DashVector + ModelScope 玩轉(zhuǎn)多模態(tài)檢索
本教程演示如何使用向量檢索服務(wù)(DashVector),結(jié)合ModelScope上的中文CLIP多模態(tài)檢索模型,構(gòu)建實(shí)時(shí)的“文本搜圖片”的多模態(tài)檢索能力。作為示例,我們采用多模態(tài)牧歌數(shù)據(jù)集作為圖片語(yǔ)料庫(kù),用戶(hù)通過(guò)輸入文本來(lái)跨模態(tài)檢索最相似的圖片。
整體流程
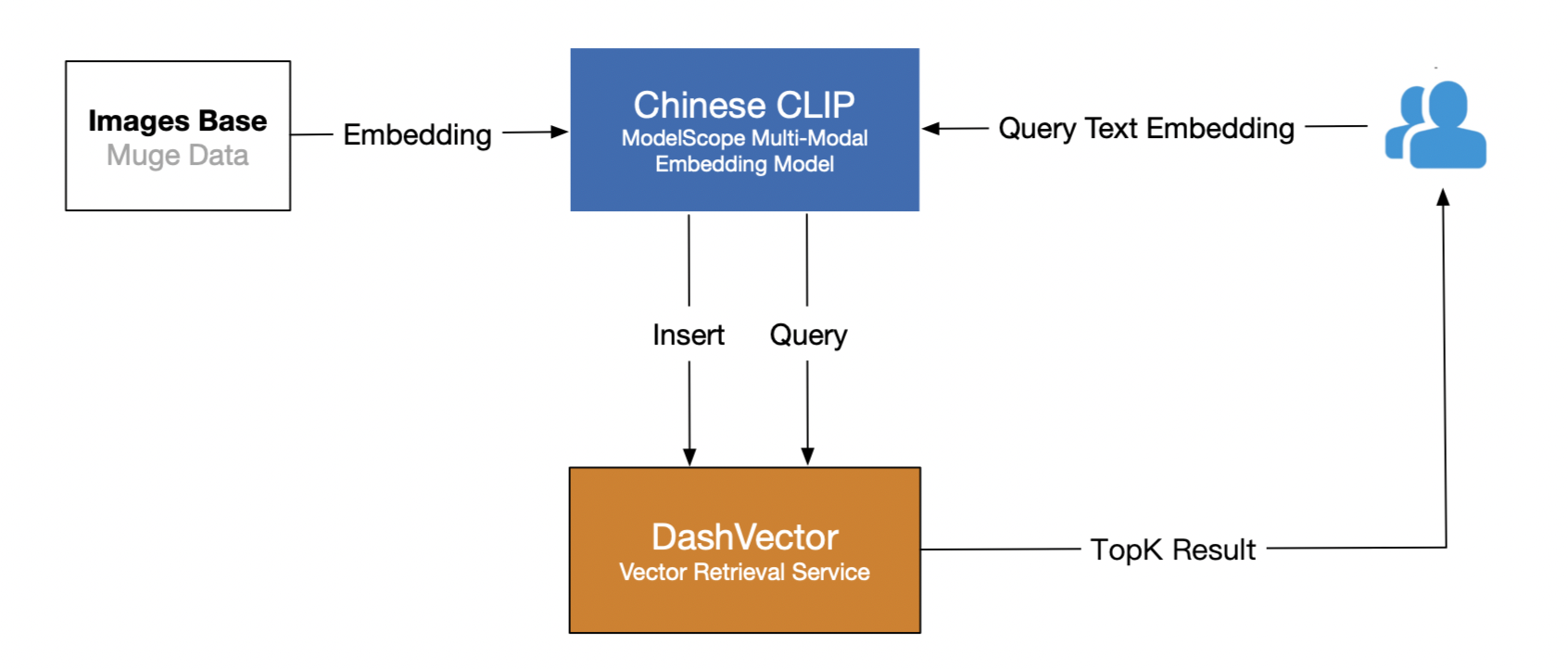
主要分為兩個(gè)階段:
圖片數(shù)據(jù)Embedding入庫(kù)。將牧歌數(shù)據(jù)集通過(guò)中文CLIP模型Embedding接口轉(zhuǎn)化為高維向量,然后寫(xiě)入DashVector向量檢索服務(wù)。
文本Query檢索。使用對(duì)應(yīng)的中文CLIP模型獲取文本的Embedding向量,然后通過(guò)DashVector檢索相似圖片。
前提準(zhǔn)備
1. API-KEY 準(zhǔn)備
開(kāi)通向量檢索服務(wù):請(qǐng)參見(jiàn)開(kāi)通服務(wù)。
創(chuàng)建向量檢索服務(wù)API-KEY:請(qǐng)參見(jiàn)API-KEY管理。
2. 環(huán)境準(zhǔn)備
本教程使用的是ModelScope最新的CLIP Huge模型(224分辨率),該模型使用大規(guī)模中文數(shù)據(jù)進(jìn)行訓(xùn)練(~2億圖文對(duì)),在中文圖文檢索和圖像、文本的表征提取等場(chǎng)景表現(xiàn)優(yōu)異。根據(jù)模型官網(wǎng)教程,我們提取出相關(guān)的環(huán)境依賴(lài)如下:
需要提前安裝 Python3.7 及以上版本,請(qǐng)確保相應(yīng)的 python 版本
# 安裝 dashvector 客戶(hù)端
pip3 install dashvector
# 安裝 modelscope
# require modelscope>=0.3.7,目前默認(rèn)已經(jīng)超過(guò),您檢查一下即可
# 按照更新鏡像的方法處理或者下面的方法
pip3 install --upgrade modelscope -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
# 需要單獨(dú)安裝decord
# pip3 install decord
# 另外,modelscope 的安裝過(guò)程會(huì)出現(xiàn)其他的依賴(lài),當(dāng)前版本的依賴(lài)列舉如下
# pip3 install torch torchvision opencv-python timm librosa fairseq transformers unicodedata2 zhconv rapidfuzz3. 數(shù)據(jù)準(zhǔn)備
本教程使用多模態(tài)牧歌數(shù)據(jù)集的validation驗(yàn)證集作為入庫(kù)的圖片數(shù)據(jù)集,可以通過(guò)調(diào)用ModelScope的數(shù)據(jù)集接口獲取。
from modelscope.msdatasets import MsDataset
dataset = MsDataset.load("muge", split="validation")具體步驟
本教程所涉及的 your-xxx-api-key 以及 your-xxx-cluster-endpoint,均需要替換為您自己的API-KAY及CLUSTER_ENDPOINT后,代碼才能正常運(yùn)行。
1. 圖片數(shù)據(jù)Embedding入庫(kù)
多模態(tài)牧歌數(shù)據(jù)集的 validation 驗(yàn)證集包含 30588 張多模態(tài)場(chǎng)景的圖片數(shù)據(jù)信息,這里我們需要通過(guò)CLIP模型提取原始圖片的Embedding向量入庫(kù),另外為了方便后續(xù)的圖片展示,我們也將原始圖片數(shù)據(jù)編碼后一起入庫(kù)。代碼實(shí)例如下:
import torch
from modelscope.utils.constant import Tasks
from modelscope.pipelines import pipeline
from modelscope.msdatasets import MsDataset
from dashvector import Client, Doc, DashVectorException, DashVectorCode
from PIL import Image
import base64
import io
def image2str(image):
image_byte_arr = io.BytesIO()
image.save(image_byte_arr, format='PNG')
image_bytes = image_byte_arr.getvalue()
return base64.b64encode(image_bytes).decode()
if __name__ == '__main__':
# 初始化 dashvector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 創(chuàng)建集合:指定集合名稱(chēng)和向量維度, CLIP huge 模型產(chǎn)生的向量統(tǒng)一為 1024 維
rsp = client.create('muge_embedding', 1024)
if not rsp:
raise DashVectorException(rsp.code, reason=rsp.message)
# 批量生成圖片Embedding,并完成向量入庫(kù)
collection = client.get('muge_embedding')
pipe = pipeline(task=Tasks.multi_modal_embedding,
model='damo/multi-modal_clip-vit-huge-patch14_zh',
model_revision='v1.0.0')
ds = MsDataset.load("muge", split="validation")
BATCH_COUNT = 10
TOTAL_DATA_NUM = len(ds)
print(f"Start indexing muge validation data, total data size: {TOTAL_DATA_NUM}, batch size:{BATCH_COUNT}")
idx = 0
while idx < TOTAL_DATA_NUM:
batch_range = range(idx, idx + BATCH_COUNT) if idx + BATCH_COUNT <= TOTAL_DATA_NUM else range(idx, TOTAL_DATA_NUM)
images = [ds[i]['image'] for i in batch_range]
# 中文 CLIP 模型生成圖片 Embedding 向量
image_embeddings = pipe.forward({'img': images})['img_embedding']
image_vectors = image_embeddings.detach().cpu().numpy()
collection.insert(
[
Doc(
id=str(img_id),
vector=img_vec,
fields={'png_img': image2str(img)}
)
for img_id, img_vec, img in zip(batch_range, image_vectors, images)
]
)
idx += BATCH_COUNT
print("Finish indexing muge validation data")
上述代碼里模型默認(rèn)在 cpu 環(huán)境下運(yùn)行,在 gpu 環(huán)境下會(huì)視 gpu 性能得到不同程度的性能提升
2. 文本Query檢索
完成上述圖片數(shù)據(jù)向量化入庫(kù)后,我們可以輸入文本,通過(guò)同樣的CLIP Embedding模型獲取文本向量,再通過(guò)DashVector向量檢索服務(wù)的檢索接口,快速檢索相似的圖片了,代碼示例如下:
import torch
from modelscope.utils.constant import Tasks
from modelscope.pipelines import pipeline
from modelscope.msdatasets import MsDataset
from dashvector import Client, Doc, DashVectorException
from PIL import Image
import base64
import io
def str2image(image_str):
image_bytes = base64.b64decode(image_str)
return Image.open(io.BytesIO(image_bytes))
def multi_modal_search(input_text):
# 初始化 DashVector client
client = Client(
api_key='{your-dashvector-api-key}',
endpoint='{your-dashvector-cluster-endpoint}'
)
# 獲取上述入庫(kù)的集合
collection = client.get('muge_embedding')
# 獲取文本 query 的 Embedding 向量
pipe = pipeline(task=Tasks.multi_modal_embedding,
model='damo/multi-modal_clip-vit-huge-patch14_zh', model_revision='v1.0.0')
text_embedding = pipe.forward({'text': input_text})['text_embedding'] # 2D Tensor, [文本數(shù), 特征維度]
text_vector = text_embedding.detach().cpu().numpy()[0]
# DashVector 向量檢索
rsp = collection.query(text_vector, topk=3)
image_list = list()
for doc in rsp:
image_str = doc.fields['png_img']
image_list.append(str2image(image_str))
return image_list
if __name__ == '__main__':
text_query = "戴眼鏡的狗"
images = multi_modal_search(text_query)
for img in images:
# 注意:show() 函數(shù)在 Linux 服務(wù)器上可能需要安裝必要的圖像瀏覽器組件才生效
# 建議在支持 jupyter notebook 的服務(wù)器上運(yùn)行該代碼
img.show()
運(yùn)行上述代碼,輸出結(jié)果如下:


