云原生AI的監控組件能夠幫助您從不同的維度(比如:集群、節點、訓練任務等)監控集群的GPU資源使用情況,以及集群的各命名空間下的資源配額使用情況。本文分別從集群、節點、訓練任務和資源配額維度介紹監控大盤,以及介紹如何安裝和使用云原生AI監控大盤。
前提條件
本文僅支持ACK Pro版集群,且Kubernetes集群版本大于等于1.18.8。
Arena組件版本大于等于0.7.0。具體操作,請參見:配置Arena客戶端。
安裝阿里云Prometheus監控組件,具體操作,請參見arms-prometheus。
安裝AI運維控制臺組件。具體操作,請參見安裝云原生AI套件。
背景信息
當使用Arena提交訓練任務后,您可能需要從集群、節點、訓練任務或資源配額的維度去查看GPU的使用率、GPU顯存的使用情況。傳統的ACK集群只能從節點的維度監控該節點的GPU使用情況(使用率、顯存使用情況、功率等)或者從Pod維度監控該Pod使用GPU的情況。
基于以上存在的問題,阿里云容器服務研發了云原生AI監控大盤,該大盤相比傳統的ACK集群GPU監控大盤,有如下特點:
整個監控大盤由四個部分組成:集群、節點、訓練任務、資源配額。
集群監控大盤主要展示集群總的GPU節點數、不健康GPU節點數、GPU平均利用率、各個狀態的訓練任務數等。
節點監控大盤主要展示每個節點的總GPU卡數、已分配GPU卡數、GPU的使用率、節點GPU顯存使用情況等。
訓練任務監控大盤主要展示每個訓練任務的狀態、已運行時長、申請GPU數、GPU的平均利用率、GPU顯存使用情況等。
資源配額監控大盤主要展示每種資源配額在某個Namespace下的分配和使用情況,比如:Max Quota、Min Quota和Used Quota等。
安裝云原生AI監控組件
登錄容器服務管理控制臺,在左側導航欄選擇集群。
在集群列表頁面,單擊目標集群名稱,然后在左側導航欄,選擇。
安裝監控組件。
如果您之前已經部署過云原生AI套件:
在云原生AI套件頁面,找到云原生AI監控組件ack-arena-exporter,然后單擊右側操作列的部署。
如果您之前未部署過云原生AI套件:
在云原生AI套件頁面,單擊一鍵部署,然后在監控區域選中監控組件,單擊部署云原生AI套件。
監控大盤介紹
進入云原生AI運維控制臺后,默認顯示集群監控大盤頁面。單擊頁面左上角![]() 可以切換監控大盤。
可以切換監控大盤。
Cluster:集群監控大盤
Nodes:節點監控大盤
TrainingJobs:訓練任務監控大盤
Quota:資源配額監控大盤
集群監控大盤
具體操作,請參見方式一:使用公網Ingress訪問AI運維控制臺。
集群監控大盤有以下可供您查看的指標:
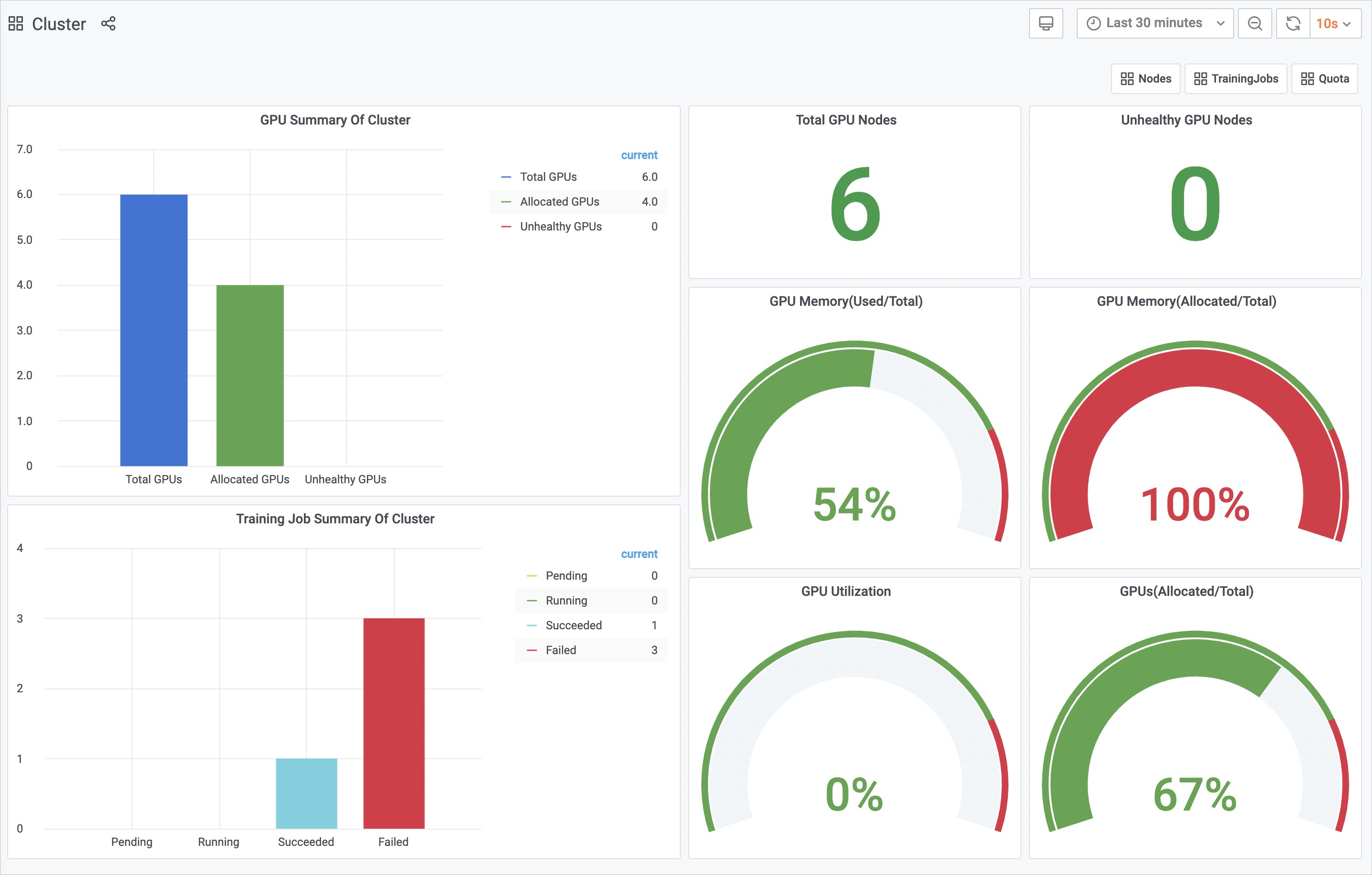
GPU Summary Of Cluster:展示集群中總的GPU節點數、已分配的GPU節點數、不健康的GPU節點數。
Total GPU Nodes:集群中總的GPU節點數。
Unhealthy GPU Nodes:不健康的GPU節點數。
GPU Memory(Used/Total):集群已使用GPU顯存與總的GPU顯存的百分比。
GPU Memory(Allocated/Total):集群已分配GPU顯存與總的GPU顯存百分比。
GPU Utilization:集群GPU的平均利用率。
GPUs(Allocated/Total):集群已分配GPU卡的個數與總的GPU卡數的百分比。
Training Job Summary Of Cluster:集群中各種狀態(Running、Pending、Succeeded、Failed)的訓練任務數。
節點監控大盤
在集群監控大盤頁面,單擊右上角的Nodes,進入節點監控大盤。
節點監控大盤有以下可供您查看的指標:
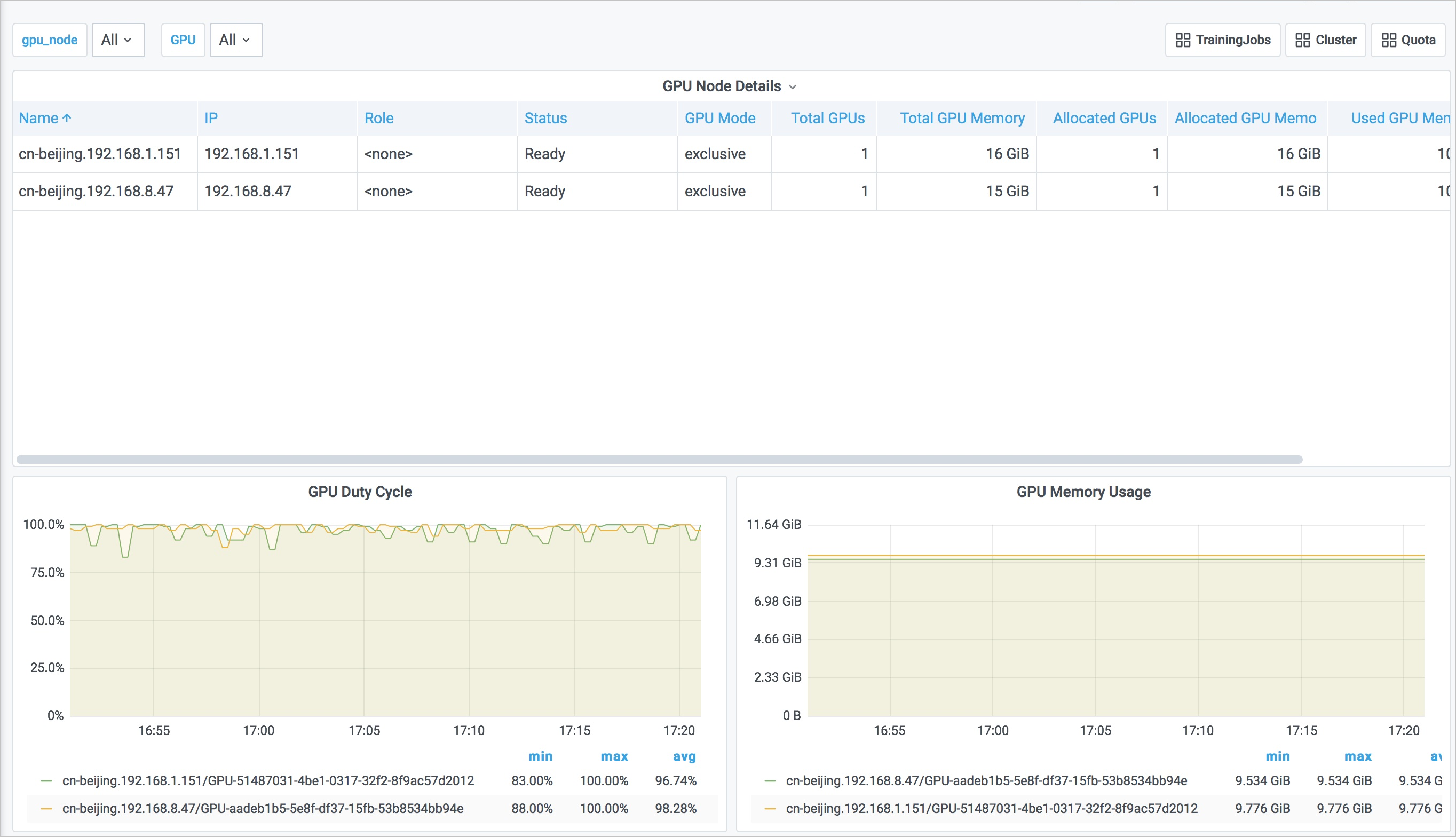
GPU Node Details:以表格的形式展示集群節點的相關信息,包括:
節點名稱(Name)
節點在集群中的IP(IP)
節點在集群中的角色(Role)
節點的狀態(Status)
GPU模式:獨占或共享(GPU Mode)
節點擁有GPU卡的個數(Total GPUs)
節點擁有總的GPU顯存(Total GPU Memory)
節點已分配GPU卡數(Allocated GPUs)
節點已分配GPU顯存(Allocated GPU Memory)
節點已使用GPU顯存(Used GPU Memory)
節點GPU平均使用率(GPU Utilization)
GPU Duty Cycle:每個節點的每個GPU的使用率。
GPU Memory Usage:每個節點的每個GPU的顯存使用量。
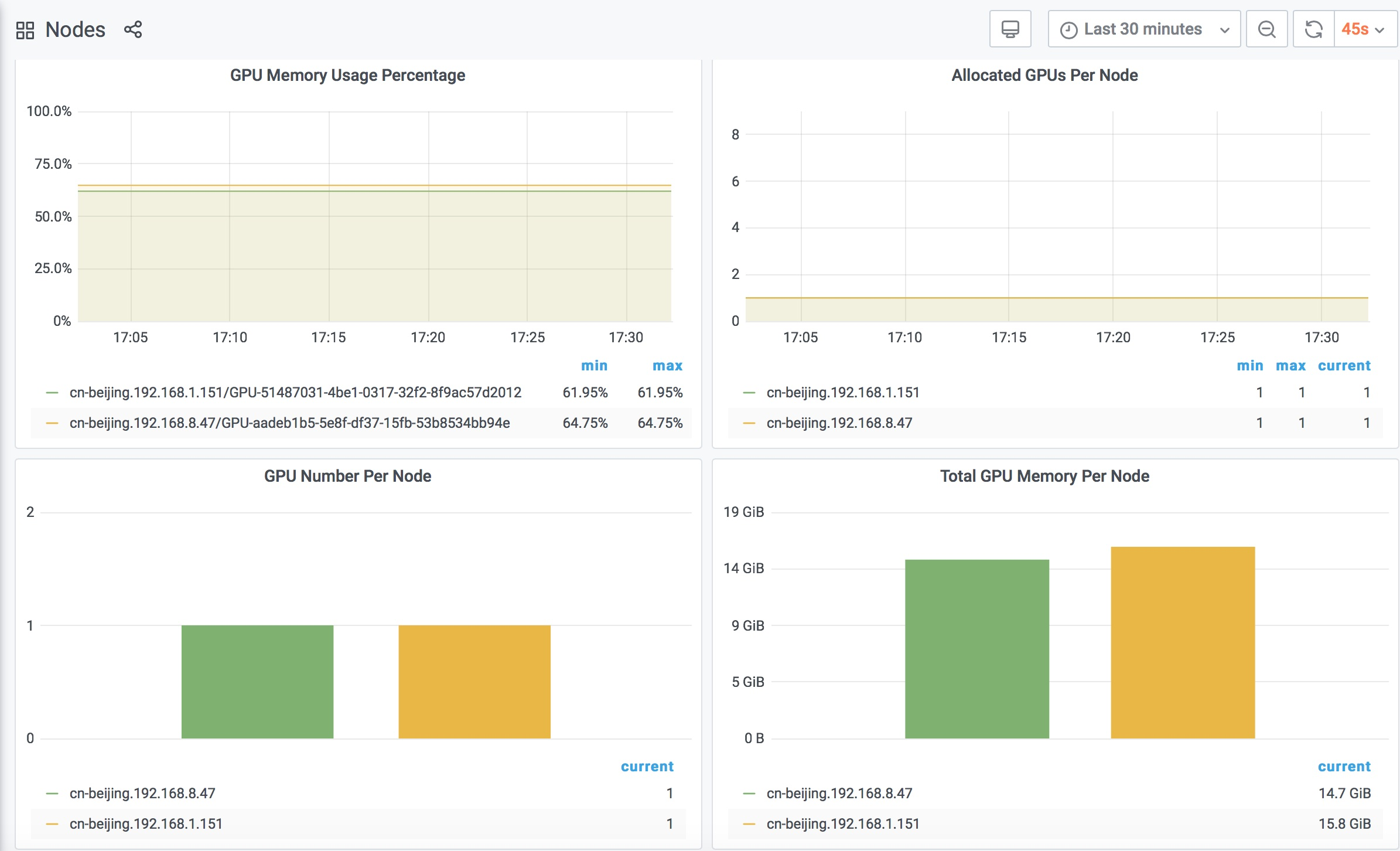
GPU Memory Usage Percentage:每個節點的每個GPU的顯存使用百分比。
Allocated GPUs Per Node:每個節點已分配的GPU卡數。
GPU Number Per Node:每個節點的總GPU卡數。
Total GPU Memory Per Node:每個節點的總GPU顯存。
您可以根據節點監控大盤左上角的gpu_node和GPU篩選項,對節點和GPU卡進行篩選,以便您查看到目標節點上的GPU使用情況。

訓練任務監控大盤
在節點監控大盤頁面,單擊右上角TrainingJobs,進入訓練任務的監控大盤。
訓練任務監控大盤有以下可供您查看的指標:
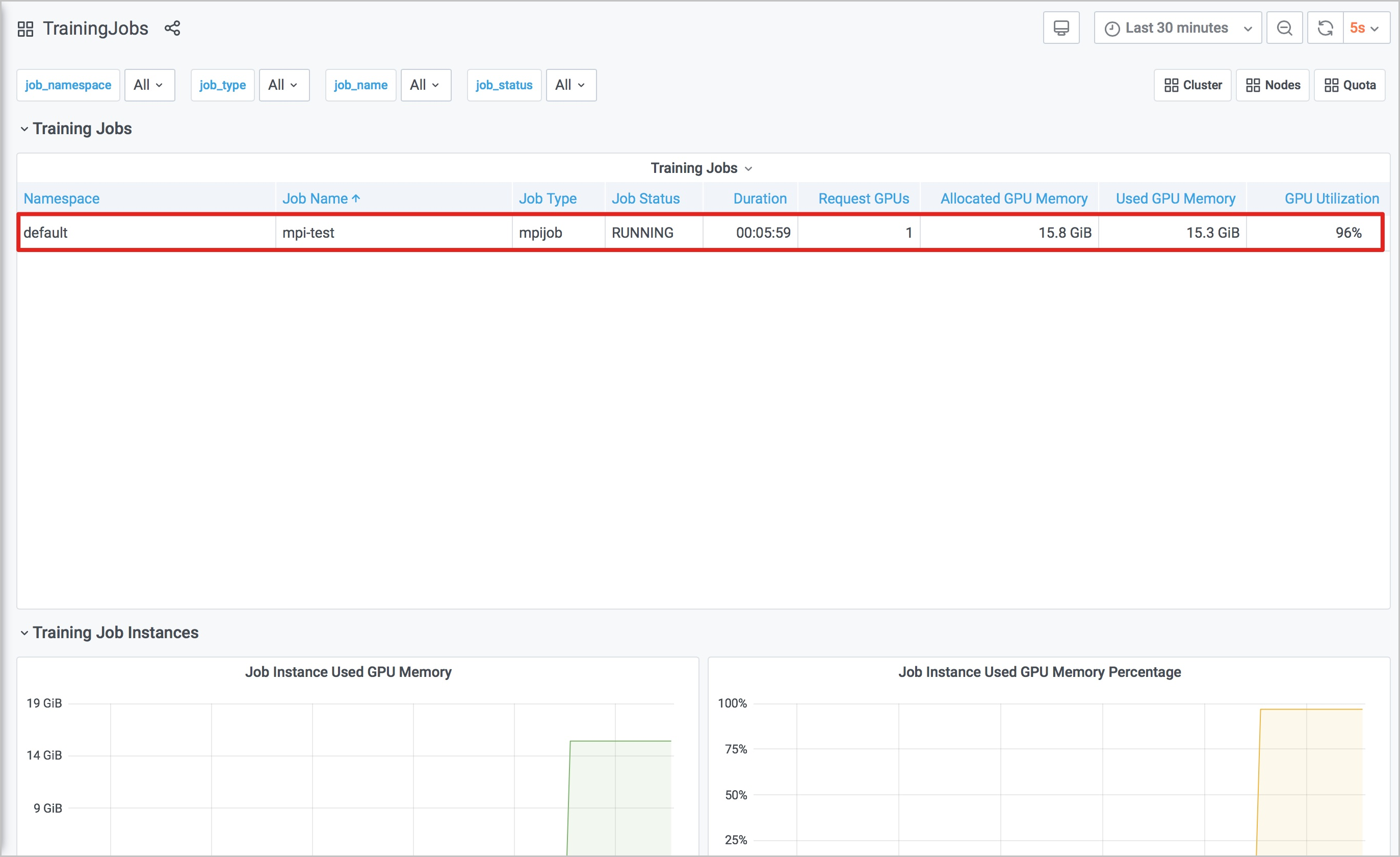
Training Jobs:通過表格的形式展示各個訓練任務的情況,包括:
訓練任務所在命名空間(Namespace)
訓練任務名稱(Job Name)
訓練任務類型(Job Type)
訓練任務狀態(Job Status)
訓練任務持續時間(Duration)
訓練任務請求GPU卡數(Request GPUs)
訓練任務請求的GPU顯存(Allocated GPU Memory)
訓練任務當前使用的GPU顯存(Used GPU Memory)
訓練任務的GPU平均利用率(GPU Utilization)
Job Instance Used GPU Memory:訓練任務中的各個實例的已使用GPU顯存。
Job Instance Used GPU Memory Percentage:訓練任務中各個實例使用GPU顯存的百分比。
Job Instance GPU Duty Cycle:訓練任務中各個實例的GPU利用率。
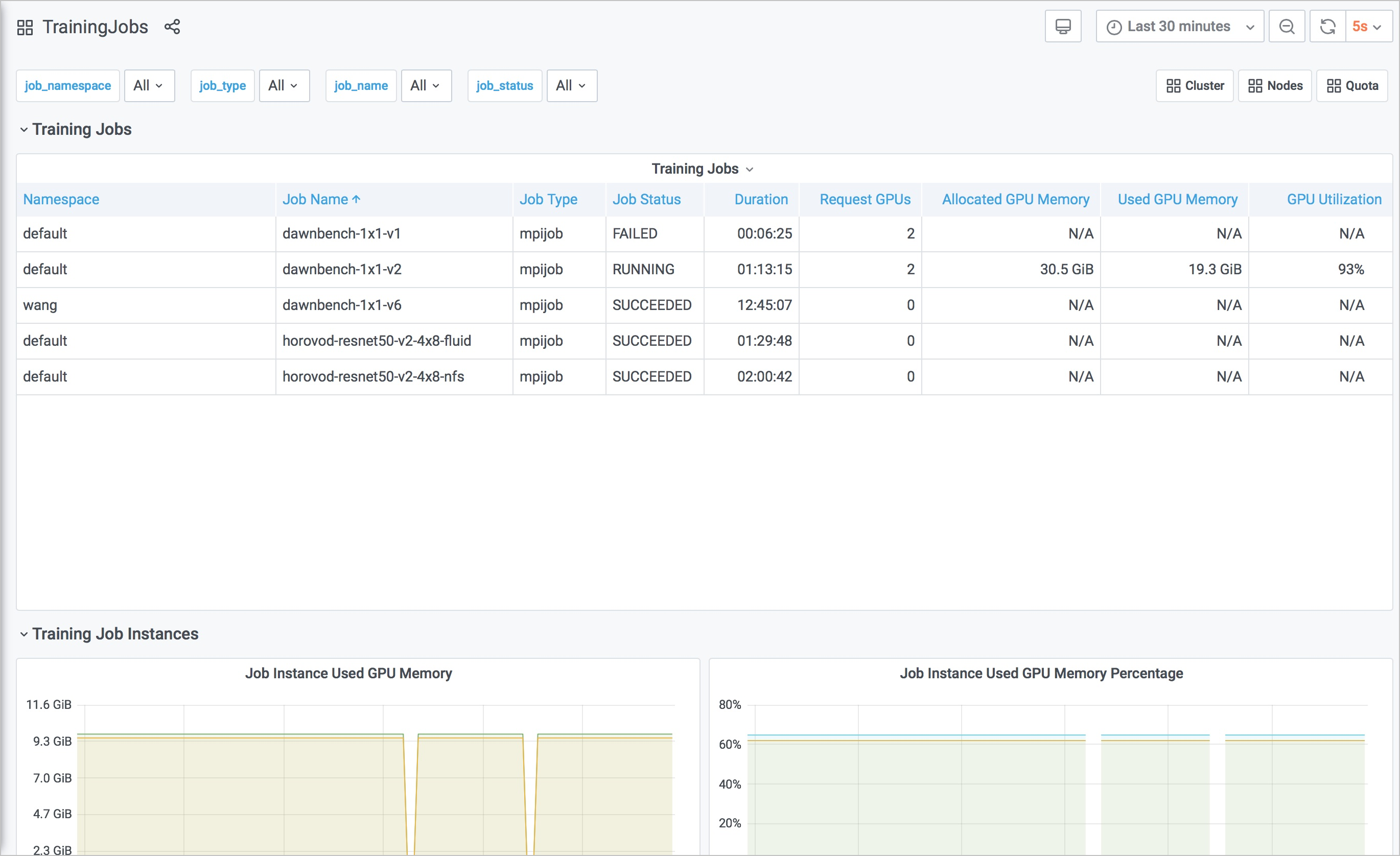
您可以根據訓練任務監控大盤左上角的job_namespace、job_type和job_name等篩選項,對訓練任務從不同維度進行篩選,以便您查看到目標訓練任務的具體情況。

資源配額監控大盤
在訓練任務監控大盤頁面,單擊右上角的Quota,進入資源配額監控大盤。
資源配額監控大盤有以下可供您查看的指標:
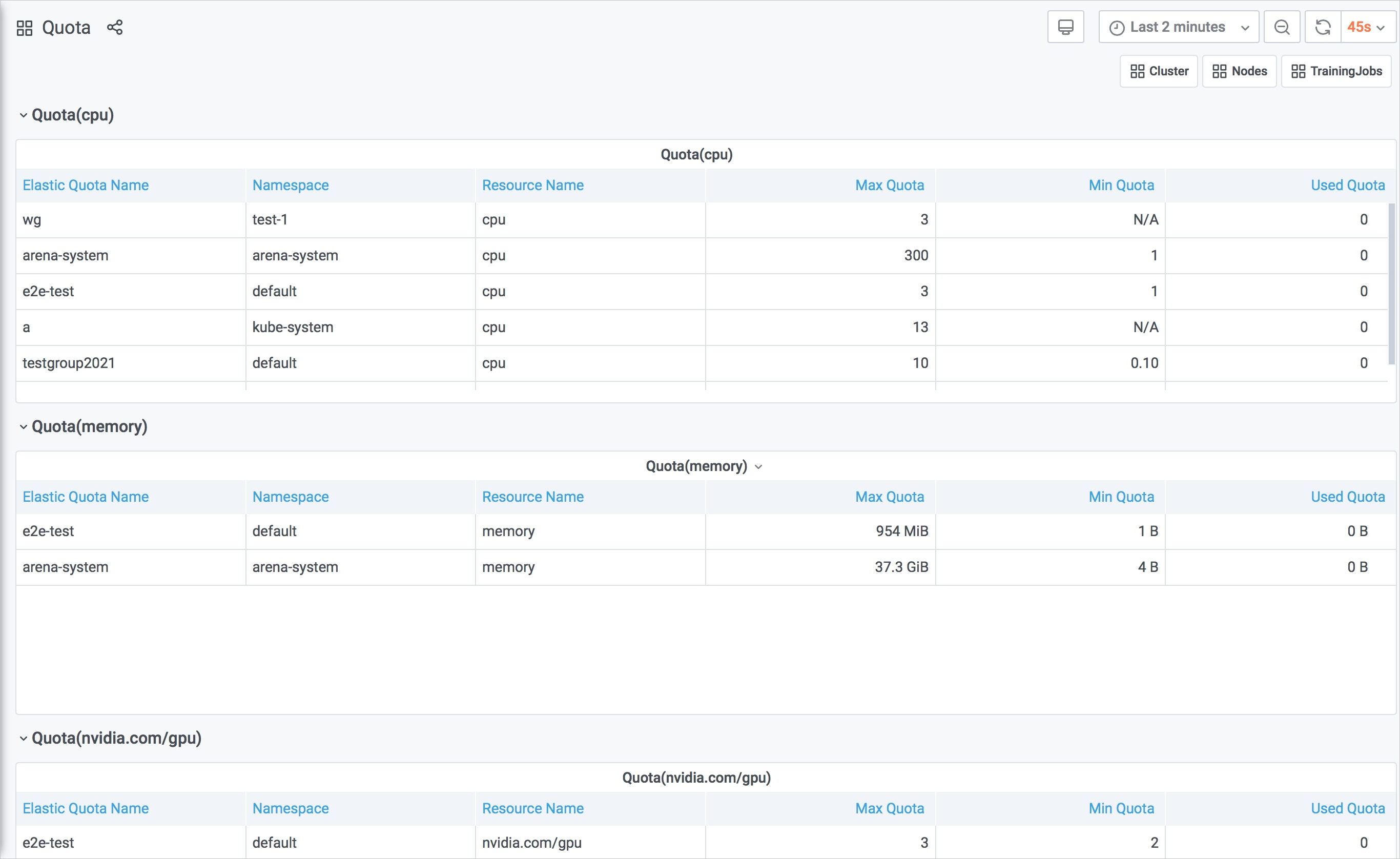
Quota(cpu)
Quota(memory)
Quota(nvidia.com/gpu)
Quota(aliyun.com/gpu-mem)
Quota(aliyun.com/gpu)
以上枚舉的每一個指標都以表格的形式展示資源配額的相關信息,包括:
Elastic Quota Name:資源配額的名稱。
Namespace:資源所屬的Namespace。
Resource Name:資源類型的名稱。
Max Quota:您在某個Namespace下某種資源所使用的上限。
Min Quota:當整個集群資源緊張時,您在某個Namespace下可以使用的保障資源。
Used Quota: 您在某個Namespace下,某種資源的已使用值。
使用云原生AI監控大盤示例
本文以使用Arena提交一個mpijob任務,然后查看監控大盤的變化為例,說明如何使用云原生AI監控大盤。
進入云原生AI運維控制臺,默認進入的是集群監控大盤頁面。
當集群沒有任何訓練任務時,集群監控大盤如下。
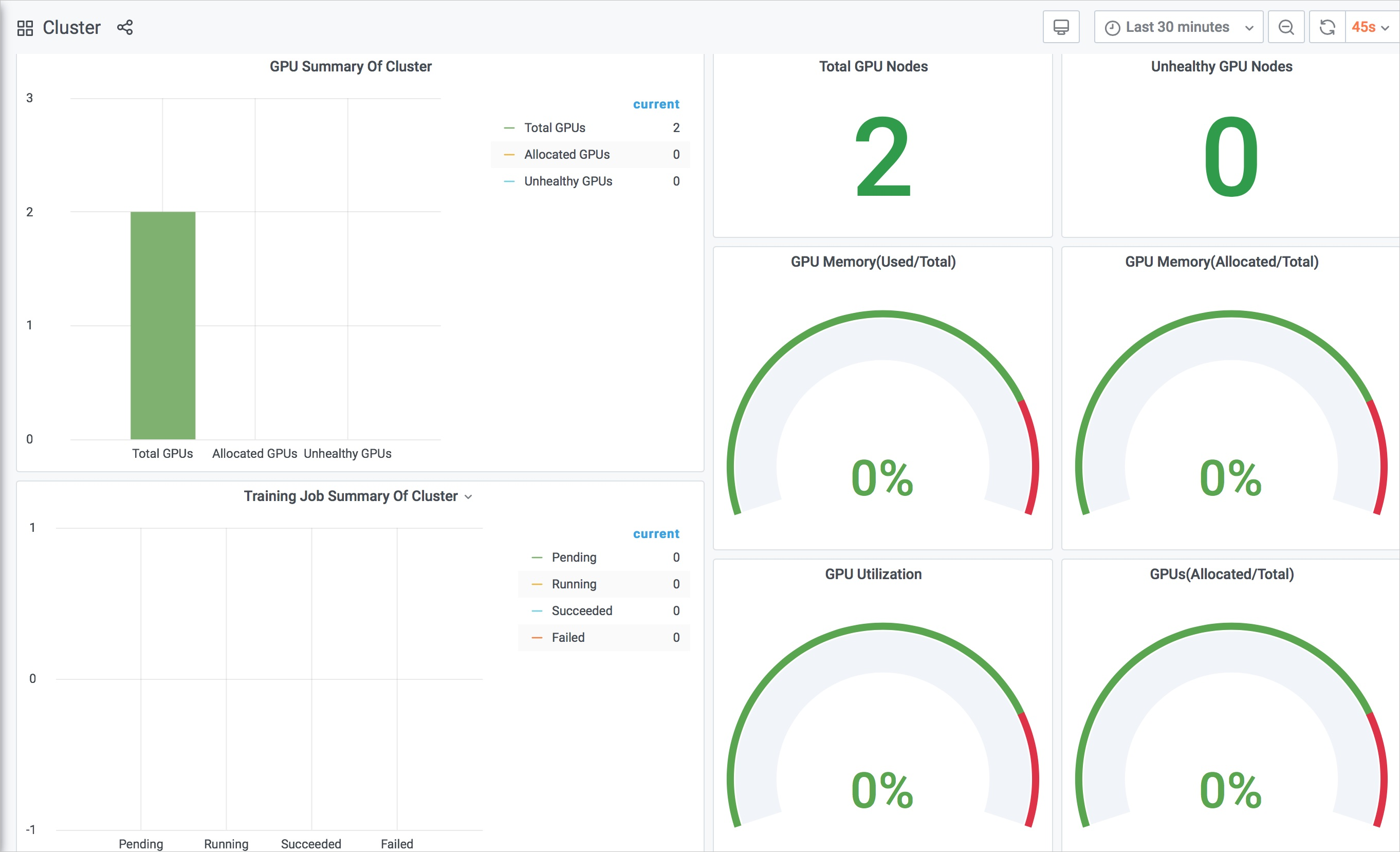
由上圖可知,集群總共有兩個GPU節點,總共有2張GPU卡。
執行以下命令,提交一個
mpijob。arena submit mpijob \ --name=mpi-test \ --gpus=1 \ --workers=1 \ --working-dir=/perseus-demo/tensorflow-demo/ \ --image=registry.cn-beijing.aliyuncs.com/ai-samples/horovod:0.13.11-tf1.10.0-torch0.4.0-py3.5 \ 'mpirun python /benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model resnet101 --batch_size 64 --num_batches 5000 --variable_update horovod --train_dir=/training_logs --summary_verbosity=3 --save_summaries_steps=10'再次查看集群監控大盤。
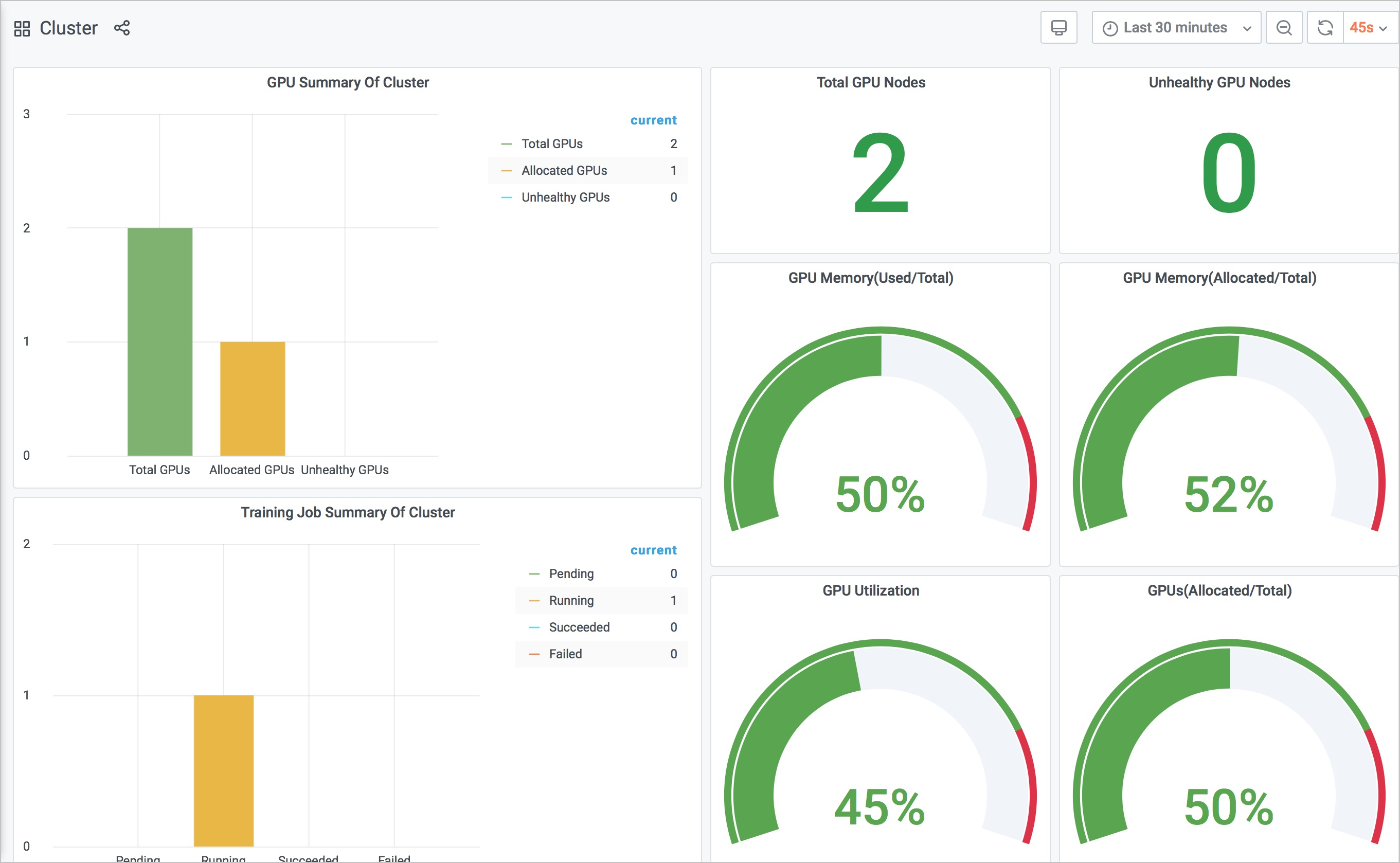
由上圖可知,集群的GPU的平均利用率、已分配GPU個數與總的GPU數的百分比等指標發生了變化。
執行以下命令,查看任務所在的節點。
arena list預期輸出:
NAME STATUS TRAINER DURATION GPU(Requested) GPU(Allocated) NODE mpi-test RUNNING MPIJOB 8s 1 1 192.168.1.151在集群監控大盤頁面,單擊右上角的Nodes,進入節點監控大盤。由步驟4中得出任務所在的節點IP為
192.168.1.151,在節點監控大盤上,您可以看到該節點上GPU的相關指標發生的變化如下。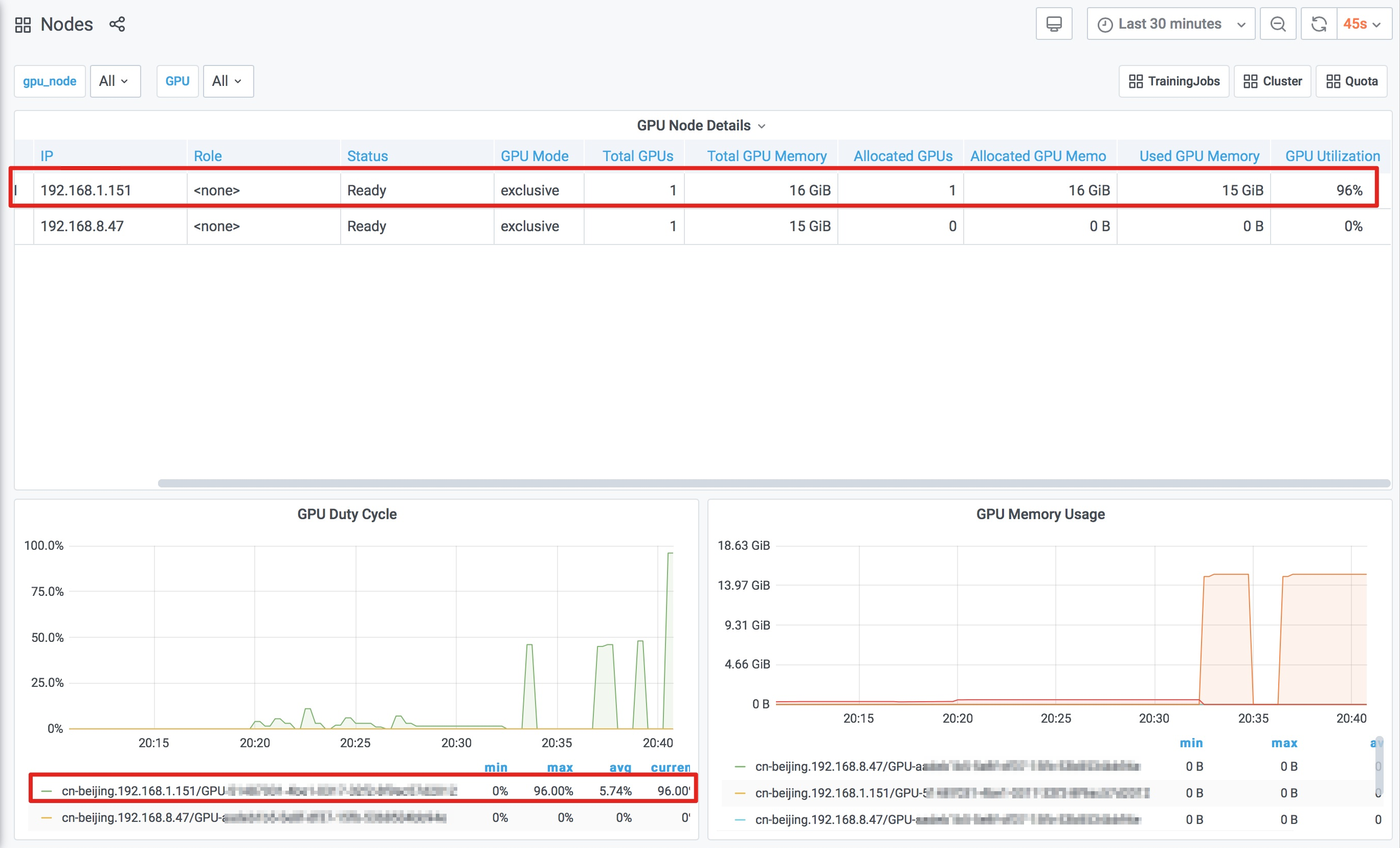
在節點監控大盤頁面,單擊右上角TrainingJobs,進入訓練任務監控大盤,您可以查看訓練任務的相關信息(任務名、任務狀態等)。