不同類型和版本的ACK集群默認安裝不同版本的NVIDIA驅動。如果您使用的CUDA庫需要匹配更高版本的NVIDIA驅動,需要自定義安裝節點的NVIDIA驅動。本文介紹如何基于節點池標簽通過OSS URL自定義GPU節點的NVIDIA驅動版本。
注意事項
對于GPU驅動版本與您業務應用的兼容性(GPU驅動版本與CDUA庫版本的兼容性),ACK不保證兩者之間兼容性,請您自行驗證。
對于已經安裝GPU驅動、NVIDIA Container Runtime等GPU組件的自定義操作系統鏡像,ACK無法保證其提供的GPU驅動與ACK其他GPU組件兼容(例如監控組件等),請您自行驗證。
通過節點池標簽指定節點池中GPU節點的驅動版本時,由于安裝驅動的過程是在添加節點時被觸發,因此僅對新擴容或新添加的節點有效,對節點池中已經存在的節點無效。如果希望對已有節點有效,需要將該節點從節點池移除,再加入原節點池。具體操作,請參見移除節點和添加已有節點。
如果您上傳自己的GPU驅動到OSS中,使用自定義的GPU節點驅動方式,可能引發GPU驅動與操作系統版本、ECS實例類型、Container Runtime等不兼容,繼而導致添加GPU節點失敗。ACK無法保證節點添加的成功率,請您自行驗證。
機型ecs.gn7.xxxxx和ecs.ebmgn7.xxxx對510.xxx和515.xxx版本驅動存在兼容性問題,建議使用關閉GSP的510以下的驅動版本(例如:470.xxx.x1PINSGHEN xxx)或525.125.06及其以上的驅動版本。
NVIDIA各卡型(P100、T4、V100、A10等)對驅動版本的更詳細的要求,請參見NVIDIA官方文檔。
步驟一:下載目標驅動
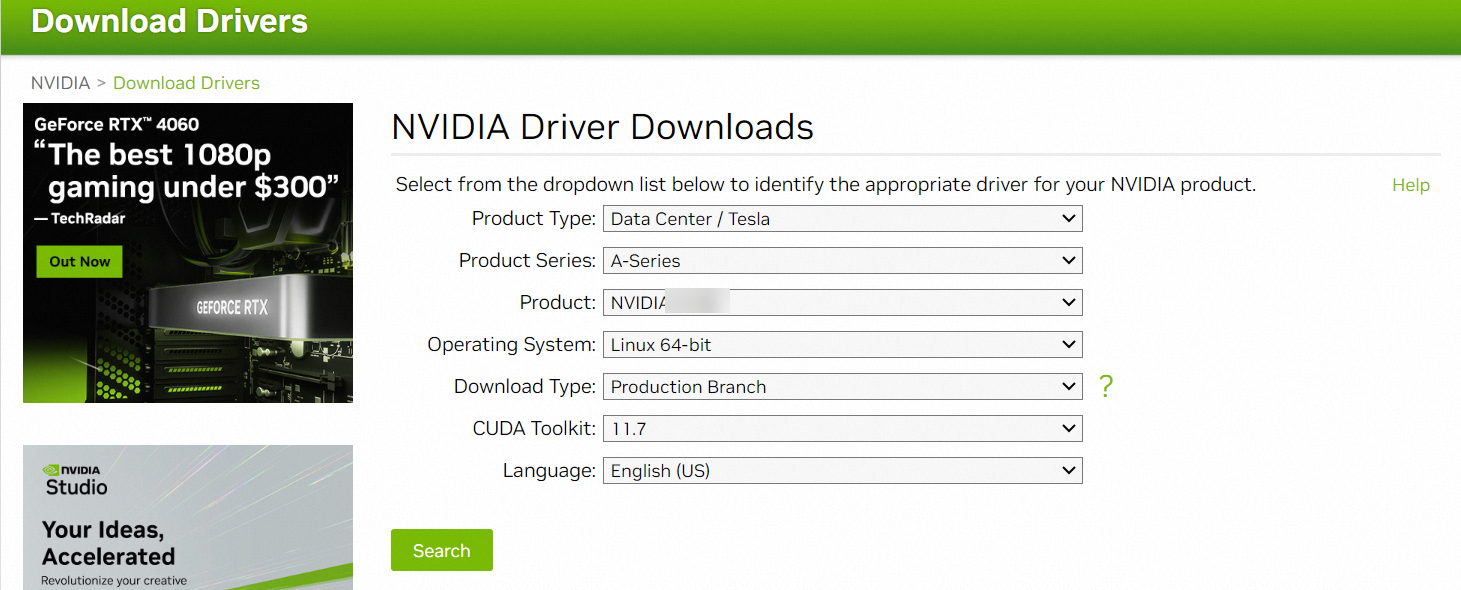
如果ACK支持的NVIDIA驅動版本列表未包含您的業務所需的驅動版本,您可以從NVIDIA官方網站下載目標驅動版本,本文以驅動版本515.86.01為例進行介紹。如下圖所示,單擊Search跳轉至下載頁面,將驅動文件NVIDIA-Linux-x86_64-515.86.01.run下載到本地。
步驟二:下載nvidia fabric manager
從NVIDIA YUM官方倉庫下載nvidia fabric manager,nvidia fabric manager的版本需和驅動版本一致。
wget https://developer.download.nvidia.cn/compute/cuda/repos/rhel7/x86_64/nvidia-fabric-manager-515.86.01-1.x86_64.rpm步驟三:創建OSS Bucket
登錄對象存儲OSS控制臺,創建OSS Bucket。具體操作,請參見創建存儲空間。
建議OSS Bucket所在地域與目標ACK集群所在地域相同,為ACK節點安裝GPU驅動時,可以通過內網OSS Bucket拉取驅動。
步驟四:上傳驅動和nvidia-fabric-manager文件到OSS Bucket
登錄對象存儲OSS控制臺,在左側導航欄,單擊Bucket列表,找到目標Bucket,上傳NVIDIA-Linux-x86_64-515.86.01.run和nvidia-fabric-manager-515.86.01-1.x86_64.rpm至目標Bucket的根目錄。
具體操作,請參見上傳文件。
重要請確保上傳文件至OSS Bucket的根目錄,不要上傳至子目錄。
在目標Bucket頁面的左側導航欄,單擊,單擊已上傳文件右側操作列的詳情,查看驅動文件的詳情。
在詳情面板,關閉使用 HTTPS開關,取消使用HTTPS的配置。
重要ACK創建集群時會通過URL拉取驅動文件,URL使用的協議為HTTP協議。但OSS默認使用HTTPS協議。因此,請關閉使用 HTTPS開關。
在目標Bucket詳情頁,單擊左側導航欄的概覽,在頁面下方獲取內網訪問地址。
重要公網域名拉取驅動文件速度較慢,容易造成集群添加GPU節點失敗,因此建議通過內網域名(帶有-internal字段)或加速域名(帶有oss-accelerate字段)拉取驅動文件。
步驟五:配置節點池標簽
登錄容器服務管理控制臺,在左側導航欄選擇集群。
在集群列表頁面,單擊目標集群名稱,然后在左側導航欄,選擇。
單擊右上角的創建節點池,然后在創建節點池對話框配置相關參數。
部分配置項說明如下。有關配置項的詳細說明,請參見創建Kubernetes托管版集群。
單擊顯示高級選項。
在節點標簽參數欄添加標簽,單擊
 圖標。
圖標。輸入第一個標簽的鍵為
ack.aliyun.com/nvidia-driver-oss-endpoint,值為步驟四獲取的OSS Bucket內網訪問地址,本文示例為my-nvidia-driver.oss-cn-beijing-internal.aliyuncs.com。輸入第二個標簽的鍵為
ack.aliyun.com/nvidia-driver-runfile,值為步驟一下載的NVIDIA驅動的名稱,本文示例為NVIDIA-Linux-x86_64-515.86.01.run。輸入第三個標簽的鍵為
ack.aliyun.com/nvidia-fabricmanager-rpm,值為步驟二下載的nvidia fabric manager的名稱,本文示例為nvidia-fabric-manager-515.86.01-1.x86_64.rpm。
參數配置完成后,單擊確認配置。
步驟六:驗證節點池自定義安裝NVIDIA驅動是否成功
登錄容器服務管理控制臺,在左側導航欄選擇集群。
在目標集群右側的操作列,選擇。
執行以下命令,查看帶有
component: nvidia-device-plugin標簽的Pod。kubectl get po -n kube-system -l component=nvidia-device-plugin -o wide預期輸出:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nvidia-device-plugin-cn-beijing.192.168.1.127 1/1 Running 0 6d 192.168.1.127 cn-beijing.192.168.1.127 <none> <none> nvidia-device-plugin-cn-beijing.192.168.1.128 1/1 Running 0 17m 192.168.1.128 cn-beijing.192.168.1.128 <none> <none> nvidia-device-plugin-cn-beijing.192.168.8.12 1/1 Running 0 9d 192.168.8.12 cn-beijing.192.168.8.12 <none> <none> nvidia-device-plugin-cn-beijing.192.168.8.13 1/1 Running 0 9d 192.168.8.13 cn-beijing.192.168.8.13 <none> <none> nvidia-device-plugin-cn-beijing.192.168.8.14 1/1 Running 0 9d預期輸出表示,NODE列的集群中剛添加的節點對應的Pod名稱為
nvidia-device-plugin-cn-beijing.192.168.1.128。執行以下命令查看節點的驅動版本是否符合預期。
kubectl exec -ti nvidia-device-plugin-cn-beijing.192.168.1.128 -n kube-system -- nvidia-smi預期輸出:
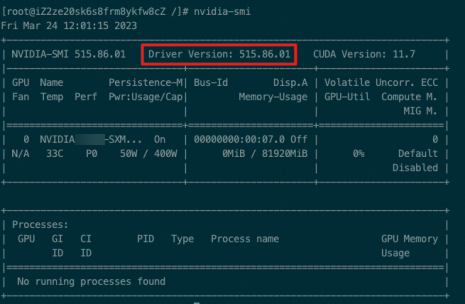
預期輸出表明,驅動版本為515.86.01,即通過節點池自定義安裝NVIDIA驅動成功。
其他方式
使用OpenAPI方式創建或者擴容集群時,可在目標節點池的配置中設置自定義驅動的OSS URL。示例代碼如下:
{
// 其他部分省略
......
"tags": [
{
"key": "ack.aliyun.com/nvidia-driver-oss-endpoint",
"value": "xxxx"
},
{
"key": "ack.aliyun.com/nvidia-driver-runfile",
"value": "xxxx"
},
{
"key": "ack.aliyun.com/nvidia-fabricmanager-rpm",
"value": "xxxx"
}
],
// 其他部分省略
......
}