向量檢索(KnnVectorQuery)使用數值向量進行近似最近鄰查詢,可以在大規模數據集中找到最相似的數據項。向量檢索功能適用于推薦系統、圖像與視頻檢索、自然語言處理與語義搜索等場景。
關于向量檢索的更多信息,請參見向量檢索介紹與使用。
注意事項
要使用向量檢索,向量字段在數據表中對應列的數據類型必須為字符串類型。創建多元索引時,該列的數據類型需要配置為向量類型字段,并指定向量維度、向量數據類型和向量之間的距離度量算法。
如果要在 SQL 查詢時使用向量檢索,則需要為數據表創建多元索引映射關系。關于如何創建多元索引映射關系,請參見創建多元索引的映射關系。
數據類型映射
表數據類型 | 多元索引數據類型 | SQL 數據類型 |
字符串 | 向量類型,并指定向量維度、向量數據類型和向量之間的距離度量算法。 | VARCHAR(主鍵) |
MEDIUMTEXT(預定義列) |
創建方法
在 CREATE TABLE 語句中,向量列和普通列的創建方法和語法相同,只需要正確書寫向量列名和對應的數據類型即可。在多元索引映射關系中,向量列的字段類型推薦定義成 MEDIUMTEXT 類型。
創建包含向量類型列的多元索引映射關系,SQL 示例如下:
CREATE TABLE `test_table__test_table_index`(
`col_vector` MEDIUMTEXT
)
ENGINE='searchindex'
ENGINE_ATTRIBUTE='{"index_name":"test_table_index", "table_name":"test_table"}';向量檢索
VECTOR_QUERY_FLOAT32
VECTOR_QUERY_FLOAT32 函數用于使用數值向量進行近似最近鄰查詢。
SQL 表達式
VECTOR_QUERY_FLOAT32(fieldName, float32QueryVector,topk, filter)參數說明
參數
類型
是否必選
說明
fieldName
string
是
要匹配的列。向量檢索必須應用于多元索引向量類型字段。
float32QueryVector
string
是
要查詢相似度的向量。
重要向量維度需要保證和多元索引中向量類型字段的維度一致。
topK
int
是
查詢最鄰近的 topK 個值。關于最大值的說明請參見多元索引限制。
重要K 值越大,召回率越好,但是查詢延遲和費用越高。
當 topK 的值小于 SQL 語句中的 limit 值時,服務端會自動把 topK 的值放大到 limit 的值。
filter
string
否
查詢過濾器,支持組合使用任意的非向量檢索的查詢條件。
示例
以下示例用于查詢 exampletable 表中 col_vector 列與
[1.5, -1.5, 2.5, -2.5]最相似的 10 個值。SELECT * FROM exampletable WHERE VECTOR_QUERY_FLOAT32(col_vector, "[1.5, -1.5, 2.5, -2.5]", 10) limit 10;
SCORE()
SCORE() 函數用于獲取查詢結果的相關性分數,分數越大代表越相似。
SQL 表達式
SCORE()示例
以下示例用于查詢 exampletable 表中 col_vector 列與
[1.5, -1.5, 2.5, -2.5]最相似的 10 個值, 并展示查詢結果的相關性分數。SELECT *,SCORE() FROM exampletable WHERE VECTOR_QUERY_FLOAT32(col_vector, "[1.5, -1.5, 2.5, -2.5]", 10) limit 10;
與其他查詢組合使用示例
向量檢索可以和其他條件自由組合使用,不同的組合使用方式會有不同的效果,以下對兩種常見的使用方式進行說明。此處以一個 Filter 命中數據量較少的場景為例進行介紹。
假設表中有 1 億張圖片,其中用戶“a”總計有 5 萬張圖片,但是在 2024 年僅有 50 張圖片,用戶“a”希望以圖搜圖的方式找到 2024 年最相似的 10 張圖片。
以下示例首先會通過 filter 篩選出用戶“a”在 2024 年的所有 50 張圖片,然后再從 50 張圖片中找到最相似的 10 張圖片返回給用戶,并展示出每一張圖片與目標圖片的相關性分數。
SELECT *,SCORE() FROM exampletable WHERE VECTOR_QUERY_FLOAT32(col_vector, "[1.5, -1.5, 2.5, -2.5]", 100, user="a" and year_num=2024) limit 10;以下示例會先返回表中 1 億張圖片中最相似的前 TopK=500 張圖片,然后再按照順序找出用戶“a”在 2024 年的 10 張圖片,并展示出每一張圖片與目標圖片的相關性分數。但是由于所有圖片的 TopK=500 張圖片中不一定包含用戶“a”2024 年所有的 50 張圖片,因此該查詢方式不一定能找到 2024 年的 10 張圖片,甚至找不到任何數據。
SELECT *,SCORE() FROM exampletable WHERE user="a" and year_num=2024 and VECTOR_QUERY_FLOAT32(col_vector, "[1.5, -1.5, 2.5, -2.5]", 500) limit 10;
使用示例
假設數據表名稱為 vector_query_table,該表中有主鍵列 pk(字符串類型)和兩個屬性列 col_vector(字符串類型)、col_keyword(字符串類型)。
如果要在 SQL 查詢時使用向量檢索,則需要為數據表創建多元索引并創建多元索引的映射關系,然后通過 SQL 語句使用向量檢索。具體步驟如下:
創建多元索引并完成對向量字段的配置。具體操作,請參見通過控制臺使用多元索引或通過 SDK 使用多元索引。
說明如果要使用的多元索引中未配置向量字段,您可以通過修改多元索引的 schema 來配置向量字段。具體操作,請參見動態修改 schema。
使用控制臺創建多元索引的配置如下圖所示。
多元索引名稱為
vector_query_table_index,包括col_vector(向量類型)和col_keyword(String 類型)列。其中向量字段所在列為col_vector。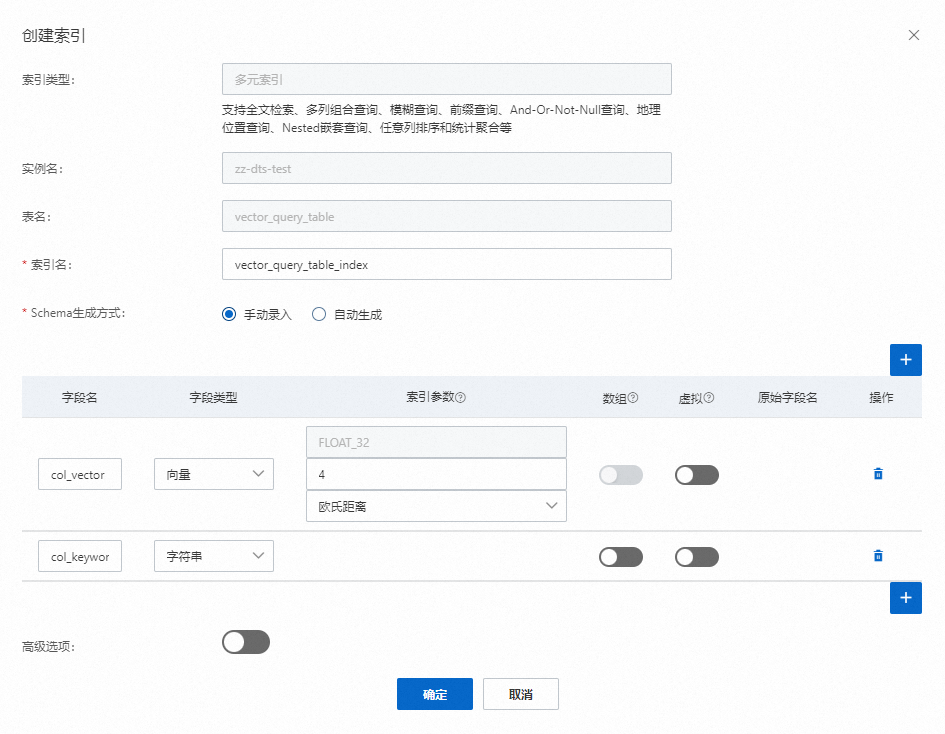
多元索引 Schema 如下圖所示。

創建多元索引映射關系。具體操作,請參見通過控制臺使用 SQL 查詢或者通過 SDK 使用 SQL 查詢。
多元索引映射關系名稱為
vector_query_table__vector_query_table_index,該映射關系向量字段所在列col_vector對應的 SQL 數據類型為 MEDIUMTEXT。更多信息,請參見創建多元索引的映射關系。SQL 示例如下:
CREATE TABLE `vector_query_table__vector_query_table_index`( `col_vector` MEDIUMTEXT, `col_keyword` MEDIUMTEXT ) ENGINE='searchindex', ENGINE_ATTRIBUTE='{"index_name":"vector_query_table_index","table_name":"vector_query_table"}';(可選)創建多元索引映射關系后,請根據需要執行如下操作。
查詢表的描述信息
執行如下語句查詢表的描述信息。
DESCRIBE vector_query_table__vector_query_table_index;返回結果如下圖所示。

獲取表中數據
執行如下語句獲取表中數據。
SELECT * FROM vector_query_table__vector_query_table_index;返回結果如下圖所示。假設多元索引映射關系
vector_query_table__vector_query_table_index有 10 條數據。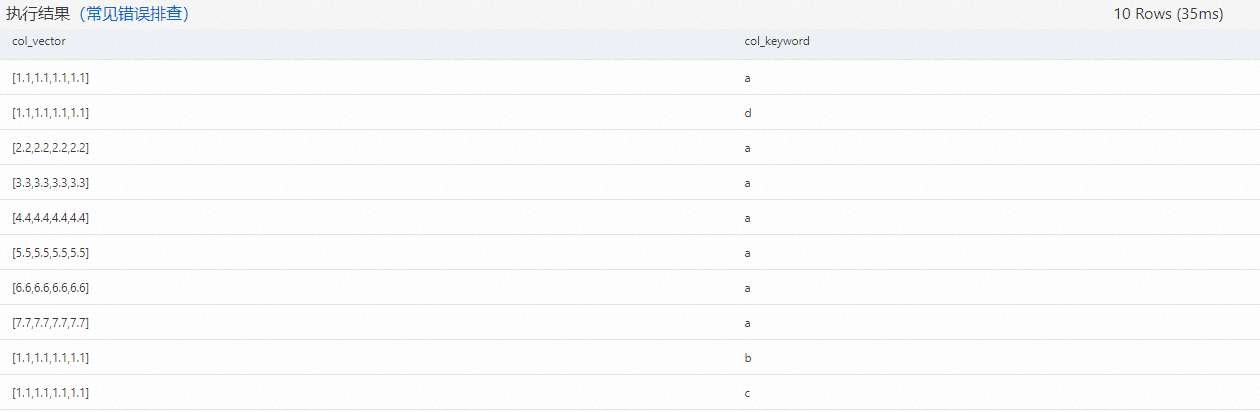
使用向量檢索查詢數據。更多信息,請參見查詢數據。
以下示例用于查詢 col_vector 列與
[1.5, 2.0, 2.5, 1.7]最相似的 5 個值, 并展示查詢結果的相關性分數。SELECT *,SCORE() FROM vector_query_table__vector_query_table_index WHERE VECTOR_QUERY_FLOAT32(col_vector, "[1.5, 2.0, 2.5, 1.7]", 5) limit 5;返回結果如下圖所示。

使用限制
VECTOR_QUERY_FLOAT32 函數只能在多元索引映射關系上使用。
使用 VECTOR_QUERY_FLOAT32 函數時,必須使用 limit,不能使用 Having 子句。
VECTOR_QUERY_FLOAT32 函數只能作為 SELECT 語句的 WHERE 子句,不能作為 SELECT 語句的列表達式,不能用于聚合函數計算,不能進行分組和排序。
SCORE() 函數只能配合 VECTOR_QUERY_FLOAT32 函數一起使用,不能單獨使用。
SCORE() 函數只能作為 SELECT 語句的列表表達式,不能作為 SELECT 語句的 WHERE 子句,不能用于聚合函數計算,不能直接用于排序語句。