一、基礎統計分析
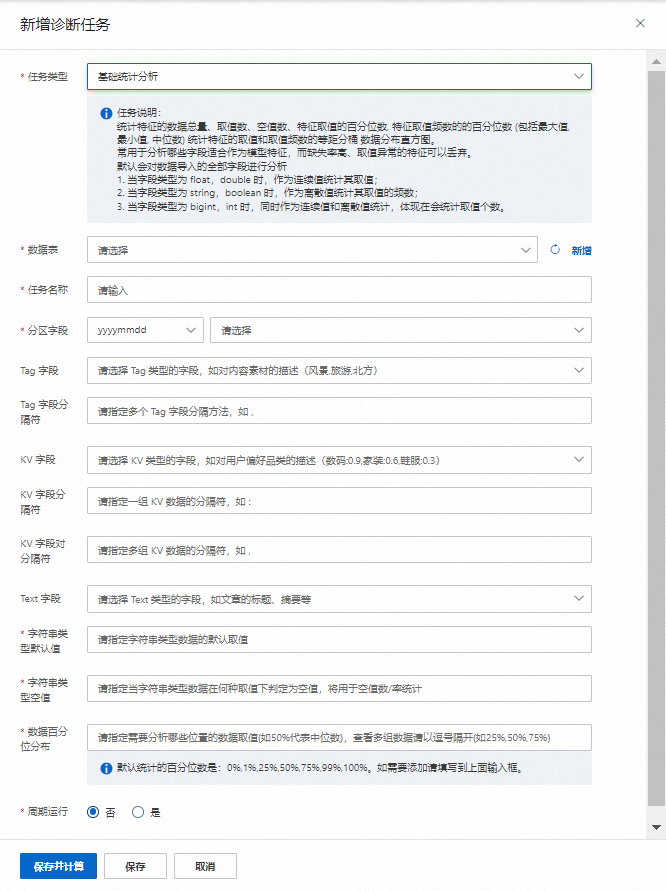
選擇任務類型:基礎統計分析,選擇相應的用戶數據表,填寫任務名稱。
分區字段:選擇相應的ds字段,分區字段顯示有兩種形式yyyymmdd與yyyy-mm-dd,可下拉選擇顯示的樣式。
Tag字段:可選擇需要分析到的字段(例如:city等)。
Tag字段分隔符:選擇需要的Tag字段的分隔符(如:,)。
KV字段:選擇為KV類型的字段(如:對用戶偏好品類的描述,數碼:0.9,家裝:0.6,鞋服:0.3,……),會對key的數量以及value的分布進行分析,如若沒有可以不選擇。
KV字段分隔符:指定每組KV數據的分隔符(如:,)。
Text字段:選擇Text類型的數據,(如:文章的標題、摘要等),如若沒有標題可以不用選擇。
字符串類型默認值:對字符串類型字段的數據設置默認值(如:"")。
字符串類型空值:指定了在何種取值下判斷為空值,將用于空值數/率的統計(如:空格 )。
數據百分位分布:指定需要分析哪些位置的數據取值(如50%代表中位數),如查看多組數據以逗號隔開(如:25%,50%,75%,……),數據百分位分布默認統計的百分位數為:0%,1%,25%,50%,75%,99%,100%。
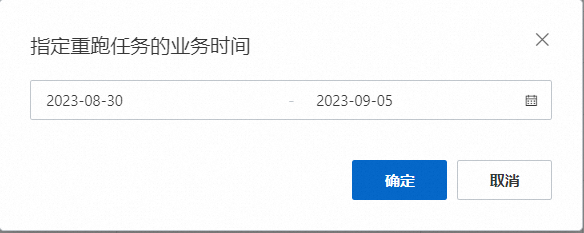
周期運行:默認選擇否,如果不對數據表進行周期分析,此時點擊保存并計算后,進入指定重跑任務的業務時間頁面,業務時間默認為最近7天,如果想看到其他時間的數據選擇相對應的時間即可,此時點擊確定即可進行數據診斷任務;若需要進行周期任務,周期運行選擇是,對周期運行任務進行配置。
統計特征的數據總量、取值數、空值數、特征取值的百分位數, 特征取值頻數的的百分位數 (包括最大值, 最小值, 中位數) 統計特征的取值和取值頻數的等距分桶 數據分布直方圖。
常用于分析哪些字段適合作為模型特征,而缺失率高、取值異常的特征可以丟棄。
默認會對數據導入的全部字段進行分析
當字段類型為 float,double 時,作為連續值統計其取值;
當字段類型為 string,boolean 時,作為離散值統計其取值的頻數;
當字段類型為 bigint,int 時,同時作為連續值和離散值統計,體現在會統計取值個數。
業務時間,是對落盤到對應日期分區內的數據,而非統計某一天操作寫入的數據。
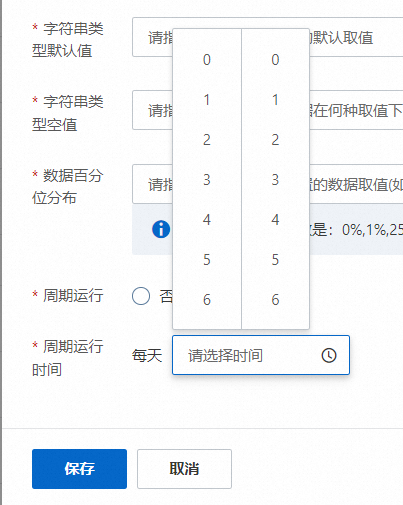
周期運行選擇是時,會對用戶偏好統計周期分析數據診斷任務的周期運行時間進行選擇,選擇每天運行的時間點擊保存即可。
二、診斷報告
下面用demo數據演示了基礎統計分析報告,其中展示了每天的用戶量,展示了多個bigint特征從最大值最小值、百分位數、頻數統計等多個角度的分析報表。

診斷結果中顯示空值率大于0.4,需要關注city字段。
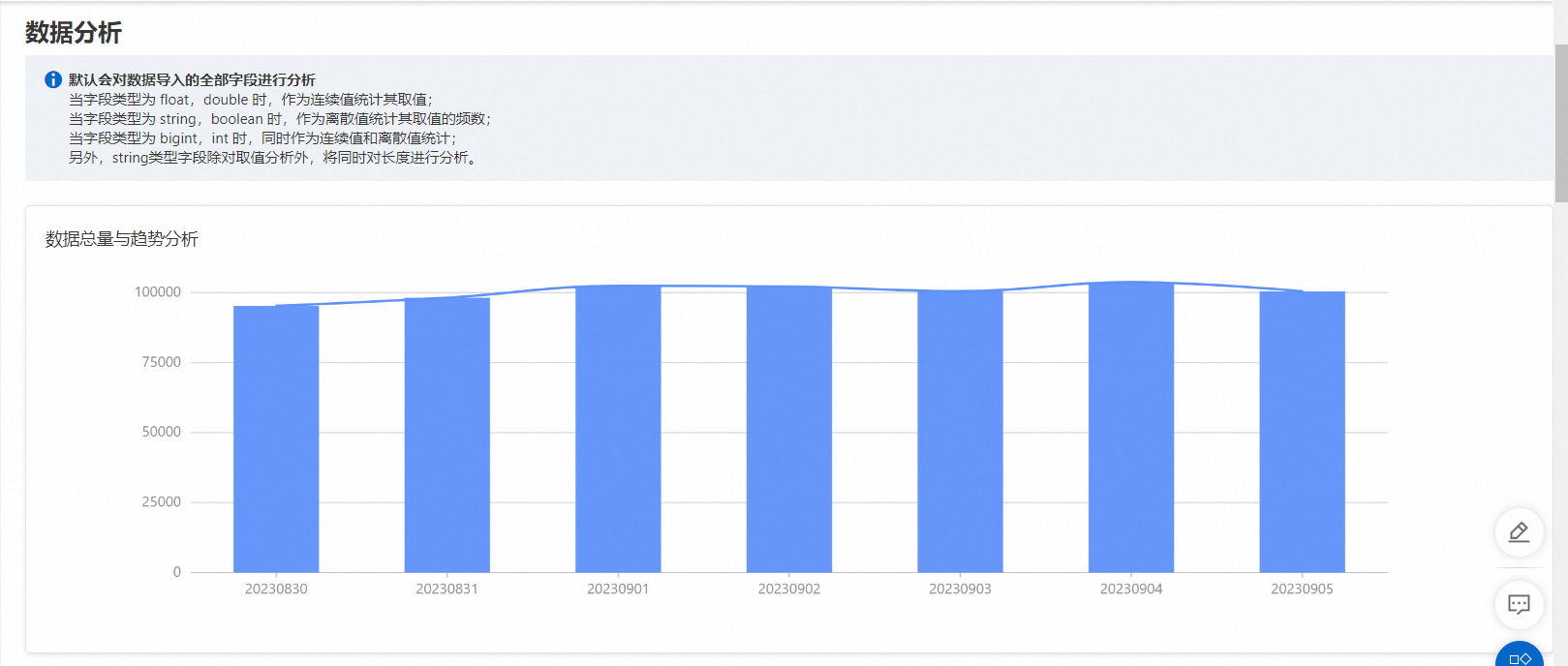
展示每天的數據總量
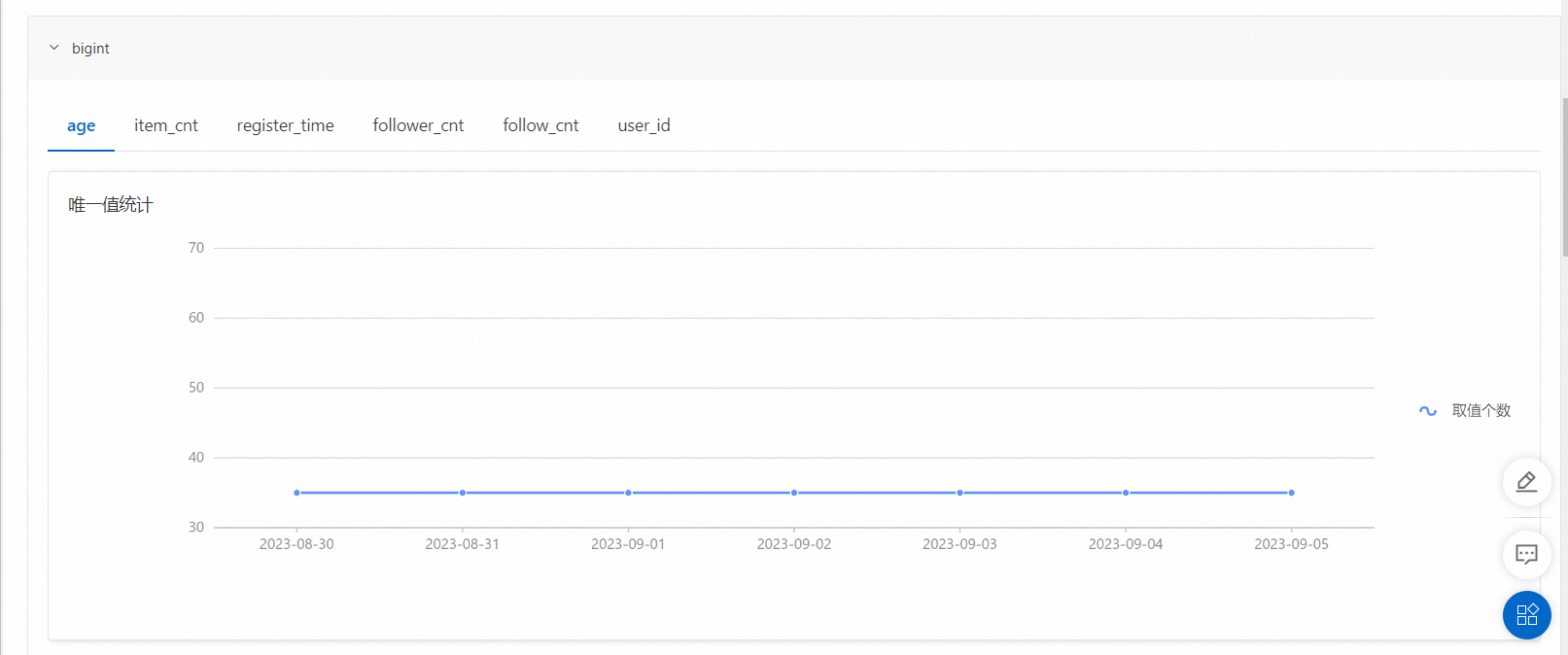
唯一值統計,展示了每個字段中唯一值的數量。
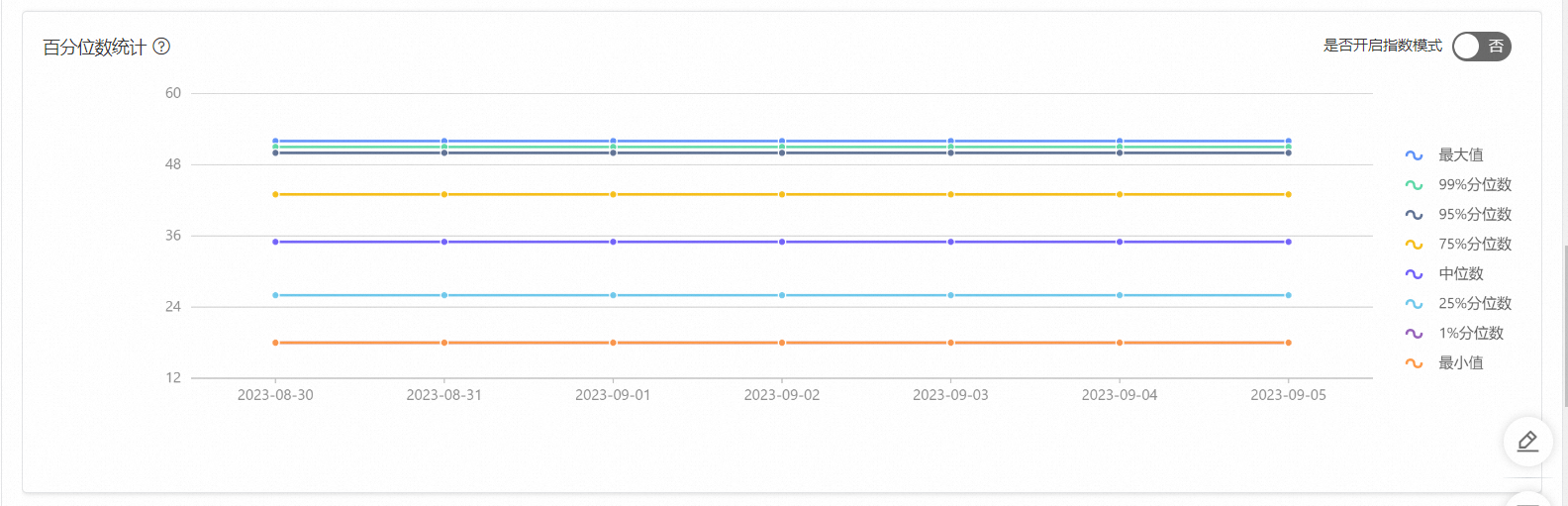
百分位數統計,以年齡為例,95%的分位數是50歲,最大值是52歲,最小值是18歲。
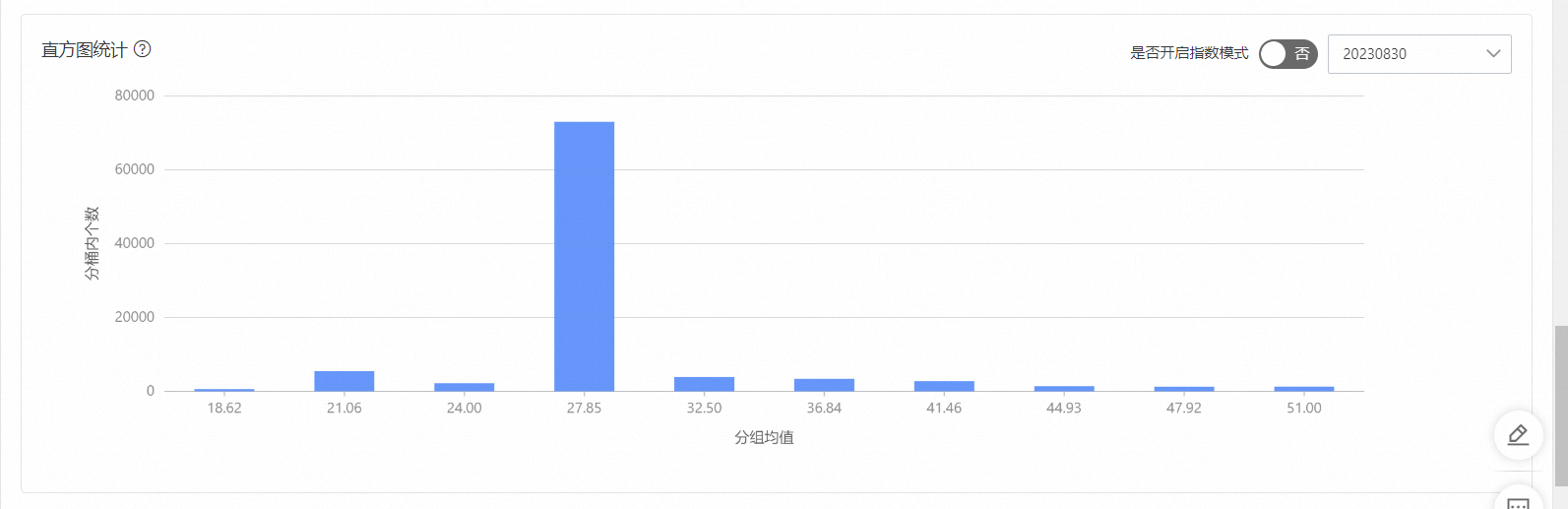
直方圖統計,把數據分為10個桶,看每個分桶中的數量。
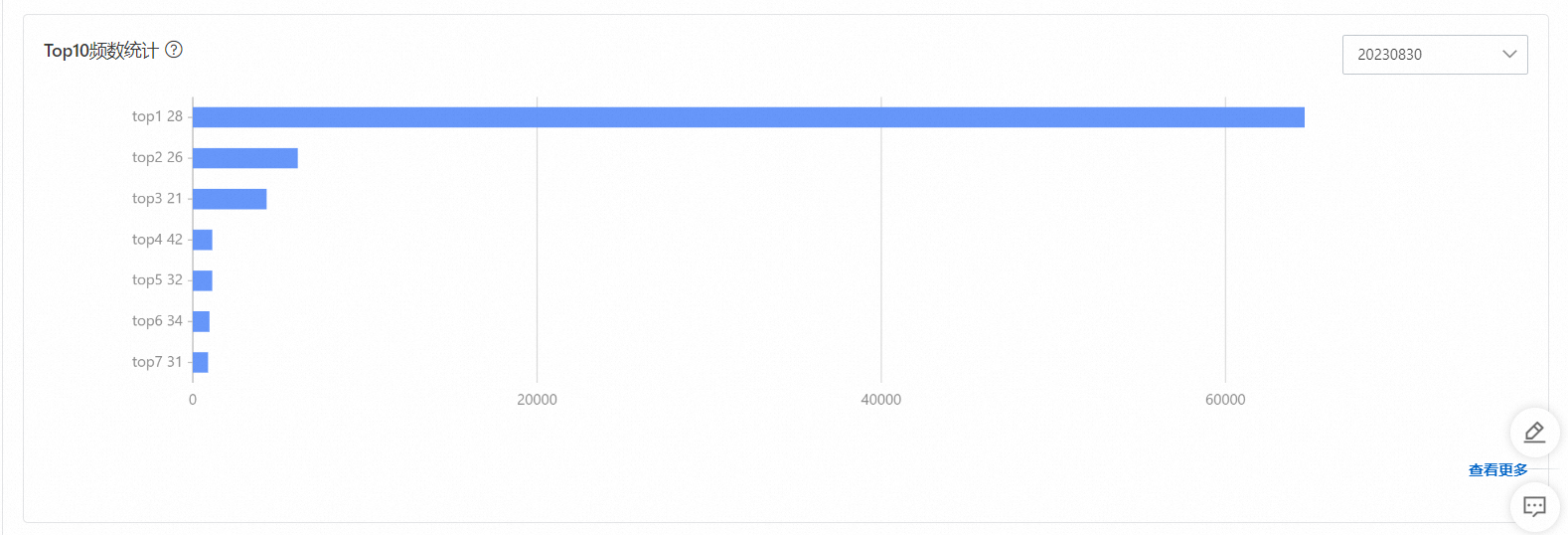
Top10頻數統計,以年齡為例,統計了年齡出現頻數最多的前10個年齡。
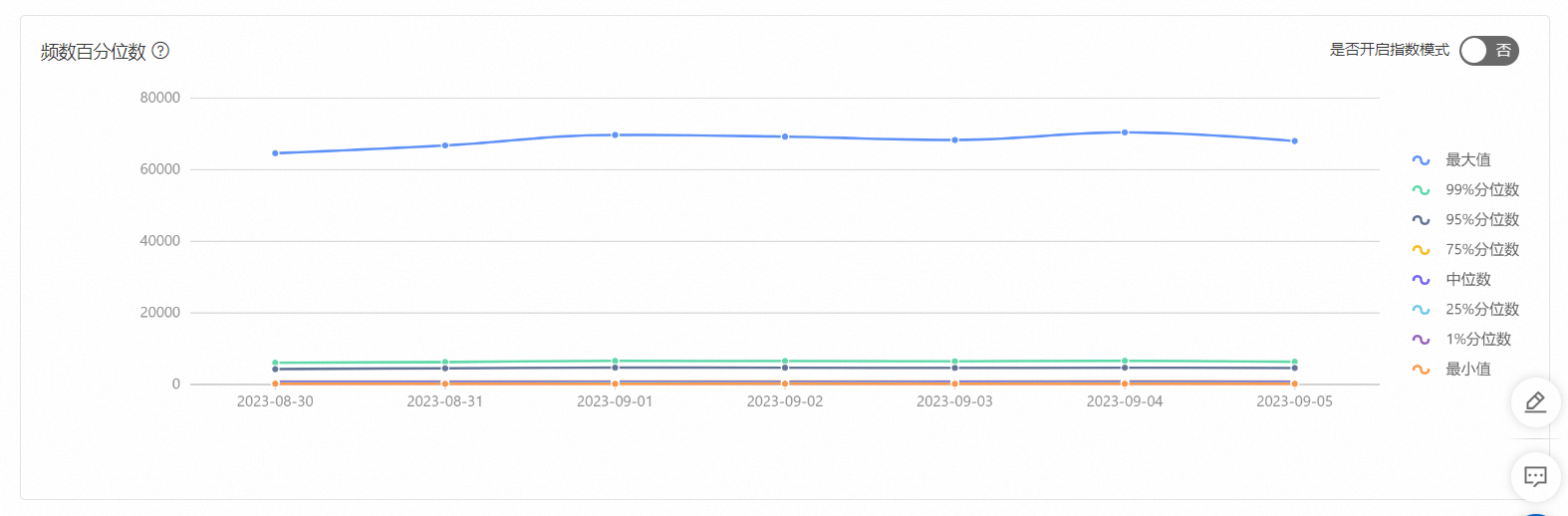
頻數百分位數,最大值是否與Top10頻數統計的最多的一致。
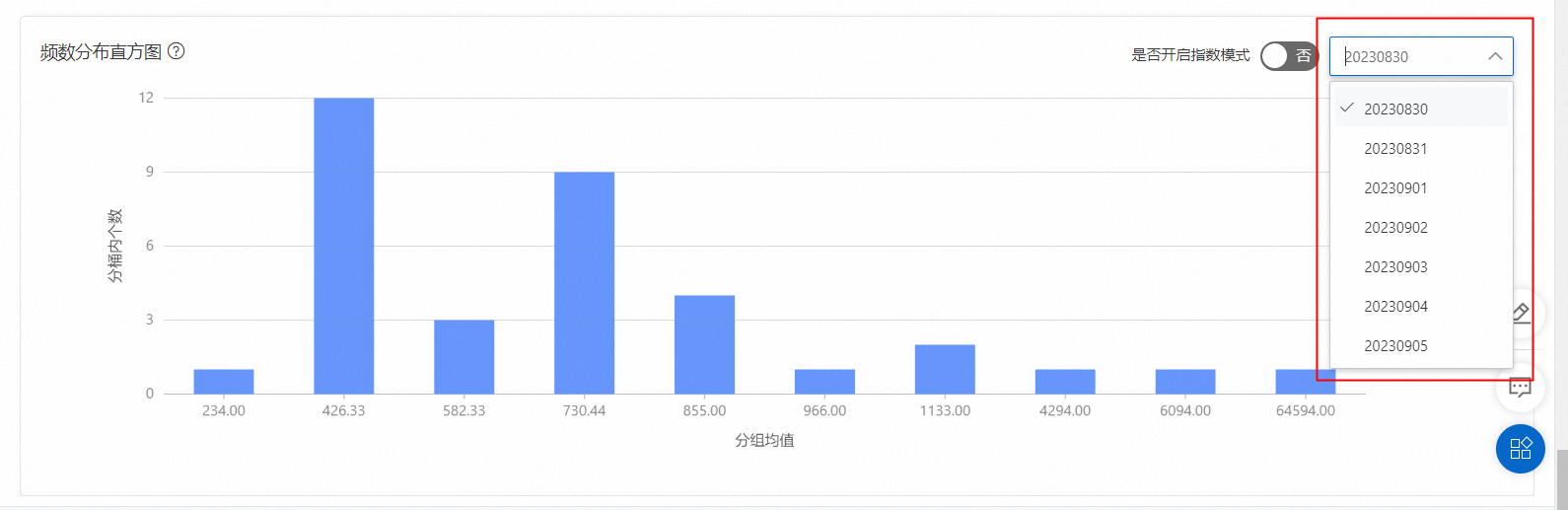
報告中有日期選擇的只展示了一天的數據,如果查看其他天的數據需要手動選擇日查看。
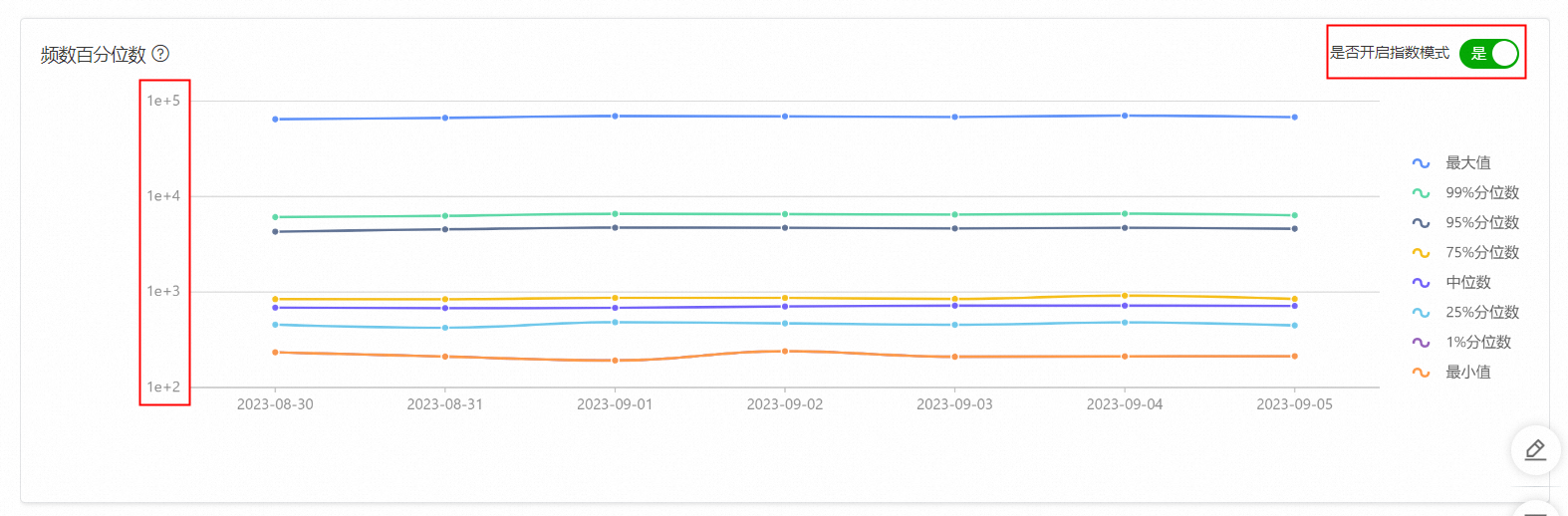
是否開啟指數模式默認為不開啟,需要手動開啟數據即可展示指數形式。
默認會對數據導入的全部字段進行分析
當字段類型為 float,double 時,作為連續值統計其取值;
當字段類型為 string,boolean 時,作為離散值統計其取值的頻數;
當字段類型為 bigint,int 時,同時作為連續值和離散值統計;
另外,string類型字段除對取值分析外,將同時對長度進行分析。