AHPA可以根據從Prometheus Adapter獲取到的GPU利用率數據,結合歷史負載趨勢和預測算法,提前預估未來的GPU資源需求,并自動調整Pod副本數量或者GPU資源分配,確保在GPU資源緊張前完成擴容操作,而在資源閑置時及時縮容,從而達到節省成本和提高集群效率的目標。
前提條件
已創建托管GPU集群。具體操作,請參見創建GPU集群。
已安裝AHPA組件,并配置相關指標源。具體操作,請參見AHPA概述。
已開啟Prometheus監控,且Prometheus監控中至少已收集7天應用歷史數據(GPU)。具體操作,請參見阿里云Prometheus監控。
原理介紹
在高性能計算領域,尤其是深度學習模型訓練、推理等對GPU資源高度依賴的場景中,通過精細化管理和動態調整GPU資源能夠有效提升資源利用率并降低成本。容器服務 Kubernetes 版支持基于GPU指標進行彈性伸縮。您可以利用Prometheus采集GPU的實時利用率和顯存使用情況等關鍵指標。然后通過Prometheus Adapter將這些指標轉換為Kubernetes可識別的metrics格式,并與AHPA集成。AHPA可以根據從Prometheus Adapter獲取到的GPU利用率數據,結合歷史負載趨勢和預測算法,提前預估未來的GPU資源需求,并自動調整Pod副本數量或者GPU資源分配,確保在GPU資源緊張前完成擴容操作,而在資源閑置時及時縮容,從而達到節省成本和提高集群效率的目標。
步驟一:部署Metrics Adapter
獲取HTTP API的內網地址。
登錄ARMS控制臺。
在左側導航欄選擇,進入可觀測監控 Prometheus 版的實例列表頁面。
在實例列表頁面頂部,選擇容器服務K8s集群所在的地域。
單擊目標Prometheus實例名稱,然后在左側導航欄單擊設置,獲取HTTP API地址下的內網地址。
部署ack-alibaba-cloud-metrics-adapter。
步驟二:基于GPU指標實現AHPA彈性預測
本文通過在GPU上部署一個模型推理服務,然后對其進行持續請求訪問,根據GPU利用率進行AHPA彈性預測。
部署推理服務。
執行以下命令,部署推理服務。
cat <<EOF | kubectl create -f - apiVersion: apps/v1 kind: Deployment metadata: name: bert-intent-detection spec: replicas: 1 selector: matchLabels: app: bert-intent-detection template: metadata: labels: app: bert-intent-detection spec: containers: - name: bert-container image: registry.cn-hangzhou.aliyuncs.com/ai-samples/bert-intent-detection:1.0.1 ports: - containerPort: 80 resources: limits: cpu: "1" memory: 2G nvidia.com/gpu: "1" requests: cpu: 200m memory: 500M nvidia.com/gpu: "1" --- apiVersion: v1 kind: Service metadata: name: bert-intent-detection-svc labels: app: bert-intent-detection spec: selector: app: bert-intent-detection ports: - protocol: TCP name: http port: 80 targetPort: 80 type: LoadBalancer EOF執行以下命令,查看Pod狀態。
kubectl get pods -o wide預期輸出:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES bert-intent-detection-7b486f6bf-f**** 1/1 Running 0 3m24s 10.15.1.17 cn-beijing.192.168.94.107 <none> <none>執行以下命令,調用推理服務,驗證部署是否成功。
您可以通過
kubectl get svc bert-intent-detection-svc命令獲取GPU節點的IP地址,替換如下命令中的47.95.XX.XX。curl -v "http://47.95.XX.XX/predict?query=Music"預期輸出:
* Trying 47.95.XX.XX... * TCP_NODELAY set * Connected to 47.95.XX.XX (47.95.XX.XX) port 80 (#0) > GET /predict?query=Music HTTP/1.1 > Host: 47.95.XX.XX > User-Agent: curl/7.64.1 > Accept: */* > * HTTP 1.0, assume close after body < HTTP/1.0 200 OK < Content-Type: text/html; charset=utf-8 < Content-Length: 9 < Server: Werkzeug/1.0.1 Python/3.6.9 < Date: Wed, 16 Feb 2022 03:52:11 GMT < * Closing connection 0 PlayMusic #意圖識別結果。當HTTP請求返回狀態碼
200和意圖識別結果,說明推理服務部署成功。
配置AHPA。
本文以GPU利用率為例,當Pod的GPU利用率大于20%時,觸發擴容。
配置AHPA指標源。
使用以下內容,創建application-intelligence.yaml文件。
prometheusUrl用于設置阿里云Prometheus的訪問地址,值為步驟1獲取的內網地址。apiVersion: v1 kind: ConfigMap metadata: name: application-intelligence namespace: kube-system data: prometheusUrl: "http://cn-shanghai-intranet.arms.aliyuncs.com:9090/api/v1/prometheus/da9d7dece901db4c9fc7f5b*******/1581204543170*****/c54417d182c6d430fb062ec364e****/cn-shanghai"執行以下命令,部署application-intelligence。
kubectl apply -f application-intelligence.yaml
部署AHPA。
使用以下內容,創建fib-gpu.yaml文件。
此處設置為
observer觀察模式,關于參數的更多信息,請參見參數說明。apiVersion: autoscaling.alibabacloud.com/v1beta1 kind: AdvancedHorizontalPodAutoscaler metadata: name: fib-gpu namespace: default spec: metrics: - resource: name: gpu target: averageUtilization: 20 type: Utilization type: Resource minReplicas: 0 maxReplicas: 100 prediction: quantile: 95 scaleUpForward: 180 scaleStrategy: observer scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: bert-intent-detection instanceBounds: - startTime: "2021-12-16 00:00:00" endTime: "2022-12-16 00:00:00" bounds: - cron: "* 0-8 ? * MON-FRI" maxReplicas: 50 minReplicas: 4 - cron: "* 9-15 ? * MON-FRI" maxReplicas: 50 minReplicas: 10 - cron: "* 16-23 ? * MON-FRI" maxReplicas: 50 minReplicas: 12執行以下命令,部署AHPA。
kubectl apply -f fib-gpu.yaml執行以下命令,查看AHPA狀態。
kubectl get ahpa預期輸出:
NAME STRATEGY REFERENCE METRIC TARGET(%) CURRENT(%) DESIREDPODS REPLICAS MINPODS MAXPODS AGE fib-gpu observer bert-intent-detection gpu 20 0 0 1 10 50 6d19h由預期輸出得到,
CURRENT(%)為0,TARGET(%)為20。說明當前GPU利用率是0%,當GPU利用率超過20%時觸發彈性擴容。
測試推理服務彈性伸縮。
執行以下命令,對推理服務進行訪問。
apiVersion: apps/v1 kind: Deployment metadata: name: fib-loader namespace: default spec: progressDeadlineSeconds: 600 replicas: 1 revisionHistoryLimit: 10 selector: matchLabels: app: fib-loader strategy: rollingUpdate: maxSurge: 25% maxUnavailable: 25% type: RollingUpdate template: metadata: creationTimestamp: null labels: app: fib-loader spec: containers: - args: - -c - | /ko-app/fib-loader --service-url="http://bert-intent-detection-svc.${NAMESPACE}/predict?query=Music" --save-path=/tmp/fib-loader-chart.html command: - sh env: - name: NAMESPACE valueFrom: fieldRef: apiVersion: v1 fieldPath: metadata.namespace image: registry.cn-huhehaote.aliyuncs.com/kubeway/knative-sample-fib-loader:20201126-110434 imagePullPolicy: IfNotPresent name: loader ports: - containerPort: 8090 name: chart protocol: TCP resources: limits: cpu: "8" memory: 16000Mi requests: cpu: "2" memory: 4000Mi訪問過程中,執行以下命令,查看AHPA的狀態。
kubectl get ahpa預期輸出:
NAME STRATEGY REFERENCE METRIC TARGET(%) CURRENT(%) DESIREDPODS REPLICAS MINPODS MAXPODS AGE fib-gpu observer bert-intent-detection gpu 20 189 10 4 10 50 6d19h由預期輸出得到,當前GPU利用率
CURRENT(%)已超過TARGET(%)的值,觸發彈性伸縮,期望的Pod數DESIREDPODS為10。執行以下命令,查看預測效果趨勢。
kubectl get --raw '/apis/metrics.alibabacloud.com/v1beta1/namespaces/default/predictionsobserver/fib-gpu'|jq -r '.content' |base64 -d > observer.html基于歷史7天的GPU指標數據預測的GPU趨勢示例結果如下:
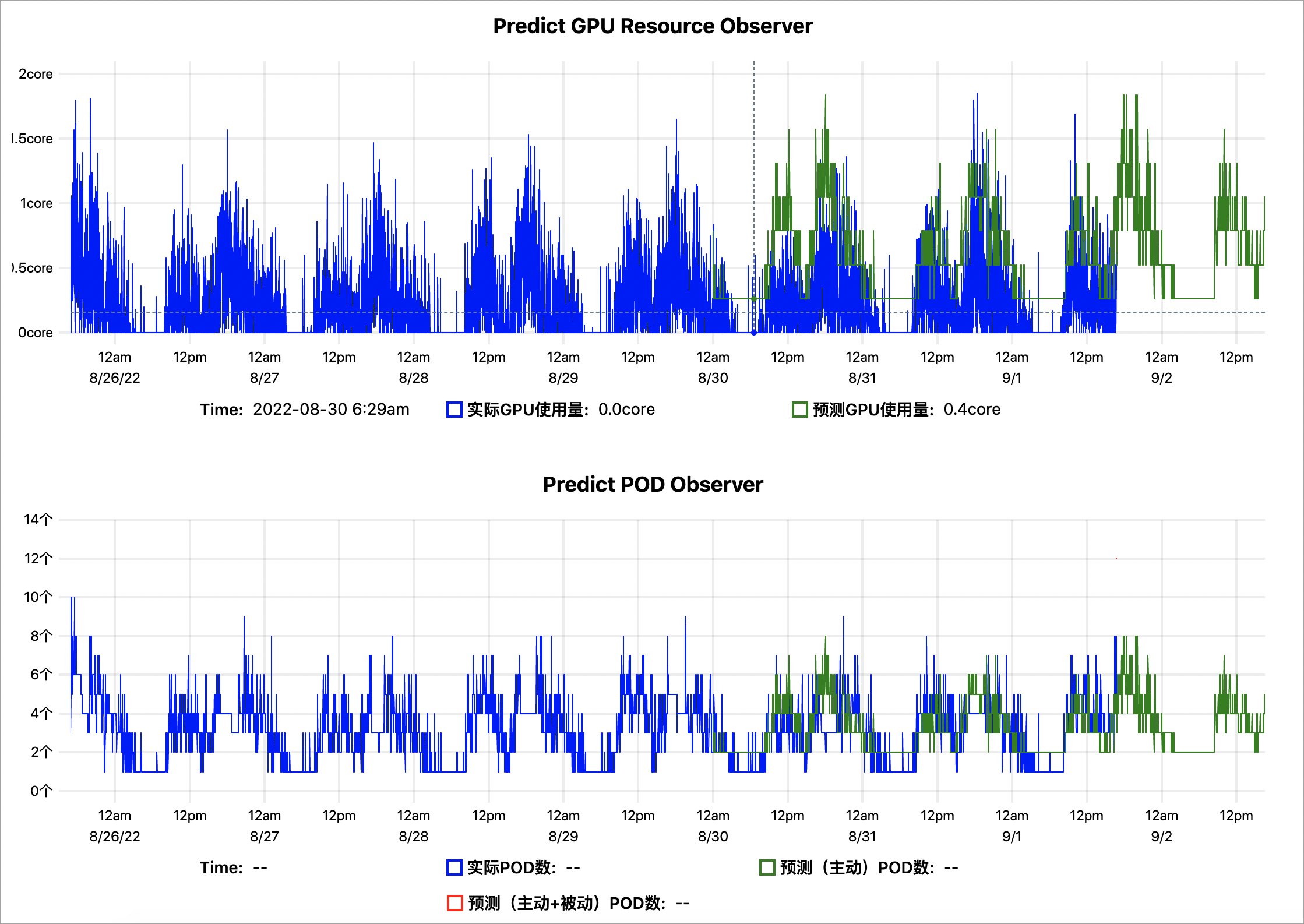
Predict GPU Resource Observer:藍色表示實際的GPU使用量,綠色表示AHPA預測出來的GPU使用量。綠色曲線大部分均大于藍色,表明預測的GPU容量相對充足。
Predict POD Oberserver:藍色表示使用實際的擴縮容Pod數,綠色表示AHPA預測出來的擴縮容Pod數,綠色曲線大部分均小于藍色,表明預測的Pod數量更少。您可以將彈性伸縮模式設置為
auto,以預測的Pod數進行設置,為您節省更多的Pod資源,避免資源的浪費。
通過預測結果表明,彈性預測趨勢符合預期。若經過觀察后,符合預期,您可以將彈性伸縮模式設置為
auto,由AHPA負責擴縮容。
相關文檔
Knative Serverless支持AHPA(Advanced Horizontal Pod Autoscaler)的彈性能力,當應用所需資源具備周期性時,可通過彈性預測,預熱資源,解決您在使用Knative中遇到的冷啟動問題。詳細信息,請參見在Knative中使用AHPA彈性預測。
很多場景中需要根據自定義指標(例如HTTP請求的QPS、消息隊列的長度等)對應用進行擴縮容。AHPA(Autoscaling Horizontal Pod Autoscaler)提供了External Metrics機制,結合alibaba-cloud-metrics-adapter組件,可以為應用提供更加豐富的擴縮機制。詳細信息,請參見通過AHPA配置自定義指標以實現應用擴縮。