產(chǎn)品架構
云數(shù)據(jù)庫 SelectDB 版是基于Apache Doris研發(fā)的現(xiàn)代化實時數(shù)倉服務,采用全新的云原生存算分離架構。本文為您介紹云數(shù)據(jù)庫 SelectDB 版的產(chǎn)品架構及基本原理。
架構圖
組件說明
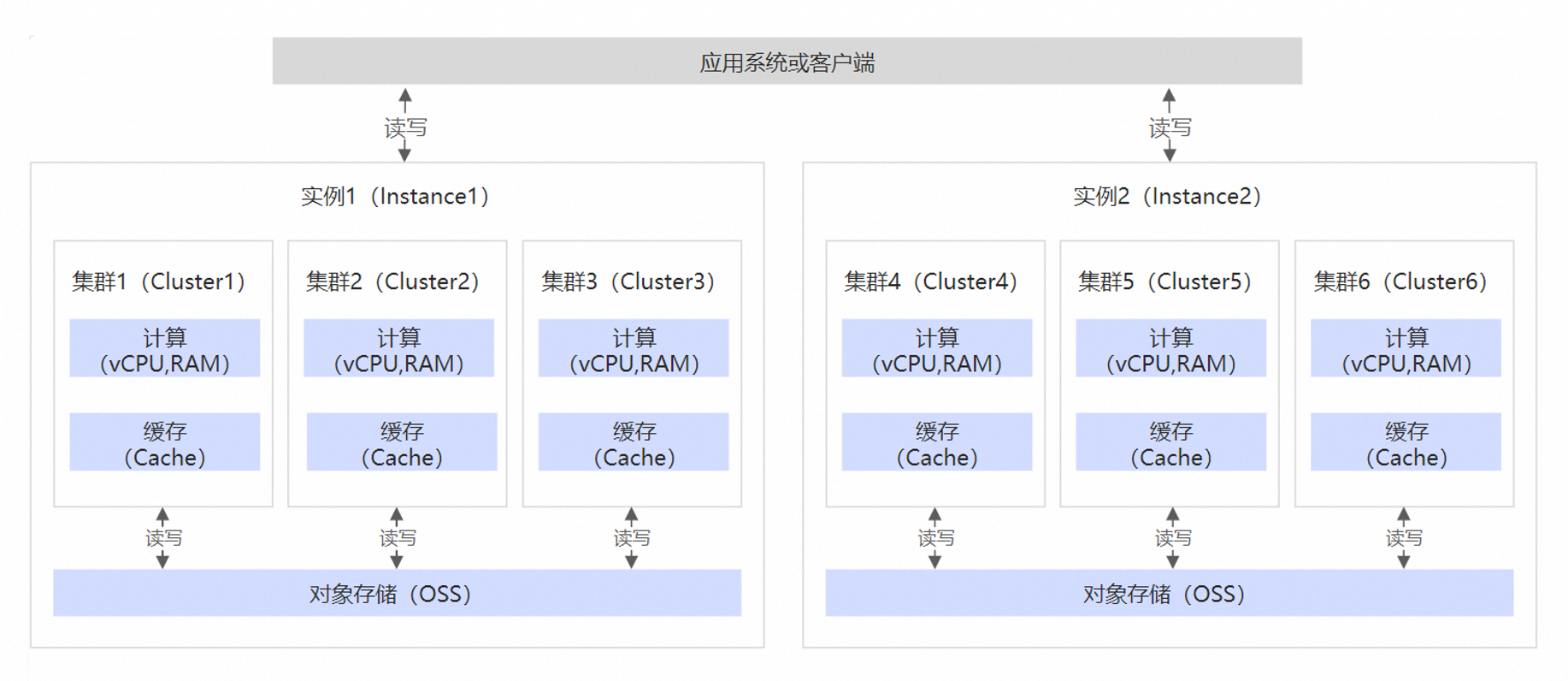
應用系統(tǒng)或客戶端
應用系統(tǒng)或客戶端是您訪問云數(shù)據(jù)庫 SelectDB 版的產(chǎn)品或工具。由于云數(shù)據(jù)庫 SelectDB 版兼容MySQL連接協(xié)議和標準SQL語法,因此MySQL生態(tài)中的命令行工具、JDBC/ODBC驅(qū)動以及可視化工具等,均可連接訪問云數(shù)據(jù)庫 SelectDB 版的實例。
為了減少網(wǎng)絡延時和不穩(wěn)定的影響,建議應用程序或客戶端與云數(shù)據(jù)庫 SelectDB 版實例部署在相同地域。
實例
云數(shù)據(jù)庫 SelectDB 版 的實例是購買和使用數(shù)據(jù)庫服務的基本單元。在購買云數(shù)據(jù)庫 SelectDB 版 的實例后,實例以及相關集群的資源歸屬于您。云數(shù)據(jù)庫 SelectDB 版采用云原生存算分離架構,包含實例入口(負責接收請求,包含一組FE節(jié)點)、集群(負責實際請求執(zhí)行的分布式系統(tǒng),包含一組BE節(jié)點)、存儲(對象存儲OSS)等組件。其中實例入口由云數(shù)據(jù)庫 SelectDB 版托管并按需伸縮,您無需管理。云數(shù)據(jù)庫 SelectDB 版的多實例之間的資源是完全物理隔離的,可用于滿足完全獨立的或敏感性差別較大的業(yè)務場景。
在使用云數(shù)據(jù)庫 SelectDB 版實例進行讀寫操作時,主體流程如下:
寫入請求:您可通過云數(shù)據(jù)庫 SelectDB 版提供的寫入接口或者已有的導入工具,向云數(shù)據(jù)庫 SelectDB 版發(fā)起寫入請求。實例入口接收到請求后,根據(jù)您選擇或者默認設置將請求重定向給目標集群。目標集群具體處理寫入請求,其將數(shù)據(jù)寫入對象存儲及緩存中,在對象存儲完成持久化后,返回成功提示。
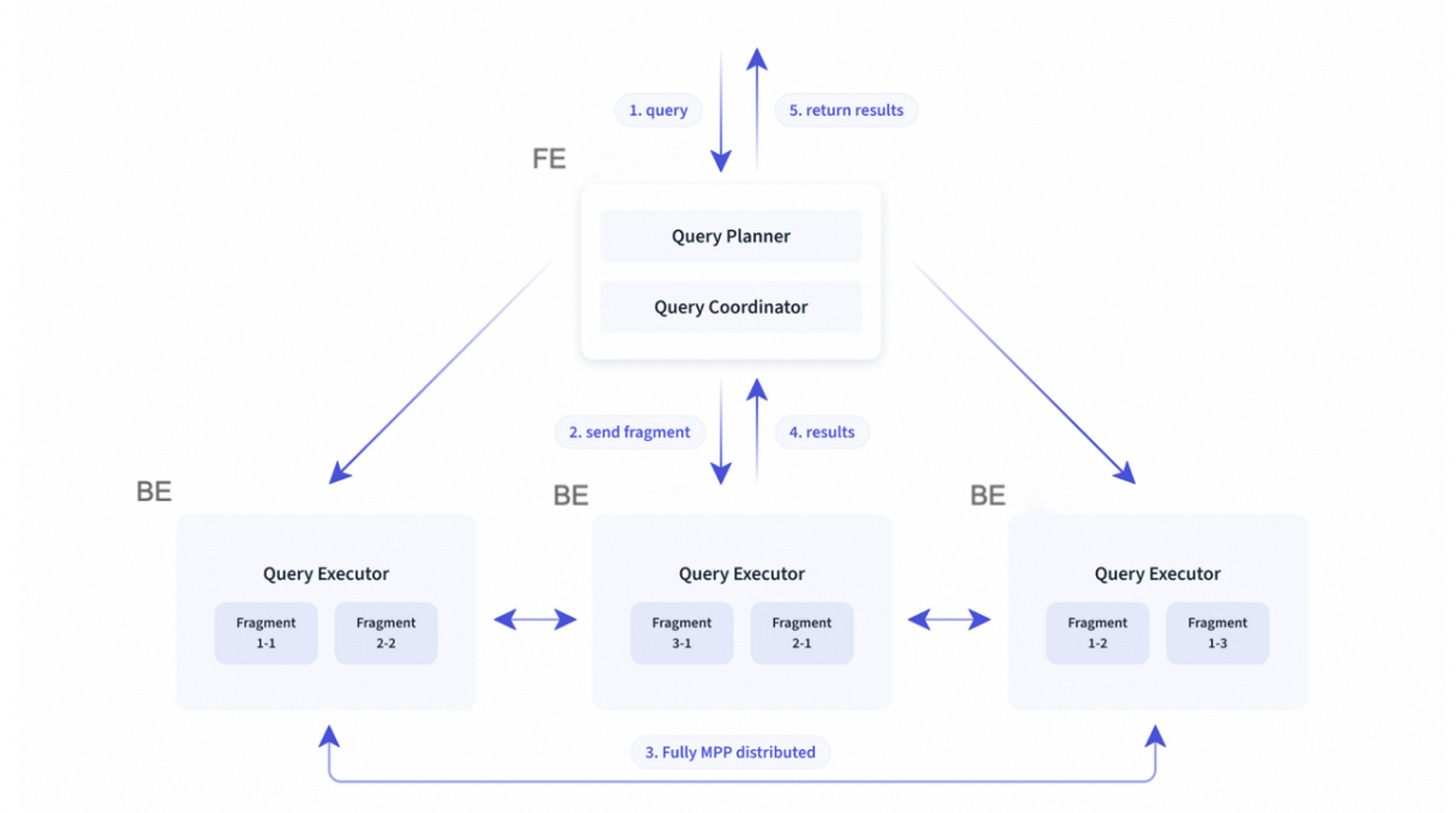
查詢請求:您可通過執(zhí)行SQL向云數(shù)據(jù)庫 SelectDB 版發(fā)起查詢請求。實例入口接收到查詢請求后,首先會對請求的SQL進行解析,然后智能優(yōu)化器對SQL進行優(yōu)化,產(chǎn)出高效的查詢執(zhí)行計劃,最后將請求轉發(fā)給目標集群。目標集群對查詢請求進行大規(guī)模并發(fā)調(diào)度執(zhí)行(Massively Parallel Processing),查詢按需讀取緩存或?qū)ο蟠鎯χ械臄?shù)據(jù),完成后通過MySQL協(xié)議將結果返回。集群在查詢處理過程中,采用了Pipeline執(zhí)行框架、索引技術、緩存技術、向量化技術等技術,使得查詢速度加快,讓您體驗到云數(shù)據(jù)庫 SelectDB 版更好的數(shù)據(jù)分析性能。以下為云數(shù)據(jù)庫 SelectDB 版處理一個查詢請求的過程圖。
集群
云數(shù)據(jù)庫 SelectDB 版的集群是包含一個或多個BE節(jié)點的分布式系統(tǒng),每個節(jié)點包含計算資源和緩存資源。由于存算分離架構中對象存儲訪問較慢,所以引入緩存用以加速數(shù)據(jù)訪問。云數(shù)據(jù)庫 SelectDB 版支持內(nèi)存、硬盤等多級緩存機制。集群支持靈活的彈性伸縮能力,伸縮過程會進行緩存的預熱與遷移,盡可能為您提供平滑的分析體驗。
云數(shù)據(jù)庫 SelectDB 版支持多集群架構,一個實例中可以包含多個集群,類似經(jīng)典分布式架構中的計算隊列、計算組。同一實例中的多個集群具有如下特性:
數(shù)據(jù)共享:多集群共享底層對象存儲,均可訪問底層數(shù)據(jù),避免了冗余數(shù)據(jù)存儲。
計算隔離:多集群間的計算與緩存資源是完全獨立的,可用于隔離不同的工作負載。每個集群可以按需購買不同規(guī)格的計算資源和存儲資源,并根據(jù)自身訪問規(guī)律進行數(shù)據(jù)緩存。
多讀多寫:多集群在數(shù)據(jù)讀寫方面具有獨立對等的特性,能夠并行寫入數(shù)據(jù)。一旦數(shù)據(jù)提交生效,所有集群均可立即查詢到最新的數(shù)據(jù)。
基于上述特性,多集群通常用于實現(xiàn)讀寫隔離、在線與離線業(yè)務隔離以及生產(chǎn)與測試環(huán)境隔離等場景。
存儲
云數(shù)據(jù)庫 SelectDB 版采用高可靠、低成本的對象存儲OSS作為存儲系統(tǒng),用于持久化保存數(shù)據(jù)。基于對象存儲本身的高可靠性,云數(shù)據(jù)庫 SelectDB 版無需在分布式數(shù)倉系統(tǒng)中維護數(shù)據(jù)副本。此外,基于對象存儲OSS的低成本特性,SelectDB的單位存儲成本相比傳統(tǒng)數(shù)倉可降低90%以上。
云數(shù)據(jù)庫 SelectDB 版的存儲資源無需預設大小,其采用按量付費的計費方式,并支持使用存儲資源包進行抵扣,從而進一步降低了存儲成本。
為了提供更好的分析性能,云數(shù)據(jù)庫 SelectDB 版對存儲和計算進行了深度結合設計,具體體現(xiàn)在以下幾個方面。
數(shù)組組織:為提升數(shù)據(jù)的訪問效率,云數(shù)據(jù)庫 SelectDB 版對底層數(shù)據(jù)組織進行了精致的設計。
數(shù)據(jù)分區(qū):數(shù)據(jù)按照時間段或Hash值進行劃分打散,以充分利用分布式集群的處理能力,同時有利于查詢時數(shù)據(jù)裁剪。
支持行列混合存儲:默認的列式存儲可滿足海量數(shù)據(jù)的高效分析,按需開啟的行式存儲可支持高性能的點查詢。
豐富的索引能力:可結合過濾條件精準定位數(shù)據(jù),數(shù)量級提升查詢性能。
數(shù)據(jù)模型:云數(shù)據(jù)庫 SelectDB 版對于不同的數(shù)據(jù)分析場景,提供了不同的數(shù)據(jù)模型。
主鍵模型(Unique模型):適用于對數(shù)據(jù)有唯一主鍵要求或高效更新要求的場景。例如電商訂單、用戶屬性信息等數(shù)據(jù)分析場景。
聚合模型(Aggregate模型):適用于保留所有原始數(shù)據(jù)記錄的場景。例如日志、賬單等明細數(shù)據(jù)分析場景。
明細模型(Duplicate模型):適用于通過預聚合提升查詢性能的聚合統(tǒng)計場景。例如網(wǎng)站流量分析、定制化報表等數(shù)據(jù)分析場景。
外部生態(tài)
云數(shù)據(jù)庫 SelectDB 版支持與周邊數(shù)據(jù)生態(tài)中的數(shù)據(jù)源及可視化工具進行集成,顯著提升數(shù)據(jù)分析的便捷性。
豐富的數(shù)據(jù)導入工具:云數(shù)據(jù)庫 SelectDB 版可從多種數(shù)據(jù)源(阿里云數(shù)據(jù)源、自建數(shù)據(jù)源)進行數(shù)據(jù)導入,提供穩(wěn)定、高效、簡單易用的數(shù)據(jù)集成方案。具體操作,請參見數(shù)據(jù)導入工具。
豐富的數(shù)據(jù)可視化集成工具:云數(shù)據(jù)庫 SelectDB 版可與MySQL協(xié)議兼容的可視化工具進行無縫對接,大幅提升數(shù)據(jù)開發(fā)、可視化分析的效率。具體操作,請參見數(shù)據(jù)可視化。
聯(lián)邦查詢能力:云數(shù)據(jù)庫 SelectDB 版與外部數(shù)據(jù)湖、數(shù)據(jù)庫進行集成,支持進行數(shù)據(jù)的讀取和寫回,提供湖倉一體的數(shù)據(jù)分析體驗,降低數(shù)據(jù)分析技術棧的資源及維護成本。具體操作,請參見湖倉一體。