DAS Auto Scaling彈性能力
數(shù)據(jù)庫自治服務DAS的Auto Scaling是以數(shù)據(jù)庫實例的實時性能數(shù)據(jù)作為輸入,由DAS完成流量異常發(fā)現(xiàn)、合理數(shù)據(jù)庫規(guī)格建議和合理磁盤容量建議,使數(shù)據(jù)庫服務具備自動擴展存儲和計算資源的能力。
背景信息
為業(yè)務應用選擇一個合適的數(shù)據(jù)庫計算規(guī)格(CPU和內(nèi)存),是每個數(shù)據(jù)庫運維人員都會經(jīng)常面臨的一個問題。若規(guī)格選得過大,會產(chǎn)生資源浪費;若規(guī)格選的過小,計算性能不足會影響業(yè)務。
通常情況下,運維人員會采用業(yè)務平穩(wěn)運行狀態(tài)下,CPU處于合理水位(例如50%以下)的一個規(guī)格(如4核CPU配8 GB內(nèi)存)并配一個相對富余的磁盤規(guī)格(如200 GB)。
然而在數(shù)據(jù)庫應用的運維人員日常工作中,線上應用流量突增導致數(shù)據(jù)庫資源打滿的情況時有發(fā)生,而引發(fā)這類問題的場景可能多種多樣:
新業(yè)務上線,對業(yè)務流量預估不足,導致資源打滿。如新上線的應用接入了大量的引流,或基礎流量比較大的平臺上線了一個新功能。
不可預知的流量。如突發(fā)的輿論熱點帶來的臨時流量,或某個網(wǎng)紅引發(fā)的限時搶購、即興話題等。
一些平時運行頻次不高,但又偶發(fā)集中式訪問。如每日一次的上班打卡場景,或每周執(zhí)行幾次的財務核算業(yè)務。這類業(yè)務場景平時業(yè)務壓力不高,雖已知會存在訪問高峰,但為節(jié)省資源而通常不會分配較高的規(guī)格。
當上述業(yè)務場景突發(fā)計算資源不足狀況時,通常會讓運維人員措手不及,嚴重影響業(yè)務,如何應對“數(shù)據(jù)庫資源打滿”是運維人員常常被挑戰(zhàn)的問題之一。
在數(shù)據(jù)庫場景下,資源打滿可分為計算資源和存儲資源兩大類,其主要表現(xiàn):
計算資源打滿:主要表現(xiàn)為CPU或內(nèi)存資源利用率達到100%,即當前規(guī)格下的計算能力不足。
存儲資源打滿:主要表現(xiàn)為磁盤空間使用率達到100%,數(shù)據(jù)庫寫入的數(shù)據(jù)量達到當前規(guī)格下磁盤空間的最大容量,導致業(yè)務無法寫入新數(shù)據(jù)。
針對上述兩類問題,數(shù)據(jù)庫自治服務DAS進行了服務創(chuàng)新,使數(shù)據(jù)庫服務具備自動擴展存儲和計算資源的技術能力,可從容應對。
本文將對DAS Auto Scaling服務的架構進行詳細的介紹,包括技術挑戰(zhàn)、解決方案和關鍵技術。
技術挑戰(zhàn)
計算資源規(guī)格調(diào)整是數(shù)據(jù)庫優(yōu)化的一種常用手段,盡管計算資源規(guī)格只涉及到CPU和內(nèi)存,但在生產(chǎn)環(huán)境中進行規(guī)格變配產(chǎn)生的影響不容忽視,涉及數(shù)據(jù)遷移、HA切換、Proxy切換等操作,對業(yè)務也會產(chǎn)生影響。
在業(yè)務有突發(fā)流量時,通常計算資源會比較緊張,甚至出現(xiàn)CPU利用率達到100%的情況。面對這種情況,通常采用擴容數(shù)據(jù)庫規(guī)格的方式來解決問題,而專業(yè)運維人員(DBA)在準備擴容方案時會至少思考如下三個問題:
擴容是否能解決資源不足的問題?
在數(shù)據(jù)庫場景下,CPU打滿只是計算資源不足的一個表征,導致這個現(xiàn)象的根因很多,解法也各不相同:
例如業(yè)務流量激增,當前規(guī)格的資源確實不能夠滿足計算需求,在合適的時機點,彈性擴容是一個好的選擇。
例如出現(xiàn)了大量的慢SQL,慢SQL堵塞任務隊列,且占用了大量的計算資源等,此時資深的數(shù)據(jù)庫管理員首先想到的是緊急SQL限流,而不是擴容。
在感知到實例資源不足時,DAS同樣需要從錯綜復雜的問題中抽絲剝繭定位根因,基于根因做出明智的決策,是限流,是擴容,還是其他。
何時應該進行擴容?
如何選擇合適的擴容時機和擴容方式:
對于應急擴容時機,選擇的好壞與緊急情況的判斷準確與否密切相關。“緊急”告警發(fā)出過于頻繁,會導致實例頻繁的高規(guī)格擴容,產(chǎn)生不必要的費用支出;“緊急”告警發(fā)出稍晚,業(yè)務受到突發(fā)情況影響的時間就會相對較長,對業(yè)務會產(chǎn)生影響,甚至引發(fā)業(yè)務故障。在實時監(jiān)控的場景下,當我們面臨一個突發(fā)的異常點時,很難預判下一時刻是否還會異常。因此,是否需要應急告警變得比較難以決斷。
對于擴容方式,通常有兩種方式,分別是通過增加只讀節(jié)點的水平擴容,以及通過改變實例自身規(guī)格的垂直擴容。
水平擴容適用于讀流量較多,而寫流量較少的場景,但傳統(tǒng)數(shù)據(jù)庫需要搬遷數(shù)據(jù)來搭建只讀節(jié)點,而搬遷過程中主節(jié)點新產(chǎn)生的數(shù)據(jù)還存在增量同步更新的問題,會導致創(chuàng)建新節(jié)點比較慢。
垂直擴容則是在現(xiàn)有規(guī)格基礎上進行升級,其一般流程為先對備庫做升級,然后主備切換,再對新備庫做規(guī)格升級,通過這樣的流程來降低對業(yè)務的影響,但是備庫升級后切換主庫時依然存在數(shù)據(jù)同步和數(shù)據(jù)延遲的問題。
因此,在什么條件下選擇哪種擴容方式也需要依據(jù)當前實例的具體流量來進行確定。
如何擴容,規(guī)格該如何選擇?
在數(shù)據(jù)庫場景下,實例變更一次規(guī)格涉及多項管控運維操作。以物理機部署的數(shù)據(jù)庫變更規(guī)格為例,一次規(guī)格變更操作通常會涉及數(shù)據(jù)文件搬遷、cgroup隔離重新分配、流量代理節(jié)點切換、主備節(jié)點切換等操作步驟;而基于Docker部署的數(shù)據(jù)庫規(guī)格變更則更為復雜,會額外增加Docker鏡像生成、Ecs機器選擇、規(guī)格庫存等微服務相關的流程。因此,選擇合適的規(guī)格可有效地避免規(guī)格變更的次數(shù),為業(yè)務節(jié)省寶貴的時間。
當CPU利用率已經(jīng)是100%的時候,升配一個規(guī)格將會面臨兩種結果:第一種結果是升配之后,計算資源負載下降并且業(yè)務流量平穩(wěn);第二種結果是升配之后,CPU依然是100%,并且流量因為規(guī)格提升后計算能力增強而提升。第一種結果,是比較理想的情況,也是預期擴容后應該出現(xiàn)的效果,但是第二種結果也是非常常見的情形,由于升配之后的規(guī)格依然不能承載當前的業(yè)務流量容量,而導致資源依然不足,并且仍在影響業(yè)務。
如何利用數(shù)據(jù)庫運行時的信息選擇一個合適的高配規(guī)格將直接影響升配的有效性。
解決方案
針對上文提到的三項技術挑戰(zhàn),下面從DAS Auto Scaling服務的產(chǎn)品能力、解決方案、核心技術這三個方面進行解讀,其中涉及RDS MySQL、PolarDB MySQL版、Redis等多種數(shù)據(jù)庫服務,提供了存儲自動擴容、計算規(guī)格自動擴容和網(wǎng)絡帶寬自動擴容等功能,最后以一個案例進一步具體說明。
能力介紹:
針對即將達到用戶已購買規(guī)格上限的實例,DAS存儲自動擴容服務可以進行磁盤空間預擴容,避免出現(xiàn)因數(shù)據(jù)庫磁盤占滿而影響用戶業(yè)務的事件發(fā)生。在該服務中,用戶可自主配置擴容的閾值比例,也可以采用DAS服務預先提供的90%規(guī)格上界的閾值配置,當觸發(fā)磁盤空間自動擴容事件后,DAS會對該實例的磁盤進行擴容。
針對需要變更實例規(guī)格的數(shù)據(jù)庫實例,DAS規(guī)格自動變配服務可進行計算資源的調(diào)整,用更符合用戶業(yè)務負載的計算資源來處理應用請求,在該服務中,用戶可自主配置業(yè)務負載流量的突發(fā)程度和持續(xù)時間,并可以指定規(guī)格變配的最大配置以及變配之后是否回縮到原始規(guī)格。
針對需要擴容實例帶寬規(guī)格的數(shù)據(jù)庫實例,DAS網(wǎng)絡帶寬自動變配服務可對實例帶寬進行調(diào)整,擴縮到合適的網(wǎng)絡帶寬規(guī)格來解決實例帶寬吞吐量的問題。
在用戶交互層面,DAS Auto Scaling主要采用消息通知的方式展示具體的進度以及任務狀態(tài),其中主要包括異常觸發(fā)事件、規(guī)格建議和任務狀態(tài)三部分。異常觸發(fā)事件用于通知用戶觸發(fā)變配任務,規(guī)格建議將針對存儲擴容和規(guī)格變配的原始規(guī)格和目標值進行說明,而管控任務狀態(tài)則將反饋Auto Scaling任務的具體進展和執(zhí)行狀態(tài)。
方案介紹
為了實現(xiàn)上面介紹的具體能力,DAS Auto Scaling實現(xiàn)了一套完整的數(shù)據(jù)閉環(huán),如下圖所示:
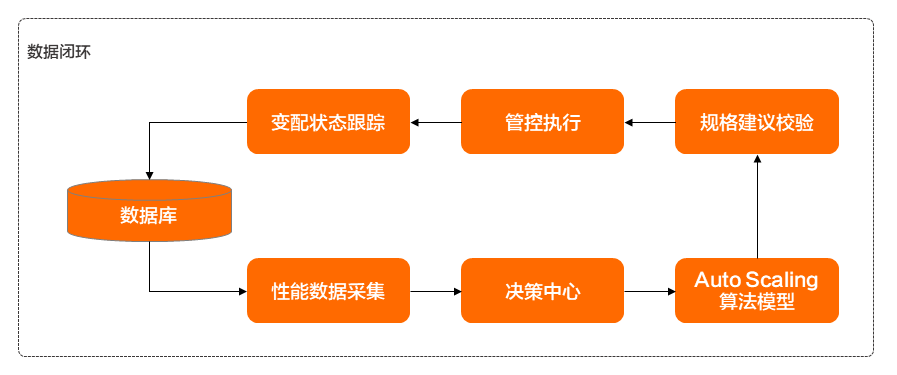
在該數(shù)據(jù)閉環(huán)中,包含性能采集模塊、決策中心、算法模型、規(guī)格建議模塊、管控執(zhí)行模塊和任務跟蹤模塊,各模塊的具體功能如下:
性能采集模塊負責對實例進行實時性能數(shù)據(jù)采集,涉及數(shù)據(jù)庫的多項性能指標信息、規(guī)格配置信息、實例運行會話信息等。
決策中心模塊則會根據(jù)當前性能數(shù)據(jù)、實例會話列表數(shù)據(jù)等信息進行全局判斷,以解決挑戰(zhàn)一的問題。例如可通過SQL限流來解決當前計算資源不足的問題則會采取限流處理;若確實為突增的業(yè)務流量,則會繼續(xù)進行Auto Scaling服務流程。
算法模型是整個DAS Auto Scaling服務的核心模塊,負責對數(shù)據(jù)庫實例的業(yè)務負載異常檢測和容量規(guī)格模型推薦進行計算,進而解決挑戰(zhàn)二和挑戰(zhàn)三的具體問題。
規(guī)格建議校驗模塊將產(chǎn)出具體建議,并針對數(shù)據(jù)庫實例的部署類型和實際運行環(huán)境進行適配,并與當前區(qū)域的可售賣規(guī)格進行二次校驗,確保的建議能夠順利在管控側進行執(zhí)行。
管控模塊負責按照產(chǎn)出的規(guī)格建議進行分發(fā)執(zhí)行。
狀態(tài)跟蹤模塊則用于衡量和跟蹤規(guī)格變更前后數(shù)據(jù)庫實例上的性能變化情況。
下文將分別針對DAS Auto Scaling支持的存儲擴容、計算規(guī)格變配和帶寬規(guī)格變配三個業(yè)務場景進行展開介紹。
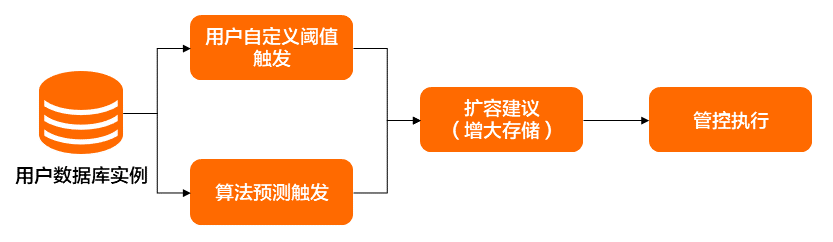
存儲擴容的方案如下圖所示,主要有兩類觸發(fā)方式,分別是用戶自定義觸發(fā)和算法預測觸發(fā)。其中,算法將根據(jù)數(shù)據(jù)庫實例過去一段時間內(nèi)的磁盤使用值結合時序序列預測算法,預測出未來一段時間內(nèi)的磁盤使用量,若短時間內(nèi)磁盤使用量將超過用戶實例的磁盤規(guī)格,則進行自動擴容。每次磁盤擴容將最少擴大5 GB,最多擴大原實例規(guī)格的15%,以確保數(shù)據(jù)庫實例的磁盤空間充足。
目前在磁盤Auto Scaling的時機方面,主要采用的是閾值和預測相結合的方式。當用戶的磁盤數(shù)據(jù)緩慢增長達到既定閾值(如90%)時,將觸發(fā)擴容操作;如果用戶的磁盤數(shù)據(jù)快速增長,算法預測到其短時間內(nèi)將會可用空間不足時,也會給出磁盤擴容建議及相應的擴容原因說明。
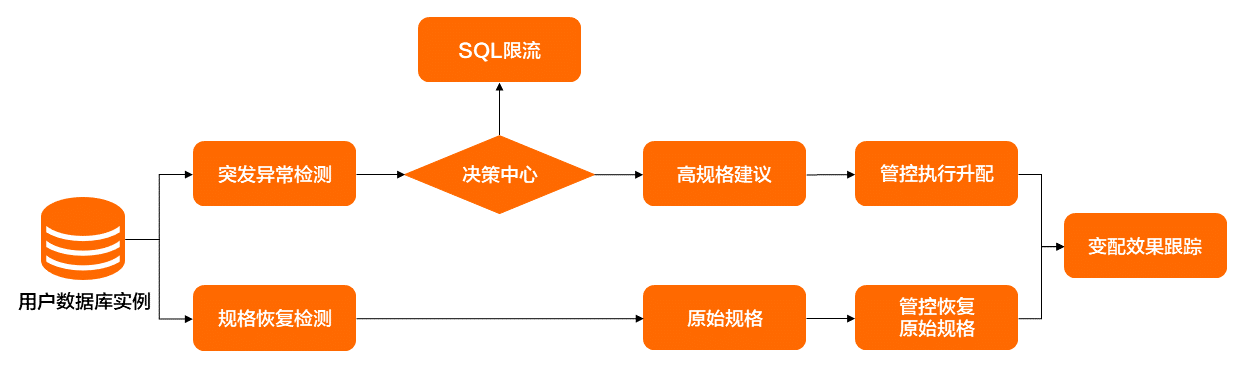
計算規(guī)格變配的方案如圖3所示,其具體流程為:首先,異常檢測模塊將針對業(yè)務突發(fā)流量從多個維度(qps、tps、active session、iops等指標)進行突發(fā)異常識別,經(jīng)決策中心判別是否需要Auto Scaling變配規(guī)格,然后由規(guī)格建議模塊產(chǎn)生高規(guī)格建議,再由管控組件進行規(guī)格變配執(zhí)行。
待應用的異常流量結束之后,異常檢測模塊將識別出流量已回歸正常,然后再由管控組件根據(jù)元數(shù)據(jù)中存儲的原規(guī)格信息進行規(guī)格回縮。在整個變配流程結束之后,將有效果跟蹤模塊產(chǎn)出變配期間的性能變化趨勢和效果評估。
目前規(guī)格的Auto Scaling觸發(fā)時機方面,主要是采取對實例的多種性能指標(包括cpu利用率、磁盤iops、實例Logic read等)進行異常檢測之后,結合用戶設定的觀測窗口期長度來實現(xiàn)有效的規(guī)格Auto Scaling觸發(fā)。觸發(fā)Auto Scaling之后,規(guī)格推薦算法模塊將基于訓練好的模型并結合當前性能數(shù)據(jù)、規(guī)格、歷史性能數(shù)據(jù)進行計算,產(chǎn)出更適合當前流量的實例規(guī)格。此外,回縮原始規(guī)格的觸發(fā)時機也是需要結合用戶的靜默期配置窗口長度和實例的性能數(shù)據(jù)進行判斷,當符合回縮原始規(guī)格條件后,將進行原始規(guī)格的回縮。
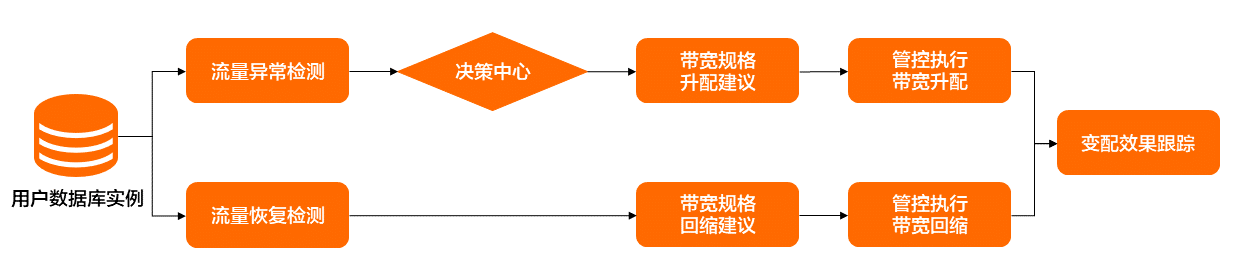
帶寬規(guī)格變配的方案如圖4所示,其具體流程為:首先,異常檢測模塊針對實例出/入口流量使用率進行突增流量異常識別,經(jīng)決策中心判別是否需要進行帶寬自動擴容,然后由帶寬規(guī)格建議模塊產(chǎn)生高規(guī)格建議,再由管控組件執(zhí)行帶寬規(guī)格升配。
待異常流量結束后,異常檢測模塊將識別出流量已回歸正常,帶寬規(guī)格建議模塊產(chǎn)生帶寬回縮建議,然后再由管控組件執(zhí)行帶寬規(guī)格回縮。在整個變配流程結束之后,將有變配效果跟蹤模塊產(chǎn)出變配期間的性能變化趨勢和效果評估。
目前帶寬自動彈性伸縮在觸發(fā)時機方面,主要是采取對實例的出/入口流量使用率進行異常檢測之后,結合用戶設定的觀測窗口期長度來實現(xiàn)帶寬彈性伸縮的觸發(fā)。觸發(fā)帶寬彈性伸縮后,帶寬規(guī)格推薦算法模塊將基于訓練好的模型結合當前實例的性能數(shù)據(jù)、帶寬規(guī)格以及歷史性能數(shù)據(jù)進行計算,產(chǎn)出更適合當前流量的實例帶寬規(guī)格。帶寬規(guī)格回縮的觸發(fā)時機也是結合了實例的性能數(shù)據(jù)進行判斷,當符合帶寬規(guī)格回縮條件后,將基于帶寬規(guī)格建議模塊產(chǎn)生的帶寬回縮建議進行帶寬規(guī)格的回縮。
核心技術
DAS Auto Scaling服務依賴的是阿里云數(shù)據(jù)庫數(shù)據(jù)鏈路團隊、管控團隊和內(nèi)核團隊的綜合技術,其中主要依賴了如下幾項關鍵技術:
全網(wǎng)數(shù)據(jù)庫實例的秒級數(shù)據(jù)監(jiān)控技術,目前監(jiān)控采集鏈路實現(xiàn)了全網(wǎng)所有數(shù)據(jù)庫實例的秒級采集、監(jiān)控、展現(xiàn)、診斷,可每秒實時處理超過1000萬項監(jiān)控指標,為數(shù)據(jù)庫服務智能化打下了堅實的數(shù)據(jù)基礎。
全網(wǎng)統(tǒng)一的實例管控任務流技術,目前該管控任務流承擔了阿里云全網(wǎng)實例的運維操作執(zhí)行,為Auto Scaling技術的具體執(zhí)行落地提供了可靠的保障。
基于預測和機器學習的時序異常檢測算法,目前的時序異常檢測算法可提供周期性檢測、轉折點判定和連續(xù)異常區(qū)間識別等功能,目前對線上70w+的數(shù)據(jù)庫實例進行1天后數(shù)據(jù)預測,誤差小于5%的實例占比穩(wěn)定在99%以上, 并且預測14天之后的誤差小于5%的實例占比在94%以上。
基于DeepLearning的數(shù)據(jù)庫RT預測模型,該算法可基于數(shù)據(jù)庫實例的CPU使用情況、邏輯讀、物理讀和iops等多項數(shù)據(jù)指標預測出實例運行時的rt值,用于指導數(shù)據(jù)庫對BufferPool內(nèi)存的縮減,為阿里巴巴數(shù)據(jù)庫節(jié)省超27T內(nèi)存,占比總內(nèi)存約17%。
基于云計算架構的下一代關系型數(shù)據(jù)庫PolarDB MySQL版。PolarDB MySQL版是阿里云數(shù)據(jù)庫團隊為云計算時代定制的數(shù)據(jù)庫,其中它的具備計算節(jié)點與存儲節(jié)點分離特性對Auto Scaling提供了強有力的技術保障,能夠避免拷貝數(shù)據(jù)存儲帶來的額外開銷,大幅提升Auto Scaling的體驗。
在上述多項技術的加持下,DAS Auto Scaling目前針對多個引擎提供不同的彈性能力,在解決業(yè)務資源受限問題的同時,能夠保證彈性服務期間的數(shù)據(jù)一致性和完整性,能夠在不影響業(yè)務穩(wěn)定性的情況下實現(xiàn)彈性能力,為業(yè)務保駕護航,具體彈性能力支持情況如下:
彈性服務類型
支持的數(shù)據(jù)庫引擎
計算規(guī)格彈性
RDS MySQL高可用系列云盤版、高可用系列本地盤版(通用型)、三節(jié)點企業(yè)系列(通用型)
PolarDB MySQL版的集群版
Redis社區(qū)版云盤實例、企業(yè)版內(nèi)存型云盤實例
存儲規(guī)格彈性
RDS MySQL高可用系列云盤、集群系列
RDS PostgreSQL高可用系列云盤版
MyBase MySQL高可用云盤版、高可用本地盤
帶寬規(guī)格彈性
Redis本地盤實例
具體案例
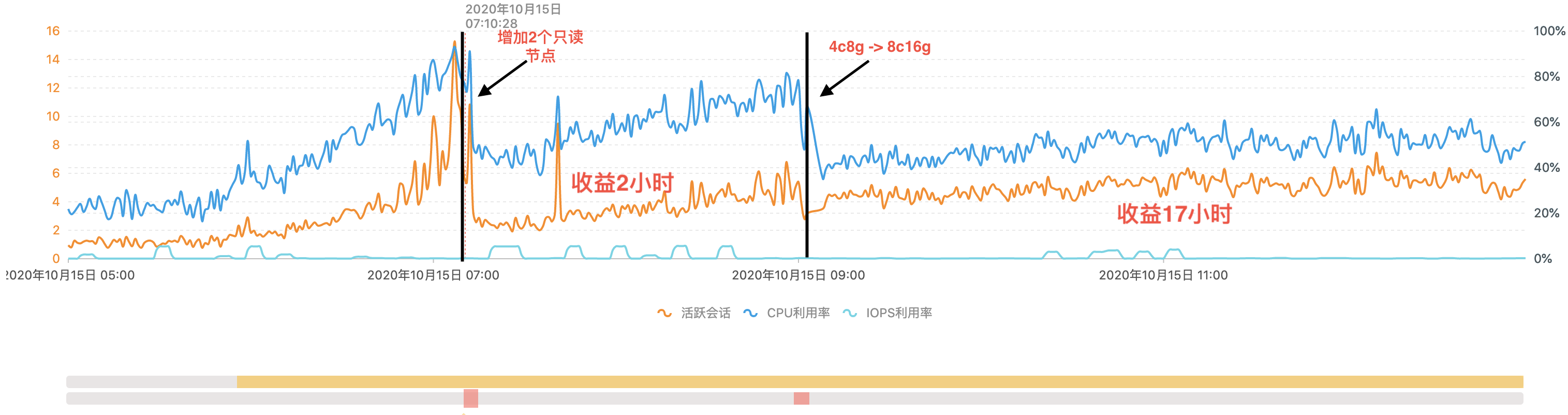
以RDS MySQL實例上的彈性過程為例。在該實例上,用戶配置了15分鐘的觀測窗口以及CPU利用率閾值為80%的觸發(fā)條件。
從上圖可以看出,該實例在07:10突然出現(xiàn)異常流量,導致CPU利用率和活躍會話飆升,CPU利用率上升至80%以上,資源相對緊張。經(jīng)過對實例上的讀寫流量進行分析發(fā)現(xiàn),當前流量中以讀流量為主,DAS Auto Scaling算法判斷通過增加2個只讀節(jié)點緩解CPU資源,且實例的CPU利用率下降到60%,解決了CPU資源緊張的問題。然而隨著用戶業(yè)務的變化,在09:00時CPU再一次打高出現(xiàn)資源緊張的情況,此時的流量分析發(fā)現(xiàn)以寫流量為主,DAS Auto Scaling算法判斷通過提升計算資源規(guī)格緩解CPU資源,且實例的CPU利用率下降到50%,解決了第二次CPU緊張的問題。
從這個實例的業(yè)務使用情況可以看出,DAS Auto Scaling通過2次主動介入,緩解了實例的CPU緊張問題,有效保障數(shù)據(jù)庫實例的業(yè)務穩(wěn)定運行。