關(guān)鍵詞感知檢索
本文主要介紹帶關(guān)鍵詞感知能力的向量檢索服務(wù)的優(yōu)勢(shì)、應(yīng)用示例以及Sparse Vector生成工具。
背景介紹
關(guān)鍵詞檢索及其局限
在信息檢索領(lǐng)域,“傳統(tǒng)”方式是通過(guò)關(guān)鍵詞進(jìn)行信息檢索,其大致過(guò)程為:
對(duì)原始語(yǔ)料(如網(wǎng)頁(yè))進(jìn)行關(guān)鍵詞抽取。
建立關(guān)鍵詞和原始語(yǔ)料的映射關(guān)系,常見(jiàn)的方法有倒排索引、TF-IDF、BM25等方法,其中TF-IDF、BM25通常用稀疏向量(Sparse Vector)來(lái)表示詞頻。
檢索時(shí),對(duì)檢索語(yǔ)句進(jìn)行關(guān)鍵詞抽取,并通過(guò)步驟2中建立的映射關(guān)系召回關(guān)聯(lián)度最高的TopK原始語(yǔ)料。
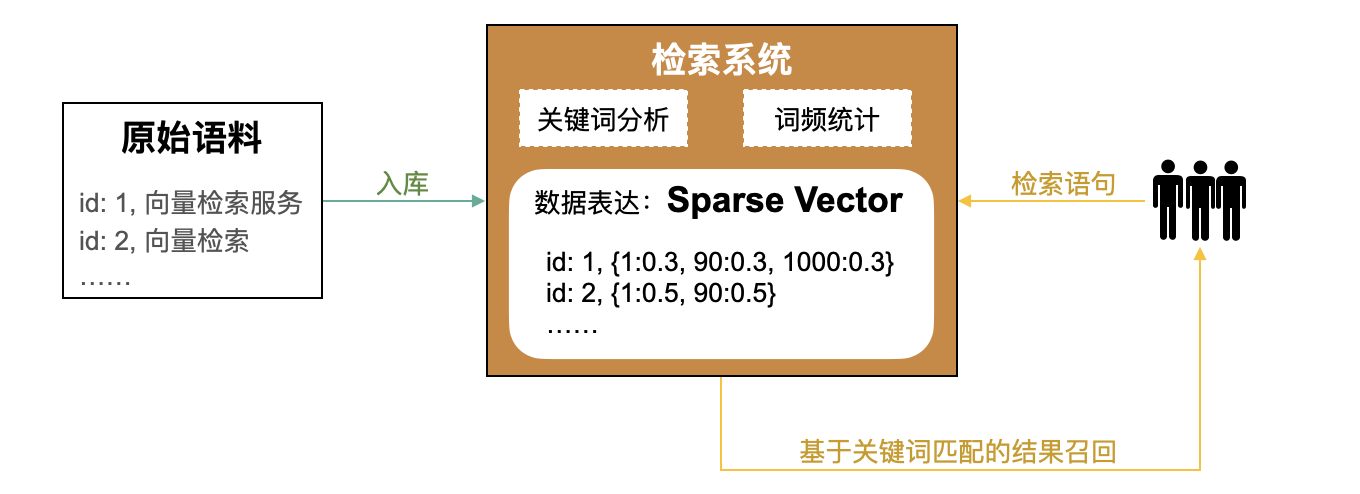
但關(guān)鍵詞檢索無(wú)法對(duì)語(yǔ)義進(jìn)行理解。例如,檢索語(yǔ)句為“浙一醫(yī)院”,經(jīng)過(guò)分詞后成為“浙一”和“醫(yī)院”,這兩個(gè)關(guān)鍵詞都無(wú)法有效的命中用戶預(yù)期中的“浙江大學(xué)醫(yī)學(xué)院附屬第一醫(yī)院”這個(gè)目標(biāo)。
基于語(yǔ)義的向量檢索
隨著人工智能技術(shù)日新月異的發(fā)展,語(yǔ)義理解Embedding模型能力的不斷增強(qiáng),基于語(yǔ)義Embedding的向量檢索召回關(guān)聯(lián)信息的方式逐漸成為主流。其大致過(guò)程如下:
原始語(yǔ)料(如網(wǎng)頁(yè))通過(guò)Embedding模型產(chǎn)生向量(Vector),又稱(chēng)為稠密向量(Dense Vector)。
向量入庫(kù)向量檢索系統(tǒng)。
檢索時(shí),檢索語(yǔ)句同樣通過(guò)Embedding模型產(chǎn)生向量,并用該向量在向量檢索系統(tǒng)中召回距離最近的TopK原始語(yǔ)料。
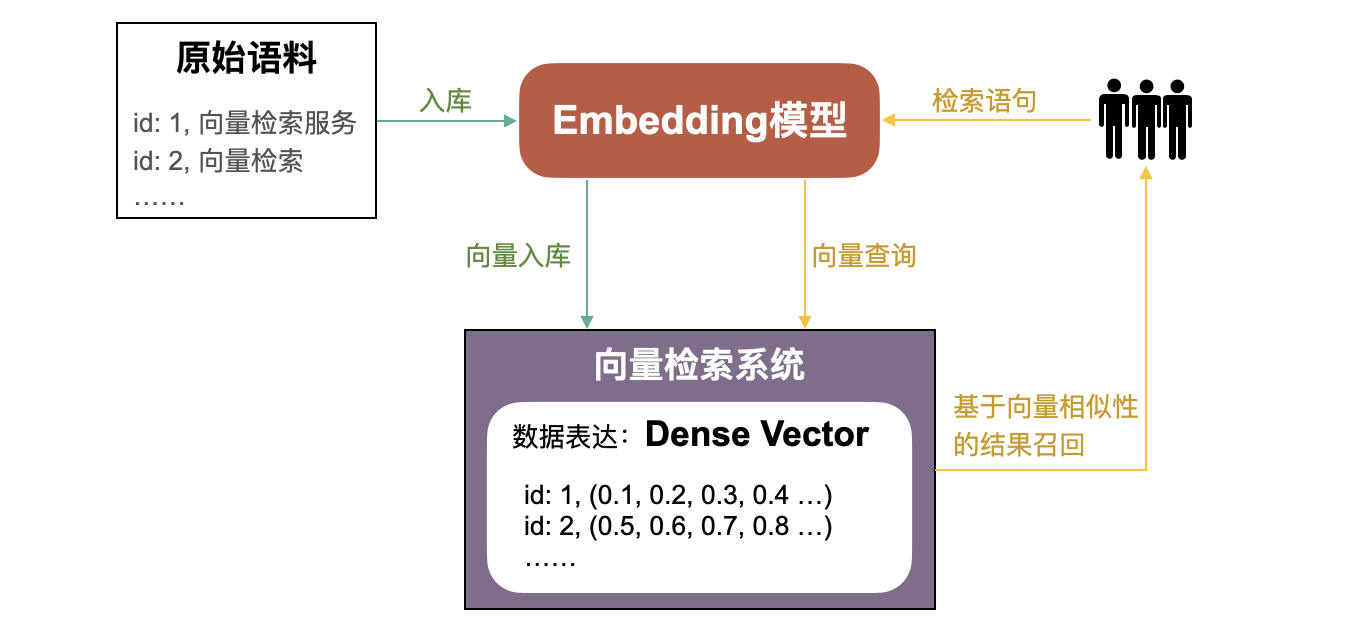
但不可否認(rèn)的是,基于語(yǔ)義的向量檢索來(lái)召回信息也存在局限——必須不斷的優(yōu)化Embedding模型對(duì)語(yǔ)義的理解能力,才能取得更好的效果。例如,若模型無(wú)法理解“水稻灌溉”和“灌溉水稻”在語(yǔ)義上比較接近,就會(huì)導(dǎo)致無(wú)法通過(guò)“水稻灌溉”召回“灌溉水稻”相關(guān)的語(yǔ)料。而關(guān)鍵字檢索在這個(gè)例子上,恰好可以發(fā)揮其優(yōu)勢(shì),通過(guò)“水稻”、“灌溉”關(guān)鍵字有效的召回相關(guān)語(yǔ)料。
關(guān)鍵詞檢索+語(yǔ)義檢索
針對(duì)上述問(wèn)題,逐漸有業(yè)務(wù)和系統(tǒng)演化出來(lái)“兩路召回、綜合排序”的方法來(lái)解決,并且在效果上也超過(guò)了單純的關(guān)鍵字檢索或語(yǔ)義檢索,如下圖所示: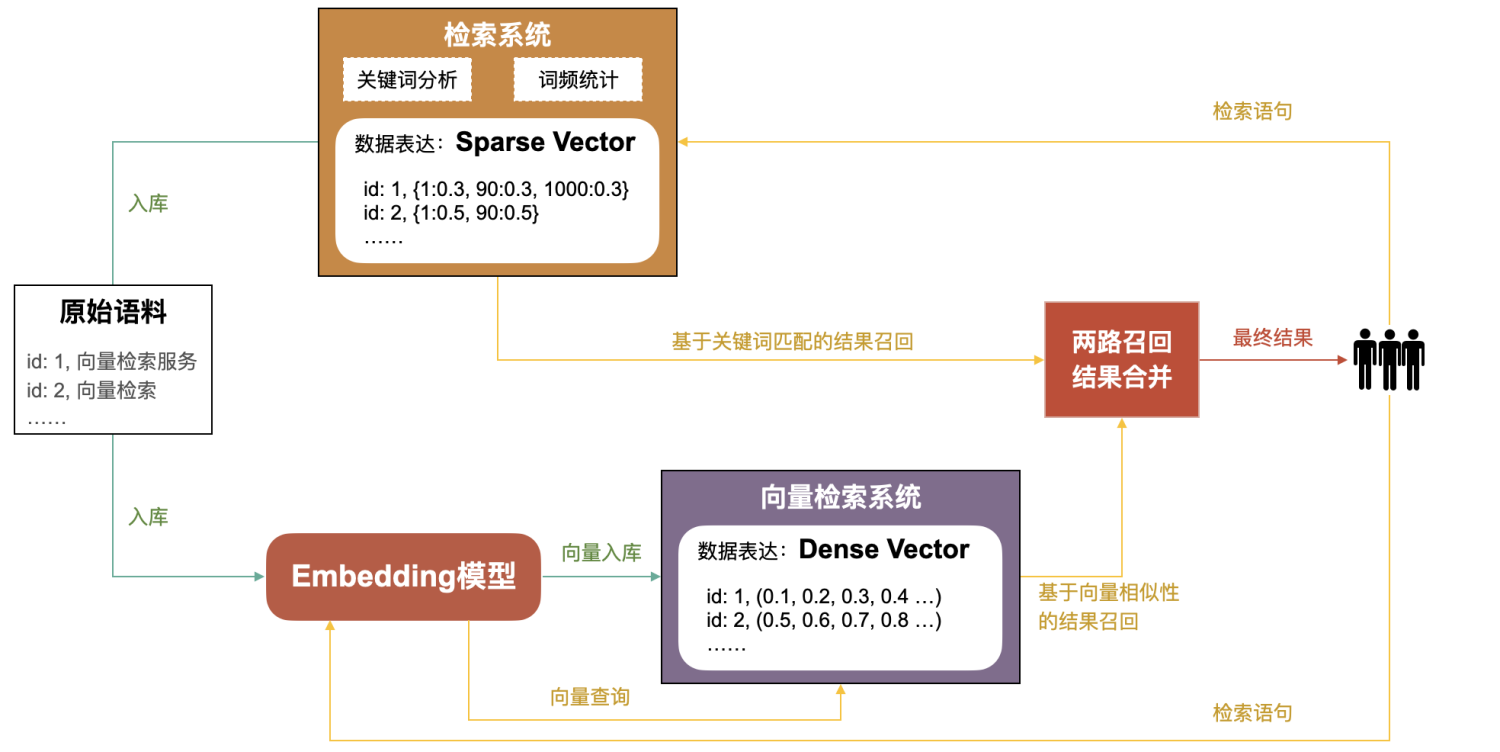
但這種方式的弊端也很明顯:
系統(tǒng)復(fù)雜度增加。
硬件資源(內(nèi)存、CPU、磁盤(pán)等)開(kāi)銷(xiāo)增加。
可維護(hù)性降低。
......
具有關(guān)鍵詞感知能力的語(yǔ)義檢索
向量檢索服務(wù)DashVector同時(shí)支持Dense Vector(稠密向量)和Sparse Vector(稀疏向量),前者用于模型的高維特征(Embedding)表達(dá),后者用于關(guān)鍵詞和詞頻信息表達(dá)。DashVector可以進(jìn)行關(guān)鍵詞感知的向量檢索,即Dense Vector和Sparse Vector結(jié)合的混合檢索。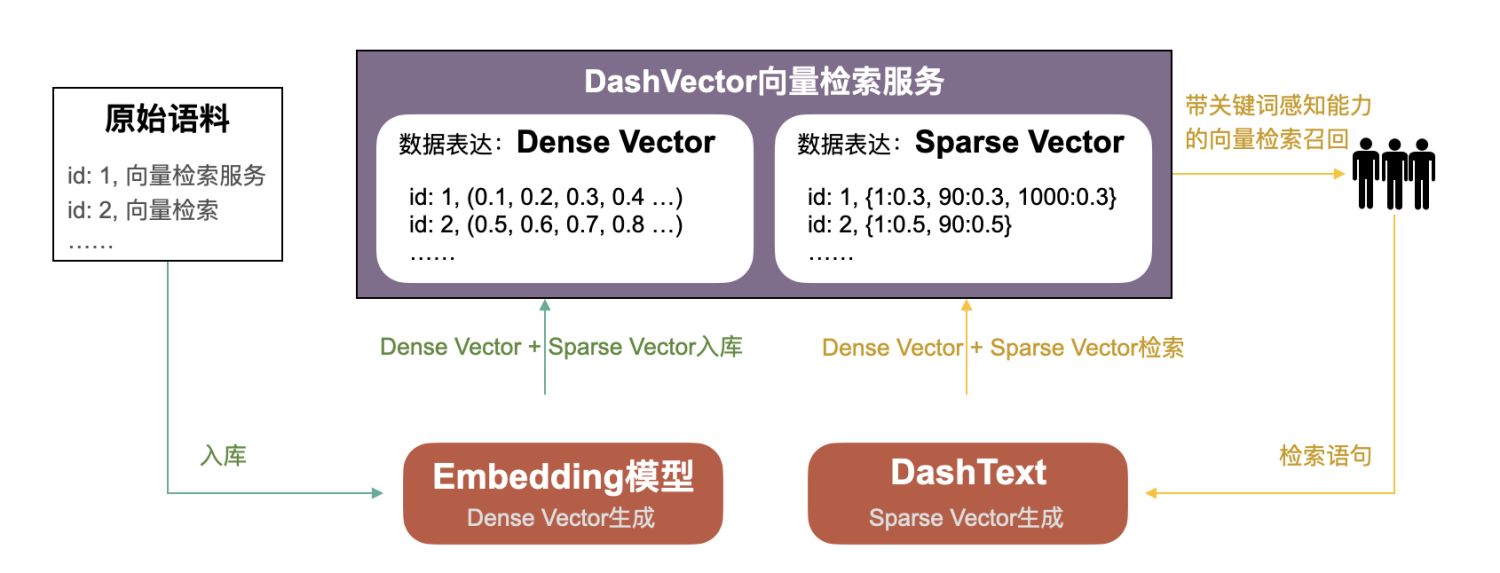
DashVector帶關(guān)鍵詞感知能力的向量檢索能力,既有“兩路召回、綜合排序”方案的優(yōu)點(diǎn),又沒(méi)有其缺點(diǎn)。使得系統(tǒng)復(fù)雜度、資源開(kāi)銷(xiāo)大幅度降低的同時(shí),還具備關(guān)鍵詞檢索、向量檢索、關(guān)鍵詞+向量混合檢索的優(yōu)勢(shì),可滿足絕大多數(shù)業(yè)務(wù)場(chǎng)景的需求。
Sparse Vector(稀疏向量),稀疏向量是指大部分元素為0,僅少量元素非0的向量。在DashVector中,稀疏向量可用來(lái)表示詞頻等信息。例如,{1:0.4, 10000:0.6, 222222:0.8}就是一個(gè)稀疏向量,其第1、10000、222222位元素(分別代表三個(gè)關(guān)鍵字)有非0值(代表關(guān)鍵字的權(quán)重),其他元素全部為0。
使用示例
前提條件
已創(chuàng)建Cluster:創(chuàng)建Cluster。
已獲得API-KEY:API-KEY管理。
已安裝最新版SDK:安裝DashVector SDK。
Step1. 創(chuàng)建支持Sparse Vector的Collection
需要使用您的api-key替換以下示例中的 YOUR_API_KEY、您的Cluster Endpoint替換示例中的YOUR_CLUSTER_ENDPOINT,代碼才能正常運(yùn)行。單擊Cluster詳情了解如何查看Cluster Endpoint。
本示例僅對(duì)Sparse Vector進(jìn)行功能演示,簡(jiǎn)化起見(jiàn),向量(Dense Vector)維度設(shè)置為4。
import dashvector
client = dashvector.Client(
api_key='YOUR_API_KEY',
endpoint='YOUR_CLUSTER_ENDPOINT'
)
ret = client.create('hybrid_collection', dimension=4, metric='dotproduct')
collection = client.get('hybrid_collection')
assert collection僅內(nèi)積度量(metric='dotproduct')支持Sparse Vector功能。
Step2. 插入帶有Sparse Vector的Doc
from dashvector import Doc
collection.insert(Doc(
id='A',
vector=[0.1, 0.2, 0.3, 0.4],
sparse_vector={1: 0.3, 10:0.4, 100:0.3}
))向量檢索服務(wù)DashVector推薦使用DashText生成Sparse Vector。
Step3. 帶有Sparse Vector的向量檢索
docs = collection.query(
vector=[0.1, 0.1, 0.1, 0.1],
sparse_vector={1: 0.3, 20:0.7}
)Sparse Vector生成工具
DashText,向量檢索服務(wù)DashVector推薦使用的SparseVectorEncoder,DashText。