導出至HDFS
AnalyticDB for MySQL支持通過外表導入導出數據。本文介紹如何通過外表將AnalyticDB for MySQL數倉版數據導出至HDFS。
前提條件
AnalyticDB for MySQL集群需為V3.1.4.4或以上版本。
說明查看企業版或湖倉版集群的內核版本,請執行
SELECT adb_version();。如需升級內核版本,請聯系技術支持。已創建HDFS集群,并在HDFS集群中創建了一個新的文件夾(本示例中文件夾名為hdfs_output_test_csv_data),用于保存導入的AnalyticDB for MySQL數據。
說明使用
INSERT OVERWRITE進行導入時,系統會覆蓋目標文件夾下的原始文件。為避免原始文件被覆蓋,建議在導出時創建一個新的目標文件夾。已在HDFS集群中為AnalyticDB for MySQL集群配置如下服務訪問端口:
namenode:用于讀寫文件系統元信息。您可以在fs.defaultFS參數中配置端口號,默認端口號為8020。詳細配置方式,請參見core-default.xml。
datanode:用于讀寫數據。您可以在dfs.datanode.address參數中配置端口號,默認端口號為50010。詳細配置方式,請參見hdfs-default.xml。
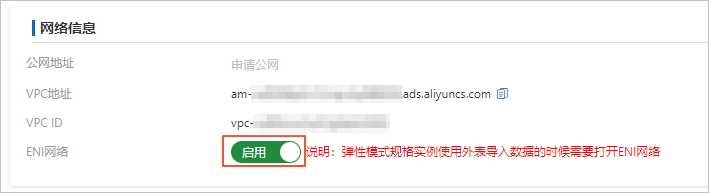
如果您的AnalyticDB for MySQL集群是彈性模式,您需要在集群信息頁面的網絡信息區域,打開啟用ENI網絡的開關。
注意事項
AnalyticDB for MySQL集群僅支持導出文件格式為CSV和Parquet的數據至HDFS。不支持導出文件格式為ORC的數據。
AnalyticDB for MySQL集群不支持自定義行級寫入的
INSERT語法,如INSERT INTO VALUES和REPLACE INTO VALUES。不支持通過分區外表導出單個文件至HDFS。
通過分區外表導出數據時,數據文件內不包含分區列的數據,分區列的數據信息以HDFS目錄的形式展現。
例如,已在分區外表中定義了3個普通列和2個分區列。其中一級分區列的列名為
p1,分區列的值為1。二級分區名稱為p2,分區數值為a,現需要通過分區外表將數據導出到HDFS的adb_data/路徑下。那么當
p1=1且p2=a的外表分區導出數據時,數據文件相對路徑目錄為adb_data/p1=1/p2=a/,且外表CSV或Parquet數據文件內不包含p1和p2這兩列,只包含3列普通列的值。
操作步驟
連接目標AnalyticDB for MySQL集群。詳細操作步驟,請參見連接集群。
創建源數據庫。詳細操作步驟,請參見創建數據庫。
本示例中,AnalyticDB for MySQL集群的源庫名為
adb_demo。創建源表并插入源數據。
您可以使用以下語句在源庫
adb_demo中創建一張源表adb_hdfs_import_source,建表語句如下:CREATE TABLE IF NOT EXISTS adb_hdfs_import_source ( uid string, other string ) DISTRIBUTED BY HASH(uid);往源表
adb_hdfs_import_source中插入一行測試數據,語句如下:INSERT INTO adb_hdfs_import_source VALUES ("1", "a"), ("2", "b"), ("3", "c");創建外部映射表。
您可以使用以下語法在源庫
adb_demo中創建一張外部映射表,用于將AnalyticDB for MySQL數據導出至HDFS:創建普通外部映射表(本文示例中目標表名為
hdfs_import_external),語法如下。CREATE TABLE IF NOT EXISTS hdfs_import_external ( uid string, other string ) ENGINE='HDFS' TABLE_PROPERTIES='{ "format":"csv", "delimiter":",", "hdfs_url":"hdfs://172.17.***.***:9000/adb/hdfs_output_test_csv_data" }';創建帶分區的外部映射表時(本文示例中目標表名為
hdfs_import_external_par),需要同時在創建語句中定義普通列(如uid和other)和分區列(如p1、p2和p3),語法如下。CREATE TABLE IF NOT EXISTS hdfs_import_external_par ( uid string, other string, p1 date, p2 int, p3 varchar ) ENGINE='HDFS' TABLE_PROPERTIES='{ "format":"csv", "delimiter":",", "hdfs_url":"hdfs://172.17.***.***:9000/adb/hdfs_output_test_csv_data" "partition_column":"p1, p2, p3" }';
說明AnalyticDB for MySQL集群僅支持導出文件格式為CSV和Parquet的數據至HDFS。不支持導出文件格式為ORC的數據。
創建外表的詳細語法說明,請參見創建HDFS外表和創建帶分區的HDFS外表。
將源AnalyticDB for MySQL集群中的數據導出至目標HDFS中。
如需通過普通外表導出數據,具體語法,請參見附錄1:數據導出語法(普通外表)。
如需通過分區外表導出數據,具體語法,請參見附錄2:數據導出語法(分區外表)。
后續步驟
導出完成后,您可以通過Hadoop客戶端到目標文件夾hdfs_output_test_csv_data中查看導出的數據文件。您也可以登錄AnalyticDB for MySQL集群,在外表中(分區外表與普通外表查詢語句一致,本示例以普通外表hdfs_import_external為例)執行如下語句查詢已導出的數據:
SELECT * FROM hdfs_import_external LIMIT 100;附錄1:數據導出語法(普通外表)
若創建外表時未指定分區列,您可以根據業務需要選擇如下幾種方式導出數據:
方式一:如果您的數據已存在于目標表中,可以通過
INSERT INTO語句將數據導入外表。使用該語句會將源表的數據寫入外表對應的HDFS位置,每次寫入會產生新的HDFS數據文件。說明外表里的列和需要導出的列,必須保持列個數的完整。
INSERT INTO為增量寫入,會額外產生新的文件,不會覆蓋舊的歷史文件。語法如下。
INSERT INTO <target_table> SELECT <col_name> FROM <source_table>;示例如下。
INSERT INTO hdfs_import_external SELECT col1, col2, col3 FROM adb_hdfs_import_source;說明col1, col2, col3表示外表中的所有列。方式二:HDFS外表不支持定義主鍵,因此
REPLACE INTO的寫入表現與INSERT INTO一致,都會將數據復制到外表。如果目標表內已有數據,執行REPLACE INTO語句導入時,已有數據保持不變,新數據會被追加到目標數據文件中。說明寫入的外表必須保持列個數的完整,不允許用戶指定只寫入一部分的列。
REPLACE INTO為增量寫入,會額外產生新的文件,不會覆蓋舊的歷史文件。
語法如下。
REPLACE INTO <target_table> SELECT <col_name> FROM <source_table>;示例如下。
REPLACE INTO hdfs_import_external SELECT col1, col2, col3 FROM adb_hdfs_import_source;方式三:您可以使用
INSERT OVERWRITE語法向外表中批量插入數據。如果目標外表中已存在數據,每次寫入會先刪除外表路徑下的全部數據文件,再產生新的HDFS數據文件。重要寫入的外表必須保持列個數的完整,不允許指定只寫入部分的列。
INSERT OVERWRITE為覆蓋寫入,會覆蓋導出目錄內已有的歷史數據,謹慎使用。
語法如下。
INSERT OVERWRITE <target_table> SELECT <col_name> FROM <source_table>;示例如下。
INSERT OVERWRITE hdfs_import_external SELECT col1, col2, col3 FROM adb_hdfs_import_source;方式四:異步執行
INSERT OVERWRITE導出數據,語法如下。SUBMIT job INSERT OVERWRITE <target_table> SELECT <col_name> FROM <source_table>;示例如下。
SUBMIT JOB INSERT OVERWRITE hdfs_import_external SELECT col1, col2, col3 FROM adb_hdfs_import_source;返回結果如下。
+---------------------------------------+ | job_id | +---------------------------------------+ | 2020112122202917203100908203303****** | +---------------------------------------+您還可以根據上述
job_id查看異步任務的狀態。更多詳情,請參見異步提交導入任務。
附錄2:數據導出語法(分區外表)
分區外表在語法中加入PARTITION字段導出數據,您還可以通過指定PARTITION字段中的分區列和分區值來確定是否使用靜態或者動態分區。
方式一:您可以使用
INSERT INTO PARTITION語法往帶分區的外表中批量插入數據。說明寫入時,數據將在對應分區追加寫入,每次寫入會產生新的HDFS數據文件,歷史數據不會被覆蓋;寫入的外表必須保持列個數的完整,不允許用戶指定只寫入一部分的列。
全靜態分區
語法如下。
INSERT INTO <target_table> PARTITION(par1=val1,par2=val2,...) SELECT <col_name> FROM <source_table>;示例如下。
INSERT INTO hdfs_import_external_par PARTITION(p1='2021-05-06',p2=1,p3='test') SELECT col1, col2, col3, FROM adb_hdfs_import_source;半靜態半動態分區
說明靜態列必須位于動態列的前面,不允許穿插使用。
語法如下。
INSERT INTO <target_table> PARTITION(par1=val1,par2,...) SELECT <col_name> FROM <source_table>;示例如下。
INSERT INTO hdfs_import_external_par PARTITION(p1='2021-05-27',p2,p3) SELECT col1, col2, col3, FROM adb_hdfs_import_source;全動態分區(即不需要
PARTITION字段)語法如下。
INSERT INTO <target_table> SELECT <col_name> FROM <source_table>;示例如下。
INSERT INTO hdfs_import_external_par SELECT col1, col2, col3, FROM adb_hdfs_import_source;
方式二:HDFS外表不支持定義主鍵,因此
REPLACE INTO PARTITION的寫入表現與INSERT INTO PARTITION一致。說明寫入的外表必須保持列個數的完整,不允許用戶指定只寫入一部分的列;
REPLACE INTO PARTITION為增量寫入,會額外產生新的文件,不會覆蓋舊的歷史文件。語法如下:
全靜態分區
語法如下。
REPLACE INTO <target_table> PARTITION(par1=val1,par2=val2,...) SELECT <col_name> FROM <source_table>;示例如下。
REPLACE INTO hdfs_import_external_par PARTITION(p1='2021-05-06',p2=1,p3='test') SELECT col1, col2, col3, FROM adb_hdfs_import_source;半靜態半動態分區
說明靜態列必須位于動態列的前面,不允許穿插使用。
語法如下。
REPLACE INTO <target_table> PARTITION(par1=val1,par2,...) SELECT <col_name> FROM <source_table>;示例如下。
REPLACE INTO hdfs_import_external_par PARTITION(p1='2021-05-06',p2,p3) SELECT col1, col2, col3, FROM adb_hdfs_import_source;全動態分區(即不需要
PARTITION字段)語法如下。
REPLACE INTO <target_table> SELECT <col_name> FROM <source_table>;示例如下。
REPLACE INTO hdfs_import_external_par SELECT col1, col2, col3, FROM adb_hdfs_import_source;
方式三:
INSERT OVERWRITE PARTITION與INSERT INTO PARTITION使用方法相同,但使用INSERT OVERWRITE PARTITION時,會覆蓋掉本次執行中涉及到的目標分區中之前已有的數據文件,對于沒有新數據寫入的分區,則不會清除其中的數據文件。語法如下。
INSERT OVERWRITE <target_table> PARTITION(par1=val1,par2=val2,...)[IF NOT EXISTS] SELECT <col_name> FROM <source_table>;重要寫入的外表必須保持列個數的完整,不允許用戶指定只寫入一部分的列;
INSERT OVERWRITE PARTITION為覆蓋寫入,會覆蓋導出目錄內已有的歷史數據,謹慎使用。IF NOT EXISTS:表示如果外表分區已存在,則不會導出到這個分區。
示例如下。
INSERT OVERWRITE hdfs_import_external_par PARTITION(p1='2021-05-06',p2=1,p3='test') IF NOT EXISTS SELECT col1, col2, col3 FROM adb_hdfs_import_source;方式四:異步執行
INSERT OVERWRITE導出數據,語法如下。SUBMIT JOB INSERT OVERWRITE <target_table> SELECT <col_name> FROM <source_table>;示例如下。
SUBMIT JOB INSERT OVERWRITE hdfs_import_external_par PARTITION(p1='2021-05-06',p2=1,p3='test') IF NOT EXISTS SELECT col1, col2, col3 FROM adb_hdfs_import_source;返回結果如下。
+---------------------------------------+ | job_id | +---------------------------------------+ | 2020112122202917203100908203303****** | +---------------------------------------+您還可以根據上述
job_id查看異步任務的狀態。更多詳情,請參見異步提交導入任務。