Lindorm Ganos時空服務提供了豐富的函數和數據類型,方便您對時空數據進行計算和分析。您可以通過Ganos時空服務預先設定地理圍欄,并根據業務需求靈活使用時空函數,結合Lindorm流引擎的實時計算能力,實現基于地理圍欄的實時區域統計功能。
背景信息
在很多基于時空位置的場景中,都有根據地理區域范圍進行聚合查詢的需求,進而形成熱力圖進行展示,例如:
在互聯網出行場景中,需要統計每個行政區(或網格)的車輛分布情況,為平衡運力調度提供依據。
在LBS客戶運營場景中,需要統計每個區域內(AOI)的客戶流量,以此來制定優惠券的發放規則。
在車聯網場景中,需要統計車輛在某個區域內的聚集情況,可用于大屏密度圖展示。
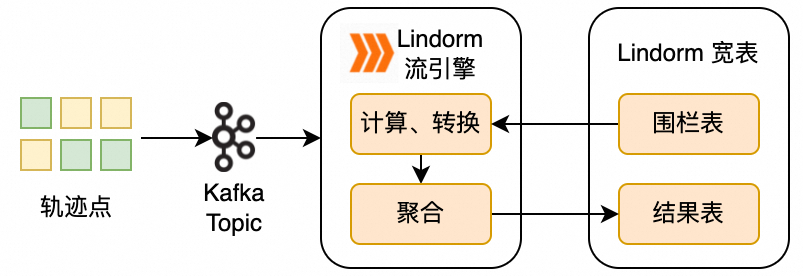
技術實現
區域統計涉及以下兩種數據:
地理圍欄:邊界是一個閉合的環且不會頻繁變更,可以使用Polygon類型將數據保存在Lindorm寬表中。
車輛位置:車輛位置信息是實時上傳的流數據,可以實時保存在Kafka Topic中。
Lindorm流引擎將讀取Kafka Topic中的實時數據,基于地理圍欄進行實時計算,并將計算結果保存在Lindorm寬表中。
前提條件
已將客戶端IP地址添加至Lindorm白名單。如何添加,請參見設置白名單。
已開通Lindorm Ganos時空服務。如何開通,請參見開通時空服務(免費)。
已開通Lindorm流引擎。如何開通,請參見開通流引擎。
注意事項
如果應用部署在ECS實例,通過專有網絡訪問Lindorm實例前,需要確保Lindorm實例和ECS實例滿足以下條件,以保證網絡的連通性。
所在地域相同,并建議所在可用區相同(以減少網絡延時)。
ECS實例與Lindorm實例屬于同一專有網絡。
步驟一:創建地理圍欄表和結果表
在寬表引擎中創建地理圍欄表和結果表,分別用于保存地理圍欄數據和計算結果。
創建地理圍欄表并插入示例數據。
創建地理圍欄表regions。
CREATE TABLE regions(rID INT, rName VARCHAR, fence GEOMETRY, PRIMARY KEY(rID));插入地理圍欄數據,包括3個區域,分別命名為SoHo、Chinatown和Tribeca。
INSERT INTO regions(rID, rName, fence) VALUES (1, 'SoHo', ST_GeomFromText('POLYGON((-74.00279525078275 40.72833625216264,-74.00547745979765 40.721929158663244,-74.00125029839018 40.71893680218994,-73.9957785919998 40.72521409075776,-73.9972377137039 40.72557184584898,-74.00279525078275 40.72833625216264))')), (2, 'Chinatown', ST_GeomFromText('POLYGON((-73.99712367114876 40.71281582267133,-73.9901070123658 40.71336881907936,-73.99023575839851 40.71452359088633,-73.98976368961189 40.71554823078944,-73.99551434573982 40.717337246783735,-73.99480624255989 40.718491949759304,-73.99652285632942 40.719109951574,-73.99776740131233 40.7168005470334,-73.99903340396736 40.71727219249899,-74.00193018970344 40.71938642421256,-74.00409741458748 40.71688186545551,-74.00051398334358 40.71517415773184,-74.0004281526551 40.714377212470005,-73.99849696216438 40.713450141693166,-73.99748845157478 40.71405192594819,-73.99712367114876 40.71281582267133))')), (3, 'Tribeca', ST_GeomFromText('POLYGON((-74.01091641815208 40.72583120006787,-74.01338405044578 40.71436586362705,-74.01370591552757 40.713617702123415,-74.00862044723533 40.711308107057235,-74.00194711120628 40.7194238654018,-74.01091641815208 40.72583120006787))'));
創建結果表cresult。
CREATE TABLE cresult(rName VARCHAR, ws TIMESTAMP, we TIMESTAMP, carCount BIGINT, PRIMARY KEY(rName,ws));
步驟二:寫入流數據
Lindorm流引擎完全兼容開源Kafka API,您可以通過Kafka開源客戶端或腳本工具連接Lindorm流引擎并寫入測試數據。
以通過開源Kafka腳本工具寫入為例。
下載并安裝Kafka腳本工具。具體操作,請參見通過開源Kafka腳本工具連接Lindorm流引擎。
創建名為
logVehicleTs的Kafka Topic。bin/kafka-topics.sh --bootstrap-server <Lindorm Stream Kafka地址> --topic logVehicleTs --create其中,Lindorm Stream Kafka地址為流引擎的Kafka連接地址,僅支持通過專有網絡訪問。獲取方式,請參見查看流引擎連接地址。
將測試數據寫入Kafka Topic中,使用組合鍵Ctrl+C可終止寫入。
bin/kafka-console-producer.sh --bootstrap-server <Lindorm Stream Kafka地址> --topic logVehicleTs {"UID": "A", "x":"-74.00035", "y": "40.72432", "tripTime":"2020-01-01 08:00:00"} {"UID": "B", "x":"-74.00239", "y": "40.71692", "tripTime":"2020-01-01 08:00:30"} {"UID": "C", "x":"-74.00201", "y": "40.72563", "tripTime":"2020-01-01 08:01:00"} {"UID": "D", "x":"-74.00158", "y": "40.72412", "tripTime":"2020-01-01 08:01:30"} {"UID": "E", "x":"-73.99836", "y": "40.71588", "tripTime":"2020-01-01 08:02:00"} {"UID": "F", "x":"-74.01015", "y": "40.71422", "tripTime":"2020-01-01 08:02:30"} {"UID": "G", "x":"-73.99183", "y": "40.71451", "tripTime":"2020-01-01 08:03:00"} {"UID": "H", "x":"-73.99595", "y": "40.71773", "tripTime":"2020-01-01 08:03:30"}您可以使用
bin/kafka-console-consumer.sh --bootstrap-server <Lindorm Stream Kafka地址> --topic logVehicleTs --from-beginning命令,查看數據是否成功寫入。
步驟三:提交流引擎計算任務
使用Flink SQL提交Lindorm流引擎計算任務,讀取Kafka Topic中的數據,并結合地理圍欄數據進行計算。
連接Lindorm流引擎。如何連接,請參見步驟二:安裝流引擎客戶端。
提交計算任務。
計算任務構造了一個大小為10分鐘的滾動窗口,并每10分鐘統計一次窗口內的數據,具體步驟如下:
加載
ganos函數模塊。在Flink Job中創建三張表:數據源表logCarWithTs、數據維表regions、數據結果表cresult,通過設置連接器參數,分別關聯已創建的Kafka Topic、地理圍欄表regions和結果表cresult。
創建流任務,通過統計函數
count、關系函數ST_Contains和時間窗口函數TUMBLE對數據進行過濾,并將計算結果寫入結果表cresult。
示例代碼如下:
CREATE FJOB fenceWs ( LOAD MODULE ganos; CREATE TABLE logCarWithTs( `uID` STRING, `x` DOUBLE, `y` DOUBLE, `tripTime` TIMESTAMP(0), WATERMARK for `tripTime` AS `tripTime`-INTERVAL '1' MINUTES ) WITH ('connector'='kafka', 'topic'='logVehicleTs', 'scan.startup.mode'='earliest-offset', 'properties.bootstrap.servers'='<Lindorm Stream Kafka地址>', 'format'='json'); -- create area table CREATE TABLE regions( `rID` INT, `rName` STRING, `fence` GEOMETRY, PRIMARY KEY (`rID`) NOT ENFORCED ) WITH ('connector'='lindorm', 'seedServer'='<Lindorm寬表HBase Java API訪問地址>', 'userName'='root', 'password'='test_password', 'tableName'='regions', 'namespace'='default'); -- create result table CREATE TABLE cresult( `rName` STRING, `ws` TIMESTAMP(0), `we` TIMESTAMP(0), `carCount` BIGINT, PRIMARY KEY (`rName`, `ws`) NOT ENFORCED ) WITH ('connector'='lindorm', 'seedServer'='<Lindorm寬表HBase Java API訪問地址>', 'userName'='root', 'password'='test_password', 'tableName'='cresult', 'namespace'='default'); -- count cars in each area every 10 minutes INSERT INTO cresult SELECT regions.rName AS rName, window_start AS ws, window_end AS we, count(*) AS carCount FROM TABLE(TUMBLE(TABLE logCarWithTs, DESCRIPTOR(tripTime),INTERVAL '10' MINUTES)) JOIN regions ON ST_Contains(regions.fence,ST_MakePoint(x,y)) GROUP BY regions.rName,window_start, window_end; );其中,Lindorm寬表HBase Java API訪問地址的獲取方式,請參見查看寬表引擎連接地址。
說明計算任務中使用到的函數,請參見關系函數、Count函數和TUMBLE窗口函數。
步驟四:查看結果
執行以下語句,查看區域統計結果。
SELECT rName, carCount FROM cresult;返回結果:
+-----------+----------+ | rName | carCount | +-----------+----------+ | Chinatown | 3 | | SoHo | 4 | | Tribeca | 3 | +-----------+----------+carCount為各區域中車輛的數量。