SQL限流是限制數據庫上執行SQL的并發度,通過限制問題SQL的并發度后,保障數據庫正常響應業務請求,保障大部分的業務正常運轉,即通過小部分業務受損,保障大部分業務正常運行。
背景信息
隨著技術的發展,尤其是云數據庫的普及,數據庫系統變得越來越穩定,運維工作也越來越輕松,版本升級、實例遷移等都可以自動完成,上層業務不會有太大的感知。即使硬件設備或者網絡出現故障,巡檢系統也可以快速遷移、及時重啟,保證服務穩定。但現有的這些手段幾乎都是針對服務端的穩定性保證,來自業務端的異常使用造成的問題還需要人工介入處理,比如業務變化中引入了新的慢SQL,突然涌入的洪峰等。這些業務層面的異常發生時,上述的運維手段幾乎都不能快速處理異常,防止系統崩潰。
問題
- 流量問題:突發的流量急劇上升,影響正常業務,比如緩存穿透、異常調用、大促等等,造成原來并發不大的SQL,并發量突然上升。
- 數據問題:有數據傾斜的SQL,影響正常業務,例如訂單數據中存在大賬號,查詢該賬號的相關SQL拖慢數據庫。
- SQL問題:資源消耗型SQL,俗稱為“爛SQL”,影響正常業務,比如新上線SQL調用量特別大,又沒有創建索引,造成整體系統繁忙。
用戶問題
- 怎么能夠在異常發生的時候,及時發現異常?
- 發現異常后,怎么識別需要限流的SQL?
- 怎么提取限流SQL的關鍵字,既能幫助業務恢復正常,又保障業務的受損最小?
- 限流執行后,怎么快速確認執行的限流操作是正確的?
除了上述的問題,在現實生活中可能還會出現各種特殊情況,比如值班人員聯系不上、工作人員身邊沒有電腦、信息太多分析難度大、壓力大緊張操作失誤等。
因此需要盡可能的把異常發現、異常SQL定位、SQL限流、跟蹤/回滾的整體流程自動化處理。
說明 自動SQL限流的解決方案應運而生,該服務已經在阿里巴巴集團內部運行了2年多,并且在2020年2月在阿里云上發布,您可以在數據庫自治服務DAS進行體驗和使用。
解讀
整體流程:
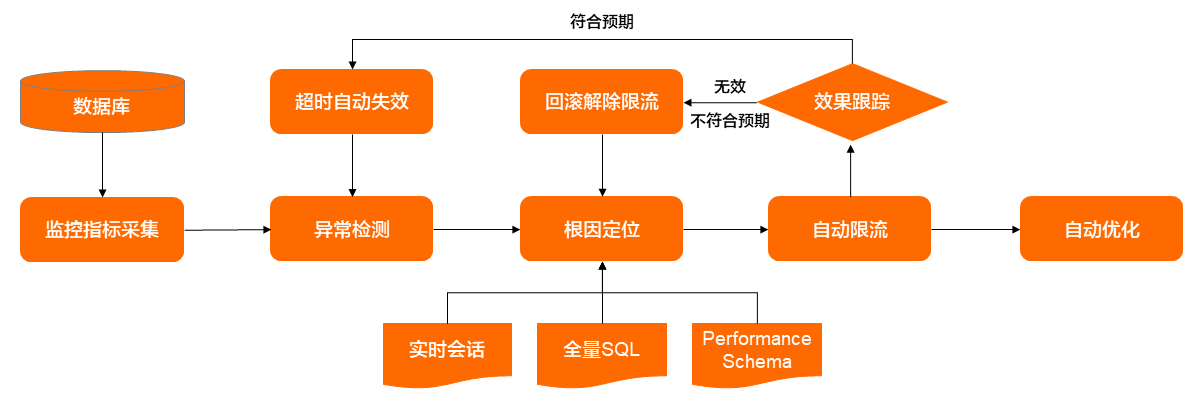
- 監控指標采集:在阿里云申請的RDS實例默認開啟主機和引擎的性能指標采集,包括CPU,IOPS,QPS,活躍會話等,這些實時數據是后續所有分析和處理的基礎。
- 異常檢測:該模塊通過機器學習對實例歷史性能數據進行離線訓練獲得相關模型,然后利用該模型對實時指標數據進行異常檢測,相比基于閾值的告警,能夠更及時的發現異常,該部分的內容將在后續的系列文章中進行詳細介紹。
- 根因定位:該模塊會訂閱實例上的異常事件,并采集異常時刻的會話信息,然后結合SQL審計中的全量SQL,performance_schema中的統計信息進行判斷,找出實例異常的原因。我們將根因分為四種場景:
- 阻塞型SQL:DAS會利用實時會話,鎖等待,運行中的事務等進行分析,分析是否存在DDL變更,大事務,鎖等待等場景,同時判斷被影響會話的數量和執行時間,如果影響的會話比較多或者執行時間很長,那這不需要通過限流來解決問題,而是終止異常會話。
- 資源消耗型SQL,俗稱為“爛SQL”:該場景中,可能SQL的并發不大,但是消耗大量的CPU或者IO或者網絡資源,并且被持續不斷的被提交。
- 流量型SQL :大量正常SQL同時在數據庫中運行,觸發數據庫的資源瓶頸,導致即使KV類的查詢SQL的響應時間都出現了異常。
- 其他:暫時還無法歸因到上述三種場景的案例。
- 自動限流:當發現實例存在根因分析中描述的資源消耗型SQL和流量型SQL時,會自動提取SQL特征,對異常SQL進行限流(用戶授權的情況下觸發)。這里面最難的問題是怎么選取SQL的特征,進行精確限流,而不會出現由于特征選取錯誤而導致業務全面受損。
- 特征選取:如果發現需要限流的異常SQL,下一步就需要確定SQL的特征,理想的情況是特征是唯一的,只對識別到的異常SQL進行限流而不影響其它SQL。這里首先要區分SQL模板限流和SQL文本限流。
- SQL模板限流:SQL模板是指將SQL文本的具體參數抽象化后的文本,這類SQL并發度高都會產生問題且與具體參數無關,對應突增流量,無索引等場景,特征只需要包含模板特征即可。
- SQL文本限流:這類限流主要針對數據傾斜的場景,同一類模板的一些SQL執行正常,一些SQL執行異常,特征中既要包含SQL模板信息,又要包含具體參數信息。
對于SQL模板限流,如果SQL中包含模板ID信息,會優先使用ID類信息,比如使用數據庫中間件根據模板自動生成的SQL ID或者開發人員在SQL模板中添加的HINT信息。
使用ID的優點是容易保證模板唯一,不會對其它模板的SQL造成影響,缺點是同樣的SQL如果不帶ID信息(比如通過命令行手動執行),仍然可以執行,不受限流并發度控制。
如果不包含模板ID信息,那就需要提取文本信息,在分析過程中通過計算獲得SQL模板。如下所示,SQL1和SQL2計算后分別可以得到模板1和模板2。那我們對模板1進行限流,可以獲得的最全特征為select~id~name~age~from~students~where~name。/*SQL文本1*/ select id,name,age from students where name='張三'; /*SQL模板1*/ select id,name,age from students where name=? /*SQL文本2*/ select id,name,age from students where name='張三' and sid='唯一ID'; /*SQL模板2*/ select id,name,age from students where name=? and sid=?使用該特征進行限流,優點是不管從哪種連接方式發送的SQL,只要滿足該特征都受限流并發度控制,缺點是存在誤限的可能性,比如模板2包含模板1中的所有特征。
- 自動優化:當根因分析發現可以優化的SQL時,除了發起限流應急處理外,還會將異常SQL發送到自動優化模塊,自動創建索引,該部分的內容將在后續的系列文章中進行詳細介紹。
- 跟蹤/回滾:自動限流后,持續跟蹤,如果發現限流后,數據庫的負載未降低或者降低的流量和預估出現偏差,自動回滾限流操作,并再次啟動根因定位。