ACK Net Exporter是部署在集群內部的網絡可觀測性增強組件,能夠提供容器網絡相關的詳盡監控數據,幫助您快速發現和定位網絡問題。本文介紹Kubernetes使用ACK Net Exporter的最佳實踐,幫助您快速上手并解決實際問題。
前提條件
已創建ACK托管版集群。詳細信息,請參見創建ACK托管集群。
背景信息
ACK Net Exporter通過守護進程Pod的方式運行在節點上,借助eBPF技術,采集節點的信息并聚合到具體的Pod中,提供標準化的接口,實現對網絡高階信息的觀測。ACK Net Exporter的核心架構如下圖所示。

安裝與配置ACK Net Exporter組件
安裝ACK Net Exporter組件
登錄容器服務管理控制臺,在左側導航欄選擇。
在應用市場頁面搜索ack-net-exporter,然后單擊搜索到的組件。
在ack-net-exporter組件頁面右上角單擊一鍵部署。
在基本信息配置向導中選擇需要部署組件的集群,命名空間,然后單擊下一步。
在參數配置配置向導中設置參數,然后單擊確定。
參數
描述
默認值
name
ACK Net Exporter組件的名稱。
ack-net-exporter-default
namespace
ACK Net Exporter組件的命名空間。
kube-system
config.enableEventServer
是否開啟事件追蹤服務。取值:
false:不開啟事件追蹤服務。
true:開啟事件追蹤服務。
false
config.enableMetricServer
是否開啟指標采集服務。取值:
false:不開啟指標采集服務。
true:開啟指標采集服務。
true
config.remoteLokiAddress
推送事件的遠端Grafana Loki服務地址
默認為空。
config.metricLabelVerbose
是否開啟指標的詳情功能。取值:
false:不開啟指標的詳情功能。
true:開啟指標的詳情功能。開啟后會額外將Pod的IP以及重要的標簽信息作為指標的標簽信息。
false
config.metricServerPort
指標服務的端口,提供HTTP服務。
9102
config.eventServerPort
事件服務的端口,提供GRPC Stream的事件流服務。
19102
config.metricProbes
需要開啟的指標探針。詳細信息,請參見下文ACK Net Exporter指標列表。
默認為空,不配置任何指標探針的情況下,會默認啟動必需探針。
config.eventProbes
需要開啟的事件探針。詳細信息,請參見下文ACK Net Exporter事件詳解。
默認為空,不配置任何指標探針的情況下,會默認啟動必需探針。
配置ACK Net Exporter組件
您可以執行如下命令,通過ConfigMap方式配置ACK Net Exporter組件。
kubectl edit cm inspector-config -n kube-system您也可以通過控制臺配置ACK Net Exporter組件。
登錄容器服務管理控制臺,在左側導航欄單擊集群。
在集群列表頁面,單擊目標集群名稱,然后在左側導航欄,選擇。
在配置項頁面,設置命名空間為kube-system,然后搜索kubeskoop-config,單擊kubeskoop-config右側操作列下的編輯。
在編輯面板配置參數,然后單擊確定。
ACK Net Exporter支持的配置項及其含義如下:
參數
描述
默認值
debugmode
是否開啟調試模式。取值:
false:不開啟調試模式。
true:開啟調試模式。開啟后,支持DEBUG級別的日志,調試接口,Go pprof和gops診斷工具。
false
event_config.loki_enable
是否開啟事件向遠端Grafana Loki服務推送的功能。詳細信息,請參見下文使用Grafana Loki收集監控事件并可視化。取值:
false:不開啟事件向遠端Grafana Loki服務推送的功能。
true:開啟事件向遠端Grafana Loki服務推送的功能。
false
event_config.loki_address
遠端Grafana Loki服務的地址,默認會自動發現相同命名空間下的名為grafana-loki的服務。
默認為空。
event_config.probes
需要開啟的事件探針。詳細信息,請參見下文ACK Net Exporter事件詳解。
默認為空,不配置任何指標探針的情況下,會默認啟動必需探針。
event_config.port
事件服務的端口,提供GRPC Stream的事件流服務。
19102
metric_config.verbose
是否開啟指標的詳情功能。取值:
false:不開啟指標的詳情功能。
true:開啟指標的詳情功能。開啟后會額外將Pod的IP以及重要的標簽信息作為指標的標簽信息。
false
metric_config.port
指標服務的端口,提供HTTP服務。
9102
metric_config.probes
需要開啟的指標探針。詳細信息,請參見下文ACK Net Exporter指標列表。
默認為空,不配置任何指標探針的情況下,會默認啟動必需探針。
metric_config.interval
指標采集的事件間隔。由于指標采集存在一定性能損耗,因此ACK Net Exporter會定期采集后緩存在內存中。
5
在v0.2.3版本及更新版本的ACK Net Exporter中,已經支持了配置的熱更新,如果您使用較早期的版本,在修改配置之后需要觸發ACK Net Exporter所有容器的重建來使配置變更生效。
ACK Net Exporter使用說明
在Alinux以外的操作系統上使用ACK Net Exporter
ACK Net Exporter的部分核心功能依賴于eBPF程序進行采集。為了滿足使用不同操作系統內核的需求,ACK Net Exporter采用CO-RE的方式實現eBPF程序的分發。在啟動過程中,依賴于與操作系統內核關聯的BTF文件(操作系統內核的調試信息元數據的文件)進行加載。如果沒有適配的BTF文件,這部分功能將不可用。在高版本的操作系統中,一般都會內置BTF文件的支持。關于操作系統的更多信息,請參見BPF Type Format。
目前我們為在Alinux2和Alinux3節點上運行的ACK Net Exporter提供了適配服務。該功能需要滿足以下條件:
操作系統內核為4.10以上版本。
至少安裝了以下任意一項文件。
已安裝對應的kernel-debuginfo文件(內核調試信息的數據文件)。
具有攜帶debug信息的vmlinux文件(操作系統內核編譯后且未經過壓縮的原始文件)。
已安裝操作系統提供的對應的BTF文件。
更新ACK Net Exporter為0.2.9或以上版本,并在安裝時將config.enableLegacyVersion設置為false。
在符合上述條件的情況下,您可以按照以下步驟使用ACK Net Exporter提供的高級功能:
將具備BTF信息的文件放在節點的/boot/路徑下。
如果您安裝了完整的vmlinux文件,您可以將vmlinux文件放置到操作系統的/boot/路徑中。
如果您安裝了kernel-debuginfo包,在安裝了kernel-debuginfo包之后,您可以在節點上/usr/lib/debug/lib/modules/路徑中根據對應的內核版本查找到帶有調試信息的vmlinux文件,然后將其復制到/boot/路徑中。
執行以下命令,驗證是否已經具備有效的BTF信息和是否支持ACK Net Exporter的運行。
# 您可以使用docker/podman/ctr等類似命令運行測試 nerdctl run -it -v /boot:/boot registry.cn-hangzhou.aliyuncs.com/acs/btfhack:latest -- btfhack discover如果以上測試命令成功輸出了您準備好的BTF信息文件路徑,則已經完成了配置,您可以觸發ACK Net Exporter的重建,等待一段時間后即可查看到更多指標和事件。
ACK Net Exporter的監控指標及格式
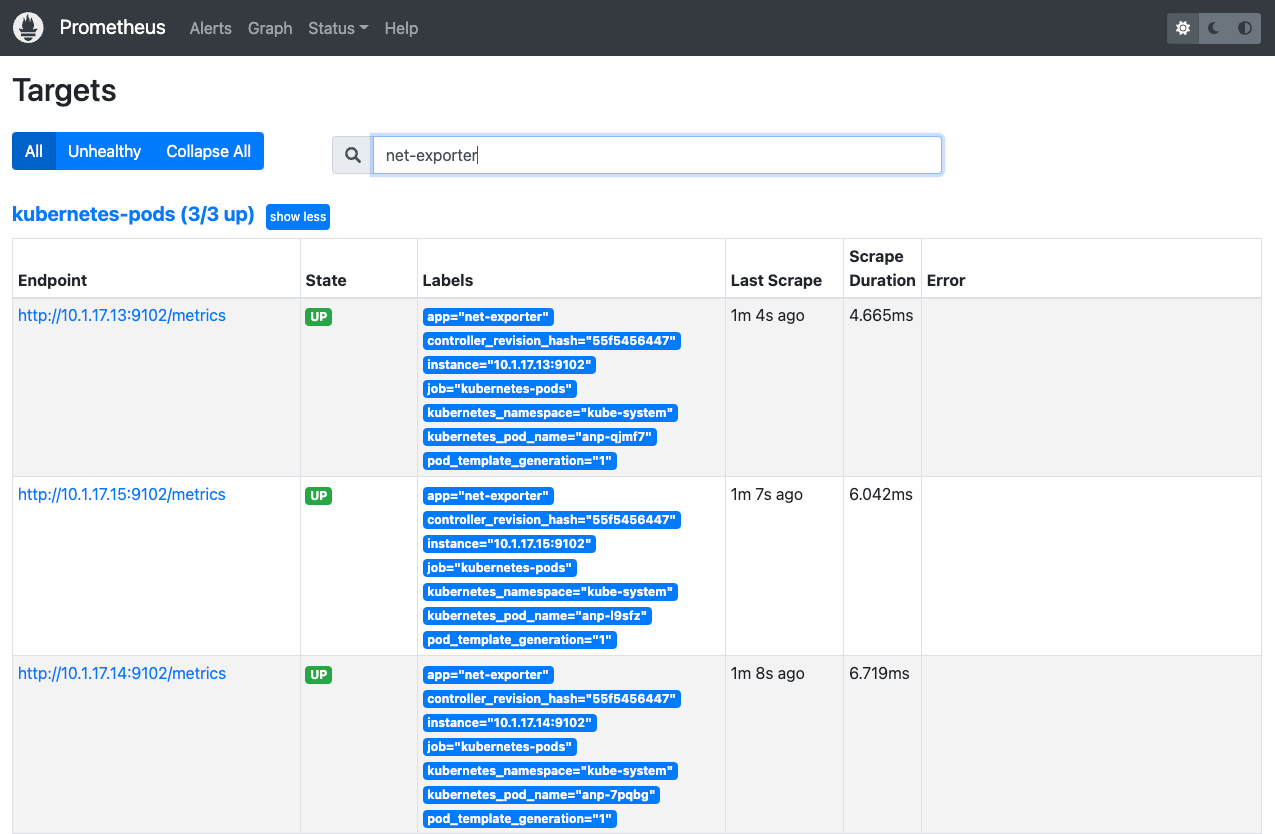
ACK Net Exporter提供適配Prometheus格式的監控數據,在安裝完ACK Net Exporter后,您可以通過訪問任意一個ACK Net Exporter的Pod實例的服務端口獲取到全部的指標信息:
如果您通過應用市場安裝了ACK Net Exporter,可執行如下命令獲取到所有ACK Net Exporter實例。
kubectl get pod -l app=net-exporter -n kube-system -o wide預期輸出:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES anp-*** 1/1 Running 0 32s 10.1.XX.XX cn-*** <none> <none>執行如下命令,獲取指標信息,需要將命令中的
10.1.XX.XX替換為上一步中獲取到的ACK Net Exporter實例的地址。curl http://<10.1.XX.XX>:9102/metrics
ACK Net Exporter提供的監控指標數據格式如下:
inspector_pod_udprcvbuferrors{namespace="elastic-system",netns="ns402653****",node="iZbp179u0bgzhofjupc****",pod="elastic-operator-0"} 0 1654487977826不同字段代表的含義如下:
inspector_pod_udprcvbuferrors表示這是一個由ACK Net Exporter提供的指標,它的作用范圍是Pod(指標作用范圍包含Pod與Node,代表指標表征的數據是Pod或者Node級別有效),它的名稱是udprcvbuferrors,表示單個Pod內出現的UDP報文因為收包隊列滿而導致的錯誤。namespace、pod、node和netns均為指標可用的Label,您可以使用PromQL對指標的Label進行過濾。其中namespace、pod與Kubernetes中的含義一致,node是您的節點的主機名,一般默認為/etc/hostname文件中保存的主機名,netns是某個Pod的容器所在的Linux網絡命名空間的ID,用于標記單個容器獨立的網絡空間。指標后方的
0與1654487977826分別代表指標的有效數據和指標產生的時間,時間是UNIX時間戳的格式。
ACK Net Exporter的監控事件及格式
ACK Net Exporter支持采集節點上發生的網絡相關的異常事件。根據長期處理網絡問題中的經驗,我們歸納了幾種常見的網絡疑難問題。這些問題往往在集群中難以無法復現,以偶然發生的方式干擾正常的業務,缺乏有效的定位手段,其中部分如下:
網絡數據報文被丟棄引發的連接失敗,響應超時等問題。
網絡數據處理耗時久引發的偶發性能問題。
TCP、conntrack等狀態機制異常引發的業務異常問題。
針對無法快速復現和難以獲取現場的網絡問題,ACK Net Exporter提供了基于eBPF的操作系統內核上下文觀測能力。在問題發生的現場捕獲操作系統的實時狀態,并輸出事件日志。關于ACK Net Exporter支持的事件和相關的探針信息,請參見ACK Net Exporter事件詳解。
在事件日志的信息中,可以查看到事件現場的相關信息.。以tcp_reset探針為例,當出現Pod收到了一個訪問未知端口的正常報文時,ACK Net Exporter會捕獲以下事件信息。
type=TCPRESET_NOSOCK pod=storage-monitor-5775dfdc77-fj767 namespace=kube-system protocol=TCP saddr=100.103.42.233 sport=443 daddr=10.1.17.188 dport=33488type=TCPRESET_NOSOCK:出現了一次TCPRESET_NOSOCK類型的事件。這屬于tcpreset探針捕獲的一種事件,表明有訪問未知端口的報文被本地發送RST報文拒絕,拒絕的原因是沒有根據報文找到相應的Socket。通常在NAT失效后會發生這個事件,例如IPVS定時器超時等原因發生后。pod/namespace:ACK Net Exporter根據發送報文的網絡命名空間,系統在匹配IP地址和網絡設備序號后關聯給事件的Pod元信息。saddr/sport/daddr/dport:ACK Net Exporter在內核獲取到的異常報文的信息。隨著事件的不同獲取的異常報文信息也會有差異,例如net_softirq探針的事件信息中沒有IP地址,取而代之的是中斷發生的CPU序號,產生的延遲時長等。
對于需要有效的操作系統內核堆棧信息的事件,ACK Net Exporter會捕獲事件發生時在操作系統內核中的堆棧上下文信息。例如以下事件信息。
type=PACKETLOSS pod=hostNetwork namespace=hostNetwork protocol=TCP saddr=10.1.17.172 sport=6443 daddr=10.1.17.176 dport=43018 stacktrace:skb_release_data+0xA3 __kfree_skb+0xE tcp_recvmsg+0x61D inet_recvmsg+0x58 sock_read_iter+0x92 new_sync_read+0xE8 vfs_read+0x89 ksys_read+0x5AACK Net Exporter支持多種事件查看方式,詳細介紹,請參見下文的從ACK Net Exporter收集監控數據。
從ACK Net Exporter收集監控數據
場景一:使用Prometheus或Grafana收集監控數據并可視化
ACK Net Exporter支持輸出到Prometheus Server實例,如果您使用自行搭建的Prometheus Server,您可以通過添加一組scrape_config的方式來使您的Prometheus Server實例主動抓取ACK Net Exporter的數據,類似如下配置:
# 只包含一個要抓取的端點的抓取配置。
scrape_configs:
# "net-exporter_sample"將作為“job=<job_name>”標簽添加到從此配置中抓取的任何時間序列中。
- job_name: "net-exporter_sample"
static_configs:
- targets: ["{kubernetes pod ip}:9102"]
如果您的Prometheus Server實例運行在ACK集群中,您也可以通過Prometheus服務發現功能自動獲取到所有正常提供服務的ACK Net Exporter實例,您可以通過在Prometheus Server的配置中添加以下內容:
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-server-conf
labels:
name: prometheus-server-conf
namespace: kube-system
data:
prometheus.yml: |-
# 將以下內容添加到Promethes Server配置中。
- job_name: 'net-exporter'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_endpoints_name]
regex: 'net-exporter'
action: keep
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
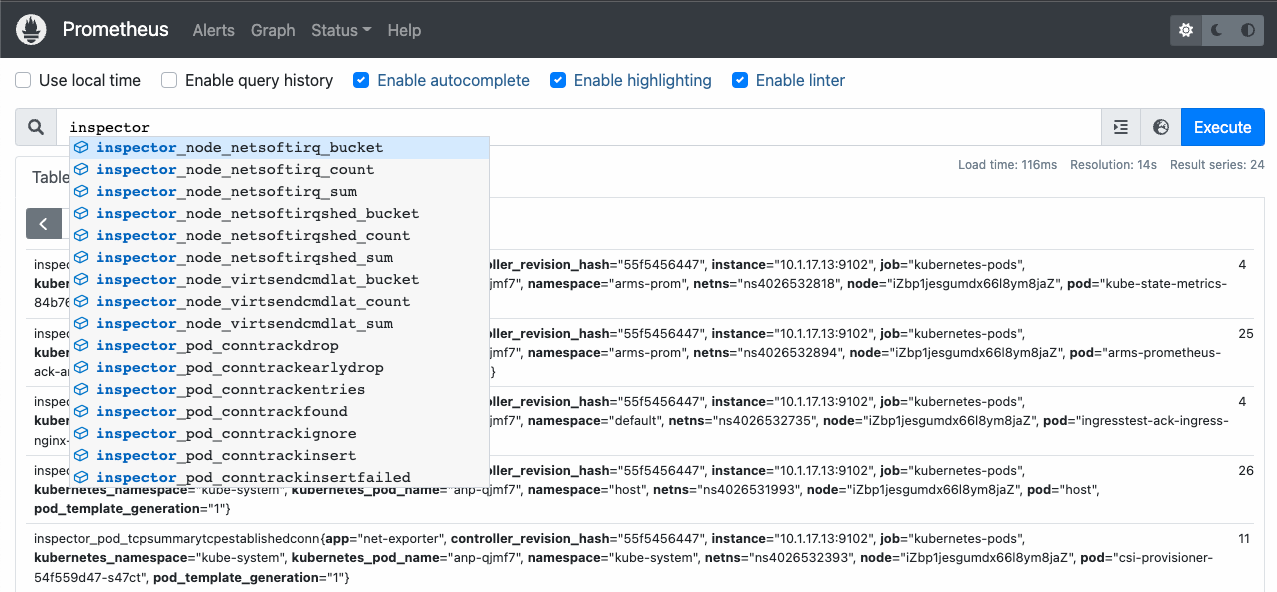
target_label: kubernetes_pod_name添加完成后,可以在Prometheus Server的界面看到已經生效的ACK Net Exporter實例,或者在Prometheus Server的Graph界面的搜索欄中輸入inspector,即可看到自動補全的ACK Net Exporter指標。
您可以通過配置Grafana將Prometheus采集到的數據進行可視化操作:
打開Grafana頁面,在左側導航欄中選擇
 > Dashboard。
> Dashboard。在New dashboard頁面單擊Add an empty panel。
進入Edit Panel頁面,在下方Data source中輸入Prometheus,然后選擇已經完成Prometheus Server的接口地址。
單擊Metric browser, 然后輸入inspector,Grafana會自動補全ACK Net Exporter所有就緒的Metric,單擊右上角Save,在彈出框中單擊Save,然后會出現可視化的數據,效果如下:
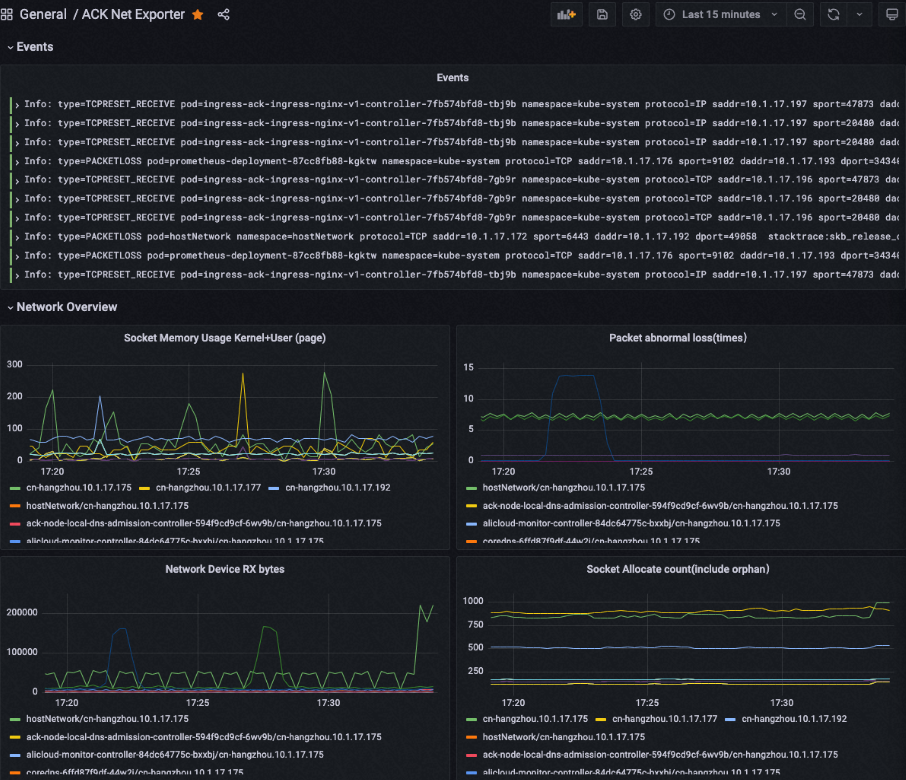
對于使用Grafana進行可視化圖形顯示的配置,可以參照上述的指標格式,對指標的顯示格式進行調整,例如
inspector_pod_tcppassiveopens指標,表征系統自開機或者Pod所屬的容器創建后,歸屬于這個網絡命名空間內的所有TCP連接由于接受客戶端的握手請求創建的Socket總數變化,通常可以認為是表征TCP總連接數量的增長,為了更加直觀的反應增長的速率變化,可以參考以下配置:// 使用PromQL提供的rate()方法配置Metrics。 rate(inspector_pod_tcppassiveopens[1m]) // 使用net-exporter提供的標簽來配置Legend,直觀顯示Metrics。 {{namespace}}/{{pod}}/{{node}}
場景二:使用應用實時監控服務ARMS收集監控數據并可視化
ACK Net Exporter支持通過應用實時監控服務ARMS進行數據可視化操作,步驟如下:
配置ACK Net Exporter自定義指標。
登錄ARMS控制臺,在左側導航欄中選擇。
登錄ARMS控制臺。
在頁面頂部,選擇容器服務ACK集群所在的地域
在左側導航欄選擇,進入可觀測監控 Prometheus 版的實例列表頁面。
- 單擊目標Prometheus實例名稱,進入集成中心頁面。
在實例列表頁面,單擊目標實例名稱(一般是集群名稱)進入對應實例頁面。
在左側導航欄中單擊服務發現,然后單擊Targets頁簽,在頁面下方的kubernetes-pods選項頁可以看到ACK Net Exporter的指標已經配置成功。
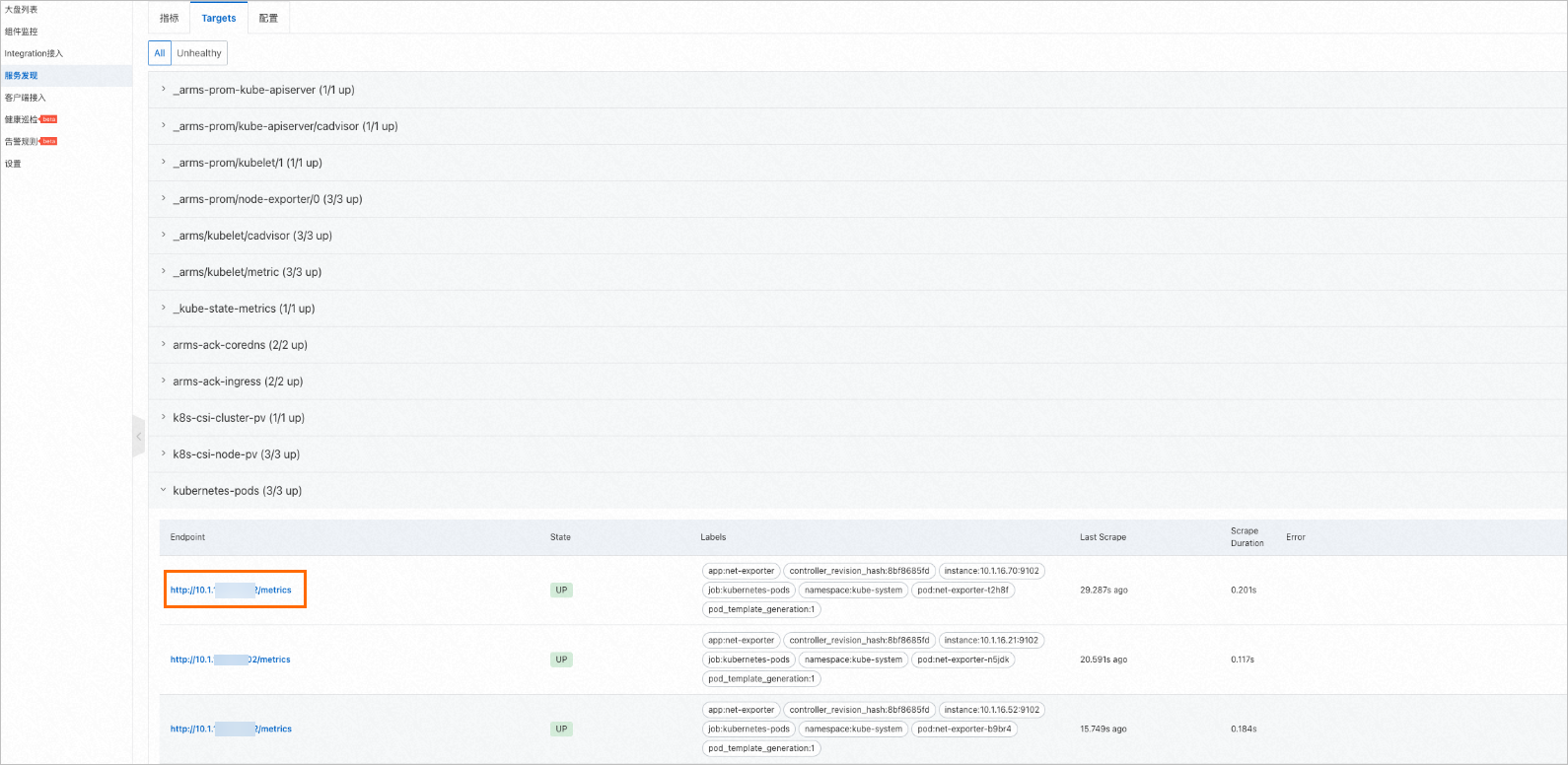
如果沒有找到相關的Pod,則需要您在配置頁簽下手動開啟默認服務發現的選項。

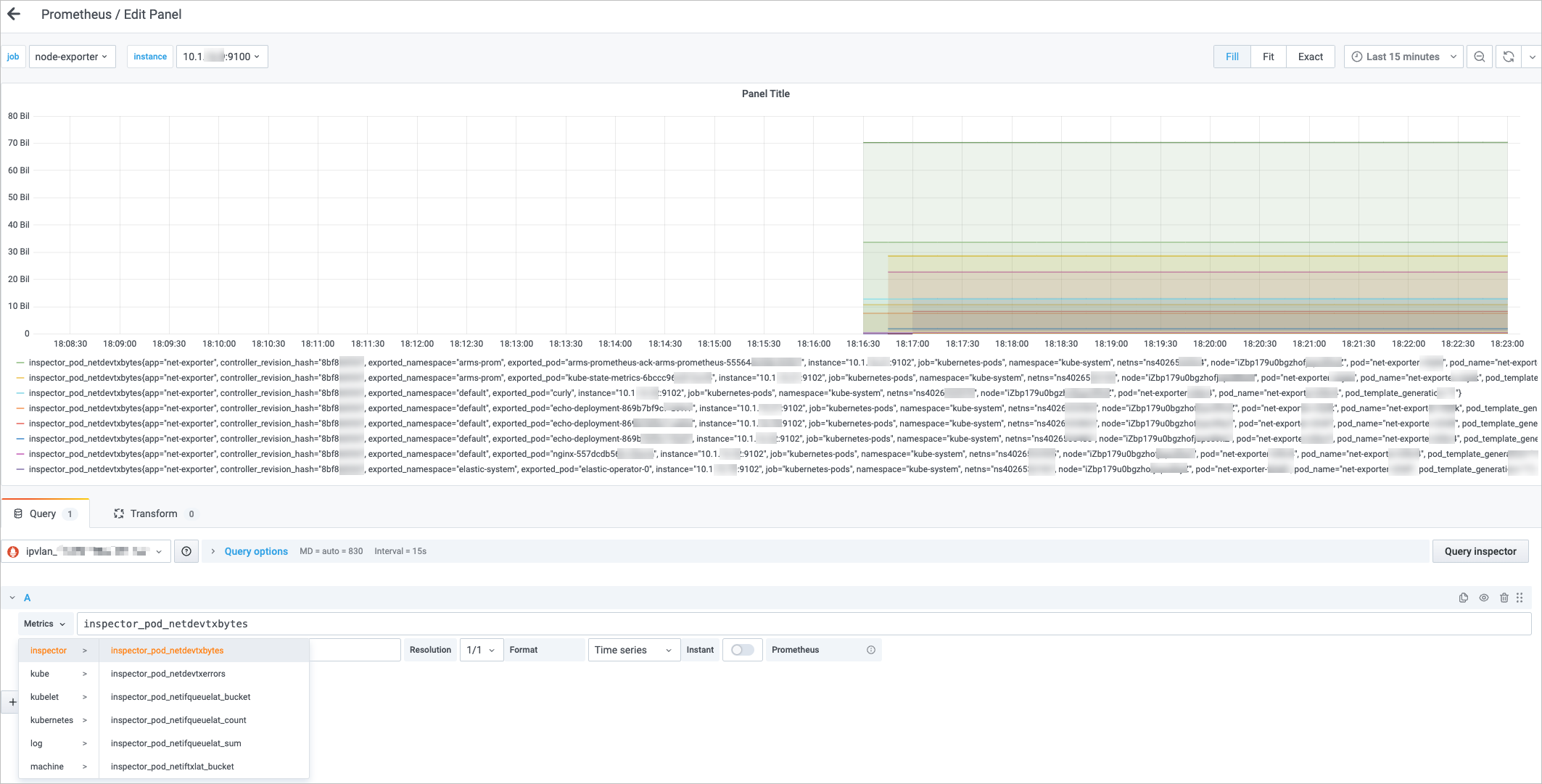
在左側導航欄中單擊大盤列表,單擊目標大盤進入Grafana,然后單擊添加Panel,選擇Graph類型,在Data source中選擇開啟ACK Net Exporter的集群相關的數據源。
單擊Metric browser, 然后輸入inspector,Grafana會自動補全ACK Net Exporter所有就緒的Metric,單擊右上角Save,在彈出框中單擊Save,然后會出現可視化的數據,效果如下:
場景三:使用Grafana Loki收集監控事件并可視化
ACK Net Exporter采集的異常事件類型的數據,支持通過預先配置的Grafana Loki服務,由ACK Net Exporter向Loki進行實時推送,從而達到將分布式的異常事件進行集中式的串型查看分析,使用ACK Net Exporter配合Grafana Loki的服務步驟如下:
- 說明
服務需要位于ACK Net Exporter的Pod可以訪問的網絡中,ACK Net Exporter會主動向已經配置并就緒的Grafana Loki服務推送事件日志信息。
在安裝ACK Net Exporter的配置頁面中,將enableEventServer配置為true,將lokiServerAddress配置為Grafana Loki服務的地址。您可以配置Grafana Loki服務的IP地址,也可以配置Grafana Loki 服務的域名。

執行以下命令,訪問Grafana Loki的服務地址來檢驗Grafana Loki服務是否已就緒。
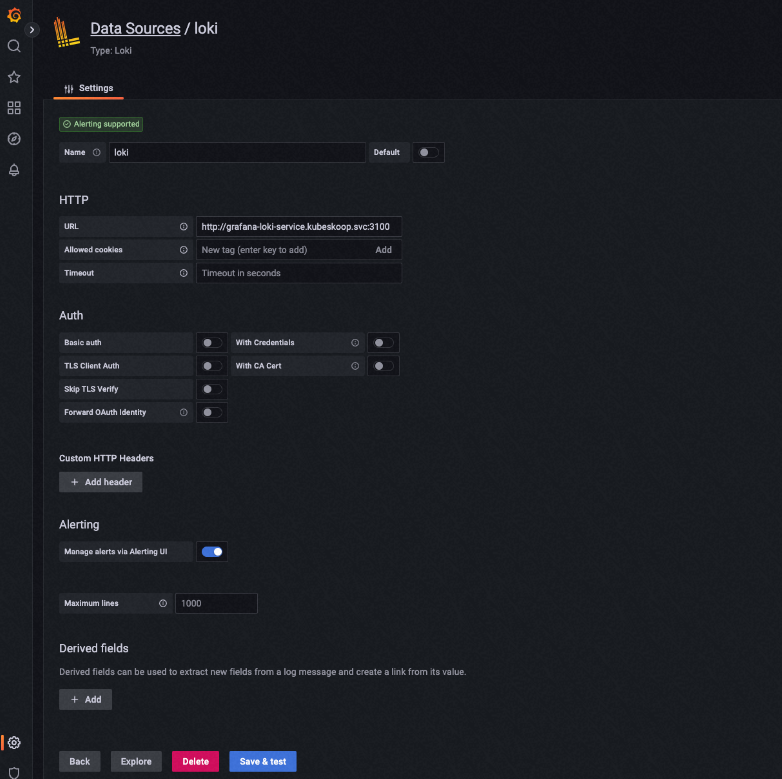
curl http://[Grafana Loki實例的地址]:3100/ready待Grafana Loki服務就緒后,添加Grafana Loki作為Grafana的數據源。
打開Grafana頁面,在左側導航欄中選擇,輸入Grafana Loki的接口地址,單擊Save&test。
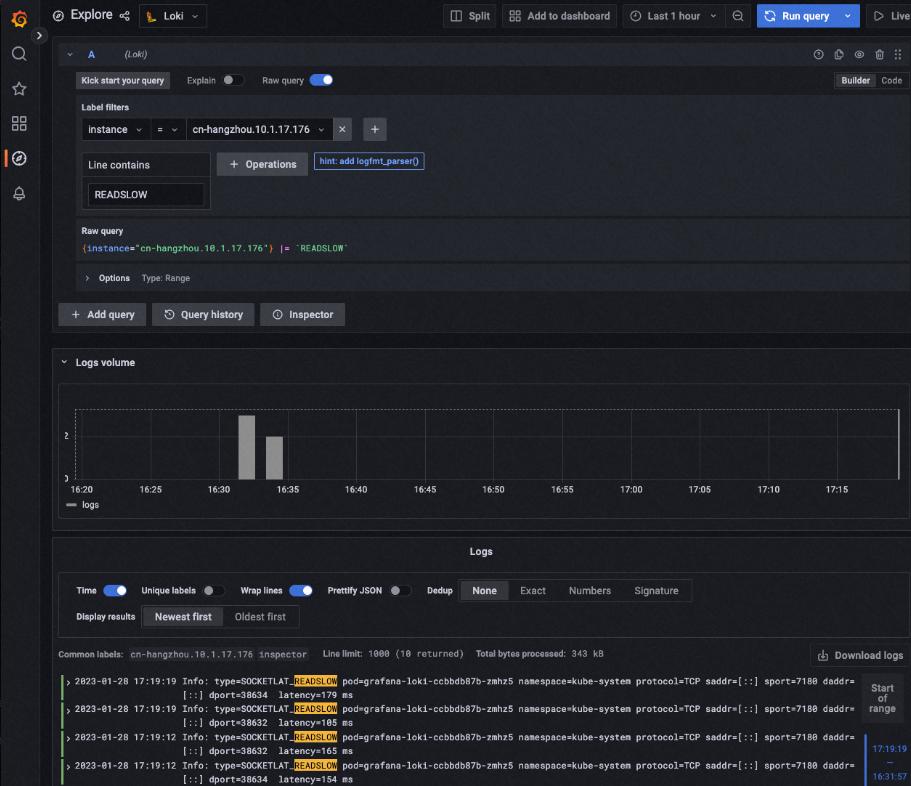
在左側導航欄單擊Explore,在頁面頂部設置數據源為Loki,查看輸出到Grafana Loki的事件信息。
您可以在Label filters下拉框中選擇過濾某個Node的事件,也可以在Line containers中輸入事件相關的信息來查看具體的事件。
您可以單擊頁面頂部的Add to dashboard,將配置好的事件Panel添加到大盤中。
ACK Net Exporter提供的事件根據事件的類型攜帶了不同的信息,單擊事件的詳情后,可以查看到詳細的事件發生時的信息。
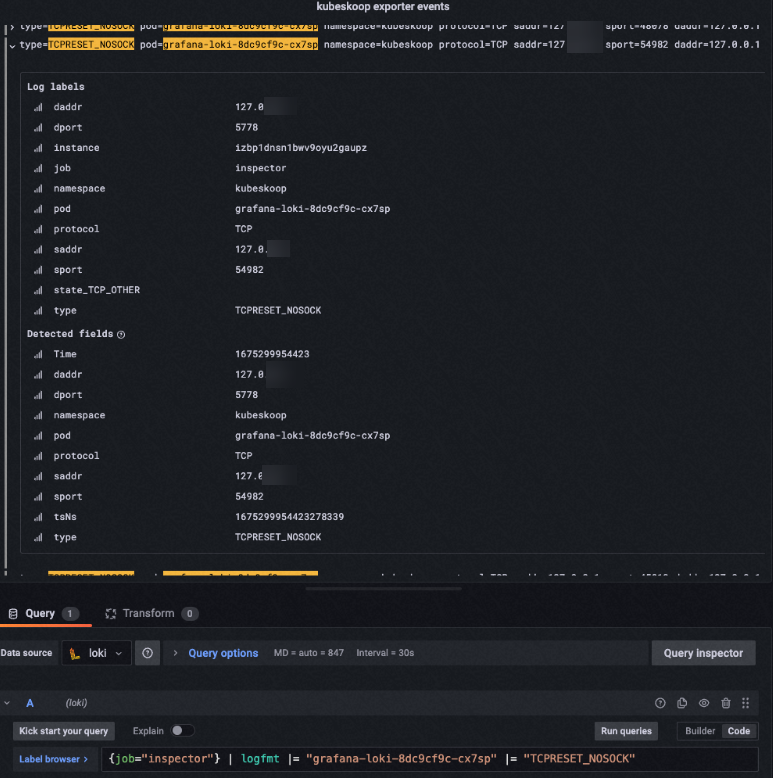
Grafana Loki服務支持通過LogQL語法查詢信息,詳細介紹,請參見LogQL。
場景四:使用ACK Net Exporter Cli工具收集監控事件
ACK Net Exporter Cli(以下簡稱inspector-cli)是ACK容器網絡團隊基于ACK Net Exporter既有的能力,提供場景化的問題排查輔助分析,獲取即時內核異常事件日志的工具,針對云原生場景設計,幫助用戶快速定位常見問題的深層次原因。
您可以通過在本地啟動容器的方式運行inspector-cli。
# 啟動臨時容器用于使用incpector-cli,您可以更換鏡像的版本來使用更新版本的特性。
docker run -it --name=inspector-cli --network=host registry.cn-hangzhou.aliyuncs.com/acs/inspector:v0.0.1-12-gff0558c-aliyun
which inspector
# /bin/inspector 是inspector-cli的執行路徑,您可以直接在容器中使用inspector-cli。例如,您可以通過以下方式使用inspector-cli獲取到某個節點的ACK Net Exporter捕獲的事件。
# 通過‘-e’指定需要獲取事件的遠端ACK Net Exporter事件服務地址。
inspector watch -e 10.1.16.255
# 以下為結果示例。
INFO TCP_RCV_RST_ESTAB Namespace=kube-system Pod=kube-proxy-worker-tbv5s Node=iZbp1jesgumdx66l8ym8j8Z Netns=4026531993 10.1.16.255:43186 -> 100.100.27.15:3128
...您也可以選擇登錄到ACK Net Exporter的inspector容器中排查問題。
# 執行命令時,需要將-n參數指定為net-exporter安裝的命名空間,同時執行需要登入的節點上的net-exporter實例。
kubectl exec -it -n kube-system -c inspector net-exporter-2rvfh -- sh
# 通過以下命令可以查看到當前節點上的網絡數據面分布情況。
inspector list entity
# 通過以下命令可以監聽本地的網絡異常事件日志及其信息。
inspector watch -d -v
#{"time":"2023-02-03T09:01:03.402118044Z","level":"INFO","source":"/go/src/net-exporter/cmd/watch.go:63","msg":"TCPRESET_PROCESS","meta":"hostNetwork/hostNetwork node=izbp1dnsn1bwv9oyu2gaupz netns=ns0 ","event":"protocol=TCP saddr=10.1.17.113 sport=6443 daddr=10.1.17.113 dport=44226 state:TCP_OTHER "}
# 通過指定多個遠端的ACK Net Exporter實例,也可以觀察到不同節點上發生的時間。
inspector watch -s 10.1.17.113 -s 10.1.18.14 -d -v
如何使用ACK Net Exporter定位容器網絡常見偶發疑難問題
以下內容提供了針對部分云原生典型問題的排查指南,結合ACK Net Exporter,幫助您快速獲取與問題有關的信息。
DNS超時相關問題
在云原生環境中,DNS服務超時問題會導致服務的訪問失敗,出現DNS訪問超時的常見原因有:
DNS服務響應的速度較慢,無法在用戶程序的超時時間到達前完成一次DNS查詢。
由于發送端的問題,沒有順利或者及時發送DNS Query報文。
服務端及時響應了報文,但是由于發送端本身的內存不足等問題出現了丟包。
您可以借助以下幾個指標來幫助排查偶發的DNS超時問題:
指標名稱 | 說明 |
inspector_pod_udpsndbuferrors | UDP協議通過網絡層方法發送時出現報錯的次數 |
inspector_pod_udpincsumerrors | UDP接收報文時出現CSUM校驗錯誤的次數 |
inspector_pod_udpnoports | 網絡層調用 |
inspector_pod_udpinerrors | UDP接收報文時出現錯誤的次數 |
inspector_pod_udpoutdatagrams | UDP協議通過網絡層方法成功發送報文的數量 |
inspector_pod_udprcvbuferrors | UDP在將應用層協議數據拷貝到Socket接收隊列時由于隊列不足導致的報錯次數 |
由于云原生環境中很多服務依賴于CoreDNS提供域名解析服務,在出現DNS問題時,如果出現問題的DNS請求與CoreDNS有關,您需要同時觀察CoreDNS相關Pod的上述指標的異常情況。
Nginx Ingress 499/502/503/504相關問題
云原生環境下,Ingress網關或者其他擔任Proxy/Broker作用的代理服務出現偶發的異常是較為常見的疑難問題,對于Nginx Ingress及以Nginx為底座的其他代理服務中,499/502/503/504問題是最為常見的四類,他們各自表征的含義如下:
499,當請求Nginx的客戶端在Nginx沒有進行回復的時候就關閉了TCP連接,常見原因包括:客戶端連接建立之后,發送請求較晚,導致Nginx回復過程中就達到了Client Timeout,常見于Android客戶端的異步請求框架中。
服務端在連接建立后,連接的處理較慢,需要深入排查。
服務端在向上游Upstream的后端發起請求時,后端處理較慢。
502,場景很多,多見于Nginx與Upstream后端之間連接層面的問題,例如連接建立失敗,或者后端異常的關閉,常見原因包括:后端配置的DNS域名解析失敗,通常在使用Kubernetes Service作為后端時會出現。
與Upstream之間建立連接失敗。
Upstream的請求或者響應過大,無法分配到內存等干擾正常業務交互的現象。
503,在Nginx中,用于提示客戶端,所有的Upstream均出現了不可用的情況,在云原生場景下,有一些特定的含義,常見原因包括:沒有可用的后端,這種情況通常出現較少。
流量過大,被Ingress的Limit Req所限制。
504,用于表征Nginx與Upstream相關的業務報文出現超時的問題,常見原因為Upstream返回的業務報文沒有及時到達。
在遇到上述幾類問題時,您需要先收集一些通用的信息用于界定問題發生的可能范圍與下一步排查方向:
Nginx提供的access_log信息,尤其是
request_time、upstream_connect_time與upstrem_response_time。Nginx提供的error_log信息,在問題發生時是否有異常的報錯信息出現。
如果配置了Liveness或者Readness健康檢查,可查看健康檢查。
在上述信息的基礎上,您需要按照問題的具體現象關注以下指標的變化,在可能出現連接失敗時:
指標名稱 | 說明 |
inspector_pod_tcpextlistenoverflows | 當LISTEN狀態的Sock接受連接時出現半連接隊列溢出時會計數 |
inspector_pod_tcpextlistendrops | 當LISTEN狀態的Sock創建SYN_RECV狀態的Sock失敗時會計數 |
inspector_pod_netdevtxdropped | 網卡發送錯誤并產生丟棄的次數 |
inspector_pod_netdevrxdropped | 網卡接收錯誤并產生丟棄的次數 |
inspector_pod_tcpactiveopens | 單個Pod內TCP成功發起SYN初次握手的次數,不包括SYN的重傳,但是連接建立失敗也會導致這個指標上升 |
inspector_pod_tcppassiveopens | 單個Pod內TCP完成握手并成功分配Sock的累積值,通常可以理解為成功新建連接的數量 |
inspector_pod_tcpretranssegs | 單個Pod內重傳的總報文數,這里已經跟據TSO進行了提前的分片計算 |
inspector_pod_tcpestabresets | 單個Pod內異常關閉TCP連接的次數,這里僅僅從結果層面統計 |
inspector_pod_tcpoutrsts | 單個Pod內TCP發送的Reset報文次數 |
inspector_pod_conntrackinvalid | 在CT創建過程中由于各種原因無法建立,但是報文并未被丟棄的次數 |
inspector_pod_conntrackdrop | 由于CT創建過程中無法建立而丟棄報文的次數 |
針對出現了類似Nginx響應慢的情況時,例如雖然出現了超時,但是Nginx的request_time很短的情況,您可以關注以下指標的變化:
指標名稱 | 說明 |
inspector_pod_tcpsummarytcpestablishedconn | 當前存在的ESTABLISHED狀態的TCP連接數量 |
inspector_pod_tcpsummarytcptimewaitconn | 當前存在的TIMEWAIT狀態的TCP連接數量 |
inspector_pod_tcpsummarytcptxqueue | 當前處ESTABLISHED狀態的TCP連接的發送隊列中存在的數據包的Bytes總數 |
inspector_pod_tcpsummarytcprxqueue | 當前處ESTABLISHED狀態的TCP連接的接收隊列中存在的數據包的Bytes總數 |
inspector_pod_tcpexttcpretransfail | 重傳報文返回除了EBUSY之外的報錯時計數,說明重傳無法正常完成 |
在上述指標信息的基礎上,根據指標在對應問題時間點的變化,可以縮小排查的范圍,如果憑借指標無法定位到問題,您可以提交工單,在發起工單時提供上述的信息,來幫助客服同學快速了解情況,避免無效溝通。
TCP Reset報文相關問題
TCP Reset報文是TCP協議中用于對非預期情況做響應的動作,通常會對用戶程序造成以下的影響:
connection reset by peer報錯,通常出現在nginx等C lib依賴的業務中。Broken pipe報錯,通常出現在Java或Python等封裝TCP連接的業務中。
云原生網絡環境中,出現Reset報文的常見原因有很多,這一類現象的出現也很難快速排查,以下列舉了幾種常見的Reset報文成因:
服務端的異常,導致無法正常提供服務,例如配置的TCP使用的內存不足等原因,這一類情況通常會主動發送Reset。
在使用Service或負載均衡時,由于endpoint或者Conntrack等有狀態的機制出現異常而轉發到了非預期的后端。
安全原因導致的連接釋放。
在NAT環境,高并發等場景下出現防止回繞序號(Protection Against Wrapped Sequence Numbers,以下簡稱PAWS)或者序號回繞現象。
使用TCP Keepalive進行連接保持,但是長時間沒有進行正常業務通信的情況。
為了快速區分以上不同的根因,您可以收集一些基本的信息指標:
梳理Reset報文產生時網絡的客戶端和服務端之間的拓撲結構。
關注以下指標的變化:
指標名稱
說明
inspector_pod_tcpexttcpabortontimeout
由于keepalive/window probe/重傳的調用超過上限發送Reset時會更新此計數
inspector_pod_tcpexttcpabortonlinger
TCP的Linger2選項開啟后,快速回收處于FIN_WAIT2的連接時發送Reset的次數
inspector_pod_tcpexttcpabortonclose
狀態機之外的原因關閉TCP連接時,仍有數據沒有讀取而發送Reset報文,則會進行指標計數
inspector_pod_tcpexttcpabortonmemory
在需要分配tw_sock/tcp_sock等邏輯中有由于tcp_check_oom出發內存不足而發送Reset結束連接的次數
inspector_pod_tcpexttcpabortondata*
由于Linger/Linger2選項開啟而通過Reset進行連接的快速回收時發送Reset的計數
inspector_pod_tcpexttcpackskippedsynrecv
在SYN_RECV狀態的Sock不回復ACK的次數
inspector_pod_tcpexttcpackskippedpaws
由于PAWS機制觸發校正,但是OOW限速限制了ACK報文發送的次數
inspector_pod_tcpestabresets
單個Pod內異常關閉TCP連接的次數,這里僅僅從結果層面統計
inspector_pod_tcpoutrsts
單個Pod內TCP發送的Reset報文次數
如果Reset偶發的現象按照一定的頻率您可以參考上文打開ACK Net Exporter的監控事件功能,采集對應的事件信息:
事件
事件信息
TCP_SEND_RST
發送了TCP Reset報文,排除下方兩個常見場景,其余發送Reset報文均會出發此事件
TCP_SEND_RST_NOSock
由于本地沒有Sock而發送了TCP Reset報文
TCP_SEND_RST_ACTIVE
由于資源,用戶態關閉等原因主動發送了TCP Reset報文
TCP_RCV_RST_SYN
在握手階段收到了Reset報文
TCP_RCV_RST_ESTAB
在連接已建立狀態下收到Reset報文
TCP_RCV_RST_TW
在揮手階段收到了Reset報文
偶發網絡延遲抖動相關問題
網絡偶發延遲抖動類問題是云原生環境中最為常見和最難以定位的一類問題,成因的現象極多,同時出現延遲可能會導致上述的三種問題的產生,容器網絡場景下,節點內部出現的網絡延遲通常包含以下幾種原因:
出現某個RT調度器管理的實時進程執行時間過久,導致用戶業務進程或網絡內核線程出現排隊較長或者處理較慢的現象。
用戶進程本身出現了偶發外部調用耗時久的現象,如云盤響應慢,RDS的RTT偶發增加等常見原因,導致請求處理較慢。
節點本身配置問題導致節點內不同CPU/不同NUMA Node之間負載不均,高負載的系統出現卡頓。
內核的有狀態機制引發的延遲,如Conntrack的Confirm操作,大量Orphan Socket影響了正常的Socket查找等。
面對此類問題,盡管表現為網絡問題,其最終的原因通常是由于OS的其他原因導致,您可以關注以下指標來縮小排查的范圍:
指標名稱 | 說明 |
inspector_pod_netsoftirqshed | 從軟中斷發起到ksoftirqd進程開始執行之間的耗時分布 |
inspector_pod_netsoftirq | 從ksoftirqd開始執行軟中斷內容到執行完成進入offcpu狀態的耗時分布 |
inspector_pod_ioioreadsyscall | 進程進行文件系統讀操作,如read,pread的次數 |
inspector_pod_ioiowritesyscall | 進程進行文件系統寫操作,如write,pwrite的次數 |
inspector_pod_ioioreadbytes | 進程從文件系統,通常是塊設備中讀取的Bytes數量 |
inspector_pod_ioiowritebyres | 進程向文件系統進行寫入的Bytes數量 |
inspector_pod_virtsendcmdlat | 網卡操作虛擬化調用的耗時分布 |
inspector_pod_tcpexttcptimeouts | CA狀態并未進入recovery/loss/disorder時觸發,當SYN報文未得到回復時進行重傳會計數 |
inspector_pod_tcpsummarytcpestablishedconn | 當前存在的ESTABLISHED狀態的TCP連接數量 |
inspector_pod_tcpsummarytcptimewaitconn | 當前存在的TIMEWAIT狀態的TCP連接數量 |
inspector_pod_tcpsummarytcptxqueue | 當前處ESTABLISHED狀態的TCP連接的發送隊列中存在的數據包的Bytes總數 |
inspector_pod_tcpsummarytcprxqueue | 當前處ESTABLISHED狀態的TCP連接的接收隊列中存在的數據包的Bytes總數 |
inspector_pod_softnetprocessed | 單個Pod內所有CPU處理的從網卡放入CPU的Backlog的報文數量 |
inspector_pod_softnettimesqueeze | 單個Pod內所有CPU處理的單次收包沒有全部獲取或者出現超時的次數 |
客戶案例分析
以下為部分容器網絡客戶借助ACK Net Exporter進行疑難問題排查分析的案例,您可以比對現象進行參考。
案例一:某客戶偶發DNS Timeout問題
客戶現象
客戶A發起工單,現象為有偶發的DNS解析超時,用戶業務采用PHP,DNS服務為配置CoreDNS。
排查過程
根據客戶描述,與客戶溝通后獲取客戶監控中的DNS相關數據。
分析客戶報錯時間點內數據,發現以下問題。
報錯時間內
inspector_pod_udpnoports增加1,指標整體較小。inspector_pod_packetloss中出現了符號__udp4_lib_rcv的丟包加1,這個符號的丟包數變化較少。
客戶反饋配置的DNS地址為公網某服務商地址,結合監控信息,判斷客戶報錯根因為DNS請求返回較慢,用戶態超時返回后,DNS回包到達。
案例二:某客戶Java應用偶發連接失敗問題
客戶現象
客戶B發起工單,現象為出現偶發的Tomcat不可用,每次出現持續時間約為5~10s。
排查過程
經過日志分析,確認現象發生時,客戶的Java Runtime正在進行GC操作。
ACK Net Exporter監控部署后發現客戶在問題的時間點
inspector_pod_tcpextlistendrops指標有明顯的上升。經過分析后得出結論,客戶的Java Runtime進行GC操作時,處理請求的速度變慢,導致請求的釋放變慢,但是請求的新建并沒有被限制,因此產生了大量的鏈接,將Listen Socket的Backlog打滿后產生溢出,導致
inspector_pod_tcpextlistendrops上升。此問題中,客戶的連接堆積持續時間短,且本身處理能力沒有問題,因此建議客戶調整Tomcat相關參數后,解決了客戶問題。
案例三:某客戶偶發網絡延遲抖動問題
客戶現象
客戶C發起工單,現象為客戶應用于Redis之間的請求出現了偶發的RTT增高導致業務超時,但是無法復現。
排查過程
經過日志分析,客戶出現了偶發的Redis請求超過300ms的總響應時間的情況。
ACK Net Exporter部署后,從監控中發現了
inspector_node_virtsendcmdlat指標在問題發生時有增長,增長的le(Prometheus監控中的Level)為18與15。經過換算得知此時出現過兩次延遲較高的虛擬化調用,其中le為15的產生了36ms以上的延遲,而le為18的產生了200ms以上的延遲。由于內核的虛擬化調用執行時會占據CPU,無法被搶占,因此客戶的偶發延遲是由于Pod的批量增刪過程中有一些虛擬化調用執行過久導致。
案例四:某客戶Ingress Nginx偶發健康檢查失敗問題
客戶現象
客戶D發起工單,現象為客戶的Ingress機器有偶發的健康檢查失敗并伴隨著業務請求失敗的問題。
排查過程
ACK Net Exporter部署監控后發現客戶出現問題是多個指標有異常的變化。
inspector_pod_tcpsummarytcprxqueue與inspector_pod_tcpsummarytcptxqueue均出現了上升。inspector_pod_tcpexttcptimeouts出現了上升。inspector_pod_tcpsummarytcptimewaitconn下降,inspector_pod_tcpsummarytcpestablishedconn上升。
經過分析后確認在問題發生的時間點,內核工作正常,連接的建立正常,但是用戶進程的運行出現了異常,包括處理收取Socket中的報文以及實際執行報文的發送操作,推測此時用戶進程存在調度問題或者限制問題。
建議用戶查看Cgroup的監控后發現客戶在問題時間點出現了CPU Throttled現象,證明此時出現了偶發的用戶進程由于Cgroup原因無法得到調度的現象。
按照文檔CPU Burst性能優化策略,為Ingress配置CPU Burst功能后,解決了這一類問題。
相關內容
ACK Net Exporter指標列表
在ACK Net Exporter更新過程中指標會有新增或變更,詳細信息請參考應用市場組件頁面的說明。除net_softirq/virtcmdlat等與Pod本身無關的邏輯外,所有的指標與事件均提供Pod粒度的詳細信息。
指標名稱 | 描述 | 探針名稱 |
inspector_pod_netdevrxbytes | 網卡設備接收的總字節數。 | netdev |
inspector_pod_netdevtxbytes | 網卡設備發送的總字節數。 | netdev |
inspector_pod_netdevtxerrors | 網卡設備出現發送錯誤的次數。 | netdev |
inspector_pod_netdevrxerrors | 網卡設備出現接受錯誤的次數。 | netdev |
inspector_pod_netdevtxdropped | 網卡發送錯誤并產生丟棄的次數。 | netdev |
inspector_pod_netdevrxdropped | 網卡接收錯誤并產生丟棄的次數。 | netdev |
inspector_pod_netdevtxpackets | 網卡發送成功的報文數。 | netdev |
inspector_pod_netdevrxpackets | 網卡接受成功的報文數。 | netdev |
inspector_pod_softnetprocessed | 單個Pod內所有CPU處理的從網卡放入CPU的backlog的報文數量。 | softnet |
inspector_pod_softnetdropped | 單個Pod內所有CPU處理的從網卡放入CPU的backlog失敗并丟棄報文數量。 | softnet |
inspector_pod_softnettimesqueeze | 單個Pod內所有CPU處理的單次收包沒有全部獲取或者出現超時的次數。 | softnet |
inspector_pod_tcpactiveopens | 單個Pod內TCP成功發起SYN初次握手的次數,不包括SYN的重傳,但是連接建立失敗也會導致這個指標上升。 | tcp |
inspector_pod_tcppassiveopens | 單個Pod內TCP完成握手并成功分配sock的累積值,通常可以理解為成功新建連接的數量。 | tcp |
inspector_pod_tcpretranssegs | 單個Pod內重傳的總報文數,這里已經跟據tso進行了提前的分片計算。 | tcp |
inspector_pod_tcpestabresets | 單個Pod內異常關閉TCP連接的次數,這里僅僅從結果層面統計。 | tcp |
inspector_pod_tcpoutrsts | 單個Pod內TCP發送的reset報文次數。 | tcp |
inspector_pod_tcpcurrestab | 單個Pod內TCP當前存在的活躍連接數。 | tcp |
inspector_pod_tcpexttcpabortontimeout | 由于keepalive/window probe/重傳的調用超過上限發送reset時會更新此計數。 | tcpext |
inspector_pod_tcpexttcpabortonlinger | tcp的linger2選項開啟后,快速回收處于FIN_WAIT2的連接時發送reset的次數。 | tcpext |
inspector_pod_tcpexttcpabortonclose | 狀態機之外的原因關閉TCP連接時,仍有數據沒有讀取而發送reset報文,則會進行指標計數。 | tcpext |
inspector_pod_tcpexttcpabortonmemory | 在需要分配tw_sock/tcp_sock等邏輯中有由于tcp_check_oom出發內存不足而發送reset結束連接的次數。 | tcpext |
inspector_pod_tcpexttcpabortondata* | 由于linger/linger2選項開啟而通過reset進行連接的快速回收時發送reset的計數。 | tcpext |
inspector_pod_tcpextlistenoverflows | 當LISTEN狀態的sock接受連接時出現半連接隊列溢出時會計數。 | tcpext |
inspector_pod_tcpextlistendrops | LISTEN狀態的sock創建SYN_RECV狀態的sock失敗時會計數。 | tcpext |
inspector_pod_tcpexttcpackskippedsynrecv | 在SYN_RECV狀態的sock不回復ACK的次數。 | tcpext |
inspector_pod_tcpexttcpackskippedpaws | 由于paws機制觸發校正,但是oow限速限制了ACK報文發送的次數。 | tcpext |
inspector_pod_tcpexttcpackskippedseq | 由于序號在窗口外觸發較正,但是被oow限速限制了ACK報文發送的次數。 | tcpext |
inspector_pod_tcpexttcpackskippedchallenge | 在需要發送challenge ack(通常用于確認reset報文)時被oow限速的次數。 | tcpext |
inspector_pod_tcpexttcpackskippedtimewait | 在fin_wait_2狀態下,對于oow報文發送ack,但是因為限速而忽略發送的次數。 | tcpext |
inspector_pod_tcpexttcpackskippedfinwait2 | 在fin_wait_2狀態下,對于oow報文發送ack,但是因為限速而忽略發送的次數。 | tcpext |
inspector_pod_tcpextpawsestabrejected* | TCP入方向的報文因為PAWS防回繞機制被丟棄的次數。 | tcpext |
inspector_pod_tcpexttcprcvqdrop | 當TCP的recv隊列出現堆積,并且無法正常分配到內存時,會進行這項計數。 | tcpext |
inspector_pod_tcpexttcpretransfail | 重傳報文返回除了EBUSY之外的報錯時計數,說明重傳無法正常完成。 | tcpext |
inspector_pod_tcpexttcpsynretrans | 重傳的SYN報文次數。 | tcpext |
inspector_pod_tcpexttcpfastretrans | CA狀態部位loss時進行的重傳均會進行計數。 | tcpext |
inspector_pod_tcpexttcptimeouts | CA狀態并未進入recovery/loss/disorder時觸發,當SYN報文未得到回復時進行重傳會計數。 | tcpext |
inspector_pod_tcpsummarytcpestablishedconn | 當前存在的ESTABLISHED狀態的TCP連接數量。 | tcpsummary |
inspector_pod_tcpsummarytcptimewaitconn | 當前存在的TIMEWAIT狀態的TCP連接數量。 | tcpsummary |
inspector_pod_tcpsummarytcptxqueue | 當前處ESTABLISHED狀態的TCP連接的發送隊列中存在的數據包的bytes總數。 | tcpsummary |
inspector_pod_tcpsummarytcprxqueue | 當前處ESTABLISHED狀態的TCP連接的接收隊列中存在的數據包的bytes總數。 | tcpsummary |
inspector_pod_udpindatagrams | UDP成功接收報文的數量。 | udp |
inspector_pod_udpsndbuferrors | UDP協議通過網絡層方法發送時出現報錯的次數。 | udp |
inspector_pod_udpincsumerrors | UDP接收報文時出現csum校驗錯誤的次數。 | udp |
inspector_pod_udpignoredmulti | UDP忽略的多播報文的數量。 | udp |
inspector_pod_udpnoports | 網絡層調用__udp4_lib_rcv收包時找不到對應端口的socket的次數。 | udp |
inspector_pod_udpinerrors | UDP接收報文時出現錯誤的次數。 | udp |
inspector_pod_udpoutdatagrams | UDP協議通過網絡層方法成功發送報文的數量。 | udp |
inspector_pod_udprcvbuferrors | UDP在將應用層協議數據拷貝到socket接收隊列時由于隊列不足導致的報錯次數。 | udp |
inspector_pod_conntrackentries* | 這個指標表征當前存在的entry的數量。 | conntrack |
inspector_pod_conntrackfound | 成功查找到ct記錄的次數。 | conntrack |
inspector_pod_conntrackinsert | 目前不會計數。 | conntrack |
inspector_pod_conntrackinvalid | 在ct創建過程中由于各種原因無法建立,但是報文并未被丟棄的次數。 | conntrack |
inspector_pod_conntrackignore | 由于ct已經建立或者協議不需要維護ct而跳過的次數。 | conntrack |
inspector_pod_conntrackinsertfailed | 目前不會計數。 | conntrack |
inspector_pod_conntrackdrop | 由于ct創建過程中無法建立而丟棄報文的次數。 | conntrack |
inspector_pod_conntrackearlydrop | 目前不會計數。 | conntrack |
inspector_pod_conntracksearchrestart | 查找ct過程中由于查找失敗而進行重試的次數。 | conntrack |
inspector_pod_fdopenfd | 單個Pod內所有進程的文件描述符數量之和。 | fd |
inspector_pod_fdopensocket | 單個Pod內socket類型的文件描述符之和。 | fd |
inspector_pod_slabtcpslabobjperslab | TCP slab中單個page所包含的object數量。 | slab |
inspector_pod_slabtcpslabpagesperslab | TCP slab中的總page數量。 | slab |
inspector_pod_slabtcpslabobjactive | TCP slab中活躍狀態的object數量。 | slab |
inspector_pod_slabtcpslabobjnum | TCP slab中的object數量。 | slab |
inspector_pod_slabtcpslabobjsize | TCP slab中的object的大小,不同的內核版本會有差異。 | slab |
inspector_pod_ioioreadsyscall | 進程進行文件系統讀操作,如read,pread的次數。 | io |
inspector_pod_ioiowritesyscall | 進程進行文件系統寫操作,如write,pwrite的次數。 | io |
inspector_pod_ioioreadbytes | 進程從文件系統,通常是塊設備中讀取的bytes數量。 | io |
inspector_pod_ioiowritebyres | 進程向文件系統進行寫入的bytes數量。 | io |
inspector_pod_net_softirq_schedslow100ms | 網絡軟中斷出發后等待調度的時間超過100ms的次數。 | net_softirq |
inspector_pod_net_softirq_excuteslow100ms | 網絡軟中段執行時間超過100ms的次數。 | net_softirq |
inspector_pod_abnormalloss(inspector_pod_packetloss_abnormal) | 內核丟棄報文,并且丟棄的報文是正常報文,即沒有出現報文完整性,校驗失敗等情況的次數。 | packetloss |
inspector_pod_totalloss(inspector_pod_packetloss_total) | 內核總丟包數量。 | packetloss |
inspector_pod_virtcmdlatency100ms | 網卡操作虛擬化消息通信執行超過100ms的次數。 | virtcmdlat |
inspector_pod_socketlatencyread100ms | 用戶程序操作讀取網絡socket文件中的內容,耗時超過100ms的情況統計。 | socketlatency |
inspector_pod_socketlatencywrite100ms | 用戶程序操作寫入網絡socket文件中后,超過100ms沒有產生網絡報文的情況統計。 | socketlatency |
kernellatency_rxslow100ms | 操作系統內核在接收網絡報文過程中耗時超過100ms的情況統計。 | kernellatency |
kernellatency_txslow100ms | 操作系統內核在發送網絡報文過程中耗時超過100ms的情況統計。 | kernellatency |
ACK Net Exporter事件詳解
ACK Net Exporter當前最新版本支持實時捕獲以下操作系統網絡相關的異常事件。
探針名稱 | 描述 |
netiftxlat | 探測網絡數據包發送時在tc qdisc等待延遲高的事件。 |
packetloss | 操作系統內核丟棄正常的網絡數據包的事件。 |
net_softirq | 操作系統軟中斷內核進程關于NET_RX/NET_TX中斷下半部的調度或執行延遲高的事件。 |
socketlatency | Pod中的進程進行socket相關的讀寫操作的耗時久的事件。 |
kernellatency | 內核在網絡層處理報文耗時久的事件。 |
virtcmdlatency | Virtio-net與宿主機通信耗時久的事件。 |
tcpreset | 接收或發出TCP協議中帶有RST標記的報文的事件。 |
tcptwrcv | TCP協議在TIMEWAIT狀態下收到了報文并處理的事件。 |
推薦使用的Grafana配置文件
如果您使用的是v8.4.0以上版本的Grafana,請單擊ACK Net Exporter-0.2.9.json鏈接獲取Grafana配置文件。
如果您使用的是v8.4.0及以下版本的Grafana,請單擊ACK Net Exporter-legacy.json鏈接獲取Grafana配置文件。