產品整體介紹
云原生數據倉庫AnalyticDB PostgreSQL版提供PB級數據實時交互式分析、ETL/ELT、BI報表展示功能,支持數據高吞吐實時寫入與批量導入,提供ACID保證和標準事務隔離級別,采用MPP全并行架構,是一款具有高性價比的云原生數倉產品,提供基于阿里云生態的公共云和混合云服務。
概述
AnalyticDB PostgreSQL版支持JDBC/ODBC連接,支持SQL 2003語法標準,兼容PostgreSQL,Greenplum,和部分Oracle語法,同時提供PL/pgSQL存儲過程。另外在SQL基礎上,支持Apache MADLib機器學習,PostGIS地理位置分析,以及JSON/JSONB半結構化數據,圖片音頻等非結構化數據與結構化數據融合分析功能。
在部署形態層面,AnalyticDB PostgreSQL版提供阿里云公共云服務,按量付費,支持垂直升降配和水平擴容,另外支持存儲容量獨立在線擴容;同時提供阿里云企業版,和敏捷版DBStack混合云部署形態,同時支持X86和ARM平臺。
在第三方認證層面,AnalyticDB PostgreSQL版通過了“國際數據庫TPC官方TPC-H 30TB認證”(性價比綜合排名第一),信通院“分布式事務型數據庫基礎能力評測”(TPC-C)和“分布式分析型數據庫大規模性能認證”(640節點 TPC-DS 100TB)。
技術架構
以下為AnalyticDB PostgreSQL版的架構圖,主要包含Master Node和Compute Node兩大組件,中間通過Interconnect進行互聯通信和數據交換傳輸。
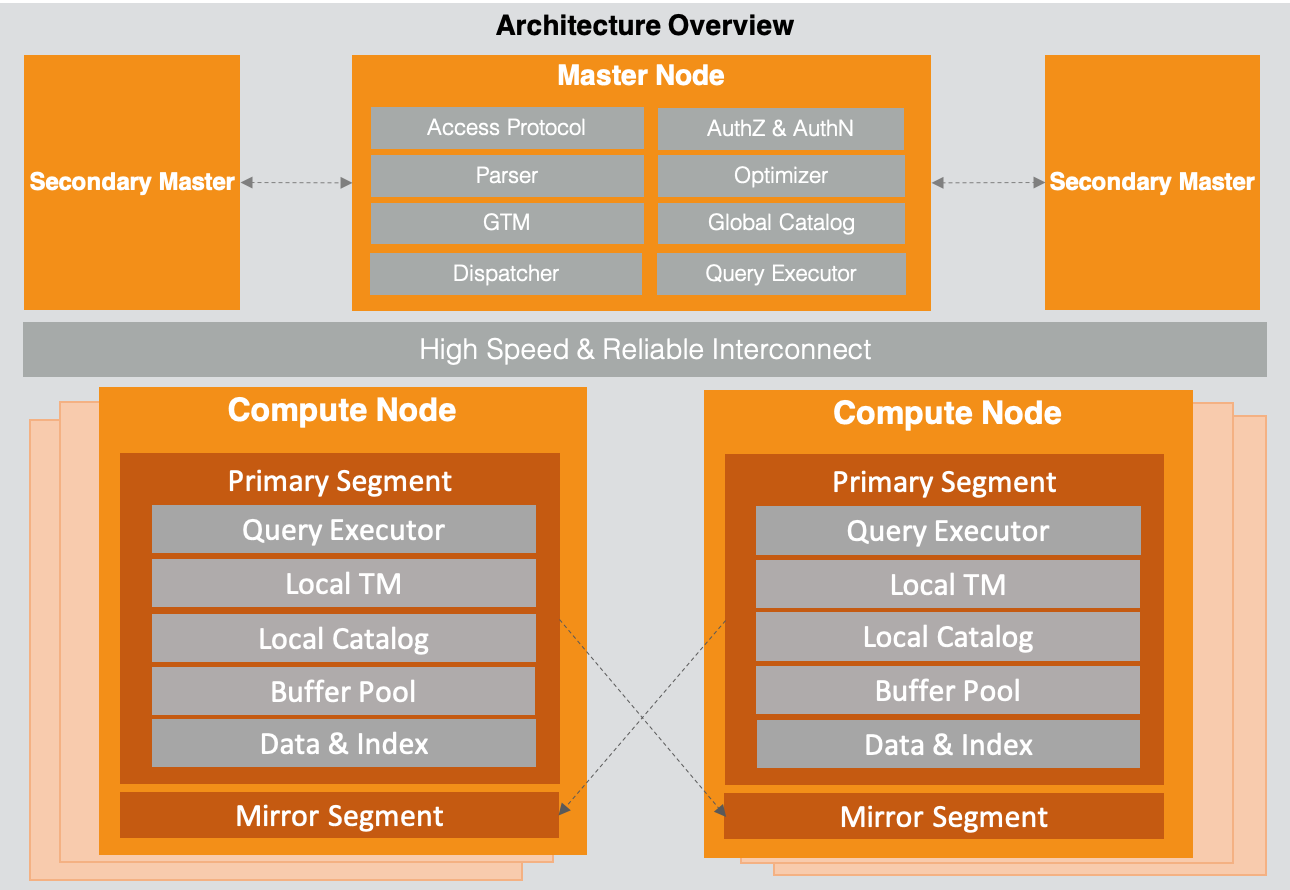
Master Node和Compute Node提供多副本保障服務高可用和數據高可靠,同時均支持通過Scale Out水平擴展來提高集群整體寫入查詢并發和吞吐。
模塊組件
Master Node
Master Node主要負責客戶端連接協議層接入(Access Protocol),認證和鑒權(Authorization & Authentication),SQL解析(Parser),重寫(Rewrite),優化(Optimizer),和執行分發協調(Dispatcher)。
另外,Master Node還包含全局事務管理器(Global Transaction Manager),負責全局事務ID、快照生成和分布式事務管理;全局元數據目錄(Global Catalog)則記錄了用戶,庫,表,視圖,索引,分布分區等數據庫對象的元數據信息。
Compute Node
Compute Node包含了一組Segment,部署形態上可以是物理機,VM或者容器。
Segment
Segment是負責具體的SQL執行和數據存儲節點。其中本地元數據(Local Catalog,與Master Node Global Catalog保持同步)起到加速執行的功能(Segment無需每次訪問Master Node獲得元數據信息);本地事務管理器(Local Transaction Manager)提供本地事務能力;緩存管理器(Buffer Pool)則提供了數據的讀寫緩存,用于提升讀寫性能。
執行引擎(Query Executor)通過向量化(Vectorization)和即時編譯(JIT)等技術,相比傳統逐行計算的火山模型獲得數倍性能提升。
數據和索引(Data & Index)支持行存表,列存表,和外表以及相應索引:
行存表:數據按行存放,支持主鍵,B+樹索引,Bitmap索引,GIN索引等,適合數據實時寫入更新刪除,點查,范圍查,通過MVCC提供事務能力。
列存表:數據按列存放,高壓縮比,適合追加寫(少量更新刪除)場景。通過B+樹索引支持高效點查,同時在block級別提供min&max輕量級索引,數據可按多列進行多維排序,支持任意排序列的組合過濾,支持高效分析場景。
外表:元數據存放在本地系統表,數據存放在OSS,支持的數據格式包括ORC,Parquet,CSV,JSON,支持表分區,其中ORC和Parquet支持列過濾和謂詞下推,提升分析性能。除OSS外,同時也支持Hadoop(HDFS, Hive)外表。

組件交互
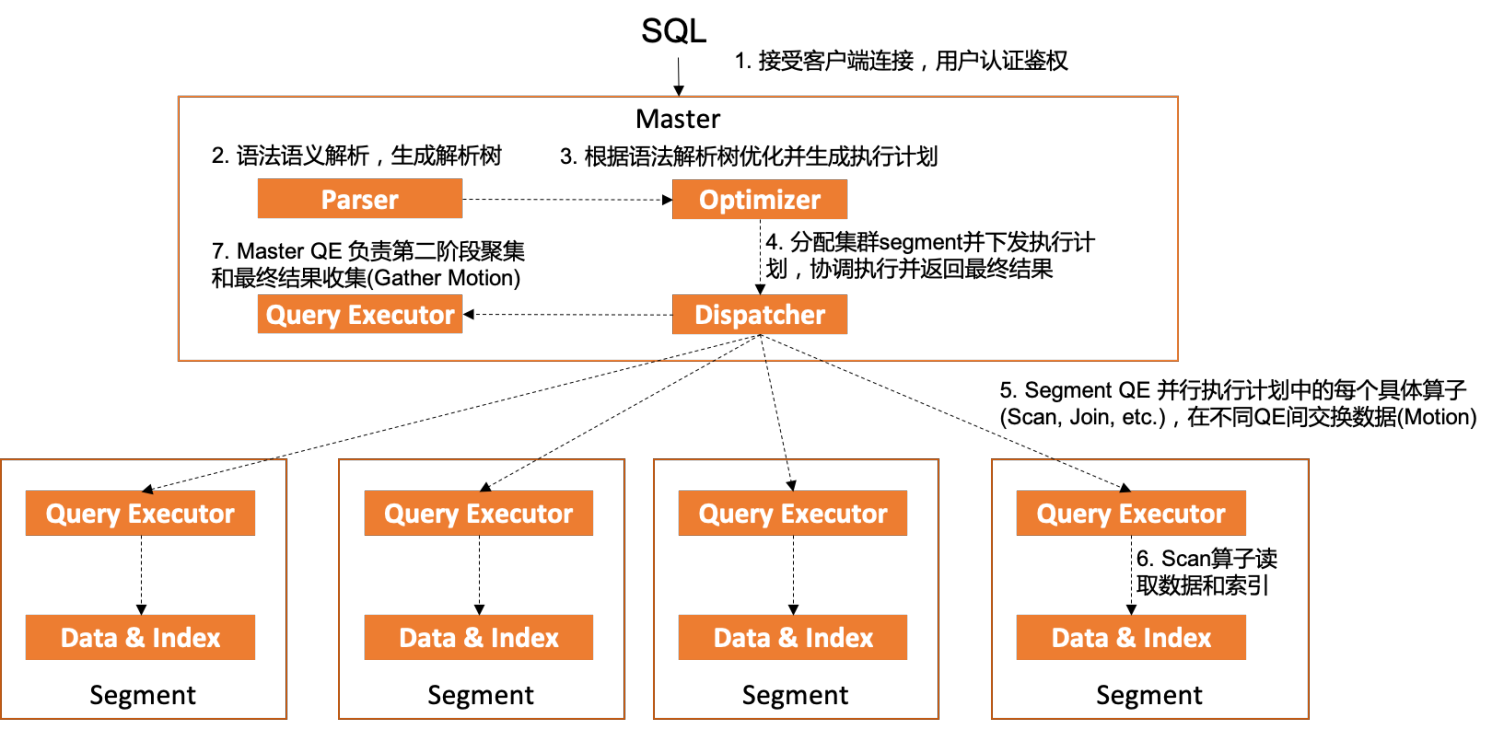
下圖展示了客戶端從建立連接到執行一條完整SQL整個過程中上述主要模塊組件的交互和執行流程。
數據模型
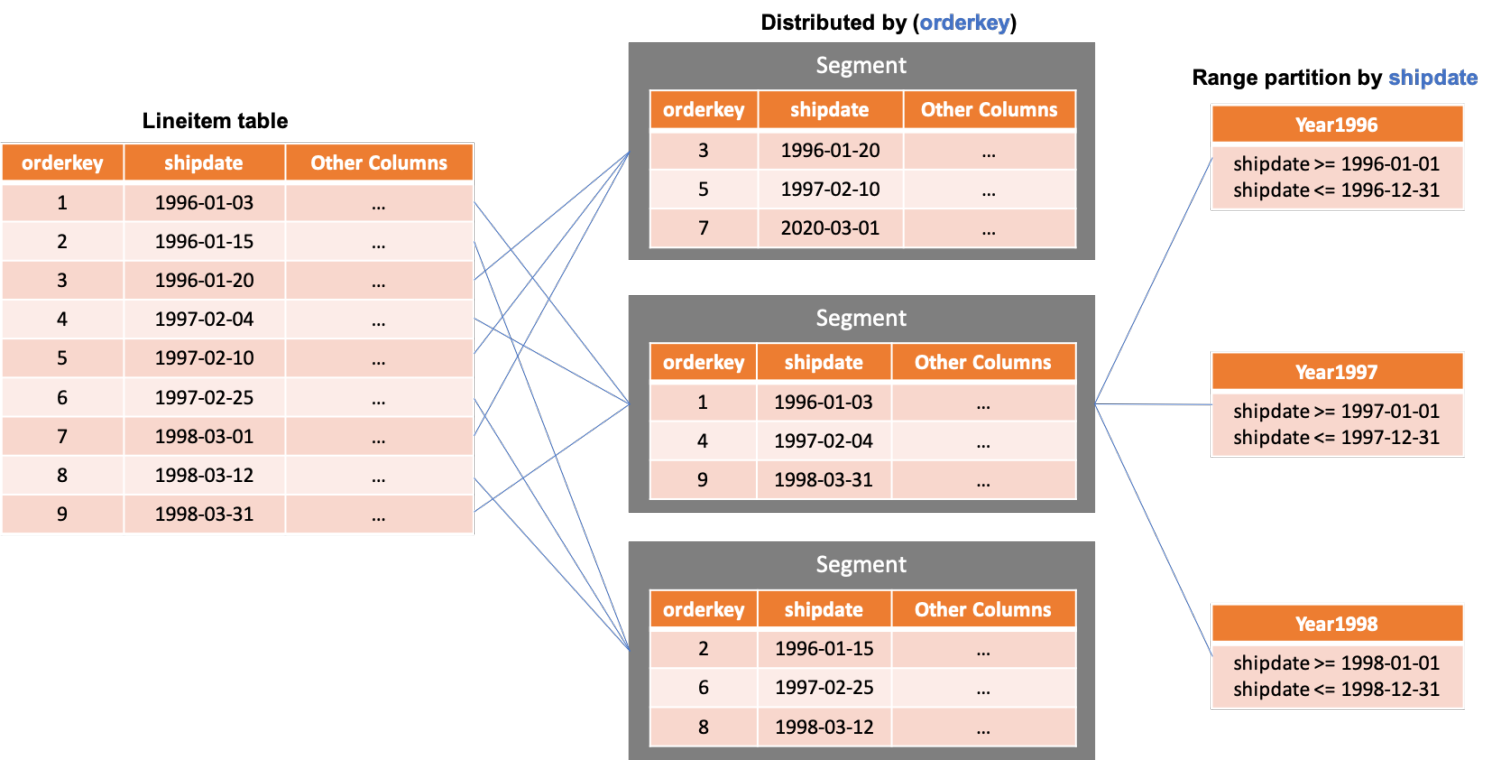
將表數據均勻的分布到各個節點中,是發揮集群整體IO性能,提升存儲容量,優化計算與網絡傳輸效率的關鍵。除了默認的哈希分布策略,AnalyticDB PostgreSQL版還支持復制分布和隨機分布。復制分布是指在每個存儲節點上都存放該表的全量數據,通常用于經常被關聯查詢的小表,在執行相應查詢時無需數據廣播或重分布環節,提升查詢性能。另外也支持隨機分布策略,主要場景是當前表字段中無合適字段作為hash分布列(比如會引起各個節點數據傾斜),同時該表也不小(不適合復制策略),隨機分布可以讓該表數據被均勻擺放到各節點。
在將表數據分布到各個存儲節點后,在單個節點上根據業務場景可對表數據進行分區,在執行具體查詢時進行分區裁剪,縮小查找和數據處理范圍。AnalyticDB PostgreSQL版支持范圍和列表分區類型,同時支持多級分區。下圖展示了一張用戶表顯示通過ID列hash分布到3個節點,然后在每個節點上按date列進行范圍分區,然后再按city列進行列表分區。圖中最右邊的每個分區都對應了一份數據存儲和索引。這些分區表可以是行存表,也可以是列存表,或者外表。比如業務上完全可以對最近需要寫入的分區(Mar)使用行存表,過去已經歸檔的分區(Feb)使用列存表,出于降低成本考慮,也可以對較少查詢的分區(Jan)使用OSS外表。
數據庫對象
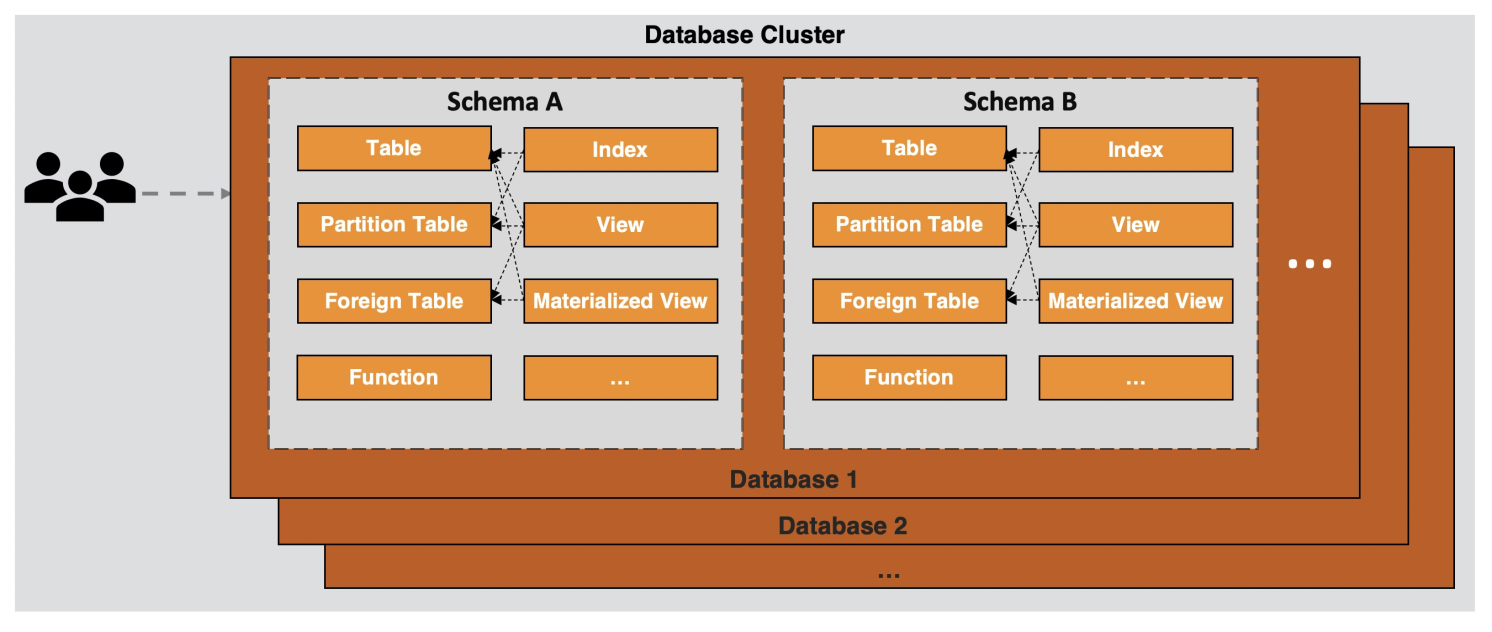
AnalyticDB PostgreSQL版不僅僅是關系型也是對象-關系型,數據庫的對象通常包括:表、視圖、函數、序列、索引、分區子表、外部表等,而對象-關系型則進一步支持用戶自定義對象和它的屬性,包括數據類型、函數、操作符,域和索引,甚至復雜的數據結構也可以被創建,存儲和檢索。這些對象將按照邏輯劃分成不同的集合即組成模式(schema),每當新數據庫創建后,都會默認為數據庫創建模式public,這也是該數據庫的默認模式,并且允許每個用戶(角色)進行訪問,所有為此數據庫創建的對象一般都將默認在這個模式中。
數據庫是數據庫對象的物理集合,而模式則是數據庫內部用于組織管理數據庫對象的邏輯集合,模式之下則是各種應用程序會接觸到的對象,比如表、索引、數據類型、函數、操作符等。使用模式把數據庫對象組織成邏輯組,讓它們便于管理,允許多個用戶(角色)使用同一個數據庫不會互相干擾。
用戶(角色)是數據庫(集群)全局范圍內的權限控制系統,用于各種集群范圍內所有的對象權限管理。用戶不特定于某個單獨的數據庫,如果需要登錄數據庫管理系統則必須連接到一個數據庫上,用戶可以擁有各種數據庫對象。
缺省情況下,用戶看不到模式中不屬于他們所有的對象,需要對象所有者賦予相應權限。如果已經被賦予適當的權限,用戶也可以在別的用戶模式里創建對象。請注意,缺省每個用戶都在public模式上有創建對象的權限,比如新建一個表并讀寫數據。
在AnalyticDB PostgreSQL版數據庫中,所有對象作為系統元數據將同時被保存在Master服務器和Segment服務器上。