通過外表導入至數倉版
AnalyticDB for MySQL支持通過外表導入導出數據。本文介紹如何通過外表查詢HDFS數據,并將HDFS數據導入至AnalyticDB for MySQL。
前提條件
AnalyticDB for MySQL集群需為V3.1.4.4或以上版本。
說明查看企業版或湖倉版集群的內核版本,請執行
SELECT adb_version();。如需升級內核版本,請聯系技術支持。HDFS數據文件格式需為CSV、Parquet或ORC。
已創建HDFS集群并在HDFS文件夾中準備需要導入的數據,本文示例中所用文件夾為hdfs_import_test_data.csv。
已在HDFS集群中為AnalyticDB for MySQL集群配置如下服務訪問端口:
namenode:用于讀寫文件系統元信息。您可以在fs.defaultFS參數中配置端口號,默認端口號為8020。詳細配置方式,請參見core-default.xml。
datanode:用于讀寫數據。您可以在dfs.datanode.address參數中配置端口號,默認端口號為50010。詳細配置方式,請參見hdfs-default.xml。
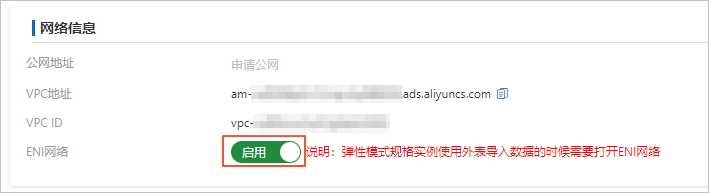
如果您的AnalyticDB for MySQL集群是彈性模式,您需要在集群信息頁面的網絡信息區域,打開啟用ENI網絡的開關。
操作步驟
連接目標AnalyticDB for MySQL集群。詳細操作步驟,請參見連接集群。
創建目標數據庫。詳細操作步驟,請參見創建數據庫。
本示例中,AnalyticDB for MySQL集群的目標庫名為
adb_demo。使用
CREATE TABLE語句在目標庫adb_demo中創建CSV、Parquet或ORC格式的外表。創建普通外表。具體語法,請參見創建HDFS外表。
創建帶分區外表。具體語法,請參見創建帶分區的HDFS外表。
創建目標表。
您可以使用以下語句在目標數據庫
adb_demo中創建一張目標表,用于存儲從HDFS導入的數據:創建普通外表對應的目標表(本文示例中目標表名為
adb_hdfs_import_test),語法如下。CREATE TABLE IF NOT EXISTS adb_hdfs_import_test ( uid string, other string ) DISTRIBUTED BY HASH(uid);創建帶分區外表對應的目標表時(本文示例中目標表名為
adb_hdfs_import_parquet_partition),需要同時在創建語句中定義普通列(如uid和other)和分區列(如p1、p2和p3),語法如下。CREATE TABLE IF NOT EXISTS adb_hdfs_import_parquet_partition ( uid string, other string, p1 date, p2 int, p3 varchar ) DISTRIBUTED BY HASH(uid);
將HDFS中的數據導入至目標AnalyticDB for MySQL集群中。
您可以根據業務需要選擇如下幾種方式導入數據(分區表導入數據語法與普通表一致,如下示例中以普通表為例):
(推薦)方式一:使用
INSERT OVERWRITE導入數據。數據批量導入,性能好。導入成功后數據可見,導入失敗數據會回滾,示例如下。INSERT OVERWRITE adb_hdfs_import_test SELECT * FROM hdfs_import_test_external_table;方式二:使用
INSERT INTO導入數據。數據插入實時可查,數據量較小時使用,示例如下。INSERT INTO adb_hdfs_import_test SELECT * FROM hdfs_import_test_external_table;方式三:異步執行導入數據,示例如下。
SUBMIT JOB INSERT OVERWRITE adb_hdfs_import_test SELECT * FROM hdfs_import_test_external_table;返回結果如下。
+---------------------------------------+ | job_id | +---------------------------------------+ | 2020112122202917203100908203303****** | +---------------------------------------+您還可以根據上述
job_id查看異步任務的狀態,更多詳情,請參見異步提交導入任務。
后續步驟
導入完成后,您可以登錄AnalyticDB for MySQL的目標庫adb_demo中,執行如下語句查看并驗證源表數據是否成功導入至目標表adb_hdfs_import_test中:
SELECT * FROM adb_hdfs_import_test LIMIT 100;創建HDFS外表
創建文件格式為CSV的外表
語句如下:
CREATE TABLE IF NOT EXISTS hdfs_import_test_external_table ( uid string, other string ) ENGINE='HDFS' TABLE_PROPERTIES='{ "format":"csv", "delimiter":",", "hdfs_url":"hdfs://172.17.***.***:9000/adb/hdfs_import_test_csv_data/hdfs_import_test_data.csv" }';參數
是否必填
說明
ENGINE='HDFS'必填
外表的存儲引擎說明。本示例使用的存儲引擎為HDFS。
TABLE_PROPERTIESAnalyticDB for MySQL訪問HDFS數據的方式。
format數據文件的格式。創建CSV格式文件的外表時需設置為
csv。delimiter定義CSV數據文件的列分隔符。本示例使用的分隔符為英文逗號(,)。
hdfs_urlHDFS集群中目標數據文件或文件夾的絕對地址,需要以
hdfs://開頭。示例:
hdfs://172.17.***.***:9000/adb/hdfs_import_test_csv_data/hdfs_import_test_data.csvpartition_column選填
定義外表的分區列,用英文逗號(,)切分各列。定義分區列的方法,請參見創建帶分區的HDFS外表。
compress_type定義數據文件的壓縮類型,CSV格式的文件目前僅支持Gzip壓縮類型。
skip_header_line_count定義導入數據時需要在開頭跳過的行數。CSV文件第一行為表頭,若設置該參數為1,導入數據時可自動跳過第一行的表頭。
默認為0,即不跳過。
hdfs_ha_host_port如果HDFS集群配置了HA功能,創建外表時需配置
hdfs_ha_host_port參數,格式為ip1:port1,ip2:port2,參數中的IP與Port是主備namenode的IP與Port。示例:
192.168.xx.xx:8020,192.168.xx.xx:8021創建HDFS Parquet格式/HDFS ORC格式的外表
以Parquet格式為例,創建HDFS外表語句如下:
CREATE TABLE IF NOT EXISTS hdfs_import_test_external_table ( uid string, other string ) ENGINE='HDFS' TABLE_PROPERTIES='{ "format":"parquet", "hdfs_url":"hdfs://172.17.***.***:9000/adb/hdfs_import_test_parquet_data/" }';參數
是否必填
說明
ENGINE='HDFS'必填
外表的存儲引擎說明。本示例使用的存儲引擎為HDFS。
TABLE_PROPERTIESAnalyticDB for MySQL訪問HDFS數據的方式。
format數據文件的格式。
創建Parquet格式文件的外表時需設置為
parquet。創建ORC格式文件的外表時需設置為
orc。
hdfs_urlHDFS集群中目標數據文件或文件夾的絕對地址,需要以
hdfs://開頭。partition_column選填
定義表的分區列,用英文逗號(,)切分各列。定義分區列的方法,請參見創建帶分區的HDFS外表。
hdfs_ha_host_port如果HDFS集群配置了HA功能,創建外表時需配置
hdfs_ha_host_port參數,格式為ip1:port1,ip2:port2,參數中的IP與Port是主備namenode的IP與Port。示例:
192.168.xx.xx:8020,192.168.xx.xx:8021說明外表創建語句中的列名需與Parquet或ORC文件中該列的名稱完全相同(可忽略大小寫),且列的順序需要一致。
創建外表時,可以僅選擇Parquet或ORC文件中的部分列作為外表中的列,未被選擇的列不會被導入。
如果創建外表創建語句中出現了Parquet或ORC文件中不存在的列,針對該列的查詢結果均會返回NULL。
Parquet文件與AnalyticDB for MySQL的數據類型映射關系
Parquet基本類型
Parquet的logicalType類型
AnalyticDB for MySQL的數據類型
BOOLEAN
無
BOOLEAN
INT32
INT_8
TINYINT
INT32
INT_16
SMALLINT
INT32
無
INT或INTEGER
INT64
無
BIGINT
FLOAT
無
FLOAT
DOUBLE
無
DOUBLE
FIXED_LEN_BYTE_ARRAY
BINARY
INT64
INT32
DECIMAL
DECIMAL
BINARY
UTF-8
VARCHAR
STRING
JSON(如果已知Parquet該列內容為JSON格式)
INT32
DATE
DATE
INT64
TIMESTAMP_MILLIS
TIMESTAMP或DATETIME
INT96
無
TIMESTAMP或DATETIME
重要Parquet格式外表暫不支持
STRUCT類型,會導致建表失敗。ORC文件與AnalyticDB for MySQL的數據類型映射關系
ORC文件中的數據類型
AnalyticDB for MySQL中的數據類型
BOOLEAN
BOOLEAN
BYTE
TINYINT
SHORT
SMALLINT
INT
INT或INTEGER
LONG
BIGINT
DECIMAL
DECIMAL
FLOAT
FLOAT
DOUBLE
DOUBLE
BINARY
STRING
VARCHAR
VARCHAR
STRING
JSON(如果已知ORC該列內容為JSON格式)
TIMESTAMP
TIMESTAMP或DATETIME
DATE
DATE
重要ORC格式外表暫不支持
LIST、STRUCT和UNION等復合類型,會導致建表失敗。ORC格式外表的列使用MAP類型可以建表,但ORC的查詢會失敗。
創建帶分區的HDFS外表
HDFS支持對Parquet、CSV和ORC文件格式的數據進行分區,包含分區的數據會在HDFS上形成一個分層目錄。在下方示例中,p1為第1級分區,p2為第2級分區,p3為第3級分區:
parquet_partition_classic/
├── p1=2020-01-01
│ ├── p2=4
│ │ ├── p3=SHANGHAI
│ │ │ ├── 000000_0
│ │ │ └── 000000_1
│ │ └── p3=SHENZHEN
│ │ └── 000000_0
│ └── p2=6
│ └── p3=SHENZHEN
│ └── 000000_0
├── p1=2020-01-02
│ └── p2=8
│ ├── p3=SHANGHAI
│ │ └── 000000_0
│ └── p3=SHENZHEN
│ └── 000000_0
└── p1=2020-01-03
└── p2=6
├── p2=HANGZHOU
└── p3=SHENZHEN
└── 000000_0以Parquet格式為例,創建外表時指定列的建表語句示例如下:
CREATE TABLE IF NOT EXISTS hdfs_parquet_partition_table
(
uid varchar,
other varchar,
p1 date,
p2 int,
p3 varchar
)
ENGINE='HDFS'
TABLE_PROPERTIES='{
"hdfs_url":"hdfs://172.17.***.**:9000/adb/parquet_partition_classic/",
"format":"parquet", //如需創建CSV或ORC格式外表,僅需將format的取值改為csv或orc。
"partition_column":"p1, p2, p3" //針對包含分區的HDFS數據,如需以分區的模式進行查詢,那么在導入數據至AnalyticDB MySQL時就需要在外表創建語句中指定分區列partition_column。
}';TABLE_PROPERTIES中的partition_column參數用于指定分區列(本例中的p1、p2、p3)。且partition_column參數中的分區列必須按照第1級、第2級、第3級的順序聲明(本例中p1為第1級分區,p2為第2級分區,p3為第3級分區)。列定義中必須定義分區列(本例中的p1、p2、p3)及類型,且分區列需要置于列定義的末尾。
列定義中分區列的先后順序需要與
partition_column中分區列的順序保持一致。分區列支持的數據類型包括:
BOOLEAN、TINYINT、SMALLINT、INT、INTEGER、BIGINT、FLOAT、DOUBLE、DECIMAL、VARCHAR、STRING、DATE、TIMESTAMP。查詢數據時,分區列和其它數據列的展示和用法沒有區別。
不指定format時,默認格式為CSV。
其他參數的詳細說明,請參見參數說明。