本教程演示如何使用向量檢索服務(DashVector),結合靈積模型服務上的Embedding API,來從0到1構建基于文本索引的構建+向量檢索基礎上的語義搜索能力。具體來說,我們將基于QQ 瀏覽器搜索標題語料庫(QBQTC:QQ Browser Query Title Corpus)進行實時的文本語義搜索,查詢最相似的相關標題。
什么是 Embedding
簡單來說,Embedding是一個多維向量的表示數組,通常由一系列數字組成。Embedding可以用來表示任何數據,例如文本、音頻、圖片、視頻等等,通過Embedding我們可以編碼各種類型的非結構化數據,轉化為具有語義信息的多維向量,并在這些向量上進行各種操作,例如相似度計算、聚類、分類和推薦等。
整體流程概述
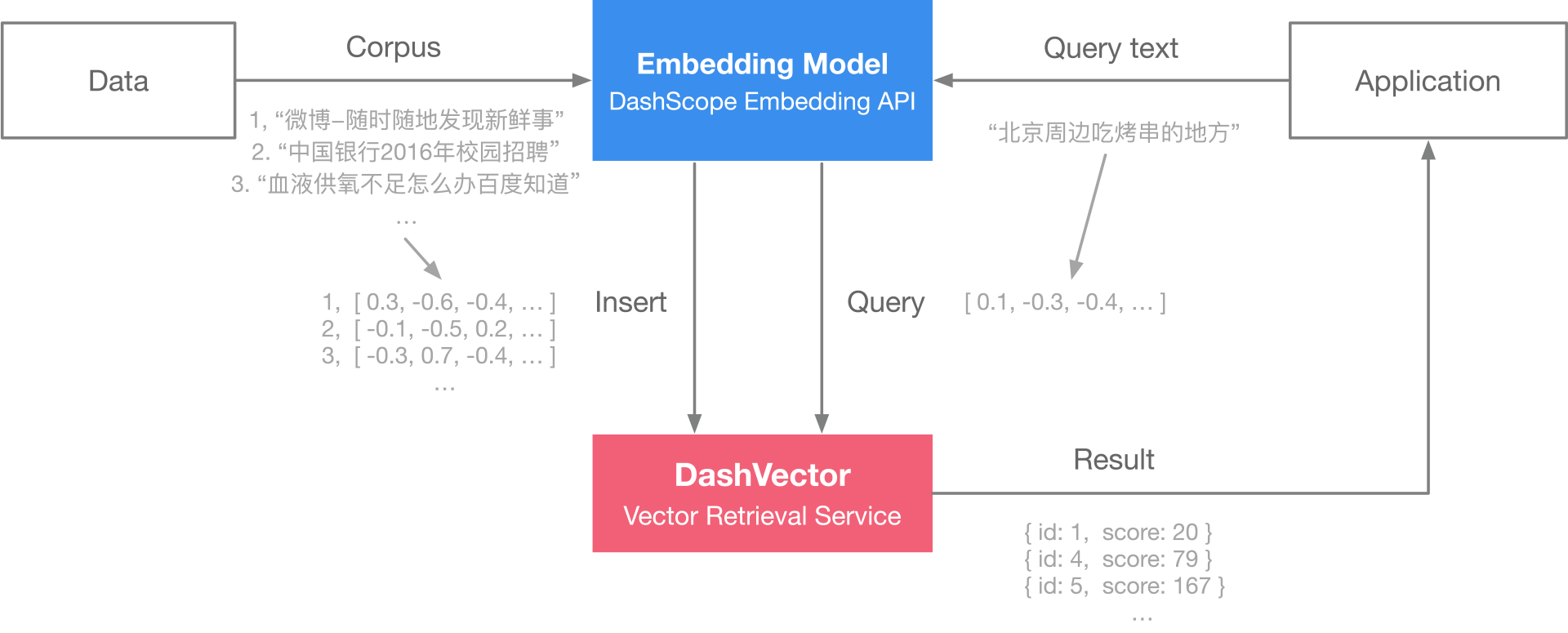
Embedding:通過DashScope提供的通用文本向量模型,對語料庫中所有標題生成對應的embedding向量。
構建索引服務和查詢:
通過DashVector向量檢索服務對生成embedding向量構建索引。
將查詢文本embedding向量作為輸入,通過DashVector搜索相似的標題。
具體操作流程
前提條件
開通靈積模型服務,并獲得 API-KEY:API-KEY的獲取與配置。
開通DashVector向量檢索服務,并獲得 API-KEYAPI-KEY管理。
1、環境安裝
需要提前安裝 Python3.7 及以上版本,請確保相應的 python 版本。
pip3 install dashvector dashscope2、數據準備
QQ瀏覽器搜索相關性數據集(QBQTC, QQ Browser Query Title Corpus),是QQ瀏覽器搜索引擎目前針對大搜場景構建的一個融合了相關性、權威性、內容質量、 時效性等維度標注的學習排序(LTR)數據集,廣泛應用在搜索引擎業務場景中。作為CLUE-benchmark的一部分,QBQTC 數據集可以直接從github上下載(訓練集路徑為dataset/train.json)。
git clone https://github.com/CLUEbenchmark/QBQTC.git
wc -l QBQTC/dataset/train.json數據集中的訓練集(train.json)其格式為 json:
{
"id": 0,
"query": "小孩咳嗽感冒",
"title": "小孩感冒過后久咳嗽該吃什么藥育兒問答寶寶樹",
"label": "1"
}我們將從這個數據集中提取title,方便后續進行embedding并構建檢索服務。
import json
def prepare_data(path, size):
with open(path, 'r', encoding='utf-8') as f:
batch_docs = []
for line in f:
batch_docs.append(json.loads(line.strip()))
if len(batch_docs) == size:
yield batch_docs[:]
batch_docs.clear()
if batch_docs:
yield batch_docs3、通過 DashScope 生成 Embedding 向量
DashScope靈積模型服務通過標準的API提供了多種模型服務。其中支持文本Embedding的模型中文名為通用文本向量,英文名為text-embedding-v1。我們可以方便的通過DashScope API調用來獲得一段輸入文本的embedding向量。
需要使用您的api-key替換示例中的 your-dashscope-api-key ,代碼才能正常運行。
import dashscope
from dashscope import TextEmbedding
dashscope.api_key='{your-dashscope-api-key}'
def generate_embeddings(text):
rsp = TextEmbedding.call(model=TextEmbedding.Models.text_embedding_v1,
input=text)
embeddings = [record['embedding'] for record in rsp.output['embeddings']]
return embeddings if isinstance(text, list) else embeddings[0]
# 查看下embedding向量的維數,后面使用 DashVector 檢索服務時會用到,目前是1536
print(len(generate_embeddings('hello')))4、通過 DashVector 構建檢索:向量入庫
DashVector 向量檢索服務上的數據以集合(Collection)為單位存儲,寫入向量之前,我們首先需要先創建一個集合來管理數據集。創建集合的時候,需要指定向量維度,這里的每一個輸入文本經過DashScope上的text_embedding_v1模型產生的向量,維度統一均為1536。
DashVector 除了提供向量檢索服務外,還提供倒排過濾功能和 scheme free 功能。所以我們為了演示方便,可以寫入數據時,可以將title內容寫入 DashVector 以便召回。寫入數據還需要指定 id,我們可以直接使用 QBQTC 中id。
需要使用您的api-key替換示例中的 your-dashvector-api-key ,以及您的Cluster Endpoint替換示例中的 your-dashvector-cluster-endpoint,代碼才能正常運行。
from dashvector import Client, Doc
# 初始化 DashVector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 指定集合名稱和向量維度
rsp = client.create('sample', 1536)
assert rsp
collection = client.get('sample')
assert collection
batch_size = 10
for docs in prepare_data('QBQTC/dataset/train.json', batch_size):
# 批量 embedding
embeddings = generate_embeddings([doc['title'] for doc in docs])
# 批量寫入數據
rsp = collection.insert(
[
Doc(id=str(doc['id']), vector=embedding, fields={"title": doc['title']})
for doc, embedding in zip(docs, embeddings)
]
)
assert rsp5、語義檢索:向量查詢
在把QBQTC訓練數據集里的title內容都寫到DashVector服務上的集合里后,就可以進行快速的向量檢索,實現“語義搜索”的能力。繼續上面代碼的例子,假如我們要搜索有多少和'應屆生 招聘'相關的title內容,可以通過在DashVector上去查詢'應屆生 招聘',即可迅速獲取與該查詢語義相近的內容,以及對應內容與輸入之間的相似指數。
# 基于向量檢索的語義搜索
rsp = collection.query(generate_embeddings('應屆生 招聘'), output_fields=['title'])
for doc in rsp.output:
print(f"id: {doc.id}, title: {doc.fields['title']}, score: {doc.score}")id: 0, title: 實習生招聘-應屆生求職網, score: 2523.1582
id: 6848, title: 應屆生求職網校園招聘yingjieshengcom中國領先的大學生求職網站, score: 3053.7095
id: 8935, title: 北京招聘求職-前程無憂, score: 5100.5684
id: 5575, title: 百度招聘實習生北京實習招聘, score: 5451.4155
id: 6500, title: 中公教育招聘信息網-招聘崗位-近期職位信息-中公教育網, score: 5656.128
id: 7491, title: 張家口招聘求職-前程無憂, score: 5834.459
id: 7520, title: 前程無憂網北京前程無憂網招聘, score: 5874.412
id: 3214, title: 鄉鎮衛生院招聘信息-58同城, score: 6005.207
id: 6507, title: 趕集網招聘實習生北京實習招聘, score: 6424.9927
id: 5431, title: 實習內容安排百度文庫, score: 6505.735