基于NVIDIA NIM快速部署LLM模型推理服務(wù)
本文介紹“基于NVIDIA NIM快速部署LLM模型推理服務(wù)”的使用文檔。
概述
NVIDIA NIM 是 NVIDIA AI Enterprise 的一部分, 是一套易于使用的預(yù)構(gòu)建容器工具, 目的是幫助企業(yè)加速生成式 AI 的部署。它支持各種 AI 模型,可確保利用行業(yè)標(biāo)準(zhǔn) API 在本地或云端進(jìn)行無縫、可擴(kuò)展的 AI 推理。本服務(wù)針對(duì)llama3-8b-instruct模型,基于NVIDIA NIM提供了一套開箱即用的方案,本方案可以快速構(gòu)建一個(gè)高性能、可觀測(cè)、靈活彈性的LLM模型推理服務(wù)
前提準(zhǔn)備
使用NVIDIA NIM需要一個(gè)API Key, API Key是一個(gè)身份驗(yàn)證令牌, 從NVIDIA的NGC倉庫下載模型和容器需要使用API Key進(jìn)行身份驗(yàn)證, 只有正確的API Key才能保證部署成功。
本服務(wù)用到的API Key請(qǐng)到此鏈接申請(qǐng),參考下圖所示:
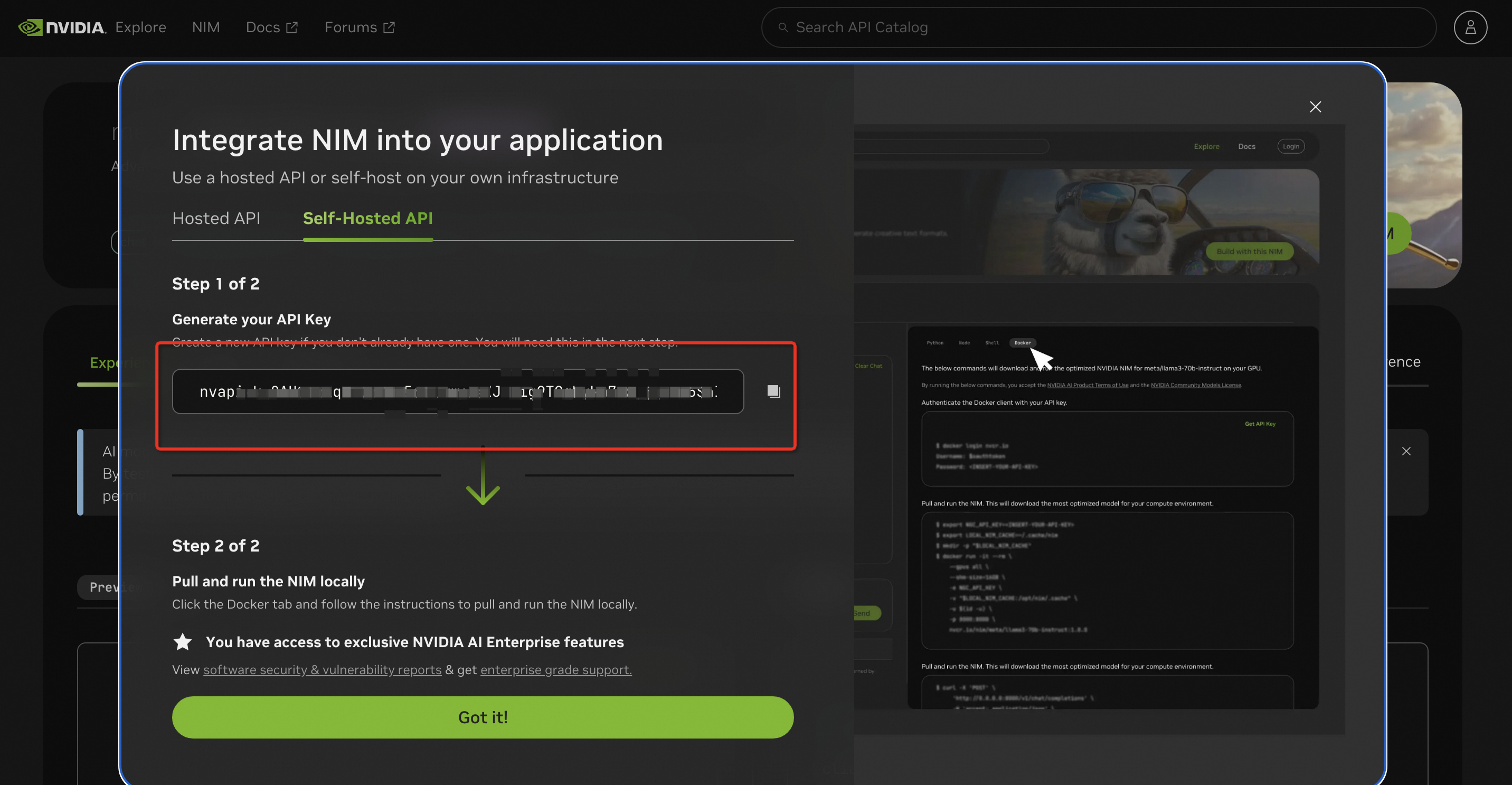
詳情請(qǐng)參考 NVIDIA NIM 文檔,生成 NVIDIA NGC API key,訪問需要部署的模型鏡像。
RAM賬號(hào)所需權(quán)限
部署服務(wù)實(shí)例,需要對(duì)部分阿里云資源進(jìn)行訪問和創(chuàng)建操作。因此您的賬號(hào)需要包含如下資源的權(quán)限。 說明:當(dāng)您的賬號(hào)是RAM賬號(hào)時(shí),才需要添加此權(quán)限
權(quán)限策略名稱 | 備注 |
AliyunECSFullAccess | 管理云服務(wù)器服務(wù)(ECS)的權(quán)限 |
AliyunBSSReadOnlyAccess | 只讀訪問費(fèi)用中心(BSS)的權(quán)限 |
AliyunCSFullAccess | 管理容器服務(wù)(CS)的權(quán)限 |
AliyunVPCFullAccess | 管理專有網(wǎng)絡(luò)(VPC)的權(quán)限 |
AliyunROSFullAccess | 管理資源編排服務(wù)(ROS)的權(quán)限 |
AliyunSLBFullAccess | 管理負(fù)載均衡服務(wù)(SLB)的權(quán)限 |
AliyunComputeNestUserFullAccess | 管理計(jì)算巢服務(wù)(ComputeNest)的用戶側(cè)權(quán)限 |
部署流程
部署步驟
單擊部署鏈接, 進(jìn)入服務(wù)實(shí)例部署界面,根據(jù)界面提示,填寫參數(shù)完成部署。
其中NVIDIA NGC API Key的設(shè)置就是前提準(zhǔn)備中申請(qǐng)的值。
參數(shù)填寫完成后可以看到對(duì)應(yīng)詢價(jià)明細(xì),確認(rèn)參數(shù)后點(diǎn)擊下一步:確認(rèn)訂單。

確認(rèn)訂單完成后同意服務(wù)協(xié)議并點(diǎn)擊立即創(chuàng)建進(jìn)入部署階段。
等待部署完成后就可以開始使用服務(wù),進(jìn)入服務(wù)實(shí)例詳情查看使用說明。通過cURL發(fā)送HTTP請(qǐng)求訪問推理服務(wù),修改content的內(nèi)容,即可自定義和推理服務(wù)交互的內(nèi)容。

使用流程
根據(jù)服務(wù)實(shí)例詳情頁中使用說明的描述,發(fā)送請(qǐng)求到推理服務(wù),例如在終端中使用cURL發(fā)送HTTP請(qǐng)求,修改content的內(nèi)容,即可自定義和推理服務(wù)交互的內(nèi)容。 如下圖所示為與推理服務(wù)兩次進(jìn)行交互的請(qǐng)求和響應(yīng)。

FAQ
部署卡到81%是什么原因?該怎么解決?
部署流程卡到81%大概率是部署的時(shí)候拉取鏡像和模型失敗了,需要到ACK集群里確定具體原因。以下是具體排查步驟和解決方案:
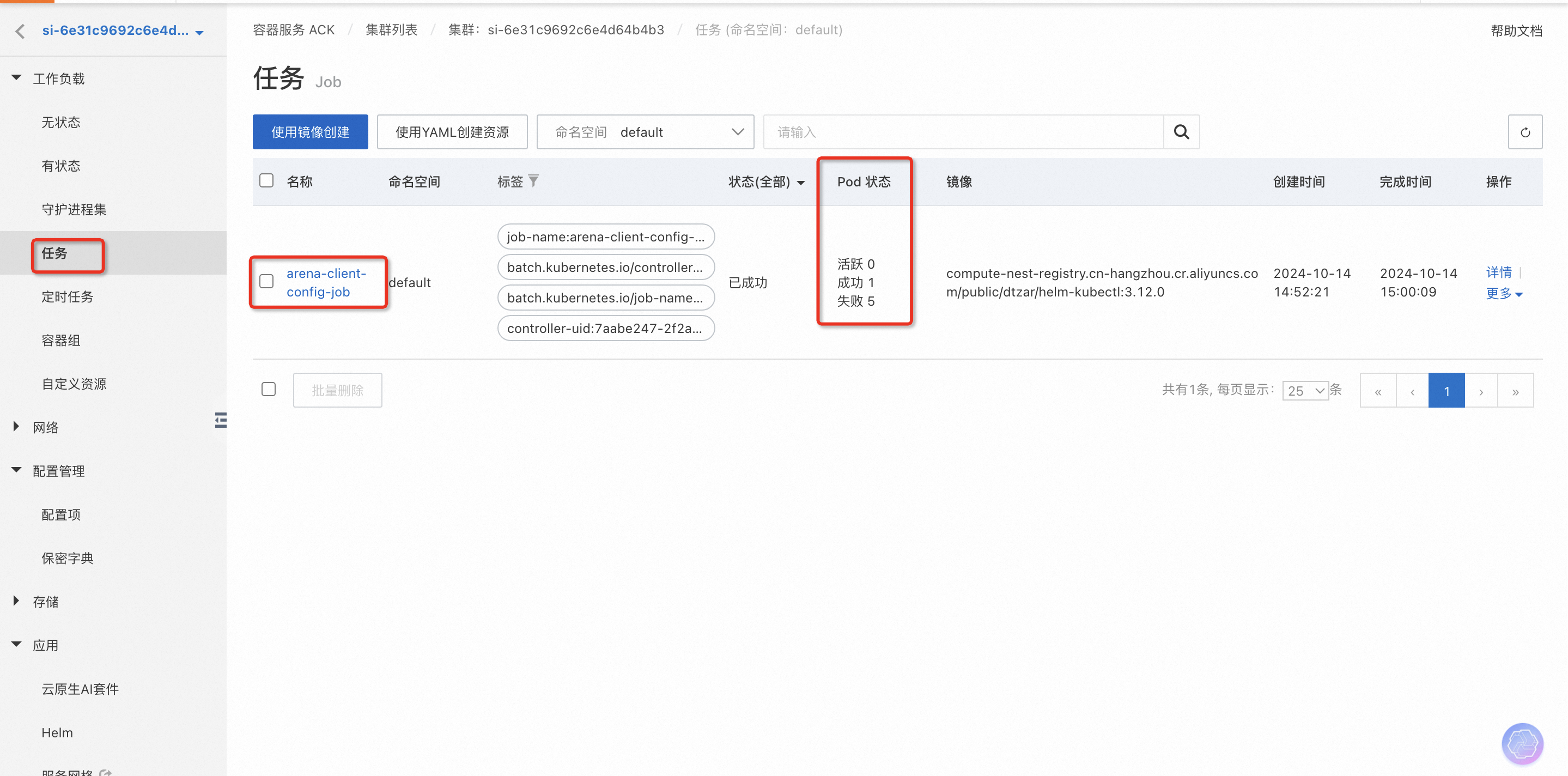
在計(jì)算巢服務(wù)實(shí)例->資源標(biāo)簽下找到Kubernetes集群,進(jìn)去到ACK控制臺(tái)查看集群狀態(tài)
在任務(wù)中查看“arena-client-config-job”這個(gè)job的狀態(tài),看是否有成功的Pod, 有失敗的Pod是正常的,一般在失敗5個(gè)之后會(huì)有成功的,若一直沒有成功的Pod,可點(diǎn)擊進(jìn)去查看Job的執(zhí)行日志。
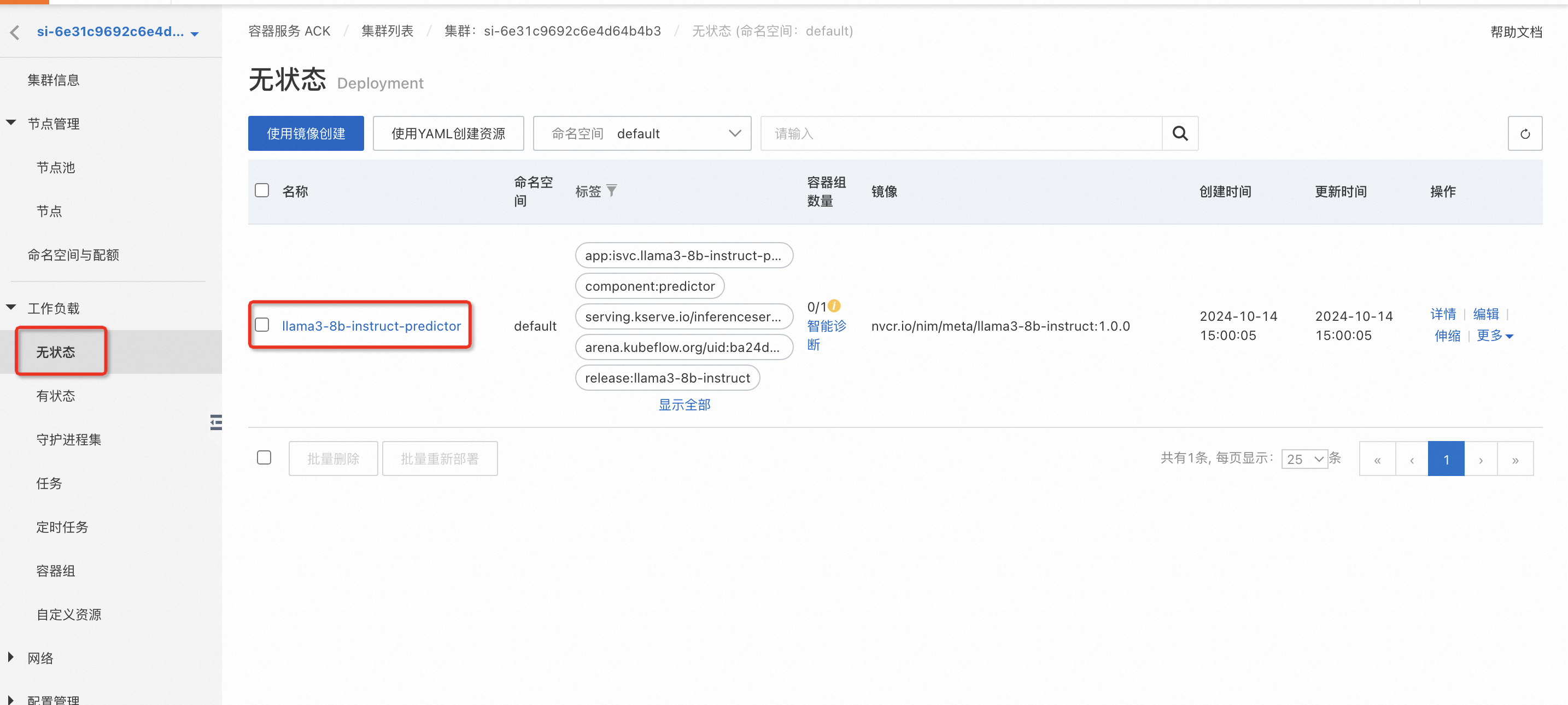
若上述有成功的Pod, 在無狀態(tài)中查看“l(fā)lama3-8b-instruct-predictor”的狀態(tài)
查看Pod的事件,如果是以下報(bào)錯(cuò),說明是API Key設(shè)置的不正確,或者API Key已經(jīng)失效,導(dǎo)致鏡像下載失敗。

針對(duì)上述API Key失效的問題,需要按照前提準(zhǔn)備章節(jié)中的說明,重新申請(qǐng)NVIDIA API Key, 并有兩種解決方案:
方案一:刪掉當(dāng)前部署的服務(wù)實(shí)例,使用重新申請(qǐng)的NVIDIA API Key 重新部署新的服務(wù)實(shí)例,推薦此種方法,更加簡單。
方案二:針對(duì)當(dāng)前環(huán)境,手動(dòng)修改集群中的相關(guān)配置,步驟如下
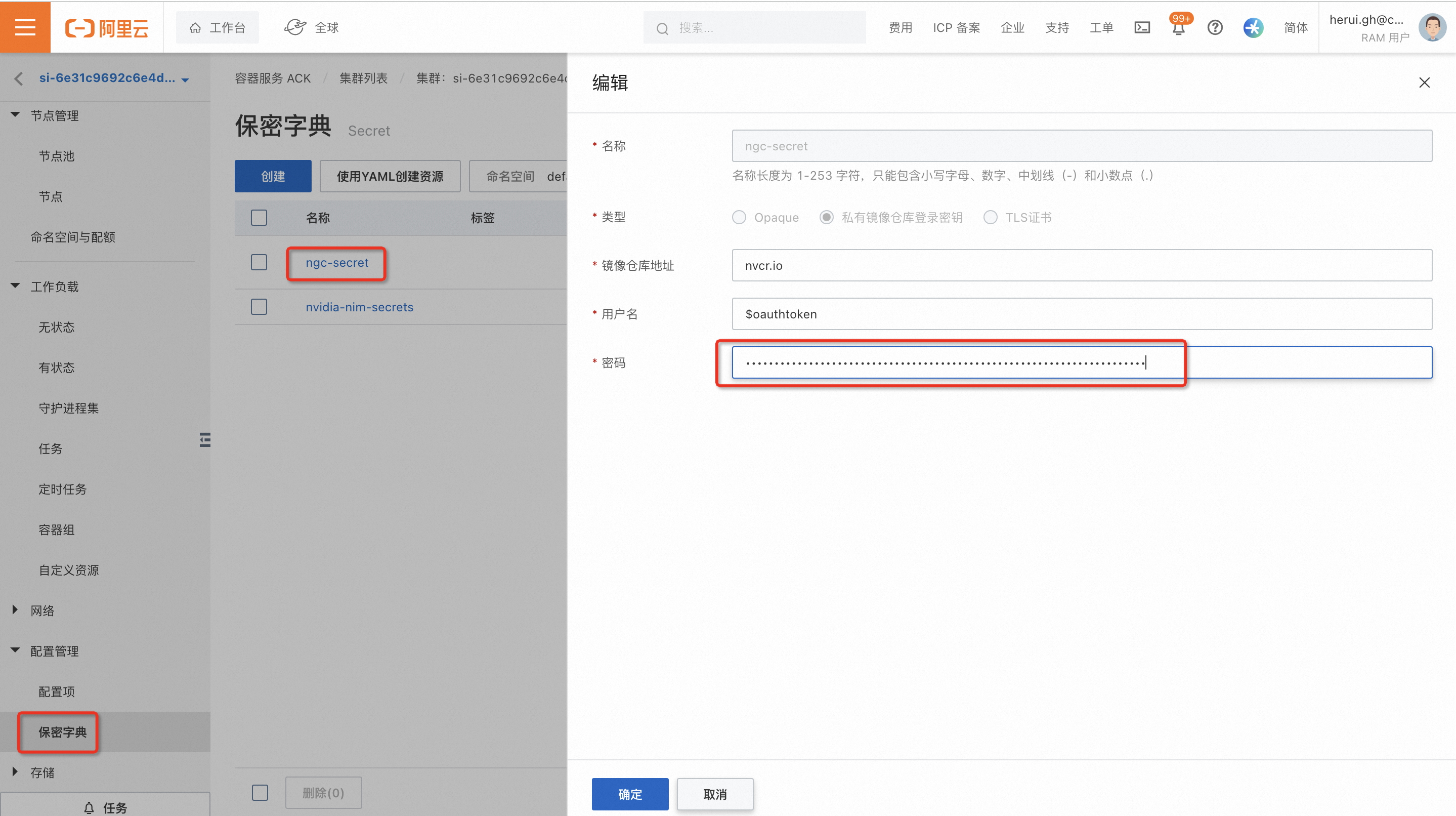
按照下圖編輯Secret中“ngc-secret”和"nvidia-nim-secrets"中的相關(guān)配置,設(shè)置為重新申請(qǐng)的NVIDIA API Key。

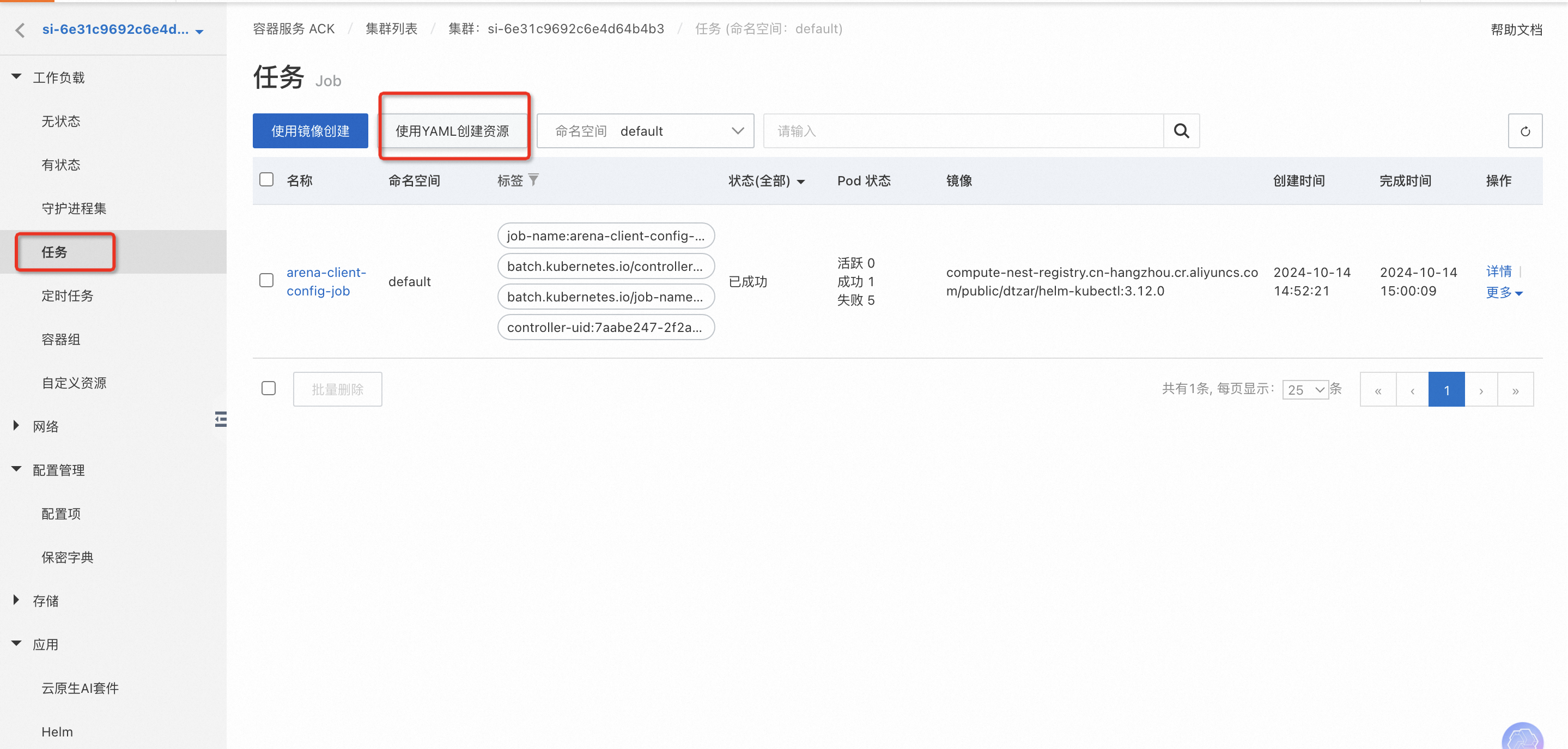
在任務(wù)中點(diǎn)擊“使用Yaml創(chuàng)建資源”
將以下內(nèi)容粘貼進(jìn)去并點(diǎn)擊創(chuàng)建
apiVersion: batch/v1 kind: Job metadata: name: arena-client-config-job-1 namespace: default spec: template: metadata: name: arena-client-config-job-1 spec: containers: - args: - > # 輸出job日志 set -x cd ~ mkdir -p ~/.kube echo '' | base64 -d >> ~/.kube/config #安裝Arena 客戶端 wget 'https://computenest-artifacts-cn-hangzhou.oss-cn-hangzhou-internal.aliyuncs.com/1853370294850618/cn-beijing/1728874973220/arena-installer-0.9.16-881780f-linux-amd64.tar.gz' -O arena-installer-0.9.16-881780f-linux-amd64.tar.gz tar -xvf arena-installer-0.9.16-881780f-linux-amd64.tar.gz cd arena-installer bash install.sh --only-binary #部署KServe推理服務(wù) arena serve delete llama3-8b-instruct arena serve kserve \ --name=llama3-8b-instruct \ --image=nvcr.io/nim/meta/llama3-8b-instruct:1.0.0 \ --image-pull-secret=ngc-secret \ --gpus=1 \ --cpu=4 \ --memory=16Gi \ --share-memory=16Gi \ --port=8000 \ --security-context runAsUser=0 \ --annotation=serving.kserve.io/autoscalerClass=external \ --env NIM_CACHE_PATH=/mnt/models \ --env-from-secret NGC_API_KEY=nvidia-nim-secrets \ --enable-prometheus=true \ --metrics-port=8000 \ --data=nim-model:/mnt/models command: - /bin/sh - '-c' - '--' image: >- compute-nest-registry.cn-hangzhou.cr.aliyuncs.com/public/dtzar/helm-kubectl:3.12.0 imagePullPolicy: IfNotPresent name: arena-client-config-job resources: {} terminationMessagePath: /dev/termination-log terminationMessagePolicy: File dnsPolicy: ClusterFirst restartPolicy: Never schedulerName: default-scheduler securityContext: {} serviceAccount: arena-client-sa serviceAccountName: arena-client-sa
觀察無狀態(tài)中“l(fā)lama3-8b-instruct-predictor”的狀態(tài),啟動(dòng)成功后就是部署成功了。