使用Spark Structured Streaming實(shí)時(shí)處理Kafka數(shù)據(jù)
本文介紹如何使用阿里云 Databricks 數(shù)據(jù)洞察創(chuàng)建的集群去訪問(wèn)外部數(shù)據(jù)源 E-MapReduce,并運(yùn)行Spark Structured Streaming作業(yè)以消費(fèi)Kafka數(shù)據(jù)。
前提條件
已注冊(cè)阿里云賬號(hào),詳情請(qǐng)參見(jiàn)阿里云賬號(hào)注冊(cè)流程。
已開(kāi)通 E-MapReduce服務(wù)。
已開(kāi)通對(duì)象存儲(chǔ) OSS服務(wù)。
已開(kāi)通 Databricks數(shù)據(jù)洞察服務(wù)。
步驟一:創(chuàng)建Kafka集群和Databricks 數(shù)據(jù)洞察集群
創(chuàng)建Kafka集群。
創(chuàng)建集群,詳情參見(jiàn)創(chuàng)建集群。
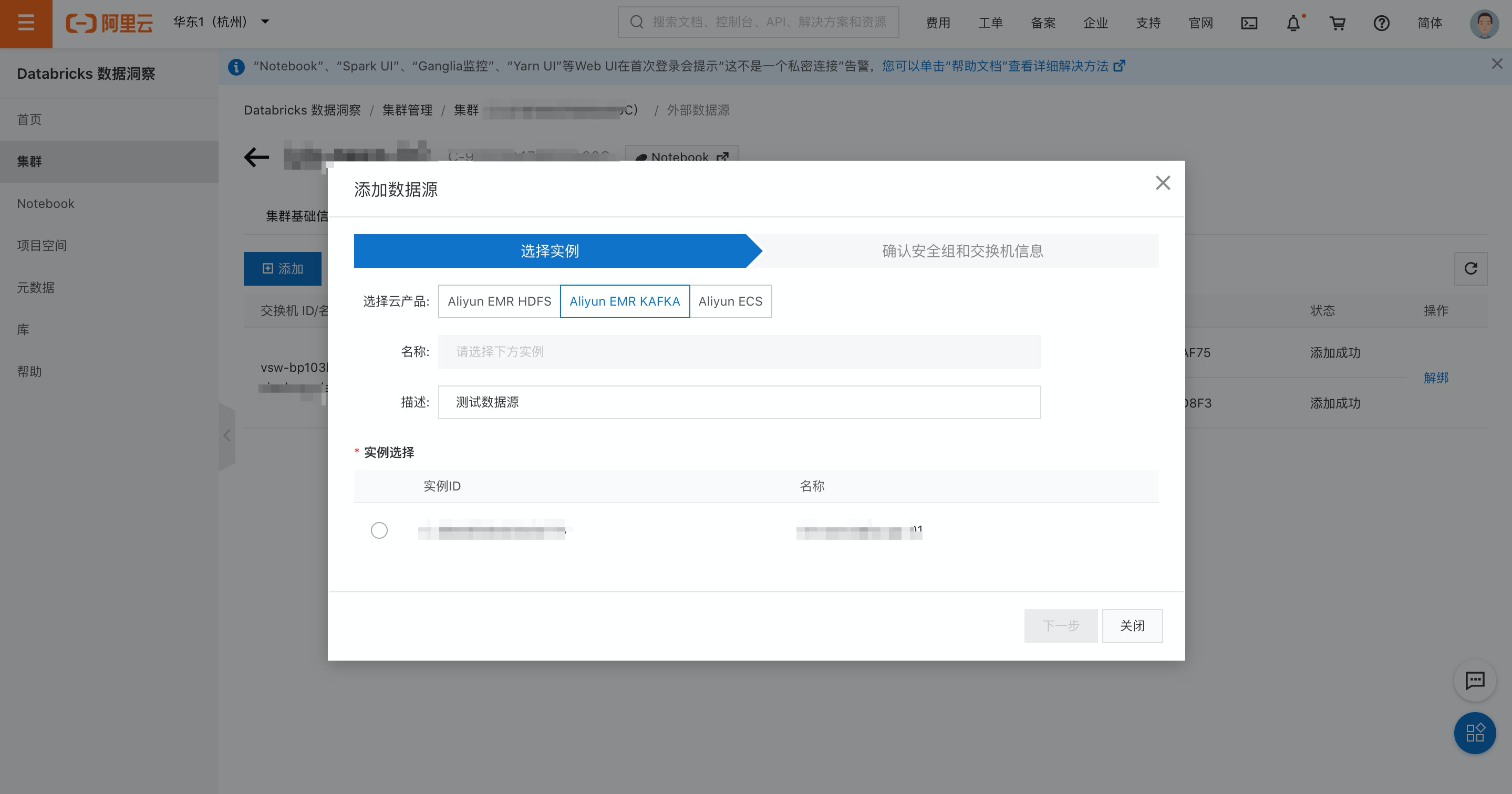
步驟二:Databricks 數(shù)據(jù)洞察集群添加外部數(shù)據(jù)源
單擊左側(cè)集群按鈕,選擇已創(chuàng)建的集群。
進(jìn)入集群詳情頁(yè)面,單擊上方數(shù)據(jù)源按鈕。
在數(shù)據(jù)源頁(yè)面,單擊添加按鈕,選擇Aliyun EMR KAFKA
填入描述,選擇kafka集群。
步驟三:獲取JAR包并上傳到對(duì)象存儲(chǔ) OSS
創(chuàng)建Bucket存儲(chǔ)空間,詳情請(qǐng)參見(jiàn)控制臺(tái)創(chuàng)建存儲(chǔ)空間。
針對(duì)創(chuàng)建Databricks版本請(qǐng)選擇性獲取對(duì)應(yīng)的Jar(DBR7+兼容高版本DBR)。
上傳JAR,詳情請(qǐng)參見(jiàn)控制臺(tái)上傳文件。
步驟四:在Kafka集群上創(chuàng)建Topic
本示例將創(chuàng)建一個(gè)分區(qū)數(shù)為10、副本數(shù)為2、名稱為test的Topic。
登錄Kafka集群的Master節(jié)點(diǎn),詳情請(qǐng)參見(jiàn)登錄集群。
通過(guò)如下命令創(chuàng)建Topic。
/usr/lib/kafka-current/bin/kafka-topics.sh --partitions 10 --replication-factor 2 --zookeeper emr-header-1:2181 /kafka-1.0.0 --topic log_test --create創(chuàng)建Topic后,請(qǐng)保留該登錄窗口,后續(xù)步驟仍將使用。
步驟五:運(yùn)行Spark Structured Streaming作業(yè)
新建項(xiàng)目空間,詳情請(qǐng)參見(jiàn)項(xiàng)目管理。
在所屬項(xiàng)目空間創(chuàng)建作業(yè),詳情請(qǐng)參見(jiàn)管理作業(yè)。
執(zhí)行如下作業(yè)命令,進(jìn)行流式單詞統(tǒng)計(jì)。
--deploy-mode cluster --class demo.action.AppKafkaSparkStreaming oss://xxx/xxx/SparkStreaming-1.0-SNAPSHOT.jar
"oss://your bucket/checkpoint_dir" "192.168.xxx.xxx:9092" "log_test" "oss://your bucket/dataOutputPath"關(guān)鍵參數(shù)說(shuō)明如下:
參數(shù) | 說(shuō)明 |
oss://xxx/xxx/spark-kafka-sample-1.0-SNAPSHOT-jar-with-dependencies.jar | oss對(duì)象存儲(chǔ)上JAR包的位置 |
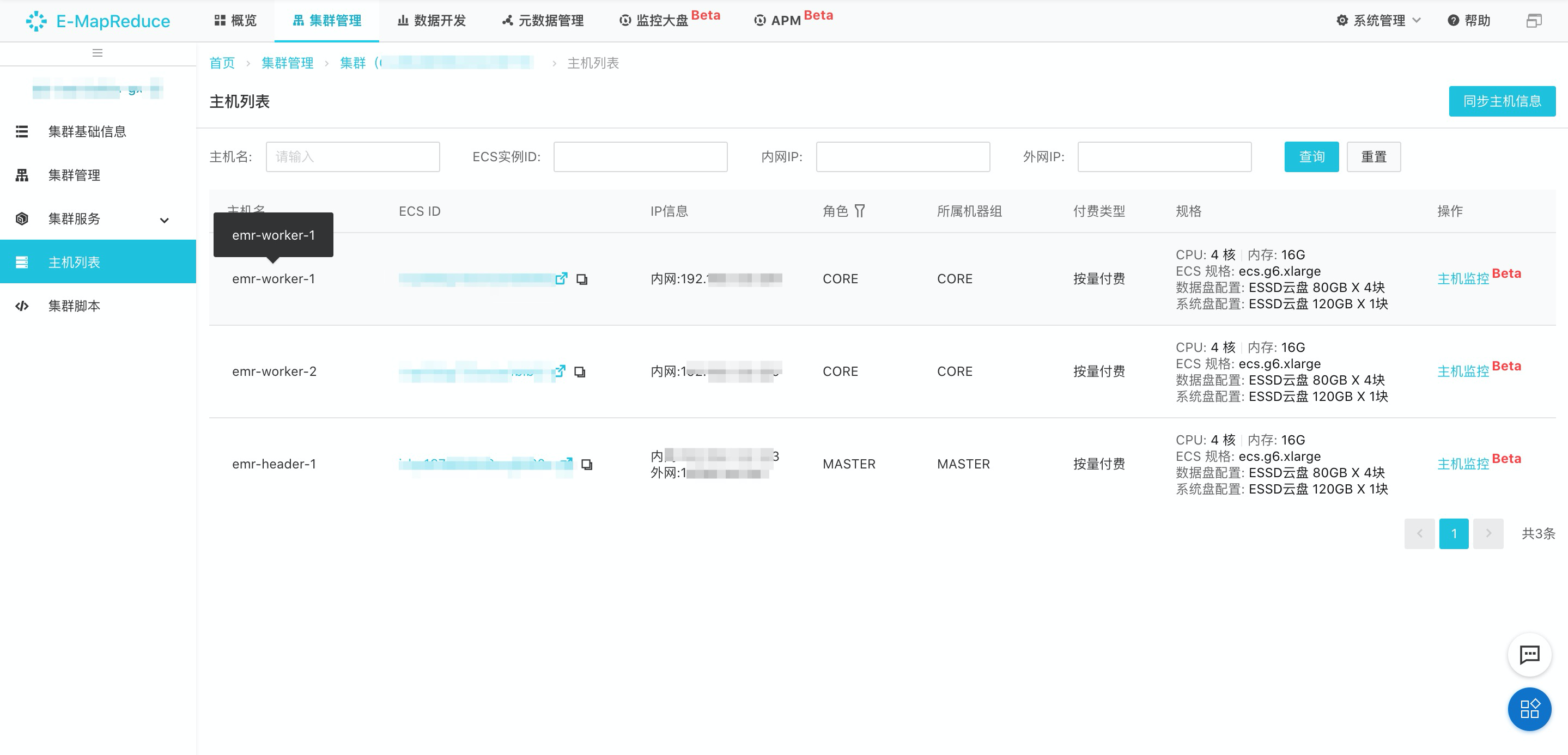
192.168.xxx.xxx:9092 | Kafka集群中任一Kafka Broker組件的內(nèi)網(wǎng)IP地址。IP地址如下圖所示。 |
log_test | Topic名稱 |
oss://your bucket/dataOutputPath | oss對(duì)象存儲(chǔ)上數(shù)據(jù)寫(xiě)入目錄 |
查看Kafka集群IP
步驟六:使用Kafka發(fā)布消息
在Kafka集群的命令行窗口,執(zhí)行如下命令運(yùn)行Kafka的生產(chǎn)者。
#日志結(jié)構(gòu)
40.198.97.68 - - [19/Mar/2021:18:26:12 +0800] "GET /category/office HTTP/1.1" 200 58 "/item/electronics/975" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.7 (KHTML, like Gecko) Chrome/16.0.912.77 Safari/535.7"
104.75.85.35 - - [19/Mar/2021:18:26:12 +0800] "GET /item/networking/4019 HTTP/1.1" 200 118 "-" "Mozilla/5.0 (iPhone; CPU iPhone OS 5_0_1 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A405 Safari/7534.48.3"/usr/lib/kafka-current/bin/kafka-console-producer.sh --topic log_test --broker-list emr-worker-1:9092在命令行中輸入4條數(shù)據(jù)

步驟七:查看Spark作業(yè)執(zhí)行情況
通過(guò)Yarn UI查看Spark Structured Streaming作業(yè)的信息,詳情請(qǐng)參見(jiàn)訪問(wèn)Web UI。
在Hadoop控制臺(tái),單擊作業(yè)的ID。
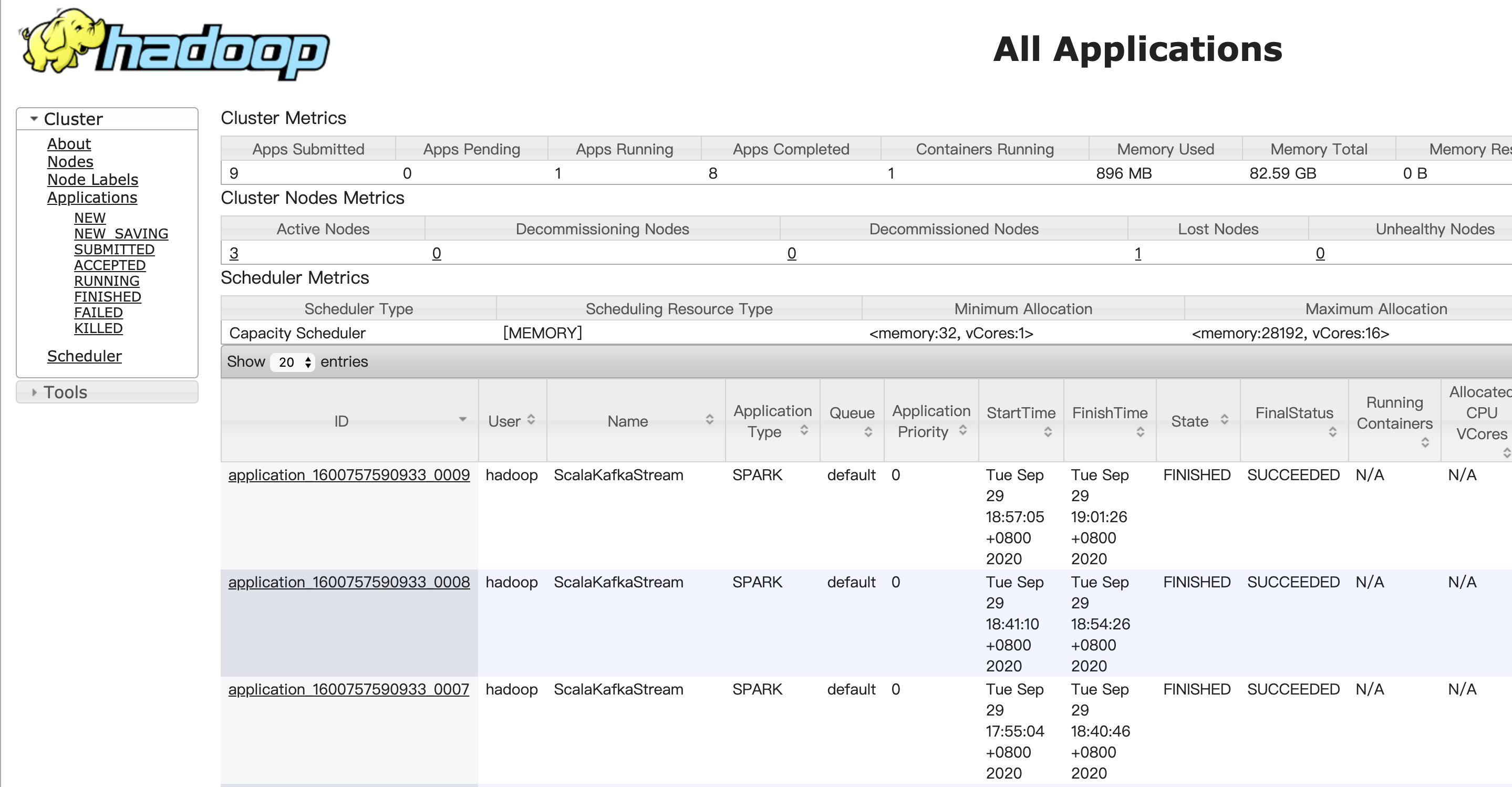
詳細(xì)信息如下。
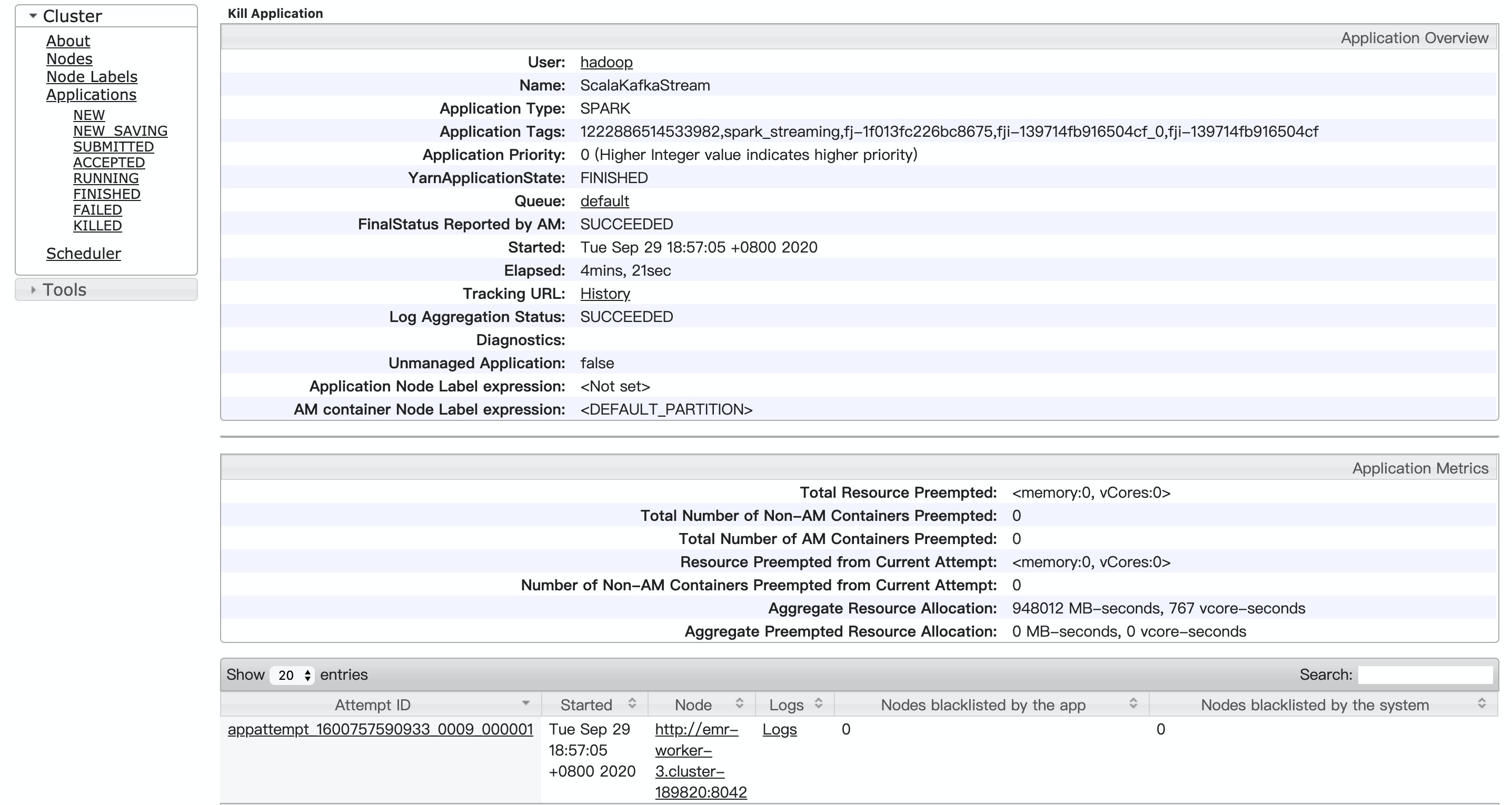
點(diǎn)擊Logs,查看詳細(xì)信息。
步驟八:查看數(shù)據(jù)寫(xiě)入情況
1. 進(jìn)入Databricks 數(shù)據(jù)洞察所在集群的Notebook頁(yè)面,Notebook使用詳情參見(jiàn)(Notebook使用說(shuō)明)
2. 執(zhí)行代碼查詢數(shù)據(jù)的寫(xiě)入情況
%spark
for( i <- 1 to 10 ) {
Thread.sleep(5000)
spark.sql("select count(*) from Delta.`oss://your bucket/dataOutputPath`").show()
}查詢數(shù)據(jù)成功寫(xiě)入4條數(shù)據(jù)