本文介紹通過阿里云Prometheus對GPU資源進行監控,查看GPU各項指標。
前提條件
您已完成以下操作:
已安裝阿里云Prometheus監控。具體操作,請參見阿里云Prometheus監控。
費用說明
在ACK集群中使用ack-gpu-exporter組件時,默認情況下它產生的阿里云Prometheus監控指標被視為基礎指標,并且是免費的。然而,如果您需要調整監控數據的存儲時長,即保留監控數據的時間超過阿里云為基礎監控服務設定的默認保留期限,這可能會產生額外的費用。關于阿里云Prometheus的自定義收費策略,請參見計費概述。
使用阿里云Prometheus進行GPU監控
登錄容器服務管理控制臺。
在集群列表頁面,單擊目標集群名稱或者目標集群右側操作列下的詳情。
在集群管理頁左側導航欄,選擇。
在Prometheus監控大盤列表頁面,單擊GPU APP和GPU Node頁簽,您分別可以看到GPU APP和GPU Node兩個監控大盤。
GPU APP用于監控Pod的GPU使用情況。
GPU Node用于監控集群節點的GPU使用情況。
使用以下YAML文件在GPU節點上部署一個服務,測試監控效果。
apiVersion: apps/v1 kind: Deployment metadata: name: bert-intent-detection spec: replicas: 1 selector: matchLabels: app: bert-intent-detection template: metadata: labels: app: bert-intent-detection spec: containers: - name: bert-container image: registry.cn-beijing.aliyuncs.com/ai-samples/bert-intent-detection:1.0.1 ports: - containerPort: 80 resources: limits: nvidia.com/gpu: 1 --- apiVersion: v1 kind: Service metadata: labels: run: bert-intent-detection name: bert-intent-detection-svc spec: ports: - port: 8500 targetPort: 80 selector: app: bert-intent-detection type: LoadBalancer在Prometheus監控大盤列表頁面,單擊GPU APP頁簽。
在GPU APP監控頁面,您可以看到GPU顯存、使用率、電量、穩定性幾項指標,以及部署在GPU節點上的應用。
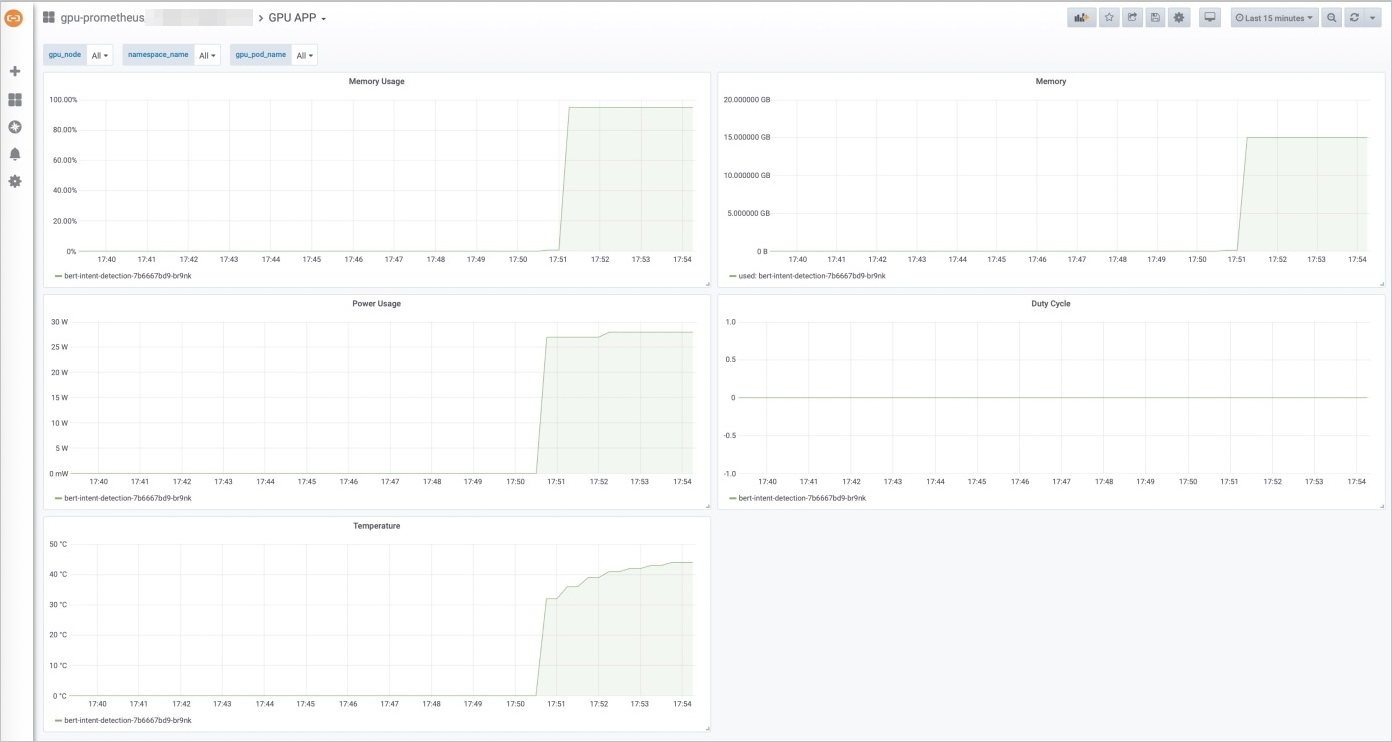
壓測部署在GPU節點上的應用,查看監控狀態的變化。
執行以下命令查看推理服務并獲取IP地址。
kubectl get svc bert-intent-detection-svc預期輸出:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE bert-intent-detection-svc LoadBalancer 172.23.5.253 123.56.XX.XX 8500:32451/TCP 14m執行以下命令進行壓測。
hey -z 10m -c 100 "http://123.56.XX.XX:8500/predict?query=music"下圖可以看出壓測時,GPU利用率有了明顯的變化。
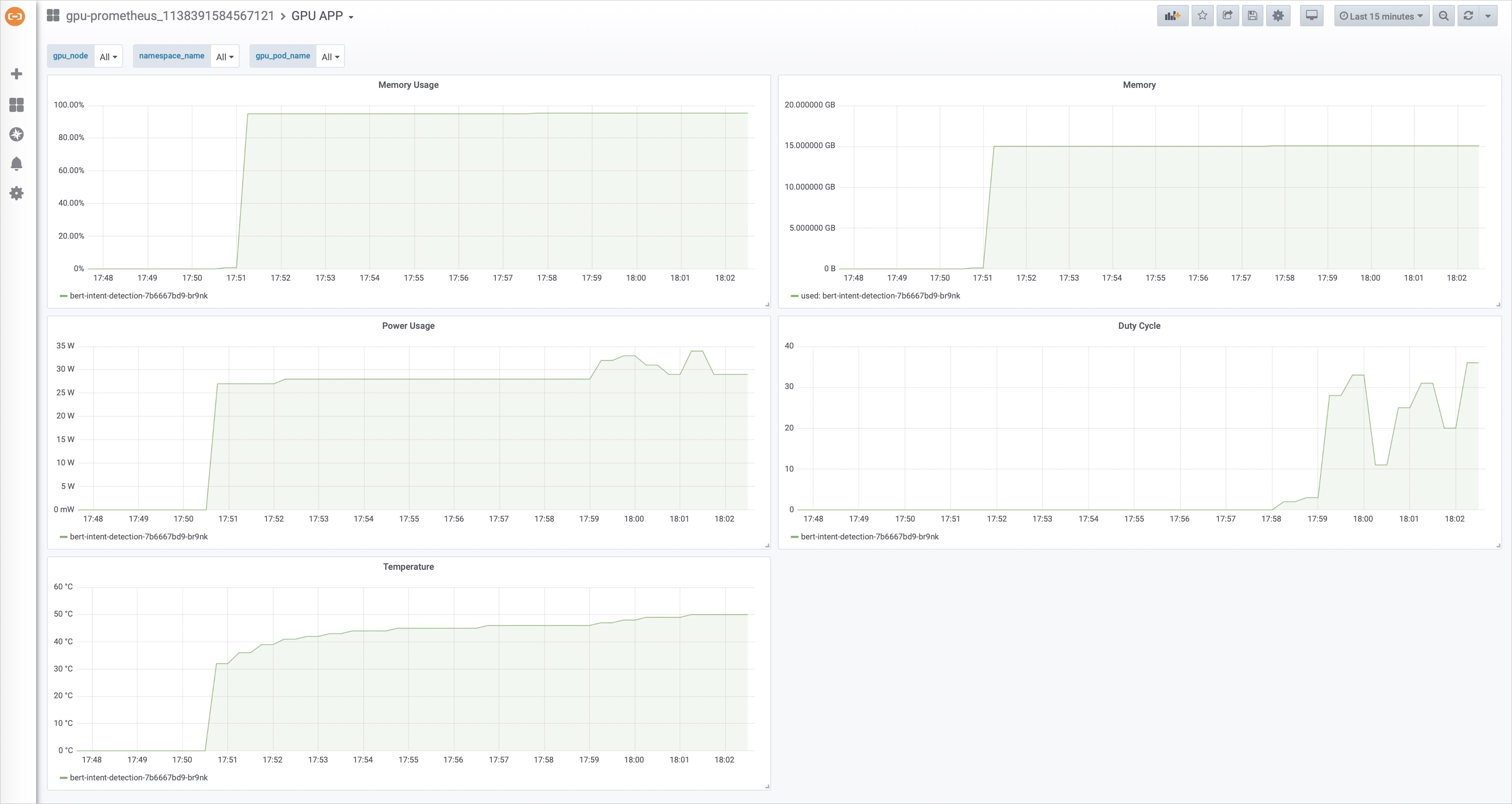
文檔內容是否對您有幫助?