本文中含有需要您注意的重要提示信息,忽略該信息可能對您的業務造成影響,請務必仔細閱讀。
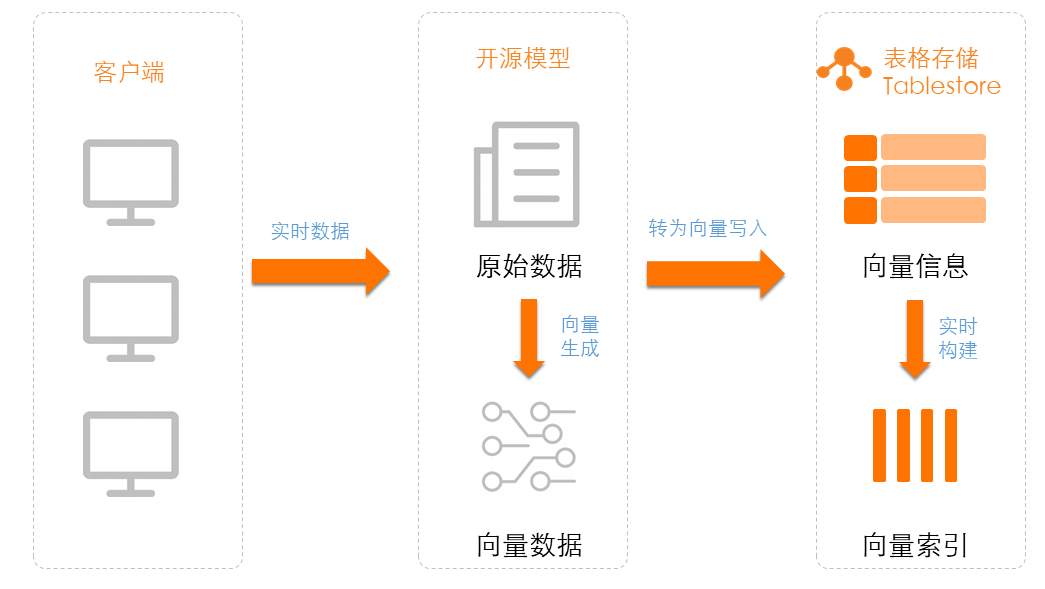
本文介紹如何將存儲在 Tablestore 中的文本數據通過開源模型生成向量。
方案概覽
ModelScope(魔搭社區)旨在打造下一代開源的模型即服務共享平臺,為泛 AI 開發者提供靈活、易用、低成本的一站式模型服務產品,讓模型應用更簡單。ModelScope 魔搭社區匯集行業領先的預訓練模型,減少開發者的重復研發成本,提供更加綠色環保、開源開放的 AI 開發環境和模型服務。
使用免費開源模型將存儲在 Tablestore 中的文本數據生成向量只需4步:
安裝 Python SDK:使用開源模型生成向量和表格存儲功能前,您需要安裝表格存儲 SDK 和開源模型 SDK。
選擇與下載開源模型:ModelScope 魔搭社區提供了大量的文本向量 Embedding 模型,您可以通過模型庫進行選擇和下載使用。
生成向量并寫入到表格存儲:使用開源模型生成向量后,將向量數據寫入到表格存儲數據表中使用。
結果驗證:使用表格存儲的數據讀取接口或者多元索引向量檢索功能查詢向量數據。
使用說明
開發語言:Python
Python版本:推薦使用 Python3.9 及以上版本。
測試環境:本文中示例已經過 CentOS 7 和 macOS 平臺的環境驗證。
注意事項
Tablestore 多元索引中向量類型的維度、類型、距離算法必須與開源模型中文本轉向量模型的相應配置保持一致。例如開源模型damo/nlp_corom_sentence-embedding_chinese-tiny生成的向量類型為 256 維、Float32 類型和 euclidean 歐氏距離算法,在 Tablestore 創建多元索引時的向量類型也必須是 256 維、Float32 類型和 euclidean 歐氏距離算法。
前提條件
使用阿里云賬號或者具有表格存儲操作權限的 RAM 用戶進行操作。
如果要使用 RAM 用戶進行操作,您需要使用阿里云賬號創建 RAM 用戶并授予 RAM 用戶訪問表格存儲(AliyunOTSFullAccess)的權限。具體操作,請參見為RAM用戶授權。
已為阿里云賬號或者 RAM 用戶創建 AccessKey。具體操作,請參見創建AccessKey。
警告阿里云賬號 AccessKey 泄露會威脅您所有資源的安全。建議您使用 RAM 用戶 AccessKey 進行操作,可以有效降低 AccessKey 泄露的風險。
已獲取表格存儲實例的名稱和服務地址。具體操作,請參見服務地址。
已將 AccessKey(包括 AccessKey ID 和 AccessKey Secret)、實例名稱和實例的服務地址配置到環境變量中。
1. 安裝 SDK
在命令行中執行 pip 命令安裝表格存儲 Python SDK 和 ModelScope 相關依賴。安裝命令如下:
# 安裝表格存儲Python SDK。
pip install tablestore
# 安裝ModelScope相關依賴。
pip install "modelscope[framework]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
pip install --use-pep517 "modelscope[nlp]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
pip install torch torchvision torchaudio2. 選擇與下載開源模型
2.1 選擇開源模型
ModelScope 提供了大量的文本向量 Embedding 模型,您可以通過模型庫進行選擇。
下表列出了使用頻率較高的模型,請根據業務需要進行選擇。
如果 ModelScope 生成的向量沒有歸一化,則在 Tablestore 中可以選擇歐式距離作為距離度量算法。
模型ID | 模型領域 | 向量維度 | 推薦距離度量算法 |
damo/nlp_corom_sentence-embedding_chinese-base | 中文-通用領域-base | 768 | 歐氏距離 |
damo/nlp_corom_sentence-embedding_english-base | 英文-通用領域-base | 768 | 歐氏距離 |
damo/nlp_corom_sentence-embedding_chinese-base-ecom | 中文-電商領域-base | 768 | 歐氏距離 |
damo/nlp_corom_sentence-embedding_chinese-base-medical | 中文-醫療領域-base | 768 | 歐氏距離 |
damo/nlp_corom_sentence-embedding_chinese-tiny | 中文-通用領域-tiny | 256 | 歐氏距離 |
damo/nlp_corom_sentence-embedding_english-tiny | 英文-通用領域-tiny | 256 | 歐氏距離 |
damo/nlp_corom_sentence-embedding_chinese-tiny-ecom | 中文-電商領域-tiny | 256 | 歐氏距離 |
damo/nlp_corom_sentence-embedding_chinese-tiny-medical | 中文-醫療領域-tiny | 256 | 歐氏距離 |
2.2 下載開源模型
確定要用的模型后,在命令行中執行 modelscope download --mode {模型 ID}下載所需模型。其中{模型 ID}請根據實際需要進行替換,此處以damo/nlp_corom_sentence-embedding_chinese-tiny模型為例介紹。命令示例如下:
modelscope download --mode damo/nlp_corom_sentence-embedding_chinese-tiny3. 生成向量并寫入到表格存儲
使用開源模型進行向量生成后,將向量寫入到表格存儲數據表中。您可以直接寫入向量到表格存儲中,也可以將表格存儲中存量的數據生成向量再寫入到表格存儲中。
以下示例用于使用 Python SDK 創建表格存儲的表和多元索引,然后使用開源模型生成維度為 256 的向量,并寫入向量數據到表格存儲。
import json
import os
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
from tablestore import OTSClient, TableMeta, TableOptions, ReservedThroughput, CapacityUnit, FieldSchema, FieldType, VectorDataType, VectorOptions, VectorMetricType, \
SearchIndexMeta, AnalyzerType, Row, INF_MIN, INF_MAX, Direction, OTSClientError, OTSServiceError, Condition, RowExistenceExpectation
# 選擇合適的模型并填寫模型ID
pipeline_se = pipeline(Tasks.sentence_embedding, model='damo/nlp_corom_sentence-embedding_chinese-tiny')
def text_to_vector_string(text: str) -> str:
inputs = {'source_sentence': [text]}
result = pipeline_se(input=inputs)
# 返回結果轉成TableStore支持的格式:float32數組字符串,例如: [1, 5.1, 4.7, 0.08]
return json.dumps(result["text_embedding"].tolist()[0])
def create_table():
table_meta = TableMeta(table_name, [('PK_1', 'STRING')])
table_options = TableOptions()
reserved_throughput = ReservedThroughput(CapacityUnit(0, 0))
tablestore_client.create_table(table_meta, table_options, reserved_throughput)
def create_search_index():
index_meta = SearchIndexMeta([
# 支持文本匹配查詢
FieldSchema('field_string', FieldType.KEYWORD, index=True, enable_sort_and_agg=True),
# 支持數字范圍查詢
FieldSchema('field_long', FieldType.LONG, index=True, enable_sort_and_agg=True),
# 全文檢索字段
FieldSchema('field_text', FieldType.TEXT, index=True, analyzer=AnalyzerType.MAXWORD),
# 向量檢索字段,使用歐氏距離作為度量,向量長度為 256
FieldSchema("field_vector", FieldType.VECTOR,
vector_options=VectorOptions(
data_type=VectorDataType.VD_FLOAT_32,
dimension=256,
metric_type=VectorMetricType.VM_EUCLIDEAN
)),
])
tablestore_client.create_search_index(table_name, index_name, index_meta)
def write_data_to_table():
for i in range(100):
pk = [('PK_1', str(i))]
text = "一段字符串,可用戶全文檢索。同時該字段生成Embedding向量,寫入到下方field_vector字段中進行向量語義相似性查詢"
vector = text_to_vector_string(text)
columns = [
('field_string', 'str-%d' % (i % 5)),
('field_long', i),
('field_text', text),
('field_vector', vector),
]
tablestore_client.put_row(table_name, Row(pk, columns))
def get_range_and_update_vector():
# 設置范圍讀的起始主鍵,INF_MIN是一個特殊最小值標志位
inclusive_start_primary_key = [('PK_1', INF_MIN)]
# 設置范圍讀的結束主鍵,INF_MAX是一個特殊最大值標志位
exclusive_end_primary_key = [('PK_1', INF_MAX)]
total = 0
try:
while True:
consumed, next_start_primary_key, row_list, next_token = tablestore_client.get_range(
table_name,
Direction.FORWARD,
inclusive_start_primary_key,
exclusive_end_primary_key,
["field_text", "想要返回的其它字段"],
5000,
max_version=1,
)
for row in row_list:
total += 1
# 獲取讀取到的"field_text"字段
text_field_content = row.attribute_columns[0][1]
# 根據"field_text"字段的內容重新生成向量
vector = text_to_vector_string(text_field_content)
update_of_attribute_columns = {
'PUT': [('field_vector', vector)],
}
update_row = Row(row.primary_key, update_of_attribute_columns)
condition = Condition(RowExistenceExpectation.IGNORE)
# 更新該行數據
tablestore_client.update_row(table_name, update_row, condition)
if next_start_primary_key is not None:
inclusive_start_primary_key = next_start_primary_key
else:
break
# 客戶端異常,一般為參數錯誤或者網絡異常。
except OTSClientError as e:
print('get row failed, http_status:%d, error_message:%s' % (e.get_http_status(), e.get_error_message()))
# 服務端異常,一般為參數錯誤或者流控錯誤。
except OTSServiceError as e:
print('get row failed, http_status:%d, error_code:%s, error_message:%s, request_id:%s' % (e.get_http_status(), e.get_error_code(), e.get_error_message(), e.get_request_id()))
print("一共處理數據:", total)
if __name__ == '__main__':
# 初始化 tablestore client
end_point = os.environ.get('end_point')
access_id = os.environ.get('access_key_id')
access_key_secret = os.environ.get('access_key_secret')
instance_name = os.environ.get('instance_name')
tablestore_client = OTSClient(end_point, access_id, access_key_secret, instance_name)
table_name = "python_demo_table_name"
index_name = "python_demo_index_name"
# 創建表
create_table()
# 創建索引
create_search_index()
# 方式1:直接寫入向量數據到TableStore中
write_data_to_table()
# 方式2:將TableStore中存量的數據生成向量再寫入到TableStore中
get_range_and_update_vector()
4. 結果驗證
在表格存儲控制臺查看寫入表格存儲中的向量數據。您可以使用數據讀取接口( GetRow、BatchGetRow 和 GetRange)或者使用多元索引的向量檢索查詢向量數據。
計費說明
使用表格存儲時,數據表和多元索引的數據量會占用存儲空間,直接讀寫表中數據和使用多元索引向量檢索功能查詢數據會消耗計算資源。其中在VCU模式(原預留模式)下,計算資源消耗會按照計算能力計費,在CU模式(原按量模式)下,計算資源消耗會按照讀吞吐量和寫吞吐量計費。
相關文檔
您也可以通過阿里云的大模型服務平臺百煉中的模型服務將表格存儲中數據轉成向量。更多信息,請參見使用云服務將Tablestore數據轉成向量。