使用Spark計算引擎訪問表格存儲時,您可以通過E-MapReduce SQL或者DataFrame編程方式對表格存儲中數據進行復雜的計算和高效的分析。
應用場景

功能特性
對于批計算,除了基礎功能外,Tablestore On Spark提供了如下核心優化功能:
索引選擇:數據查詢效率的關鍵在于選擇合適的索引方式,根據過濾條件選擇最匹配的索引方式增加查詢效率。表格存儲的索引方式可選全局二級索引或者多元索引。
說明全局二級索引和多元索引的更多信息請參見海量結構化數據存儲技術揭秘:Tablestore存儲和索引引擎詳解。
表分區裁剪:根據過濾條件進行邏輯分區(Split)的細化匹配,提前篩選出無效的Split,降低服務端的數據出口量。
Projection和Filter下推:將Projection列和Filter條件下推到服務端,降低每個分區的數據出口量。
動態指定Split大小:支持調整每個邏輯分區(Split)中的數據量和分區數,每個Split會和RDD(Resilient Distributed DataSet)的Partition綁定,可用于加速Spark任務的執行。
說明通過ComputeSplitsBySize接口可以獲取邏輯分區(Split),該接口將全表數據在邏輯上劃分成若干接近指定大小的分片,并返回這些分片之間的分割點以及分片所在機器的提示。一般用于計算引擎規劃并發度等執行計劃。
對于流計算,基于通道服務,利用CDC(數據變更捕獲)技術完成Spark的mini batch流式消費和計算,同時提供了at-least-once一致性語義。在流計算中每個分區和RDD的Partition一一綁定,通過擴展表的分區,可以完成數據吞吐量的線性擴展。
場景案例
使用方式
根據業務場景可以選擇通過E-MapReduce SQL或者DataFrame編程方式使用Spark訪問表格存儲。
E-MapReduce SQL方式
此方式使用標準的SQL語句進行業務數據操作和訪問,操作便捷,可以將已有的業務邏輯進行無縫遷移。
DataFrame方式
此方式需要一定的編程基礎,但可以組合實現復雜的業務邏輯,適用于比較復雜和靈活的場景。
數據訪問方式
表格存儲為Spark批計算提供KV查詢(數據表或全局二級索引)和多元索引查詢兩種數據訪問方式,以支持海量結構化數據快速讀寫和豐富的查詢分析能力。
兩種數據訪問方式的區別如下:
KV查詢方式在過濾字段是主鍵的場景下效率較高,但不適合過濾字段變動較大且過濾字段中非主鍵列較多的場景,KV查詢方式也不支持地理位置查詢。
多元索引查詢方式適用于如下數據訪問場景:
說明多元索引基于倒排索引和列式存儲,可以解決大數據的復雜查詢難題,提供類似于ElasticSearch的全文檢索、模糊查詢、地理位置查詢、統計聚合等查詢和分析功能。
少量且對延時要求較高的實時數據分析場景。
非主鍵的過濾字段較多,過濾字段無法被全局二級索引主鍵或者數據表主鍵包含。
過濾字段的篩選效率較高,可以通過某一字段條件過濾掉大部分數據。
例如
select * from table where col = 1000;中,col是非主鍵列,且col = 1000字段條件可以過濾掉大部分數據。查詢條件中包含地理位置查詢。
結合下圖以select * from table where col1 like '阿%' or col2 = 'a';SQL語句為例介紹兩種查詢方式的使用樣例。
通過多元索引方式訪問數據時,在多元索引的col1中可以獲取col1的值為'阿%'的一行數據pk1 = 1,在多元索引的col2中可以獲取col2的值為'a'的兩行數據pk1 = 1和pk1 = 2,然后將兩次中間結果的數據進行union,即可得到滿足條件的數據
pk1 = 1,col1 = '阿里云',col2 = 'a'。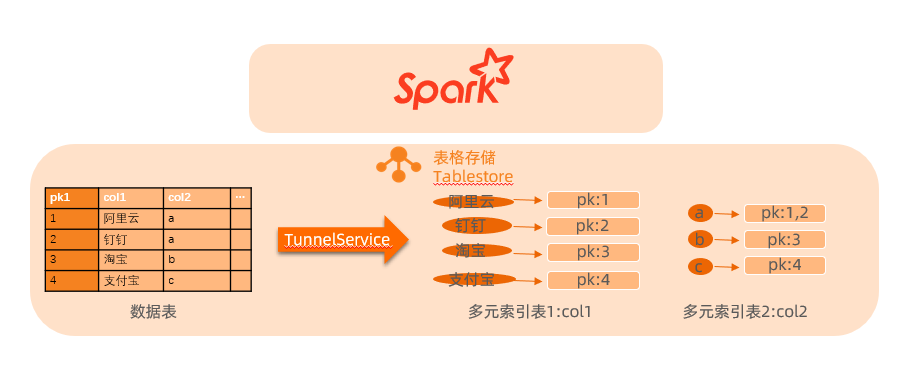
通過KV查詢方式訪問數據時,查詢主體是表格存儲的數據表,數據表只能通過主鍵查詢。如果查詢的SQL語句中的過濾字段不是數據表的主鍵,則需要進行全表掃描。
由于col1不是數據表的主鍵,表格存儲會進行全表掃描找到col1的值為'阿%'的一行數據;由于col2不是數據表的主鍵,表格存儲會再次進行全表掃描找到col2的值為'a'的兩行數據,然后將兩次中間結果的數據進行union。
此時也可以通過構建一個主鍵為col1、col2的索引表支持該查詢,但此種方式的靈活性較低。