本文介紹窗口函數的基本語法及示例。
簡介
普通的聚合函數只能用來計算一行內的結果或把所有行聚合成一行結果,而窗口函數支持為每一行生成一個結果。窗口函數包含分區、排序和框架這3個核心元素。更多信息,請參見Window Function Concepts and Syntax。
function over (
[partition by partition_expression]
[order by order_expression]
[frame]
)分區:分區元素由partition by子句定義。partition by子句用于劃分窗口分區,如果沒有指定partition by子句,則整個查詢與分析結果集作為一個窗口分區。
排序:排序元素由order by子句定義。order by子句用于對窗口分區內的行進行排序。
說明使用order by子句對重復的數值進行排序時,排序結果不穩定。如果您希望每次排序結果相同,可指定多個列進行排序。例如
order by request_time, request_method。框架:框架元素在窗口分區內對行進一步限制。框架元素不適用于排名函數。框架子句的語法為
{ rows | range} { frame_start | frame_between },例如range between unbounded preceding and unbounded following。更多信息,請參見Window Function Frame Specification。
函數列表
分類 | 函數名稱 | 語法 | 說明 | 支持SQL | 支持SPL |
聚合函數 | 無 | 所有聚合函數都支持在窗口函數中使用。聚合函數列表請參見聚合函數。 | √ | × | |
排名函數 | cume_dist() | 統計窗口分區內各個值的累計分布。即計算窗口分區內值小于等于當前值的行數占窗口內總行數的比例。返回值范圍為(0,1]。 | √ | × | |
dense_rank() | 窗口分區內值的排名。相同值擁有相同的排名,排名是連續的,例如有兩個相同值的排名為1,則下一個值的排名為2。 | √ | × | ||
ntile(n) | 將窗口分區內數據按照順序分成N組。 | √ | × | ||
percent_rank() | 計算窗口分區內各行的百分比排名。 | √ | × | ||
rank() | 窗口分區內值的排名。相同值擁有相同的排名,排名不是連續的,例如有兩個相同值的排名為1,則下一個值的排名為3。 | √ | × | ||
row_number() | 窗口分區內值的排名。每個值擁有唯一的序號,從1開始。三個相同值的排名為1、2、3。 | √ | × | ||
偏移函數 | first_value(x) | 返回各個窗口分區內第一行的值。 | √ | × | |
last_value(x) | 返回各個窗口分區內最后一行的值。 | √ | × | ||
lag(x, offset, default_value) | 返回窗口分區內位于當前行上方第offset行的值。如果不存在該行,則返回default_value。 | √ | × | ||
lead(x, offset, default_value) | 返回窗口分區內位于當前行下方第offset行的值。如果不存在該行,則返回default_value。 | √ | × | ||
nth_value(x, offset) | 返回窗口分區中第offset行的值。 | √ | × |
聚合函數
所有聚合函數都支持在窗口函數中使用。聚合函數列表請參見聚合函數。此處以sum函數為例。
語法
sum() over (
[partition by partition_expression]
[order by order_expression]
[frame]
)參數說明
參數 | 說明 |
partition by partition_expression | 窗口分區,根據分區表達式將數據劃分成不同的分區。 |
order by order_expression | 窗口排序,根據排序表達式對各個分區內的每一行進行排序。 |
frame | 窗口框架,例如 |
返回值類型
double類型。
示例
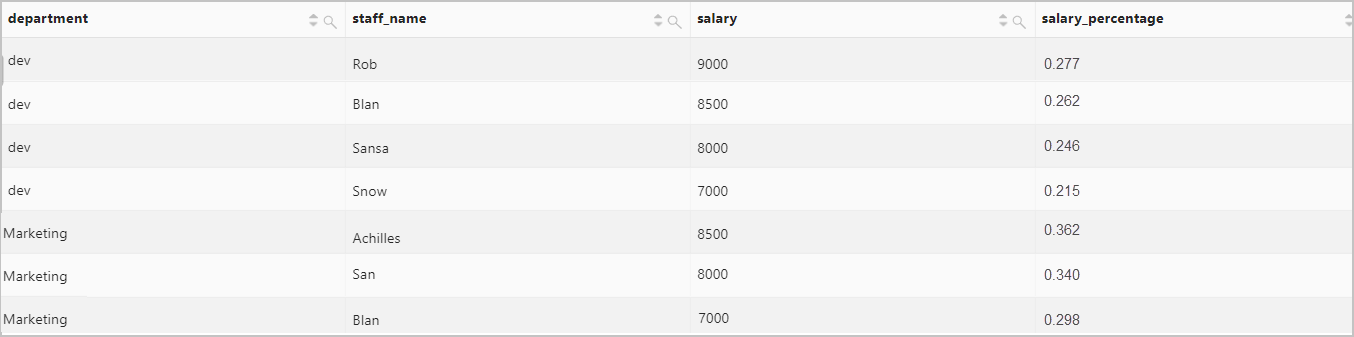
按照部門分區,獲取每個員工薪水在部門內的占比。
查詢和分析語句
* | SELECT department, staff_name, salary, round ( salary * 1.0 / sum(salary) over(partition by department), 3) AS salary_percentage查詢和分析結果
cume_dist函數
cume_dist函數用于統計窗口分區內各個值的累計分布。即計算窗口分區內值小于等于當前值的行數占窗口內總行數的比例。返回值范圍為(0,1]。
語法
cume_dist() over (
[partition by partition_expression]
[order by order_expression]
)參數說明
參數 | 說明 |
partition by partition_expression | 窗口分區,根據分區表達式將數據劃分成不同的分區。 |
order by order_expression | 窗口排序,根據排序表達式對各個分區內的每一行進行排序。 |
返回值類型
double類型。
示例
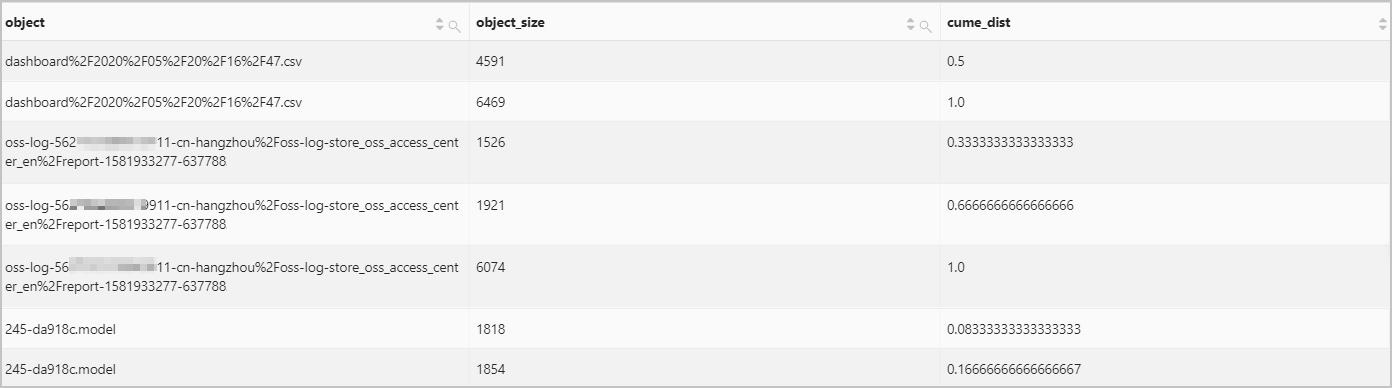
統計名為bucket00788的OSS Bucket內各個對象的大小的累計分布。
查詢和分析語句
bucket=bucket00788 | select object, object_size, cume_dist() over ( partition by object order by object_size ) as cume_dist from oss-log-store查詢和分析結果
dense_rank函數
dense_rank函數用于窗口分區內值的排名。相同值擁有相同的排名,排名是連續的,例如有兩個相同值的排名為1,則下一個值的排名為2。
語法
dense_rank() over (
[partition by partition_expression]
[order by order_expression]
)參數說明
參數 | 說明 |
partition by partition_expression | 窗口分區,根據分區表達式將數據劃分成不同的分區。 |
order by order_expression | 窗口排序,根據排序表達式對各個分區內的每一行進行排序。 |
返回值類型
bigint類型。
示例
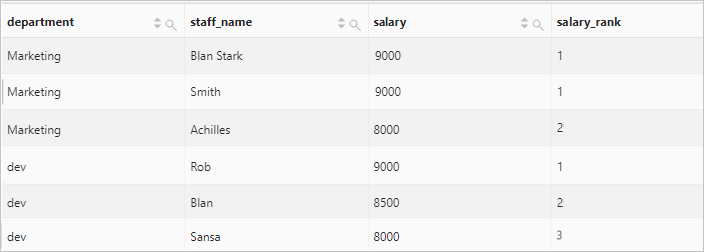
按照部門分區,計算員工薪水在部門內的排名。
查詢和分析語句
* | select department, staff_name, salary, dense_rank() over( partition by department order by salary desc ) as salary_rank order by department, salary_rank查詢和分析結果
ntile函數
ntile函數用于將窗口分區內數據按照順序分成N組。
語法
ntile(n) over (
[partition by partition_expression]
[order by order_expression]
)參數說明
參數 | 說明 |
n | 組數。 |
partition by partition_expression | 窗口分區,根據分區表達式將數據劃分成不同的分區。 |
order by order_expression | 窗口排序,根據排序表達式對各個分區內的每一行進行排序。 |
返回值類型
bigint類型。
示例
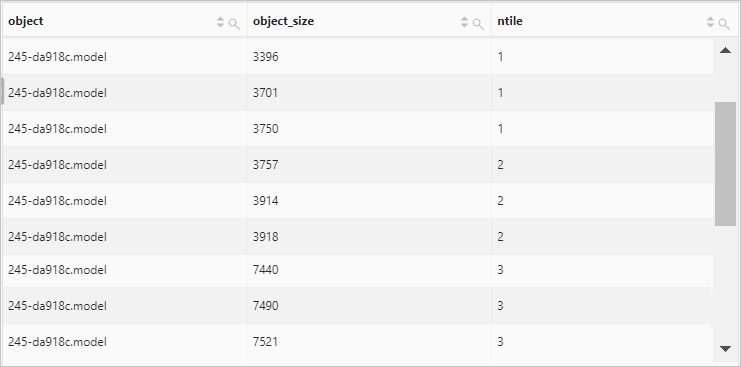
將指定對象中的數據分成3組。
查詢和分析語句
object=245-da918c.model | select object, object_size, ntile(3) over ( partition by object order by object_size ) as ntile from oss-log-store查詢和分析結果
percent_rank函數
函數用于計算窗口分區內各行的百分比排名。計算公式為(rank - 1) / (total_rows - 1) ,其中rank為當前行的排名,total_rows為當前窗口分區內的總行數。
語法
percent_rank() over (
[partition by partition_expression]
[order by order_expression]
)參數說明
參數 | 說明 |
partition by partition_expression | 窗口分區,根據分區表達式將數據劃分成不同的分區。 |
order by order_expression | 窗口排序,根據排序表達式對各個分區內的每一行進行排序。 |
返回值類型
double類型。
示例
計算目標OSS對象的不同大小的百分比排名。
查詢和分析語句
object=245-da918c3e2dd9dc9cb4d9283b%2F555e2441b6a4c7f094099a6dba8e7a5f.model| select object, object_size, percent_rank() over ( partition by object order by object_size ) as ntile FROM oss-log-store查詢和分析結果

rank函數
函數用于窗口分區內值的排名。相同值擁有相同的排名,排名不是連續的,例如有兩個相同值的排名為1,則下一個值的排名為3。
語法
rank() over (
[partition by partition_expression]
[order by order_expression]
)參數說明
參數 | 說明 |
partition by partition_expression | 窗口分區,根據分區表達式將數據劃分成不同的分區。 |
order by order_expression | 窗口排序,根據排序表達式對各個分區內的每一行進行排序。 |
返回值類型
bigint類型。
示例
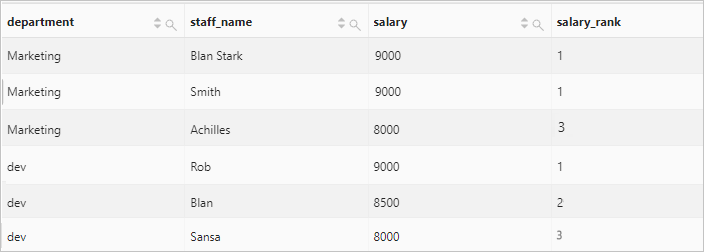
按照部門分區,計算員工薪水在部門內的排名。
查詢和分析語句
* | select department, staff_name, salary, rank() over( partition by department order by salary desc ) as salary_rank order by department, salary_rank查詢和分析結果
row_number函數
row_number函數用于窗口分區內值的排名。每個值擁有唯一的序號,從1開始。
語法
row_number() over (
[partition by partition_expression]
[order by order_expression]
)參數說明
參數 | 說明 |
partition by partition_expression | 窗口分區,根據分區表達式將數據劃分成不同的分區。 |
order by order_expression | 窗口排序,根據排序表達式對各個分區內的每一行進行排序。 |
返回值類型
bigint類型。
示例
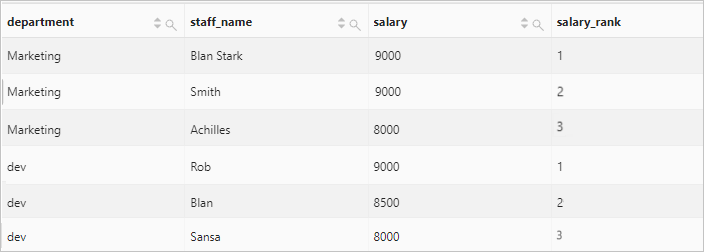
按照部門分區,計算員工薪水在部門內的排名。
查詢和分析語句
* | select department, staff_name, salary, row_number() over( partition by department order by salary desc ) as salary_rank order by department, salary_rank查詢和分析結果
first_value函數
first_value函數用于返回各個窗口分區內第一行的值。
語法
first_value(x) over (
[partition by partition_expression]
[order by order_expression]
[frame]
)參數說明
參數 | 說明 |
x | 列名,可以為任意數據類型。 |
partition by partition_expression | 窗口分區,根據分區表達式將數據劃分成不同的分區。 |
order by order_expression | 窗口排序,根據排序表達式對各個分區內的每一行進行排序。 |
frame | 窗口框架,例如 |
返回值類型
與x的數據類型一致。
示例
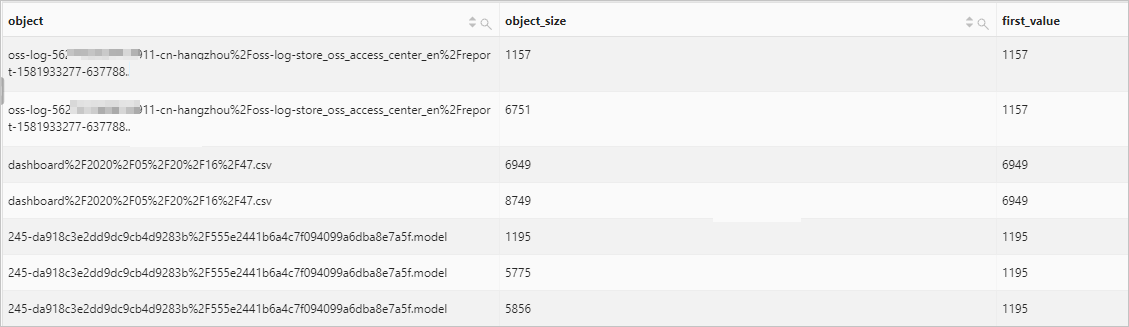
獲取目標OSS Bucket中各個對象的最小值。
查詢和分析語句
bucket :bucket90 | select object, object_size, first_value(object_size) over ( partition by object order by object_size range between unbounded preceding and unbounded following ) as first_value from oss-log-store查詢和分析結果
last_value函數
last_value函數用于返回各個窗口分區內最后一行的值。
語法
last_value(x) over (
[partition by partition_expression]
[order by order_expression]
[frame]
)參數說明
參數 | 說明 |
x | 列名,可以為任意數據類型。 |
partition by partition_expression | 窗口分區,根據分區表達式將數據劃分成不同的分區。 |
order by order_expression | 窗口排序,根據排序表達式對各個分區內的每一行進行排序。 |
frame | 窗口框架,例如 |
返回值類型
與x的數據類型一致。
示例
獲取目標OSS Bucket中各個對象的最大值。
查詢和分析語句
bucket :bucket90 | select object, object_size, last_value(object_size) over ( partition by object order by object_size range between unbounded preceding and unbounded following ) as last_value from oss-log-store查詢和分析結果
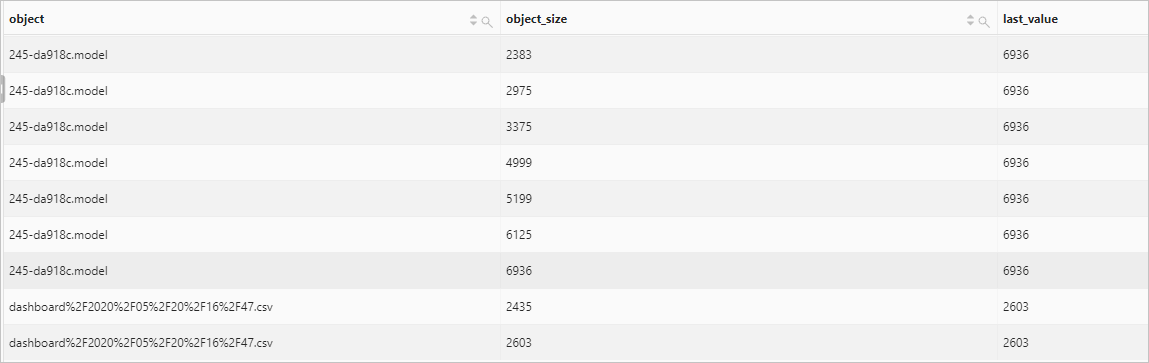
lag函數
lag函數用于返回窗口分區內位于當前行上方第offset行的值。
語法
lag(x, offset, default_value) over (
[partition by partition_expression]
[order by order_expression]
[frame]
)參數說明
參數 | 說明 |
x | 列名,可以為任意數據類型。 |
offset | 偏離量。如果offset為0,則返回當前行的值。 |
default_value | 如果不存在指定的偏離行,則返回default_value。 |
partition by partition_expression | 窗口分區,根據分區表達式將數據劃分成不同的分區。 |
order by order_expression | 窗口排序,根據排序表達式對各個分區內的每一行進行排序。 |
frame | 窗口框架,例如 |
返回值類型
與x的數據類型一致。
示例
按天統計網站訪問UV,獲取每天網站訪問UV相比前一天的增長情況。
查詢和分析語句
* | select day, UV, UV * 1.0 /(lag(UV, 1, 0) over()) as diff_percentage from ( select approx_distinct(client_ip) as UV, date_trunc('day', __time__) as day from log group by day order by day asc )查詢和分析結果
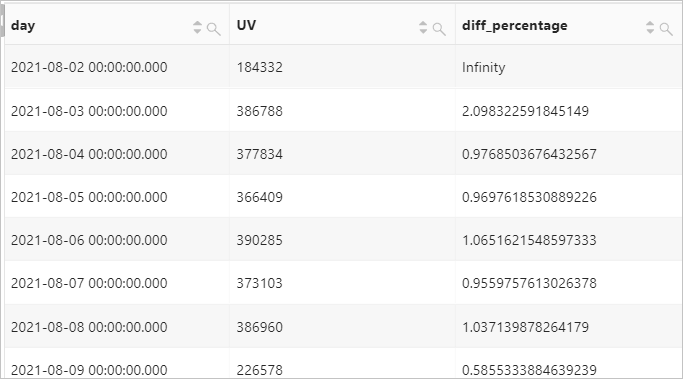
lead函數
函數用于返回窗口分區內位于當前行下方第offset行的值。
語法
lead(x, offset, default_value) over (
[partition by partition_expression]
[order by order_expression]
[frame]
)參數說明
參數 | 說明 |
x | 列名,可以為任意數據類型。 |
offset | 偏離量。如果offset為0,則返回當前行的值。 |
default_value | 如果不存在指定的偏離行,則返回default_value。 |
partition by partition_expression | 窗口分區,根據分區表達式將數據劃分成不同的分區。 |
order by order_expression | 窗口排序,根據排序表達式對各個分區內的每一行進行排序。 |
frame | 窗口框架,例如 |
返回值類型
與x的數據類型一致。
示例
計算2021-08-26當天,當前一小時網站訪問UV與后一小時的占比情況。
查詢和分析語句
* | select time, UV, UV * 1.0 /(lead(UV, 1, 0) over()) as diff_percentage from ( select approx_distinct(client_ip) as uv, date_trunc('hour', __time__) as time from log group by time order by time asc )查詢和分析結果
nth_value函數
nth_value函數用于返回窗口分區中第offset行的值。
語法
nth_value(x, offset) over (
[partition by partition_expression]
[order by order_expression]
[frame]
)參數說明
參數 | 說明 |
x | 列名,可以為任意數據類型。 |
offset | 偏離量。 |
partition by partition_expression | 窗口分區,根據分區表達式將數據劃分成不同的分區。 |
order by order_expression | 窗口排序,根據排序表達式對各個分區內的每一行進行排序。 |
frame | 窗口框架,例如 |
返回值類型
與x的數據類型一致。
示例
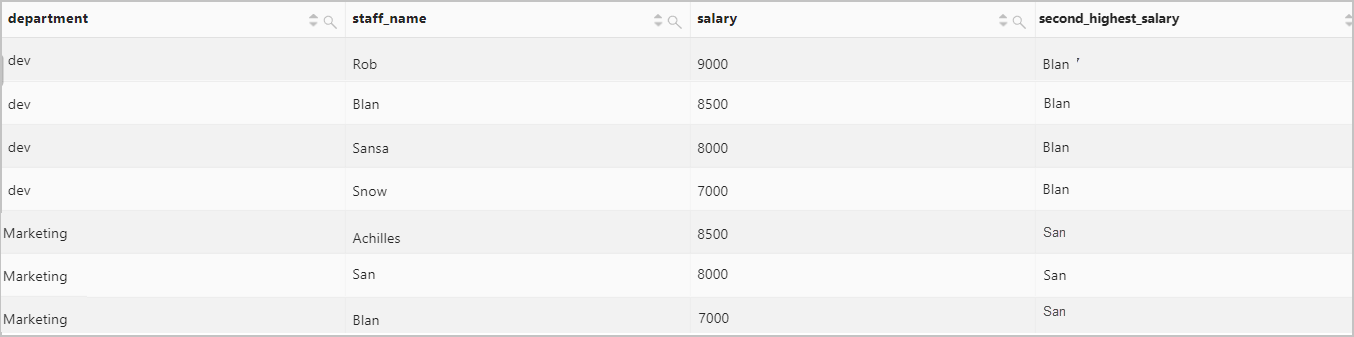
按照部門分區,統計各個部門中薪水第二高的員工。
查詢和分析語句
* | select department, staff_name, salary, nth_value(staff_name, 2) over( partition by department order by salary desc range between unbounded preceding and unbounded following ) as second_highest_salary from log查詢和分析結果