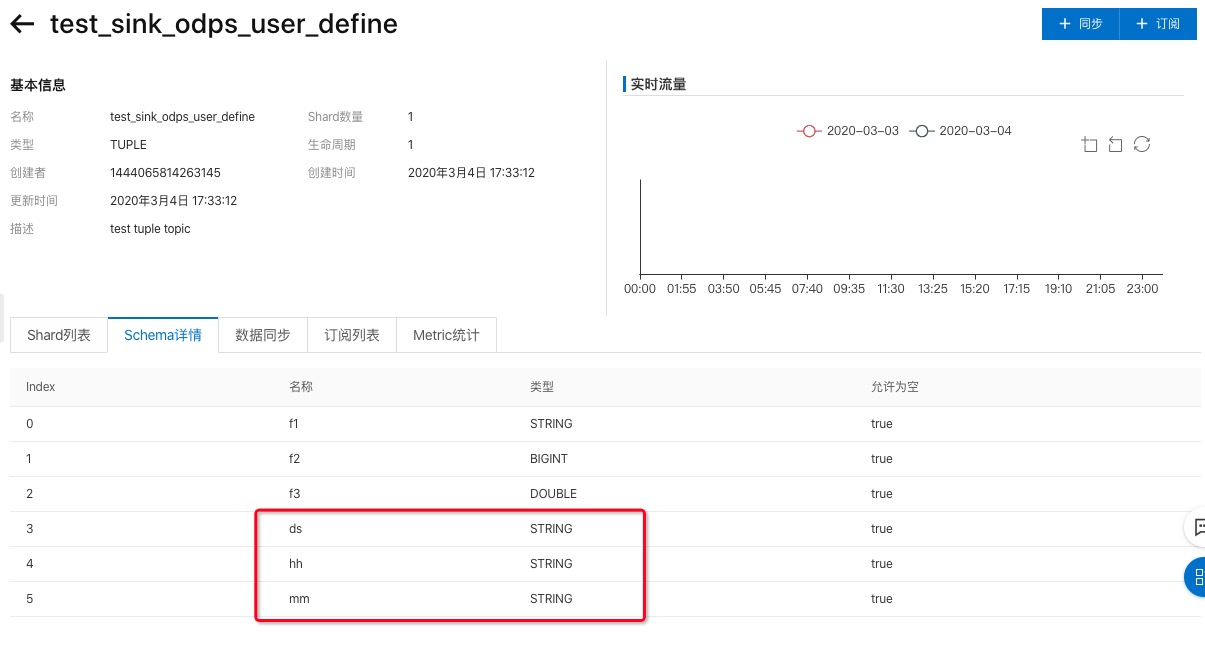
向DataHub Topic寫入數(shù)據(jù),可以使用datahub-sdk進行數(shù)據(jù)寫入
測試過程中使用SDK寫入幾條條數(shù)據(jù),其中[ds,hh,mm]分別為:[20210304,01,15]和[20210304,02,15],數(shù)據(jù)內(nèi)容如下所示:
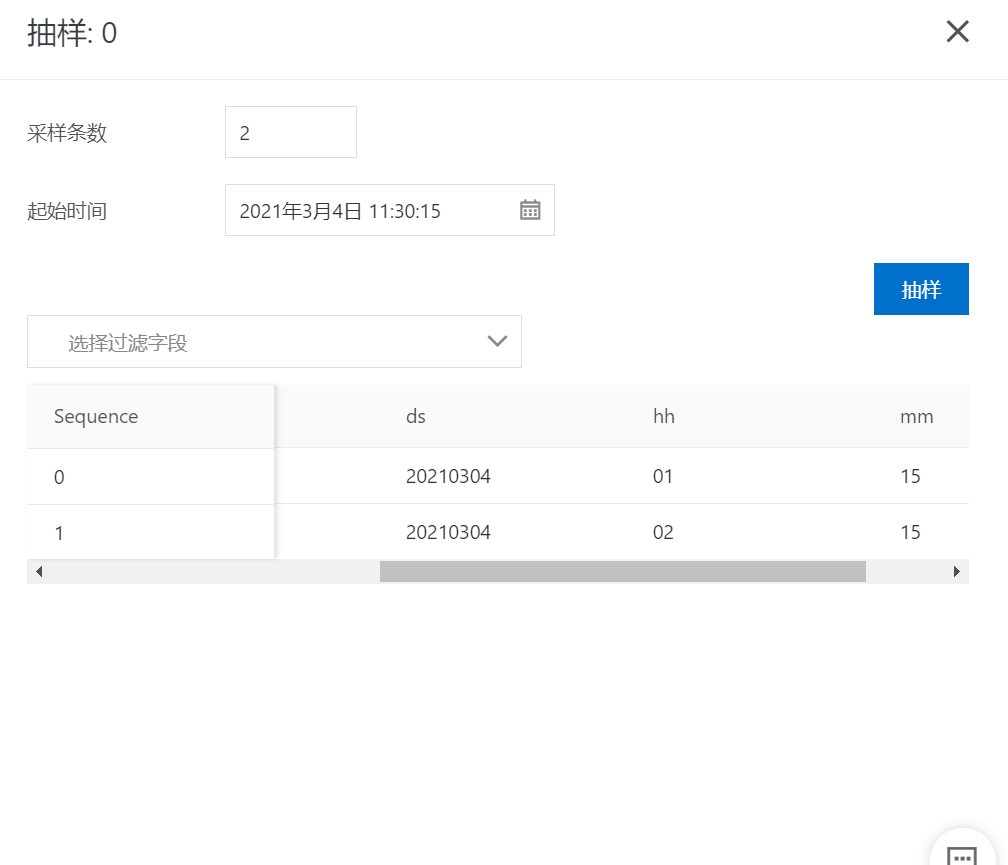
3 建立同步任務
USER_DEFINE分區(qū)模式可以通過在同步中設置分區(qū)配置字段,如果MaxCompute沒有對應的表,可自動創(chuàng)建。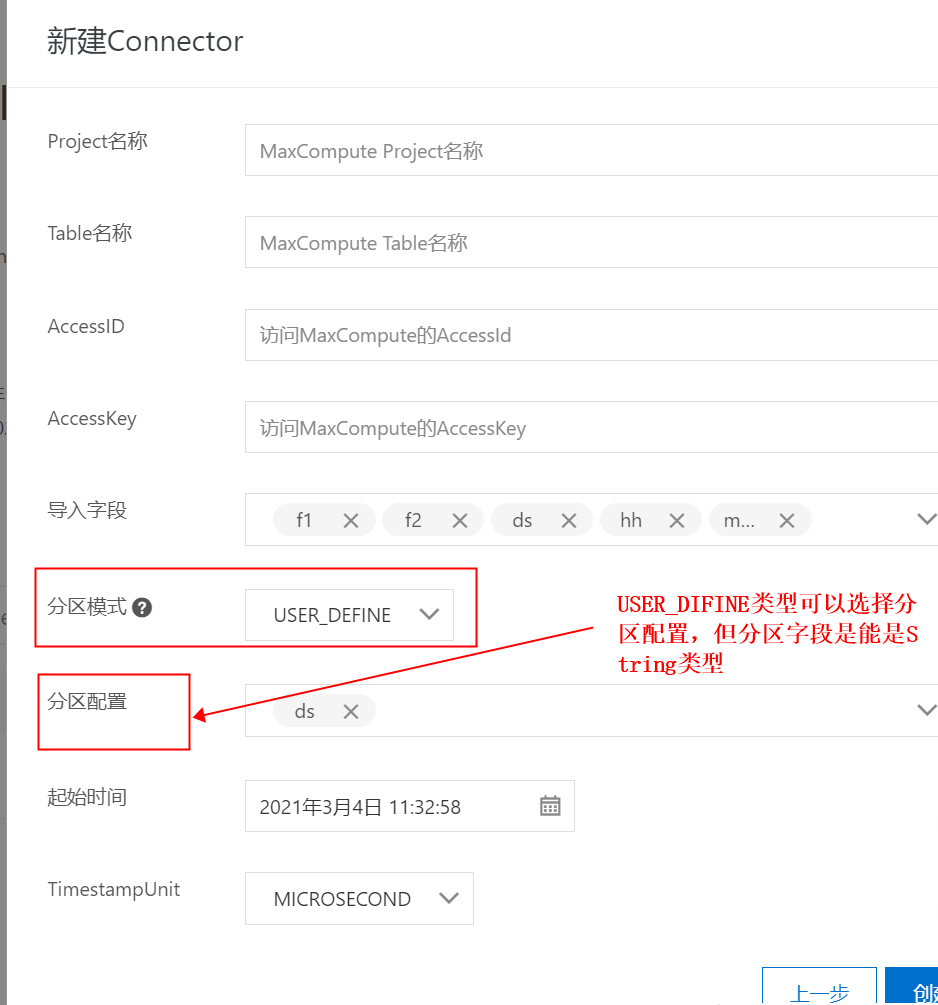 這里導入字段中設置導入f1、f2字段,不同步f3字段。
這里導入字段中設置導入f1、f2字段,不同步f3字段。
4 確認同步數(shù)據(jù)
可以從DataHub管控臺查看對應同步任務的同步信息。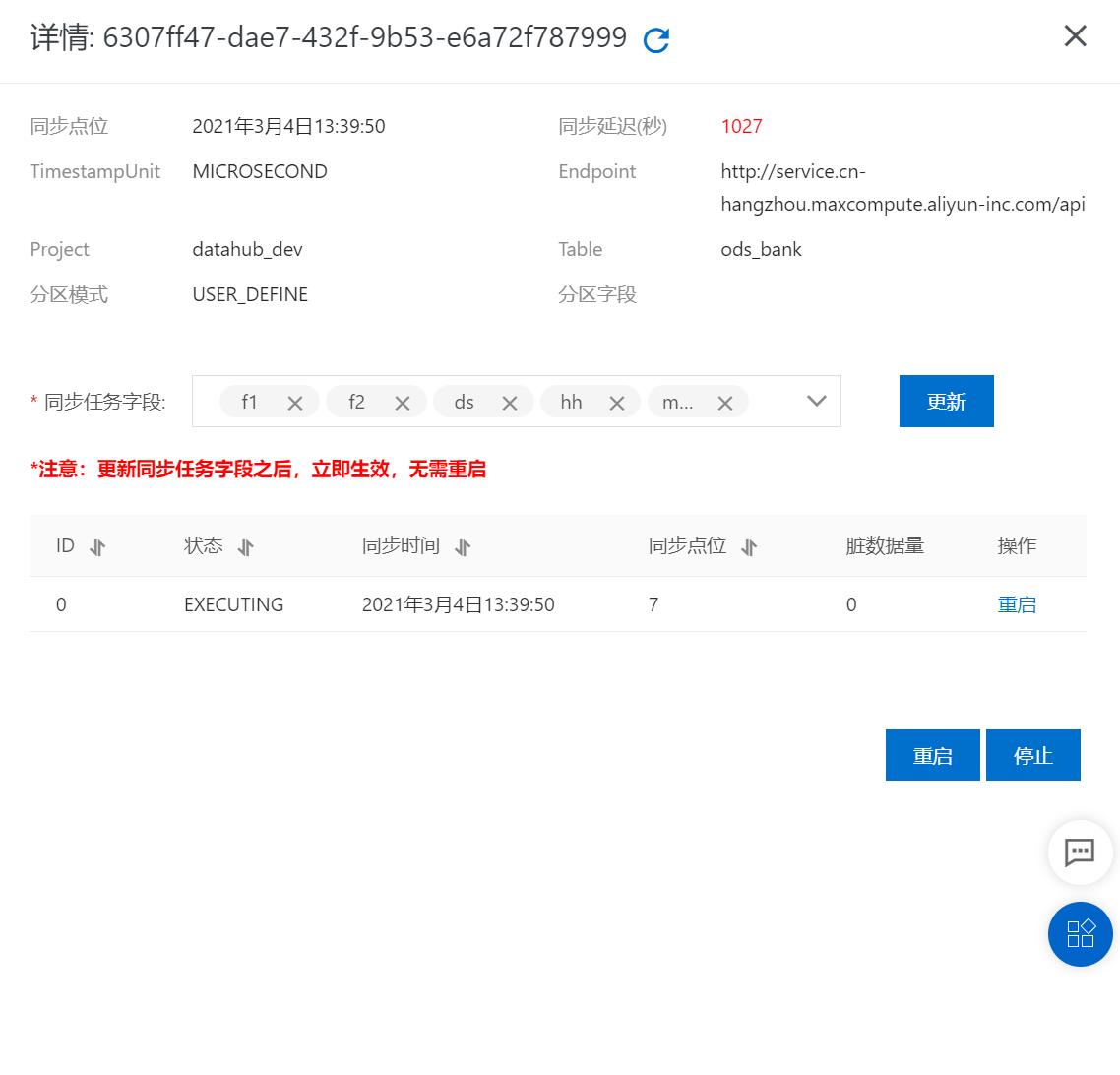 查詢MaxCompute數(shù)據(jù)結果,結果如下:
查詢MaxCompute數(shù)據(jù)結果,結果如下: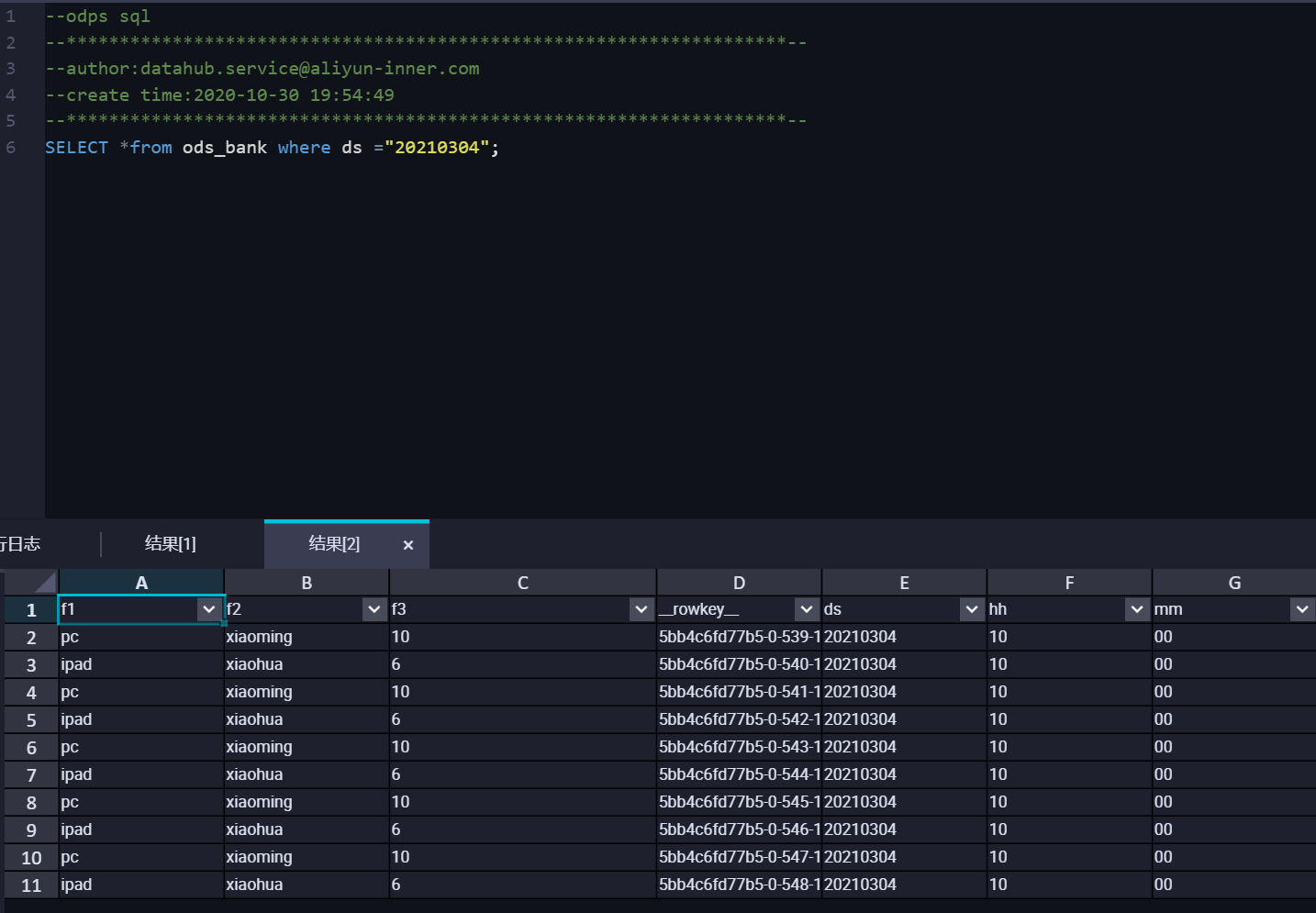 可以看到在USER_DEFINE模式下,DataHub會根據(jù)
可以看到在USER_DEFINE模式下,DataHub會根據(jù)MaxCompute分組字段所對應的value將DataHub中的數(shù)據(jù)同步到對應的分區(qū)中。
2. SYSTEM_TIME同步模式
建立DataHub Topic
備注:由于分區(qū)是根據(jù)寫入DataHub時間來計算的,因此topic schema只需包含數(shù)據(jù)字段,不需要包含分區(qū)字段,如下圖所示:
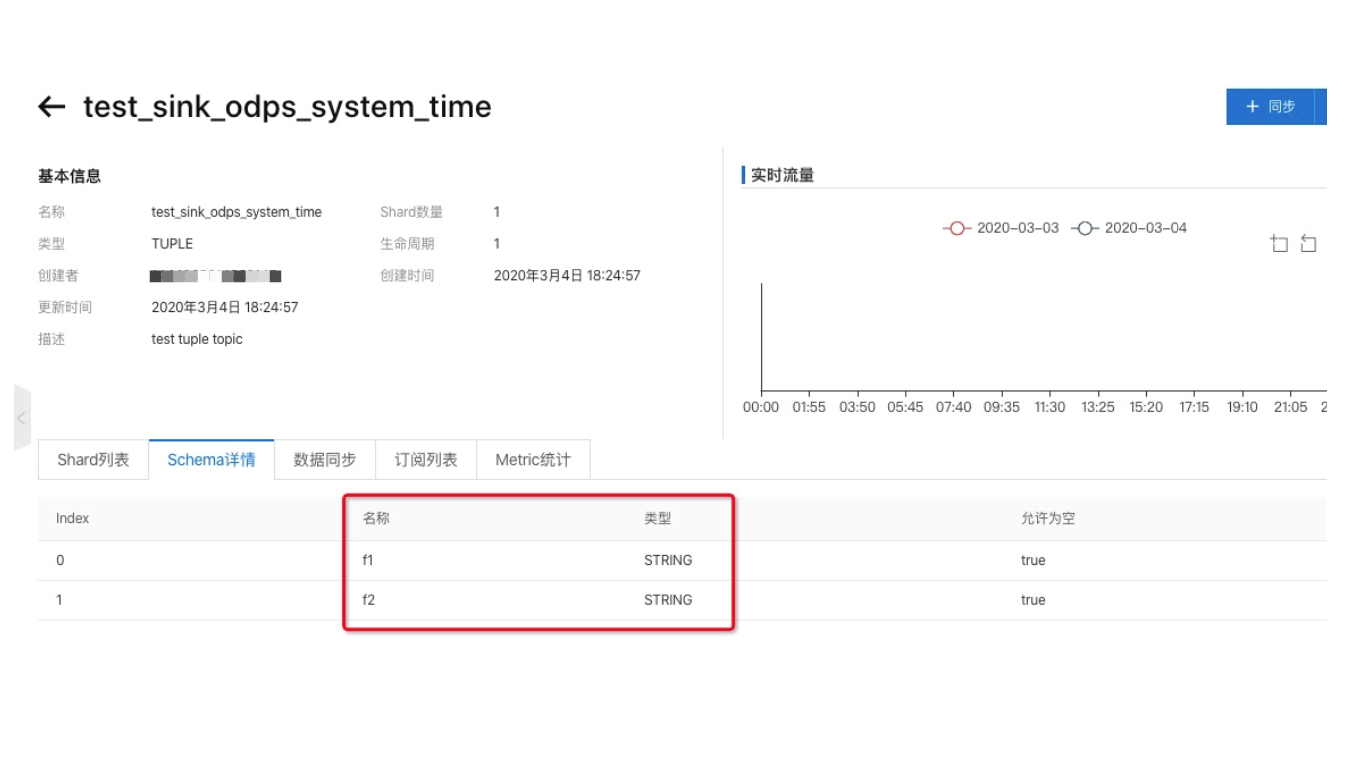
向DataHub Topic寫入數(shù)據(jù),可以使用datahub-sdk進行數(shù)據(jù)寫入。
測試過程中使用SDK寫入幾條數(shù)據(jù),DataHub目前對應的寫入時間為
2021-03-04 14:02:45,數(shù)據(jù)內(nèi)容如下所示: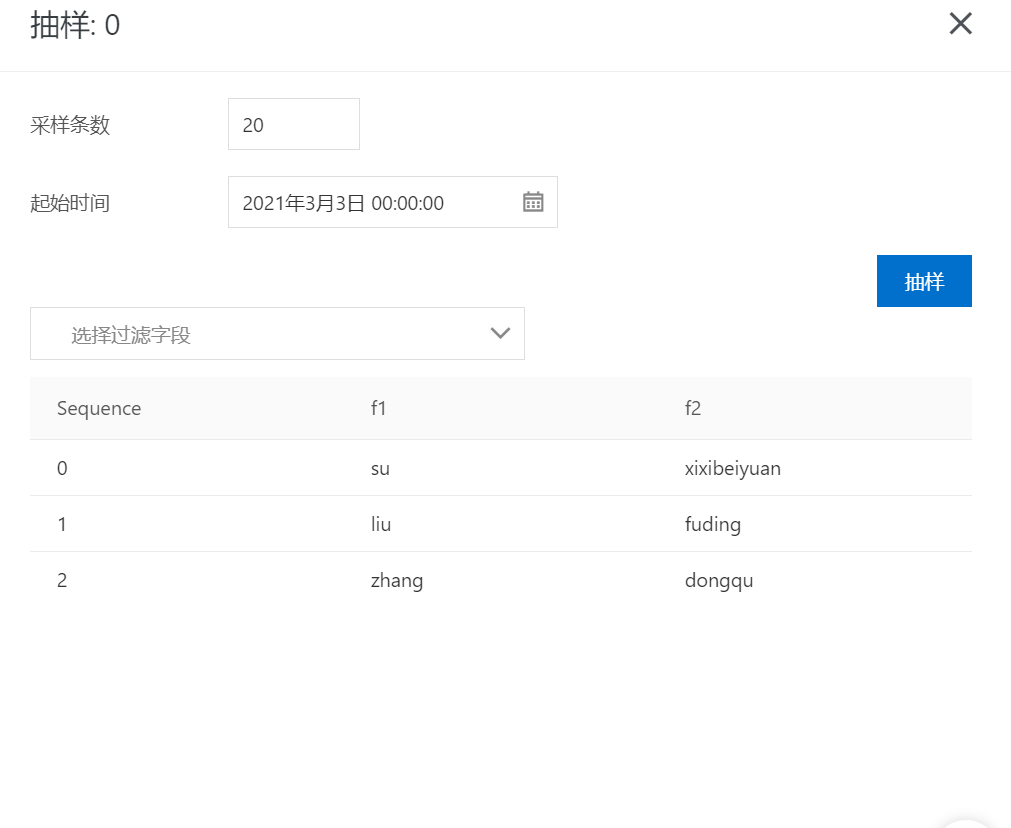
建立同步任務
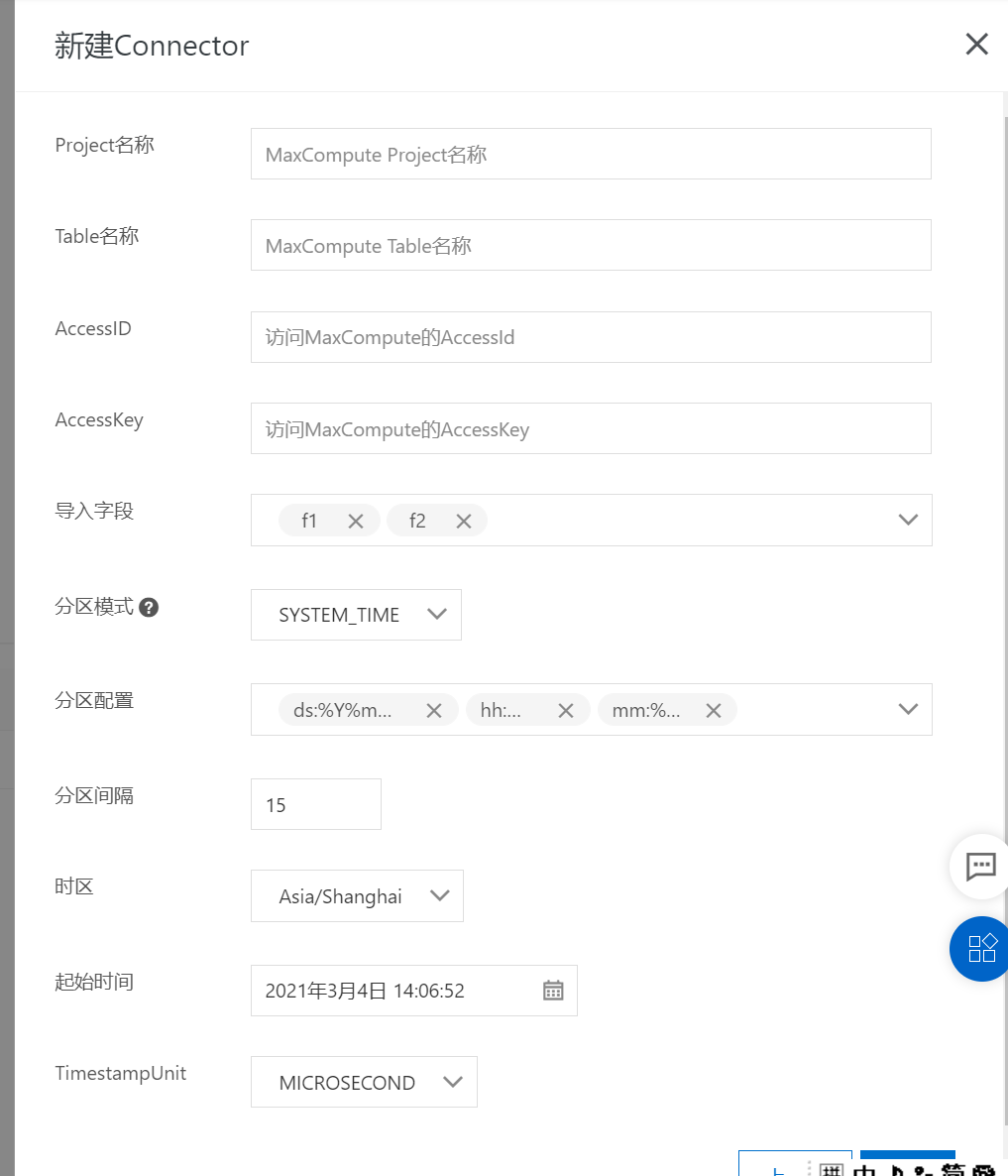
請注意分區(qū)配置需要和MaxCompute表分區(qū)一致。
4 確認同步數(shù)據(jù)
可以從DataHub管控臺查看對應同步任務的同步信息,如DoneTime。 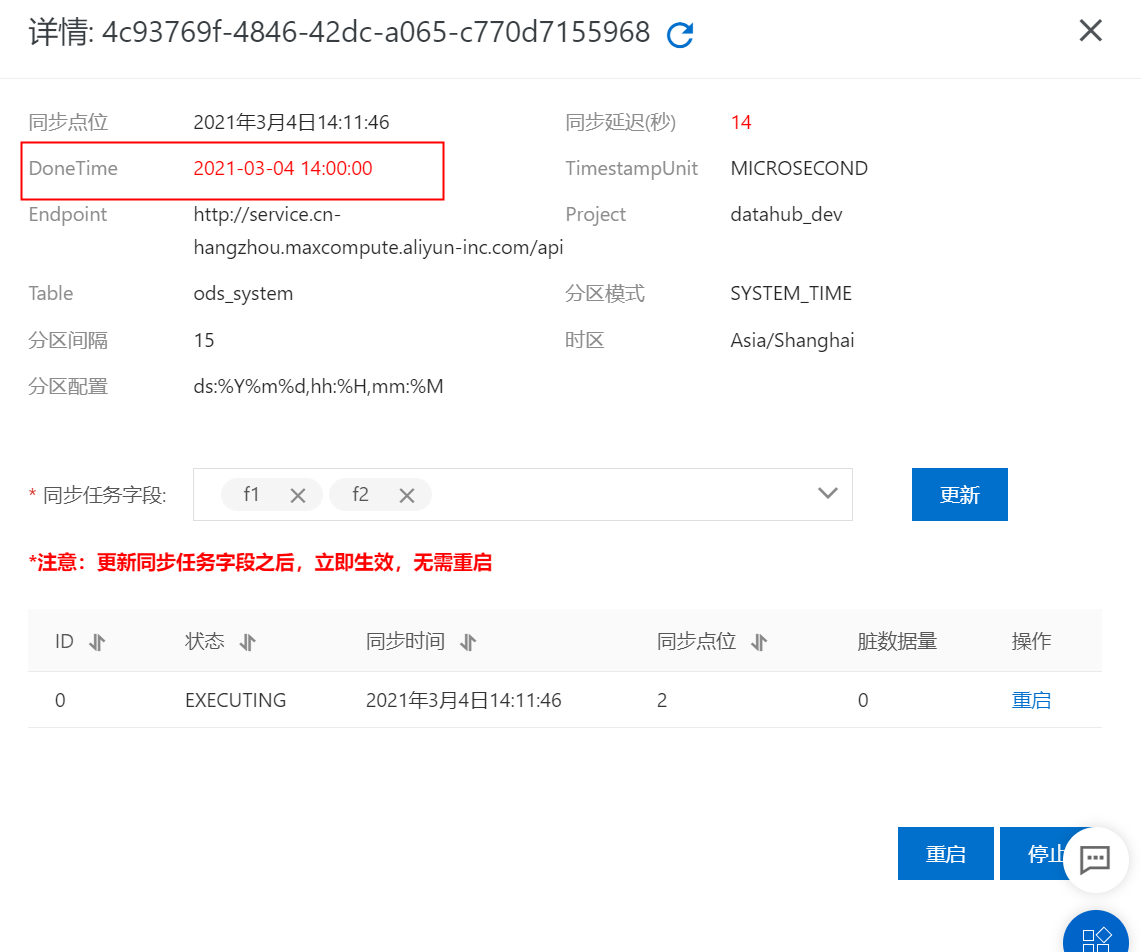 查詢MaxCompute數(shù)據(jù)結果,結果如下:
查詢MaxCompute數(shù)據(jù)結果,結果如下: 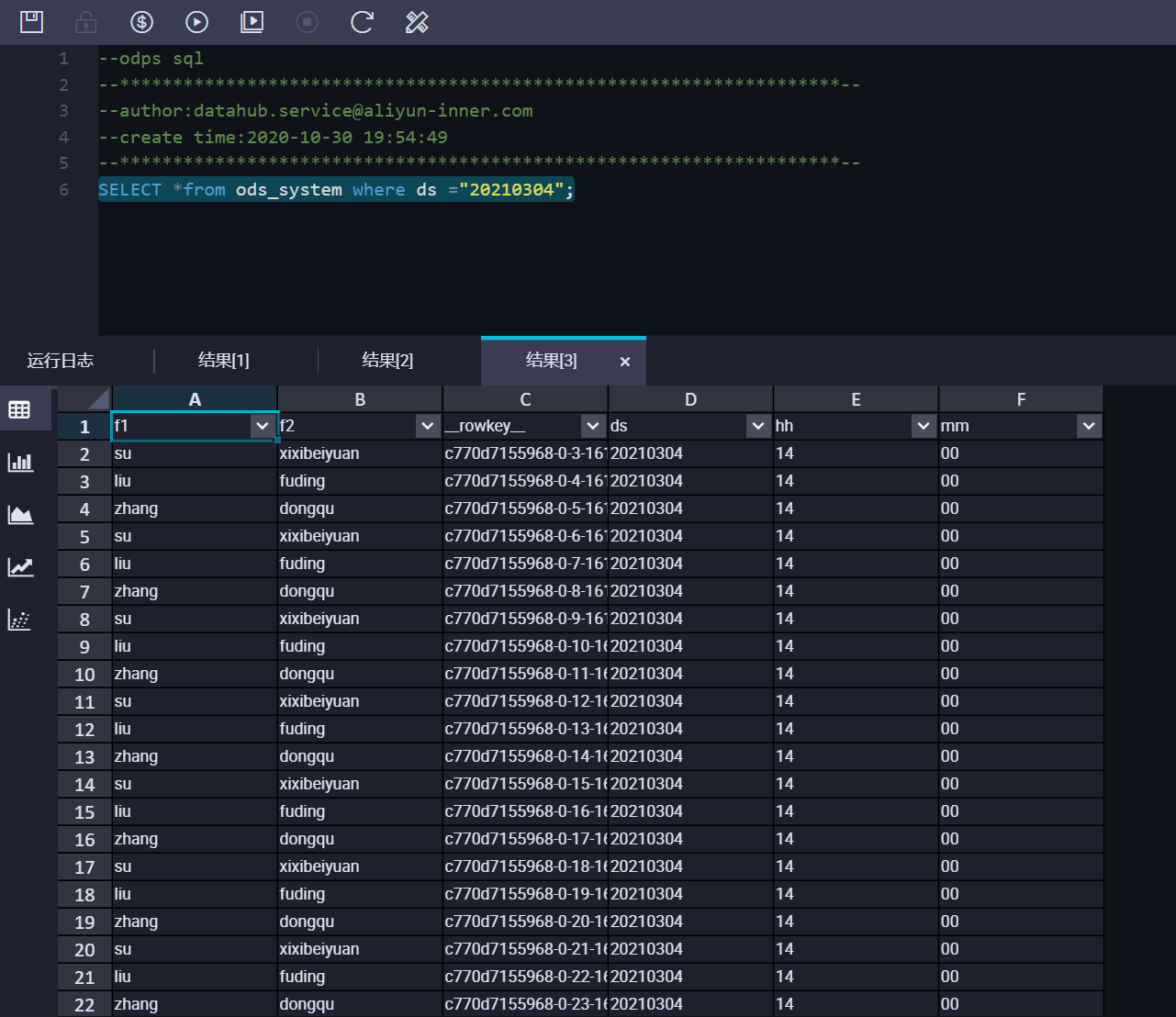 可以看到在SYSTEM_TIME模式下,DataHub會根據(jù)
可以看到在SYSTEM_TIME模式下,DataHub會根據(jù)數(shù)據(jù)寫入DataHub的時間將DataHub中的數(shù)據(jù)同步到對應的分區(qū)中。
常見問題
同步到MaxCompute timestamp字段時間變?yōu)?970-01-19
原因:DataHub同步MaxCompute默認時間戳單位為微秒,用戶寫入時間戳為毫秒解決方案:寫入DataHub時間戳以微秒方式寫入。