本文主要介紹了什么是部分克隆、使用場景,以及如何使用部分克隆。進而闡述了提升大倉庫體驗的其他方案-Git LFS。
部分克隆功能簡介
什么是部分克隆?
眾所周知,Git是一個分布式的版本控制系統,當在默認情況(例如不帶任何參數情況下使用git clone命令)下克隆倉庫時,Git會自動下載倉庫所有文件的所有歷史版本。
如此設計一方面帶來了分布式的代碼協同能力, 但在另一方面, 隨著開發者持續向倉庫中提交代碼,倉庫的體積會不可避免的變得越來越大, 因為遠端倉庫體積迅速膨脹, 帶來clone后本地后磁盤空間的迅速增長以及clone耗時的不斷增加。Git的部分克隆(partial-clone)特性可以優化和解決這些問題。目前,部分克隆已經在阿里云Codeup上線, 用戶可以試用該功能體驗新特性帶來的研發效率的提升。
部分克隆允許您在克隆代碼倉庫時,通過添加--filter選項來配置需要過濾的對象,從而達到按需下載的目的,這種按需下載大大減少了傳輸的數據量和過程的耗時,同時還可以降低本地磁盤空間的占用。在后續工作中需要用到這些缺失文件的時候,Git會自動地按需下載這些文件,在不必進行任何額外配置的情況下,用戶仍然可以正常開展工作。
部分克隆的適用場景
在許多場景下,都可以用部分克隆來提升您的效率,以幾個典型場景為例:
大倉庫
當倉庫體積較大時,就可以考慮使用部分克隆來提升開發過程中的效率及體驗。例如,Linux的內核,目前有100萬以上的提交,整個倉庫包含了830萬+的對象,體積約在3.3GB左右。
要全量克隆這樣一個倉庫,克隆速度以2MB/s 來算,需要約26分鐘的時間。在網絡條件不佳的情況下,克隆可能還會耗費更久的時間。
$ git clone --mirror gi*@codeup.aliyun.com:6125fa3a03f23adfbed12b8f/linux.git linux
克隆到純倉庫 'linux'...
remote: Enumerating objects: 8345032, done.
remote: Counting objects: 100% (8345032/8345032), done.
remote: Total 8345032 (delta 6933809), reused 8345032 (delta 6933809), pack-reused 0
接收對象中: 100% (8345032/8345032), 3.26 GiB | 2.08 MiB/s, 完成.
處理 delta 中: 100% (6933809/6933809), 完成.下面是開啟部分克隆blob:none選項,使用部分克隆后的效果:
$ git clone --filter=blob:none --no-checkout git@codeup.aliyun.com:6125fa3a03f23adfbed12b8f/linux.git
正克隆到 'linux'...
remote: Enumerating objects: 6027574, done.
remote: Counting objects: 100% (6027574/6027574), done.
remote: Total 6027574 (delta 4841929), reused 6027574 (delta 4841929), pack-reused 0
接收對象中: 100% (6027574/6027574), 1.13 GiB | 2.71 MiB/s, 完成.
處理 delta 中: 100% (4841929/4841929), 完成.可以看到,使用了blob:none選項后,需要下載的對象由834萬左右減少至602萬左右,需要下載的數據量更是由3.26GB下降到了1.13GB,還是以2MB/s速度來計算,部分克隆時間僅需9分鐘左右,與原來的全量克隆相比,時間僅為原來的三分之一左右。
如果使用treeless模式的部分克隆,需要下載的對象、耗費的時間還將進一步減少。但是,treeless模式的克隆在開發場景下會更加頻繁地觸發缺失對象的下載,不推薦使用。使用部分克隆,花費了更少的時間,克隆了更少的對象,帶來的優化是顯著的。
微服務單根代碼倉
近年來,越來越多項目選擇了使用微服務的架構,將大單體服務拆分為若干個內聚化的微型服務,每一個服務由一個微型團隊進行維護,團隊間開發可以并行、互不干擾,團隊間協同復雜度大幅降低。但是,這也將帶來公用代碼更難重用、不同倉庫之間依賴混亂、團隊之間流程規范難以協同等問題。
因此,微服務單根代碼倉模式被提出,在這種模式下,子服務使用Git來進行管理,并且由一個根倉庫來統一管理所有的服務:
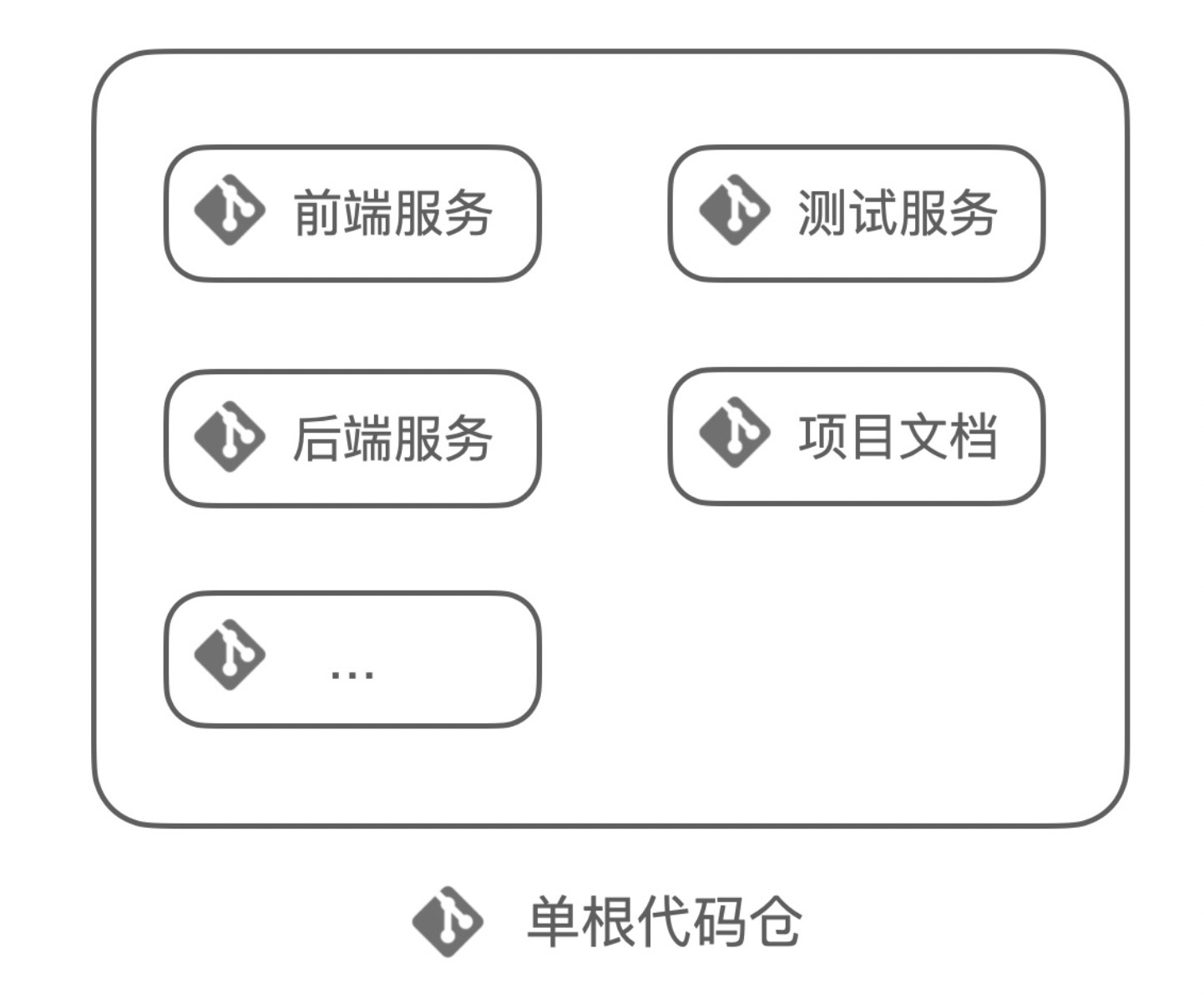
使用單根代碼倉,公用代碼更易于共享,項目文檔、流程規范可以集中于一處,也更加易于實施持續集成。但是,這種模式也有缺點,對于一名開發者來說,即使他只關注項目中某一部分,他也不得不克隆整個倉庫。
部分克隆配合稀疏檢出特性,可以解決這一問題,可以首先啟用部分克隆,并指定--no-checkout選項來指定克隆完成后不執行自動檢出,避免檢出時自動下載當前分支下的所有文件。之后,再通過稀疏檢出功能,只按需下載并檢出指定目錄下的文件。
例如,創建了一個項目,具有如下結構:
monorepo
├── README
├── backend
│ └── command
│ └── command.go
├── docs
│ └── api_specification
├── frontend
│ ├── README.md
│ └── src
│ └── main.js
└── libraries
└── common.lib現在,作為一名后端開發人員,我只關心backend下的代碼,并且也不想花費時間下載其他目錄下的代碼,那么就可以執行:
$ git clone --filter=blob:none --no-checkout https://codeup.aliyun.com/61234c2d1bd96aa110f27b9c/monorepo.git
正克隆到 'monorepo'...
remote: Enumerating objects: 24, done.
remote: Counting objects: 100% (24/24), done.
remote: Total 24 (delta 0), reused 0 (delta 0), pack-reused 0
接收對象中: 100% (24/24), 2.62 KiB | 2.62 MiB/s, 完成.然后,進入該項目,開啟稀疏檢出,并配置為只下載backend下的文件:
$ cd monorepo
$ git config core.sparsecheckout true
$ echo "backend/*" > .git/info/sparse-checkout最后執行git checkout,并執行tree命令觀察目錄結構。可以看到,只有backend目錄下的文件被下載了。
$ tree .
.
└── backend
└── command
└── command.go
2 directories, 1 file應用構建
在構建場景下,構建服務器首先需要從Git倉庫獲取代碼,并執行構建,最后發布應用。在構建的過程中,并不需要倉庫中的歷史代碼,而是根據代碼的最新版本來構建應用。此時,可以用部分克隆的tree:0選項,最大程度減少需要下載的對象數量。
對于構建場景來說,還可以使用Git淺克隆特性,進一步的過濾歷史的commit對象。關于Git淺克隆,請參考git-clone。
部分克隆使用及原理簡介
Git底層對象類型簡介
在使用部分克隆前,還需要了解一些Git的底層存儲原理,以便更好地理解各個選項的含義,主要涉及blob對象,tree對象,以及commit對象。
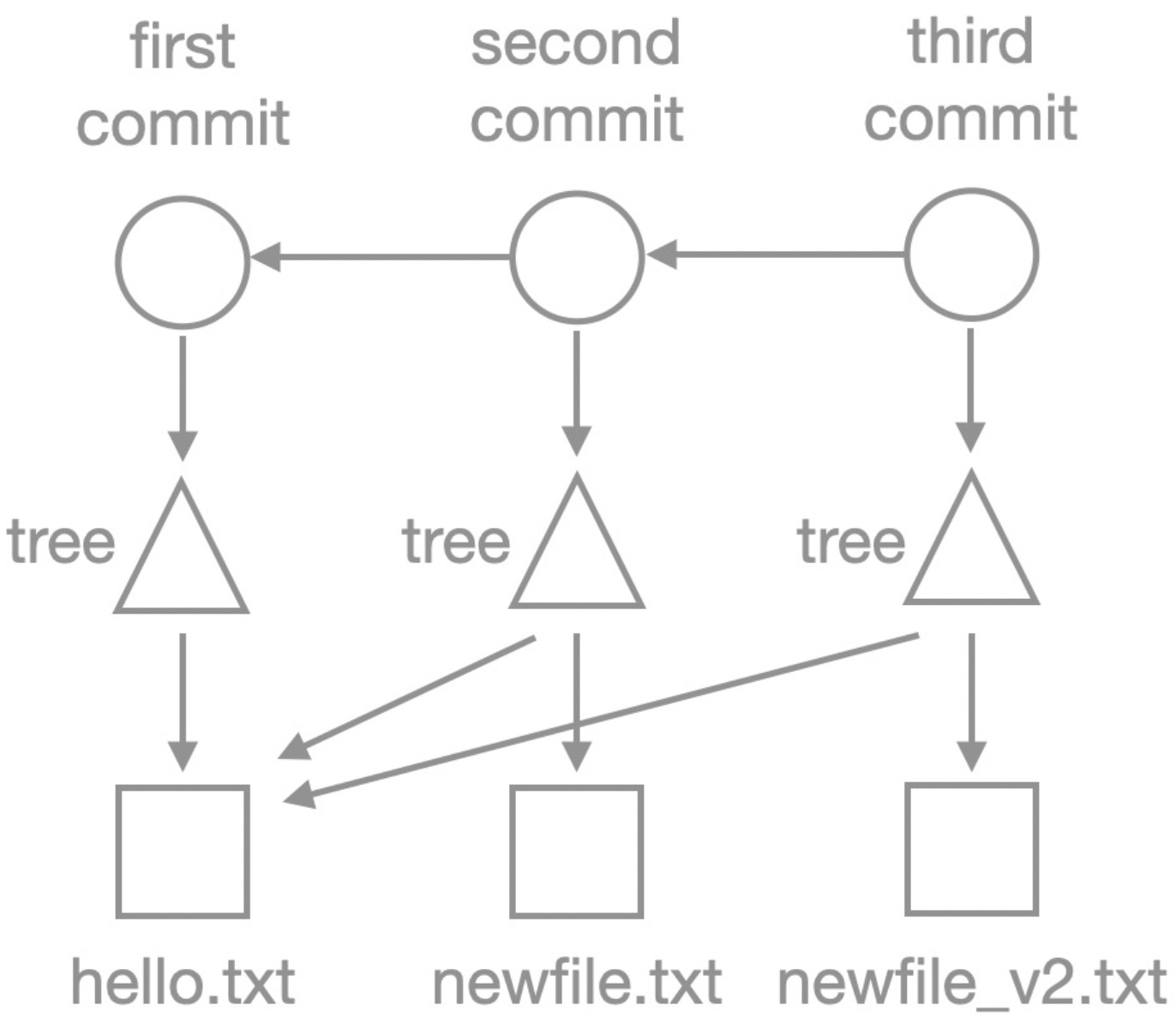
下圖以Git底層對象的形式,展示了一個Git倉庫的結構。其中:
圓形,代表了
commit對象,commit對象用于存儲提交信息,并指向了父commit(如果存在)以及根tree對象。通過commit對象,我們可以回溯代碼的歷史版本。三角形,代表一個
tree對象,tree對象用于存儲文件名及目錄結構信息,并且指向blob對象或其他tree對象,由此組成嵌套的目錄結構。方塊,代表了
blob對象,存儲了文件的實際內容。
部分克隆使用限制
客戶端限制:本地的Git版本在2.22.0或更高。
服務端filter限制:目前,Codeup支持指定兩種
--filter。Blobless克隆:
--filter=blob:none。Treeless克隆:
--filter=tree:<depth>。
在本地客戶端支持的情況下,就可以使用部分克隆來提升研發效率了。
如何使用部分克隆
要使用部分克隆,有如下幾種方式:
使用 git clone 命令創建部分克隆:
git clone --filter=blob:none <倉庫地址>使用 git fetch 命令創建部分克隆
git init . git remote add origin <倉庫地址> git fetch --filter=blob:none origin git switch master使用 git config 設置項目成為部分克隆
git init . git remote add origin <倉庫地址> git config remote.origin.promisor true git config remote.origin.partialclonefilter blob:none git fetch origin git switch master
這三種方式達到效果是一樣的,您可以自行選擇喜歡的方式。下面,我們用git clone的方式來分別介紹blobless克隆和treeless克隆的使用以及基本原理。
Blobless克隆
在克隆時使用--filter=blob:none選項,即可開啟blobless模式克隆。在這種情況下,倉庫中歷史commit、tree會被下載,blob則不會。下面用一個例子來更好地說明使用此選項克隆時倉庫的結構。
首先,創建一個測試倉庫。
在第一個提交中,創建文件hello.txt,內容為hello world!。
在第二個提交中,創建文件src/hello.go,內容為打印"hello world"。
在第三個提交中,修改文件src/hello.go,修改輸出內容為“hello codeup"。
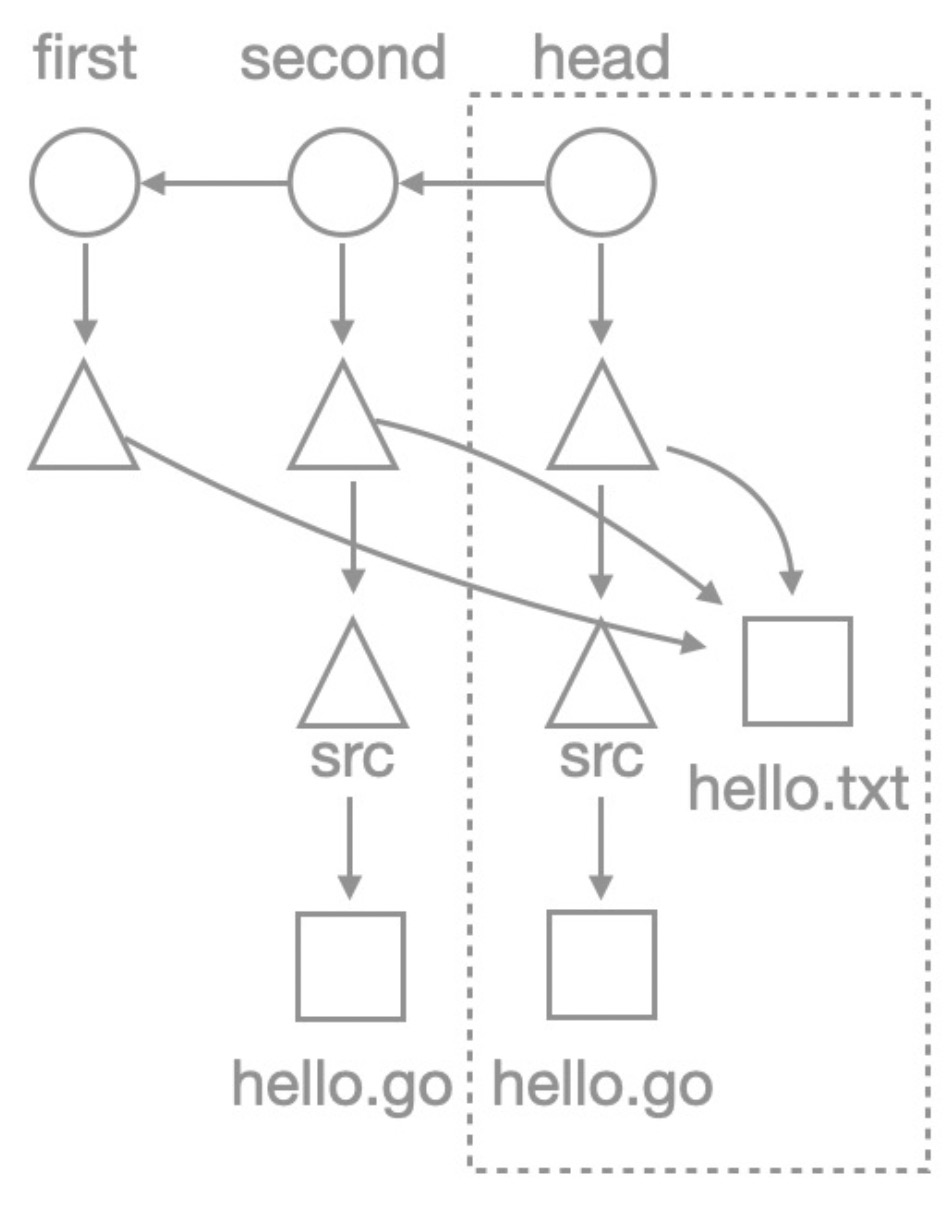
整個倉庫結構看起來像是這樣:
然后,執行以下命令,來執行一次blobless模式的部分克隆
git clone --filter=blob:none \
https://codeup.aliyun.com/61234c2d1bd96aa110f27b9c/partial-clone-tutorial.git克隆完成后,進入此倉庫,并執行git rev-list命令來檢視倉庫中的對象,得到輸出為:
$ git rev-list --missing=print --objects HEAD
18990720b6e55a70ba9f9877213dad948e0973a2
e18cc4e7890e6ec832f683c1a0f58412b4a37964
2f7478bda13e73e1e1eaab6fae3d0dfd35e50b32
e7c719df0874ebd3b2ec02666d65879e986d537d
a0423896973644771497bdc03eb99d5281615b51 hello.txt
98a390b9c8b5ba25e9444c8b5a487634795d7c72 src
02a9d16faa87c68bd6fc2af27cbe3714e53af272 src/hello.go
b7458566de2bf5e1011142ef5fe81ccaa4c9e73e
3f2157b609fb05814ba0a45cf40a452640e663c3 src
6009101760644963fee389fc730acc4c437edc8f
?f2482c1f31b320e28f0dea5c4e7c8263a0df8fec注意最后一行ID,第一個字符是問號,這也就意味著這個對象在本地其實是不存在的。為什么會出現這種情況呢?其實這正是部分克隆所要達到的效果。
下面來看看f2482c1f31b320e28f0dea5c4e7c8263a0df8fec這個對象是什么,執行:
$ git cat-file -p f2482c1f31b320e28f0dea5c4e7c8263a0df8fec
remote: Enumerating objects: 1, done.
remote: Counting objects: 100% (1/1), done.
remote: Total 1 (delta 0), reused 0 (delta 0), pack-reused 0
接收對象中: 100% (1/1), 109 字節 | 109.00 KiB/s, 完成.
package main
import "fmt"
func main() {
fmt.Println("hello world")
}第五行,接收對象意味著這個對象實際上是剛被下載下來的,其中內容為fmt.Println("hello world"),也就是第二個提交的版本。
通過以上分析,可以知道,使用部分克隆blob:none選項克隆倉庫后,只有第二個提交中的hello.go文件不存在。
將圖形上色,空心代表對象不存在,實心代表對象存在,那么倉庫結構可以表示成這個樣子:
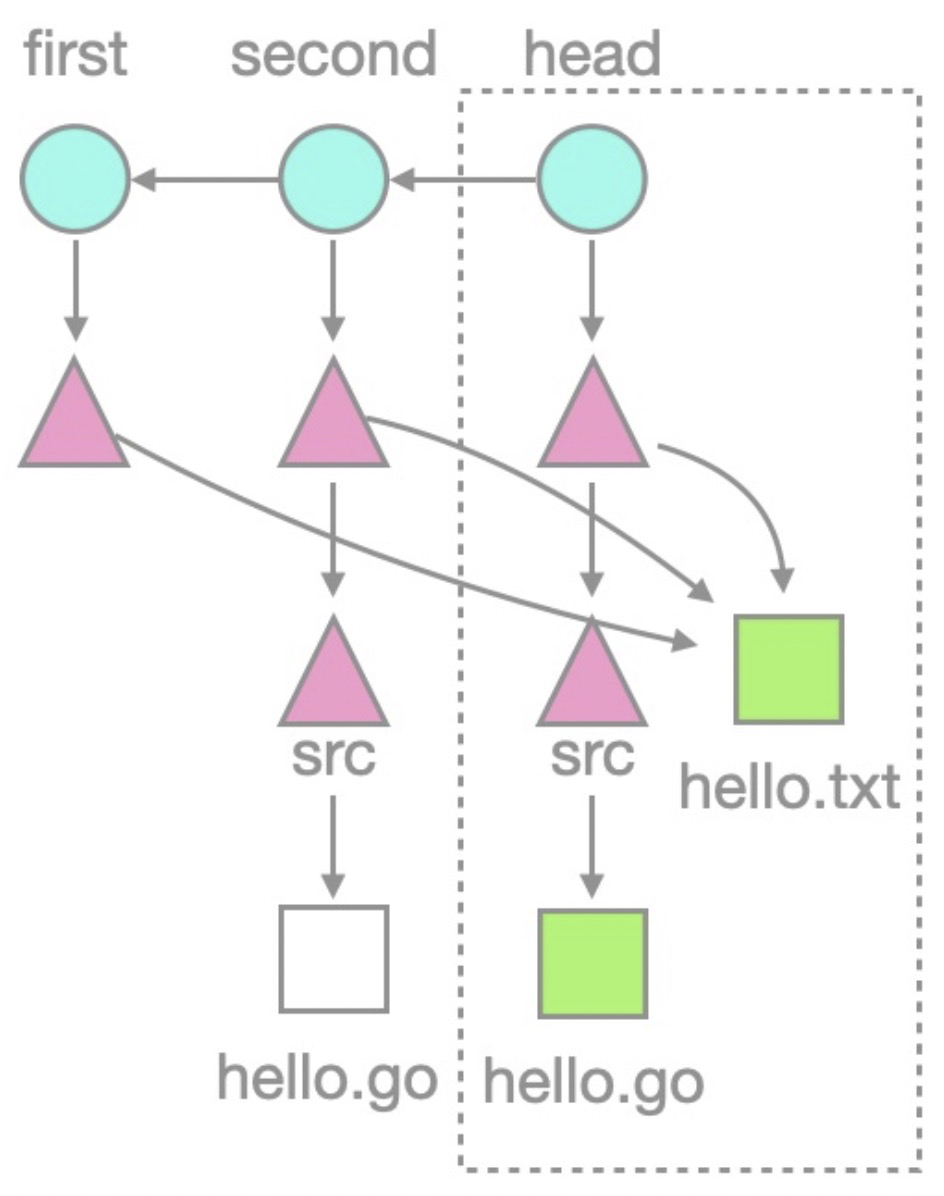
可以看到,倉庫中歷史commit、tree對象都存在,歷史blob對象則不存在。把這個觀察推廣到更復雜一些的倉庫,就可以總結出以blobless模式克隆倉庫的一般形式:
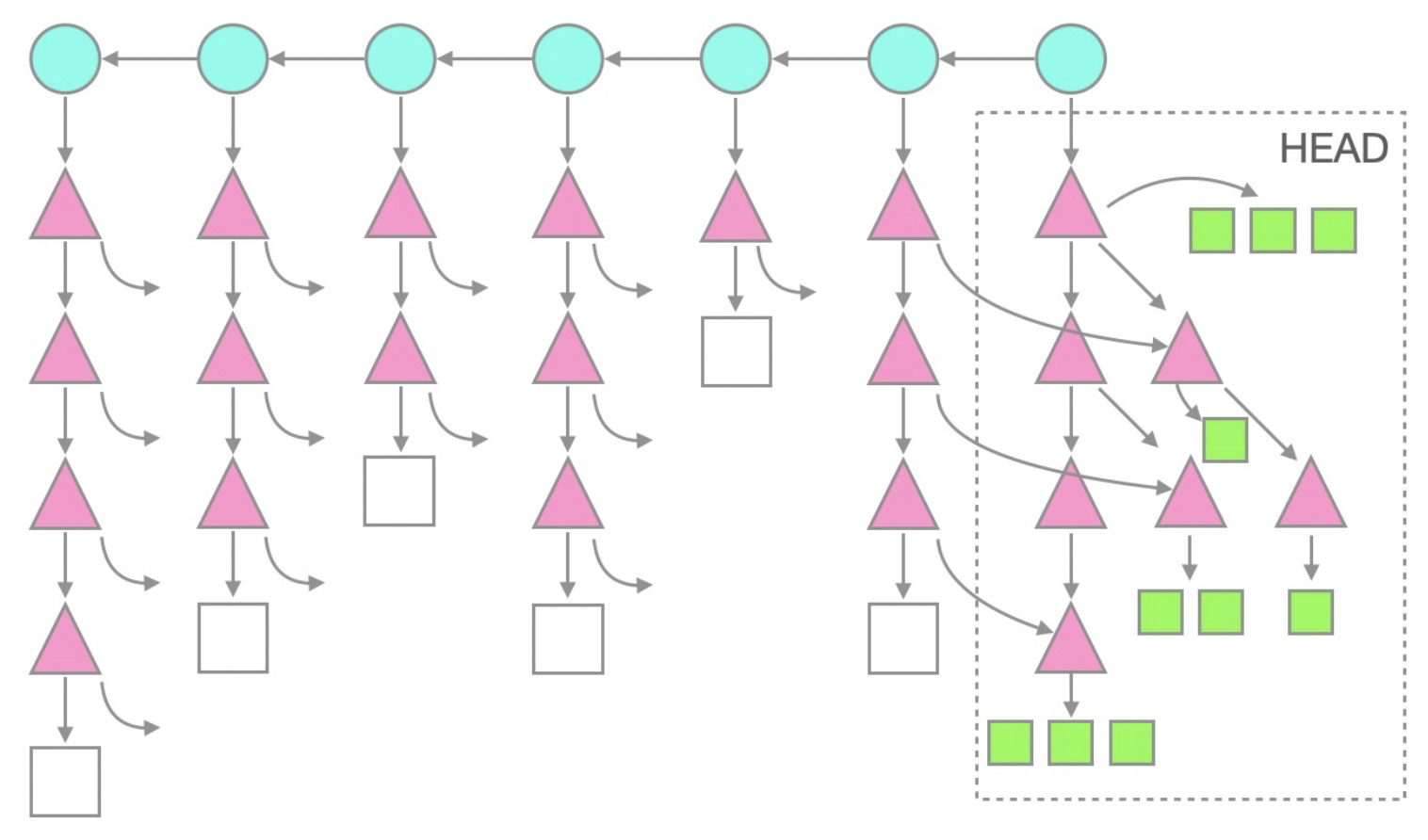
需要注意的是,在當前HEAD分支下,所有的tree和blob對象都存在,這是由于在克隆之后自動執行了一次檢出。在此基礎之上,可以修改,提交代碼,展開工作。對于歷史提交來說,commit和tree對象都存在,僅有blob對象未被下載。通過不下載這些歷史blob對象,達到了節省克隆時間,節省磁盤占用空間的目的。
如果此時檢出歷史提交,那么Git客戶端會自動地批量下載這些缺失的blob對象。此外,當需要使用到文件內容時,就會觸發blob下載,當只需要文件的OID時,就不需要了。這也就意味著可以運行git merge-base、git log等命令,性能與完全克隆模式相同。
Treeless克隆
在克隆時使用--filter=tree:<depth>選項,就開啟了無tree克隆,其中depth是一個數字,代表了從commit對象開始的深度。在這種模式下,只有給定深度內的tree以及blob對象會被下載。
回到測試倉庫,這次利用--filter=tree:0來啟用treeless克隆,并用rev-list來檢視本地對象:
$ git clone --filter=tree:0 \
https://codeup.aliyun.com/61234c2d1bd96aa110f27b9c/partial-clone-tutorial.git
$ cd partial-clone-tutorial
$ git rev-list --missing=print --objects HEAD
18990720b6e55a70ba9f9877213dad948e0973a2
e18cc4e7890e6ec832f683c1a0f58412b4a37964
2f7478bda13e73e1e1eaab6fae3d0dfd35e50b32
e7c719df0874ebd3b2ec02666d65879e986d537d
a0423896973644771497bdc03eb99d5281615b51 hello.txt
98a390b9c8b5ba25e9444c8b5a487634795d7c72 src
02a9d16faa87c68bd6fc2af27cbe3714e53af272 src/hello.go
?b7458566de2bf5e1011142ef5fe81ccaa4c9e73e
?6009101760644963fee389fc730acc4c437edc8f現在問號出現在兩個對象ID前,來看看這些對象是什么:
$ git cat-file -p HEAD^^
tree 6009101760644963fee389fc730acc4c437edc8f
author yunhuai.xzy <yunhuai.***@alibaba-inc.com> 1631697940 +0800
committer yunhuai.xzy <yunhuai.***@alibaba-inc.com> 1631697940 +0800
first commit$ git cat-file -p HEAD^
tree b7458566de2bf5e1011142ef5fe81ccaa4c9e73e
parent 2f7478bda13e73e1e1eaab6fae3d0dfd35e50b32
author yunhuai.xzy <yunhuai.***@alibaba-inc.com> 1631698032 +0800
committer yunhuai.xzy <yunhuai.***@alibaba-inc.com> 1631698032 +0800
add hello.go注意其中第二行,可以發現b74585和b74585這兩個對象,正好是第一第二個提交所指向的根樹。畫出倉庫結構如下:
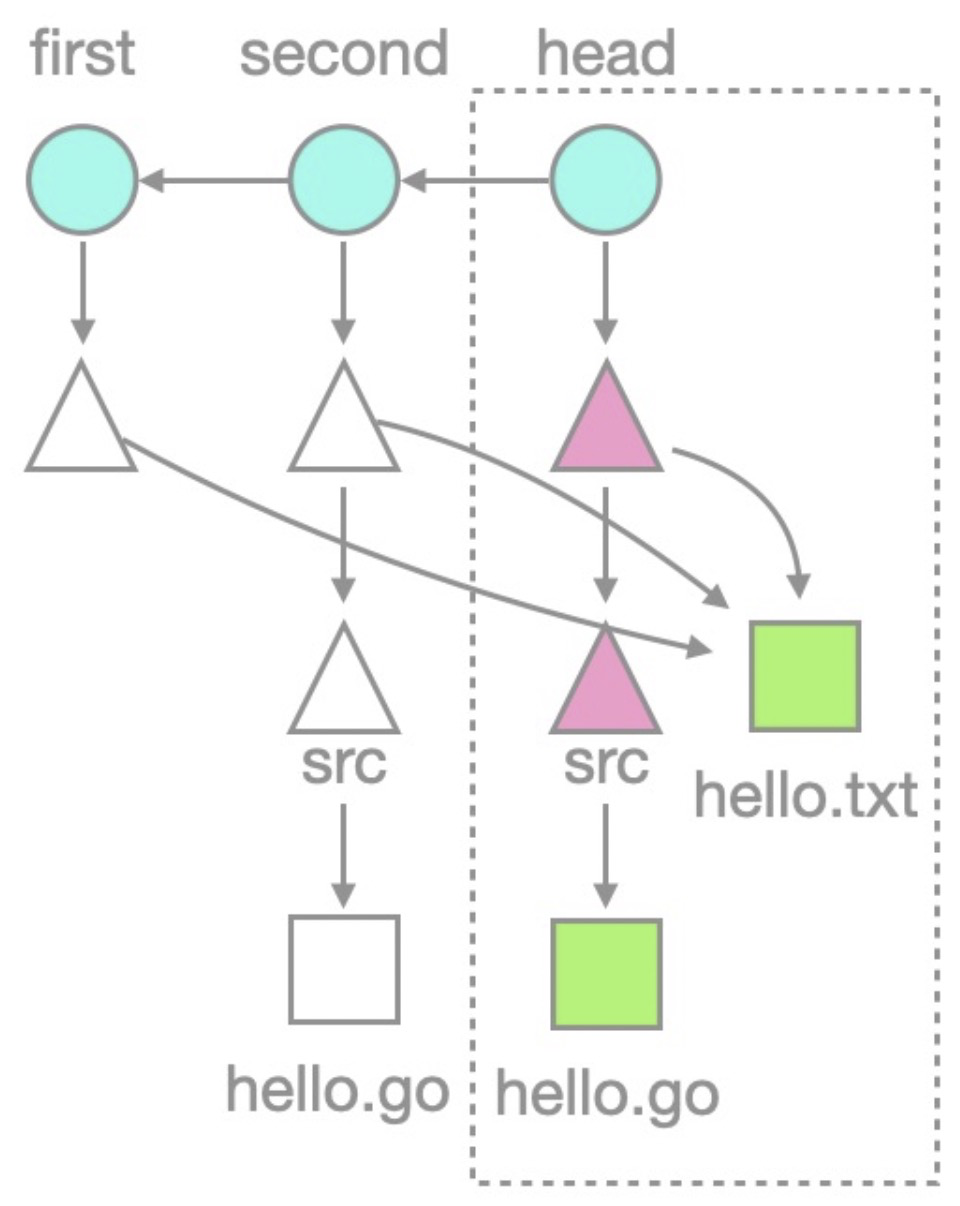
推廣到更一般的Git倉庫,則如下圖所示:
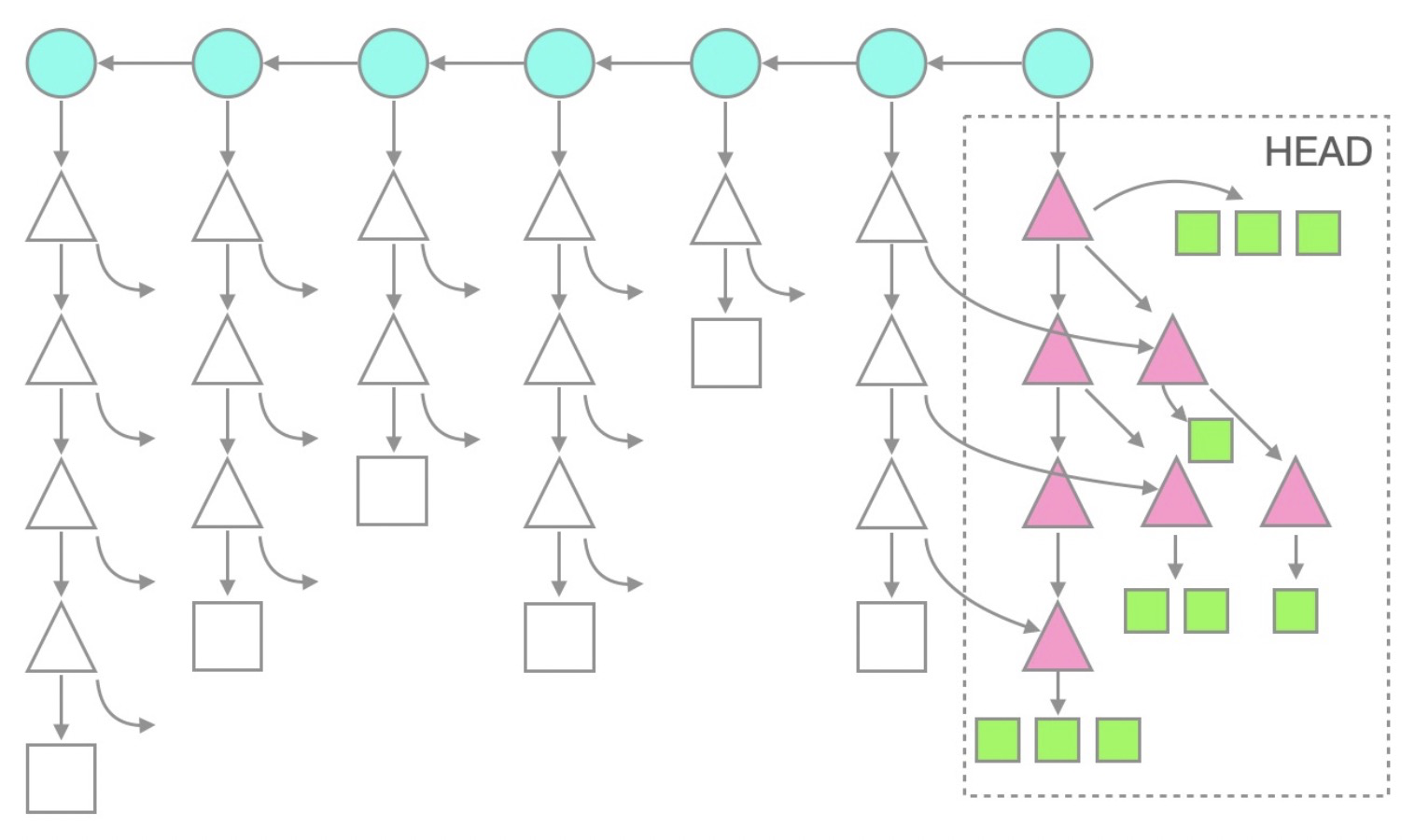
可以看到,擁有所有提交信息,以及在HEAD分支下的所有對象(還是由于自動檢出),但不包含任何歷史提交中的tree和blob。
與blobless模式相比,treeless模式需要下載的對象更少了,克隆時間會更短,磁盤占用空間也會更少。但是在后續工作中,treeless模式的克隆會更加頻繁的觸發數據的下載,并且代價也更為昂貴。例如,Git客戶端會向服務端請求一顆樹及其所有的子樹,在這個過程中,客戶端不會告訴服務端本地已有一些樹,服務端不得不把所有的樹都發送給客戶端,然后客戶端可以對缺失的blob對象發起批量請求。
為了更好理解treeless克隆,下圖是一個使用了--filter=tree:1選項的例子。可以看到,深度為1的tree對象也被下載了,更深的tree或者blob對象則沒有。
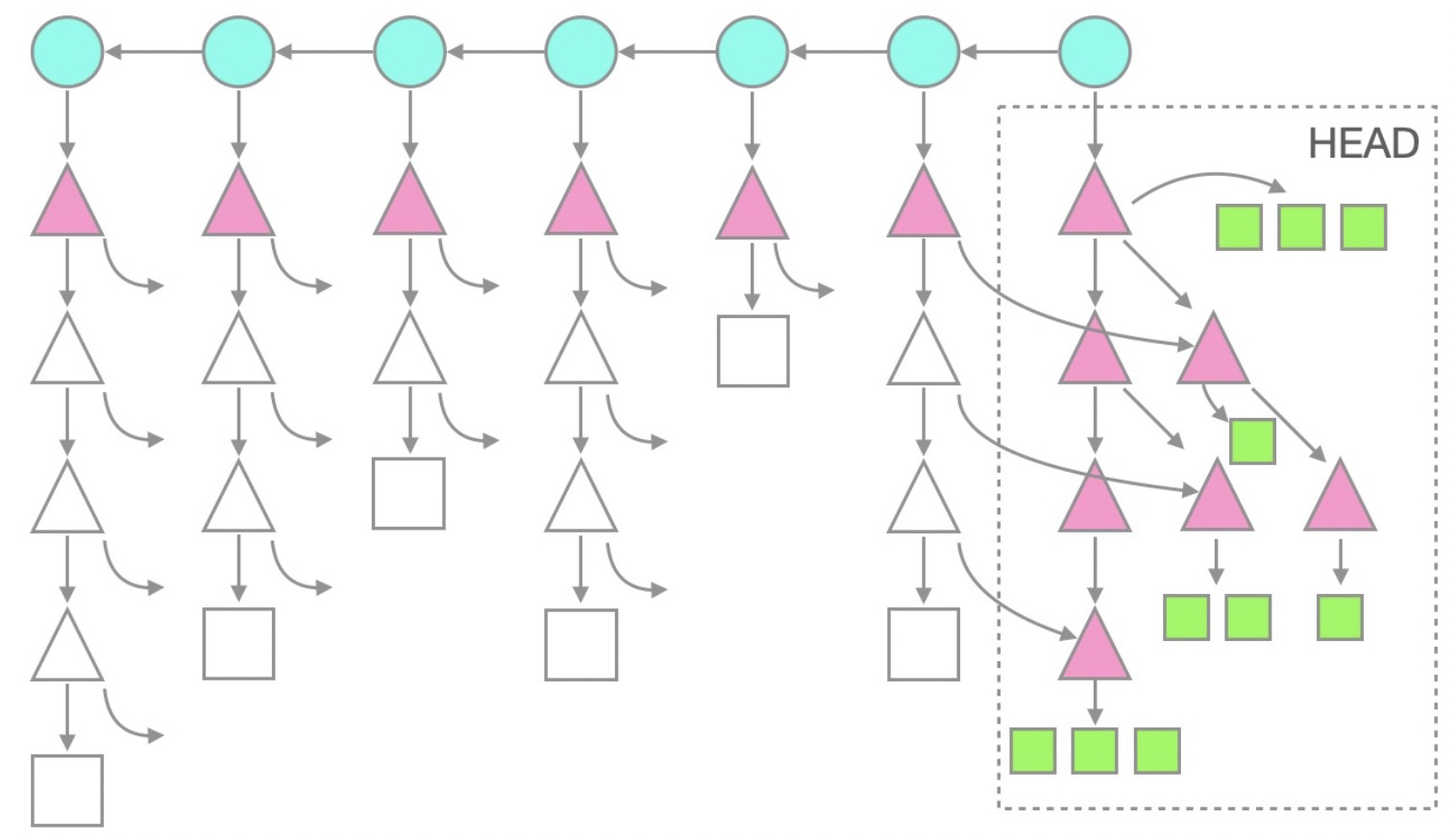
在日常開發過程中,不建議使用treeless模式的克隆,treeless克隆更加適用于自動構建的場景,快速的克隆倉庫,構建,然后刪除。
部分克隆的其他選項
部分克隆還可以使用其他選項,完整選項請參考https://git-scm.com/docs/git-rev-list中的--filter=<filter-spec>節,正在逐步支持其他選項。
部分克隆的性能陷阱
部分克隆通過只下載部分數據方式,在首次克隆時減輕了需要傳輸的數據量,降低了克隆需要的時間。但是,在后續過程中如果需要使用到這些歷史數據,就會觸發對象的按需下載。根據執行的命令不同,性能可能好也可能壞。
命令 | 性能 | 說明 |
| 好 | 這些命令支持批量下載缺失的對象,因此性能很好。 |
| 不好 | 這些命令會逐一下載需要的對象,性能很差。 |
另外,在執行git rev-parse --verify "<object-id>^{object}"命令校驗某個對象是否存在的時候,如果該對象在倉庫中不存在,會執行git fetch對該對象按需獲取。如果這個缺失對象是一個提交對象,則獲取過程會將該提交關聯的所有歷史提交、樹對象等都重新下載,即使很多歷史提交已經在倉庫中了。這是因為部分倉庫按需獲取過程中執行git fetch命令使用了-c fetch.negotiationAlgorithm=noop參數,沒有在客戶端和服務器之間進行提交信息的協商。
如何避免性能問題
git clone、git checkout、git switch、git archive、git merge、git reset等命令支持對缺失對象的批量下載,因此性能很好。
其他不支持批量下載的命令可以用如下方式優化:
找到需要訪問且在倉庫中缺失的對象。
啟動
git fetch進程,通過標準輸入傳遞缺失對象列表,批量下載缺失對象。
那么如何查找缺失對象呢?可以使用git rev-list命令,通過參數--missing=print顯示缺失對象,缺失對象在打印時會以問號開頭。
如下命令顯示v1.0.0和v2.0.0之間缺失的對象:
git rev-list --objects --missing=print v1.0.0..v2.0.0 | grep "^?"將獲取到的缺失對象列表通過管道傳遞給下面的git fetch進程,實現缺失對象的批量獲取:
git -c fetch.negotiationAlgorithm=noop \
fetch origin \
--no-tags \
--no-write-fetch-head \
--recurse-submodules=no \
--filter=blob:none \
--stdin提升大倉庫體驗的其他方案
Git LFS(大文件存儲)
除了部分克隆,Codeup 同時提供 Git LFS 大文件存儲能力。關于Git LFS,請參考Git-LFS 大文件存儲。
部分克隆與Git LFS的異同
方案 | 目標 | 應用場景 | 實現機制 | 優點 | 缺點 |
部分克隆 | 主要解決由于倉庫歷史較長或文件數量龐大導致的倉庫體積增大問題。 | 適用于倉庫歷史較長或文件數量較多的情況,特別是只需要代碼最新版本的場景。 | 通過在克隆倉庫時設置過濾器選項,只下載特定的歷史對象或文件,減少克隆時的傳輸流量和本地磁盤占用。 |
| 可能會導致某些歷史記錄不完整,影響回溯和調試。 |
Git LFS | 主要解決向Git倉庫中提交大量二進制文件導致的倉庫體積膨脹問題。 | 適用于需要管理大量二進制文件(如圖片、視頻、音頻、設計資源等)的倉庫。 | 通過將大文件替換為指針文件存儲在倉庫中,實際的大文件則存儲在第三方服務器上。在檢出分支時,指針文件會被替換為實際文件。 |
|
|
部分克隆與大文件存儲也不是割裂的,可以結合使用,以達到更好的代碼協同體驗。例如,使用部分克隆來減少歷史對象的下載,同時使用Git LFS來管理大文件。Codeup對這兩個特性都進行了支持,您可以根據實際情況合理選擇和結合使用部分克隆和Git LFS,以有效優化大型倉庫的管理和使用體驗。