本教程在前述教程(DashVector + ModelScope玩轉多模態檢索)的基礎之上,基于DashScope上新推出的ONE-PEACE通用多模態表征模型結合向量檢索服務DashVector來對多模態檢索進行升級,接下來我們將展示更豐富的多模態檢索能力。
整體流程
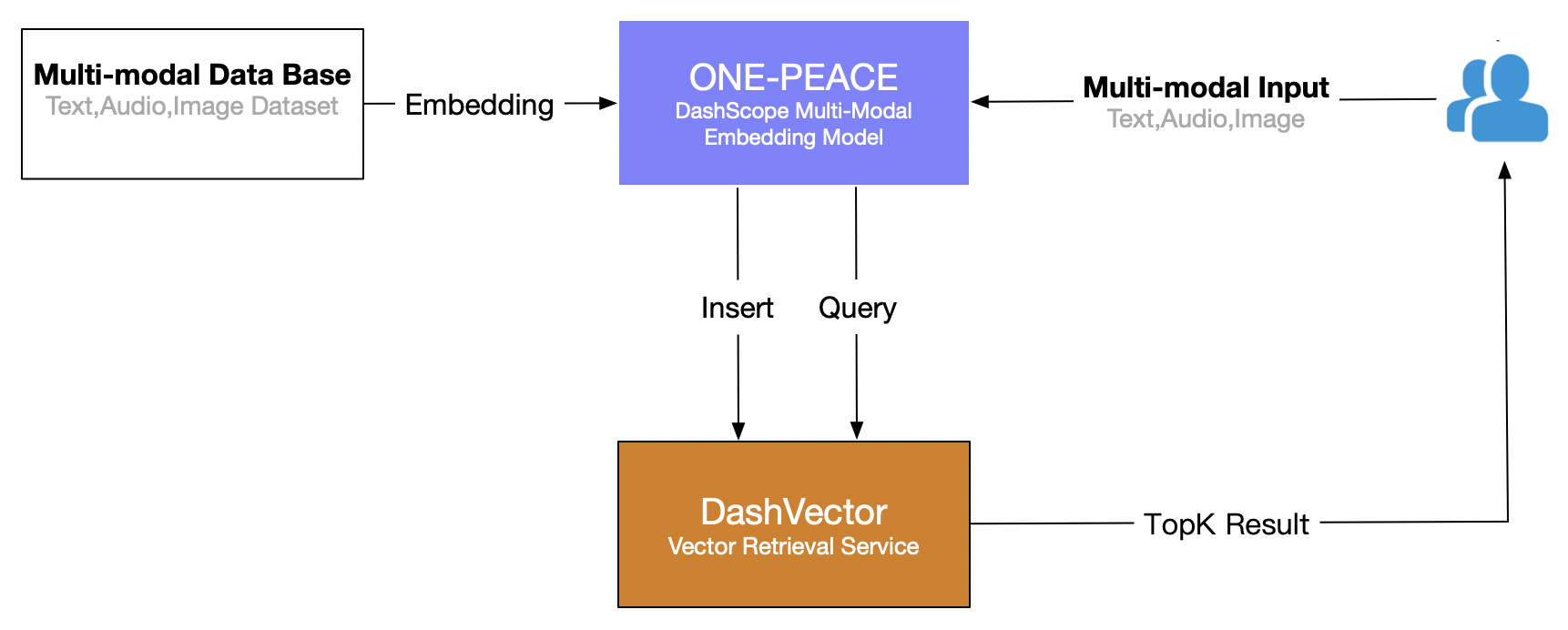
主要分為兩個階段:
多模態數據Embedding入庫。通過ONE-PEACE模型服務Embedding接口將多種模態的數據集數據轉化為高維向量。
多模態Query檢索。基于ONE-PEACE模型提供的多模態Embedding能力,我們可以自由組合不同模態的輸入,例如單文本、文本+音頻、音頻+圖片等多模態輸入,獲取Embedding向量后通過DashVector跨模態檢索相似結果。
前提準備
1. API-KEY 準備
開通靈積模型服務,并獲得API-KEY:API-KEY的獲取與配置
開通DashVector向量檢索服務,并獲得API-KEY:API-KEY管理
2. 環境準備
本教程使用的多模態推理模型服務是DashScope最新的ONE-PEACE模型。ONE-PEACE是一個圖文音三模態通用表征模型,在語義分割、音文檢索、音頻分類和視覺定位幾個任務都達到了新SOTA表現,在視頻分類、圖像分類圖文檢索、以及多模態經典benchmark也都取得了比較領先的結果。模型相關的環境依賴如下:
需要提前安裝Python3.7 及以上版本,請確保相應的python版本。
# 安裝 dashscope 和 dashvector sdk
pip3 install dashscope dashvector基本檢索
1. 數據準備
由于DashScope的ONE-PEACE模型服務當前只支持URL形式的圖片、音頻輸入,因此需要將數據集提前上傳到公共網絡存儲(例如 oss/s3),并獲取對應圖片、音頻的url地址列表。
當前示例場景使用ImageNet-1k的validation數據集作為入庫的圖片數據集,將原始圖片數據Embedding入庫。檢索時使用ESC-50數據集作為音頻輸入,文本和圖片輸入由用戶自定義,用戶也可對不同模態數據自由組合。
2. 數據Embedding入庫
本教程所涉及的 your-xxx-api-key 以及 your-xxx-cluster-endpoint,均需要替換為您自己的API-KAY及CLUSTER_ENDPOINT后,代碼才能正常運行。
ImageNet-1k的validation數據集包含50000張標注好的圖片數據,其中包含1000個類別,每個類別50張圖片,這里我們基于ONE-PEACE模型提取原始圖片的Embedding向量入庫,另外為了方便后續的圖片展示,我們也將原始圖片的url一起入庫。代碼示例如下:
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client, Doc, DashVectorException
dashscope.api_key = '{your-dashscope-api-key}'
# 由于 ONE-PEACE 模型服務當前只支持 url 形式的圖片、音頻輸入,因此用戶需要將數據集提前上傳到
# 公共網絡存儲(例如 oss/s3),并獲取對應圖片、音頻的 url 列表。
# 該文件每行存儲數據集單張圖片的公共 url,與當前python腳本位于同目錄下
IMAGENET1K_URLS_FILE_PATH = "imagenet1k-urls.txt"
def index_image():
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 創建集合:指定集合名稱和向量維度, ONE-PEACE 模型產生的向量統一為 1536 維
rsp = client.create('imagenet1k_val_embedding', 1536)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 調用 dashscope ONE-PEACE 模型生成圖片 Embedding,并插入 dashvector
collection = client.get('imagenet1k_val_embedding')
with open(IMAGENET1K_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url = line.strip('\n')
input = [{'image': url}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url}
)
)
if (i + 1) % 100 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
if __name__ == '__main__':
index_image()
上述代碼需要訪問DashScope的ONE-PEACE多模態Embedding模型,總體運行速度視用戶開通該服務的qps有所不同。
因圖片大小影響ONE-PEACE模型獲取Embedding的成功與否,上述代碼運行后最終入庫數據可能小于50000條。
3. 模態檢索
3.1. 文本檢索
對于單文本模態檢索,可以通過ONE-PEACE模型獲取文本Embedding向量,再通過DashVector向量檢索服務的檢索接口,快速檢索相似的底庫圖片。這里文本query是貓 “cat”,代碼示例如下:
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
dashscope.api_key = '{your-dashscope-api-key}'
def show_image(image_list):
for img in image_list:
# 注意:show() 函數在 Linux 服務器上可能需要安裝必要的圖像瀏覽器組件才生效
# 建議在支持 jupyter notebook 的服務器上運行該代碼
img.show()
def text_search(input_text):
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 獲取上述入庫的集合
collection = client.get('imagenet1k_val_embedding')
# 獲取文本 query 的 Embedding 向量
input = [{'text': input_text}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
text_vector = result.output["embedding"]
# DashVector 向量檢索
rsp = collection.query(text_vector, topk=3)
image_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img = Image.open(urlopen(img_url))
image_list.append(img)
return image_list
if __name__ == '__main__':
"""文本檢索"""
# 貓
text_query = "cat"
show_image(text_search(text_query))運行上述代碼,檢索結果如下:
|
|
|



3.2. 音頻檢索
單音頻模態檢索與文本檢索類似,這里音頻query取自ESC-50的“貓叫聲”片段,代碼示例如下:
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
dashscope.api_key = '{your-dashscope-api-key}'
def show_image(image_list):
for img in image_list:
# 注意:show() 函數在 Linux 服務器上可能需要安裝必要的圖像瀏覽器組件才生效
# 建議在支持 jupyter notebook 的服務器上運行該代碼
img.show()
def audio_search(input_audio):
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 獲取上述入庫的集合
collection = client.get('imagenet1k_val_embedding')
# 獲取音頻 query 的 Embedding 向量
input = [{'audio': input_audio}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
audio_vector = result.output["embedding"]
# DashVector 向量檢索
rsp = collection.query(audio_vector, topk=3)
image_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img = Image.open(urlopen(img_url))
image_list.append(img)
return image_list
if __name__ == '__main__':
"""音頻檢索"""
# 貓叫聲
audio_url = "http://proxima-internal.oss-cn-zhangjiakou.aliyuncs.com/audio-dataset/esc-50/1-47819-A-5.wav"
show_image(audio_search(audio_url))運行上述代碼,檢索結果如下:
|
|
|



3.3. 文本+音頻檢索
接下來,我們嘗試“文本+音頻”聯合模態檢索,同上,首先通過ONE-PEACE模型獲取“文本+音頻”輸入的Embedding向量,再通過DashVector向量檢索服務檢索結果。這里的文本query選取的是草地“grass”,音頻query依然選擇的是ESC-50的“貓叫聲”片段。代碼示例如下:
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
dashscope.api_key = '{your-dashscope-api-key}'
def show_image(image_list):
for img in image_list:
# 注意:show() 函數在 Linux 服務器上可能需要安裝必要的圖像瀏覽器組件才生效
# 建議在支持 jupyter notebook 的服務器上運行該代碼
img.show()
def text_audio_search(input_text, input_audio):
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 獲取上述入庫的集合
collection = client.get('imagenet1k_val_embedding')
# 獲取文本+音頻 query 的 Embedding 向量
input = [
{'text': input_text},
{'audio': input_audio},
]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
text_audio_vector = result.output["embedding"]
# DashVector 向量檢索
rsp = collection.query(text_audio_vector, topk=3)
image_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img = Image.open(urlopen(img_url))
image_list.append(img)
return image_list
if __name__ == '__main__':
"""文本+音頻檢索"""
# 草地
text_query = "grass"
# 貓叫聲
audio_url = "http://proxima-internal.oss-cn-zhangjiakou.aliyuncs.com/audio-dataset/esc-50/1-47819-A-5.wav"
show_image(text_audio_search(text_query, audio_url))運行上述代碼,檢索結果如下:
|
|
|



3.4. 圖片+音頻檢索
我們再嘗試下“圖片+音頻”聯合模態檢索,與前述“文本+音頻”檢索類似,這里的圖片選取的是草地圖像(需先上傳到公共網絡存儲并獲取 url),音頻query依然選擇的是ESC-50的“貓叫聲”片段。代碼示例如下:
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
dashscope.api_key = '{your-dashscope-api-key}'
def show_image(image_list):
for img in image_list:
# 注意:show() 函數在 Linux 服務器上可能需要安裝必要的圖像瀏覽器組件才生效
# 建議在支持 jupyter notebook 的服務器上運行該代碼
img.show()
def image_audio_search(input_image, input_audio):
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 獲取上述入庫的集合
collection = client.get('imagenet1k_val_embedding')
# 獲取圖片+音頻 query 的 Embedding 向量
# 注意,這里音頻 audio 模態輸入的權重參數 factor 為 2(默認為1)
# 目的是為了增大音頻輸入(貓叫聲)對檢索結果的影響
input = [
{'factor': 1, 'image': input_image},
{'factor': 2, 'audio': input_audio},
]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
image_audio_vector = result.output["embedding"]
# DashVector 向量檢索
rsp = collection.query(image_audio_vector, topk=3)
image_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img = Image.open(urlopen(img_url))
image_list.append(img)
return image_list
if __name__ == '__main__':
"""圖片+音頻檢索"""
# 草地
image_url = "http://proxima-internal.oss-cn-zhangjiakou.aliyuncs.com/image-dataset/grass-field.jpeg"
# 貓叫聲
audio_url = "http://proxima-internal.oss-cn-zhangjiakou.aliyuncs.com/audio-dataset/esc-50/1-47819-A-5.wav"
show_image(image_audio_search(image_url, audio_url))輸入示意圖如下:

運行代碼,檢索結果如下:
|
|
|



進階使用
上述場景里作為檢索底庫數據的是單模態的圖片數據,這里我們也可以將多種模態的數據同時通過ONE-PEACE模型獲取Embedding向量,將Embedding向量作為檢索庫數據入庫檢索,觀察檢索效果。
1. 數據準備
本示例場景使用微軟COCO在Captioning場景下的validation數據集,將圖片以及對應的圖片描述caption文本兩種模態數據一起Embedding入庫。對于檢索時輸入的圖片、音頻與文本等多模態數據,用戶可以自定義,也可以使用公共數據集的數據。
2. 數據Embedding入庫
本教程所涉及的 your-xxx-api-key 以及 your-xxx-cluster-endpoint,均需要替換為您自己的API-KAY及CLUSTER_ENDPOINT后,代碼才能正常運行。
微軟COCO的Captioning validation驗證集包含5000張標注良好的圖片及對應的說明文本,這里我們需要通過 DashScope的ONE-PEACE模型提取數據集的“圖片+文本”的Embedding向量入庫,另外為了方便后續的圖片展示,我們也將原始圖片url和對應caption文本一起入庫。代碼示例如下:
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client, Doc, DashVectorException
dashscope.api_key = '{your-dashscope-api-key}'
# 由于 ONE-PEACE 模型服務當前只支持 url 形式的圖片、音頻輸入,因此用戶需要將數據集提前上傳到
# 公共網絡存儲(例如 oss/s3),并獲取對應圖片、音頻的 url 列表。
# 該文件每行存儲數據集單張圖片的公共 url 和對應的 caption 文本,以`;`分割
COCO_CAPTIONING_URLS_FILE_PATH = "cocoval5k-urls-captions.txt"
def index_image_text():
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 創建集合:指定集合名稱和向量維度, ONE-PEACE 模型產生的向量統一為 1536 維
rsp = client.create('coco_val_embedding', 1536)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 調用 dashscope ONE-PEACE 模型生成圖片 Embedding,并插入 dashvector
collection = client.get('coco_val_embedding')
with open(COCO_CAPTIONING_URLS_FILE_PATH, 'r') as file:
for i, line in enumerate(file):
url, caption = line.strip('\n').split(";")
input = [
{'text': caption},
{'image': url},
]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}")
continue
embedding = result.output["embedding"]
collection.insert(
Doc(
id=str(i),
vector=embedding,
fields={'image_url': url, 'image_caption': caption}
)
)
if (i + 1) % 20 == 0:
print(f"---- Succeeded to insert {i + 1} image embeddings")
if __name__ == '__main__':
index_image_text()
上述代碼需要訪問DashScope的ONE-PEACE多模態Embedding模型,總體運行速度視用戶開通該服務的qps有所不同。
3. 模態檢索
3.1. 文本檢索
首先我們嘗試單文本模態檢索。代碼示例如下:
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
dashscope.api_key = '{your-dashscope-api-key}'
def show_image_text(image_text_list):
for img, cap in image_text_list:
# 注意:show() 函數在 Linux 服務器上可能需要安裝必要的圖像瀏覽器組件才生效
# 建議在支持 jupyter notebook 的服務器上運行該代碼
img.show()
print(cap)
def text_search(input_text):
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 獲取上述入庫的集合
collection = client.get('coco_val_embedding')
# 獲取文本 query 的 Embedding 向量
input = [{'text': input_text}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
text_vector = result.output["embedding"]
# DashVector 向量檢索
rsp = collection.query(text_vector, topk=3)
image_text_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img_cap = doc.fields['image_caption']
img = Image.open(urlopen(img_url))
image_text_list.append((img, img_cap))
return image_text_list
if __name__ == '__main__':
"""文本檢索"""
# 狗
text_query = "dog"
show_image_text(text_search(text_query))
運行上述代碼,檢索結果如下:
The fur on this dog is long enough to cover his eyes. |
A picture of a dog on a bed. |
A dog going to the bathroom in the park. |



3.2. 音頻檢索
我們再嘗試單音頻模態檢索。我們使用ESC-50數據集的“狗叫聲片段”作為音頻輸入,代碼示例如下:
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
dashscope.api_key = '{your-dashscope-api-key}'
def show_image_text(image_text_list):
for img, cap in image_text_list:
# 注意:show() 函數在 Linux 服務器上可能需要安裝必要的圖像瀏覽器組件才生效
# 建議在支持 jupyter notebook 的服務器上運行該代碼
img.show()
print(cap)
def audio_search(input_audio):
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 獲取上述入庫的集合
collection = client.get('coco_val_embedding')
# 獲取音頻 query 的 Embedding 向量
input = [{'audio': input_audio}]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
audio_vector = result.output["embedding"]
# DashVector 向量檢索
rsp = collection.query(audio_vector, topk=3)
image_text_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img_cap = doc.fields['image_caption']
img = Image.open(urlopen(img_url))
image_text_list.append((img, img_cap))
return image_text_list
if __name__ == '__main__':
""""音頻檢索"""
# dog bark
audio_url = "http://proxima-internal.oss-cn-zhangjiakou.aliyuncs.com/audio-dataset/esc-50/1-100032-A-0.wav"
show_image_text(audio_search(audio_url))
運行上述代碼,檢索結果如下:
The fur on this dog is long enough to cover his eyes. |
A dog standing on a bed in a room. |
A small black and white dog with the wind blowing through it's hair. |



3.3. 文本+音頻檢索
進一步的,我們嘗試使用“文本+音頻”進行雙模態檢索。這里使用ESC-50數據集的“狗叫聲片段”作為音頻輸入,另外使用“beach”作為文本輸入,代碼示例如下:
import dashscope
from dashscope import MultiModalEmbedding
from dashvector import Client
from urllib.request import urlopen
from PIL import Image
dashscope.api_key = '{your-dashscope-api-key}'
def show_image_text(image_text_list):
for img, cap in image_text_list:
# 注意:show() 函數在 Linux 服務器上可能需要安裝必要的圖像瀏覽器組件才生效
# 建議在支持 jupyter notebook 的服務器上運行該代碼
img.show()
print(cap)
def text_audio_search(input_text, input_audio):
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 獲取上述入庫的集合
collection = client.get('coco_val_embedding')
# 獲取文本+音頻 query 的 Embedding 向量
input = [
{'text': input_text},
{'audio': input_audio},
]
result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1,
input=input,
auto_truncation=True)
if result.status_code != 200:
raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}")
text_audio_vector = result.output["embedding"]
# DashVector 向量檢索
rsp = collection.query(text_audio_vector, topk=3)
image_text_list = list()
for doc in rsp:
img_url = doc.fields['image_url']
img_cap = doc.fields['image_caption']
img = Image.open(urlopen(img_url))
image_text_list.append((img, img_cap))
return image_text_list
if __name__ == '__main__':
"""文本+音頻檢索"""
text_query = "beach"
# 狗叫聲
audio_url = "http://proxima-internal.oss-cn-zhangjiakou.aliyuncs.com/audio-dataset/esc-50/1-100032-A-0.wav"
show_image_text(text_audio_search(text_query, audio_url))
運行上述代碼,檢索結果如下:
a couple of dogs stand on a beach next to some water. |
A view of a beach that has some people sitting on it. |
people enjoy swimming in the waves of the ocean on a sunny day at the beach. |



觀察上述檢索結果,發現后兩張圖的重點更多的是在展示 “beach” 文本輸入對應的沙灘,而 “狗叫聲片段”音頻輸入指示的狗的圖片形象則不明顯,其中第二張圖需要放大后才可以看到圖片中站立在水中的狗,第三張圖中基本沒有狗的形象。
對于上述情況,我們可以通過調整不同輸入的權重來設置mbedding向量中哪種模態占更大的比重,從而在檢索中突出重點。例如對于上述代碼,我們可以給予“狗叫聲片段”更大的權重,重點突出檢索結果里狗的形象。
# 其他代碼一致
# 通過 `factor` 參數來調整不同模態輸入的權重,默認為 1,這里設置 audio 為 2
input = [
{'factor': 1, 'text': input_text},
{'factor': 2, 'audio': input_audio},
]替換 input后,運行上述代碼,結果如下:
a couple of dogs stand on a beach next to some water. |
A beautiful woman in a bikini surfing with her dog. |
A small black and white dog with the wind blowing through it's hair. |



寫在最后
本文結合DashScope的ONE-PEACE模型的和DashVector向量檢索服務向大家展示了豐富多樣的多模態檢索示例,得益于ONE-PEACE模型優秀的多模態Embedding能力和DashVector強大的向量檢索能力,我們能初步看到AI多模態檢索令人驚喜的效果。
本文的范例中,我們的向量檢索服務,模型服務以及數據均可以公開獲取,我們提供的示例也只是有限的展示了多模態檢索的效果,非常歡迎大家來體驗,自由發掘多模態檢索的潛力。