本文介紹正則式函數基本語法及示例。
日志服務支持如下正則式函數(正則表達式采用RE2語法)。
函數名稱 | 語法 | 說明 | 支持SQL | 支持SPL |
regexp_extract_all(x, regular expression) | 提取目標字符串中符合正則表達式的子串,并返回所有子串的集合。 | √ | × | |
regexp_extract_all(x, regular expression, n) | 提取目標字符串中符合正則表達式的子串,然后返回與目標捕獲組匹配的子串集合。 | √ | × | |
regexp_extract(x, regular expression) | 提取并返回目標字符串中符合正則表達式的第一個子串。 | √ | √ | |
regexp_extract(x, regular expression, n) | 提取目標字符串中符合正則表達式的子串,然后返回與目標捕獲組匹配的第一個子串。 | √ | √ | |
regexp_extract_bool(x, regular expression) | 提取并返回目標字符串中符合正則表達式的子串,并轉換為boolean類型,轉換失敗返回 | √ | × | |
regexp_extract_bool(x, regular expression, n) | 提取目標字符串中符合正則表達式的子串,然后返回與目標捕獲組匹配的子串,并轉換為boolean類型,轉換失敗返回 | √ | × | |
regexp_extract_long(x, regular expression) | 提取并返回目標字符串中符合正則表達式的子串,并轉換為bigint類型,轉換失敗返回 | √ | × | |
regexp_extract_long(x, regular expression, n) | 提取目標字符串中符合正則表達式的子串,然后返回與目標捕獲組匹配的子串,并轉換為bigint類型,轉換失敗返回 | √ | × | |
regexp_extract_double(x, regular expression) | 提取并返回目標字符串中符合正則表達式的第一個子串,并轉換為double類型,轉換失敗返回 | √ | × | |
regexp_extract_double(x, regular expression, n) | 提取目標字符串中符合正則表達式的子串,然后返回與目標捕獲組匹配的子串,并轉換為double類型,轉換失敗返回 | √ | × | |
regexp_like(x, regular expression) | 判斷目標字符串是否符合正則表達式。 | √ | √ | |
regexp_replace(x, regular expression) | 刪除目標字符串中符合正則表達式的子串,返回未被刪除的子串。 | √ | √ | |
regexp_replace(x, regular expression, replace string) | 替換目標字符串中符合正則表達式的子串,返回被替換后的字符串。 | √ | √ | |
regexp_split(x, regular expression) | 使用正則表達式分割目標字符串,返回被分割后的子串集合。 | √ | × |
使用正則式函數提取字符串中的單引號(')時,需要在正則表達式中再添加一個單引號(')進行提取。具體示例,請參見regexp_extract函數(示例3)。
regexp_extract_all函數
regexp_extract_all函數用于提取目標字符串中符合正則表達式的子串。
語法
提取目標字符串中符合正則表達式的子串,并返回所有子串的集合。
regexp_extract_all(x, regular expression)提取目標字符串中符合正則表達式的子串,然后返回與目標捕獲組匹配的子串集合。
regexp_extract_all(x, regular expression, n)
參數說明
參數 | 說明 |
x | 參數值為varchar類型。 |
regular expression | 包含捕獲組的正則表達式。例如 |
n | 第n個捕獲組。n為從1開始的整數。 |
返回值類型
array類型。
示例
示例1:提取
server_protocol字段值中所有的數字。字段樣例
server_protocol:HTTP/2.0查詢和分析語句(調試)
*| SELECT regexp_extract_all(server_protocol, '\d+')查詢和分析結果

示例2:提取
http_user_agent字段值中的Chrome部分,然后統計由Chrome瀏覽器發起的請求數量。字段樣例
http_user_agent:Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.803.0 Safari/535.1查詢和分析語句(調試)
*| SELECT regexp_extract_all(http_user_agent, '(Chrome)',1) AS Chrome, count(*) AS count GROUP BY Chrome查詢和分析結果

regexp_extract函數
regexp_extract函數用于提取目標字符串中符合正則表達式的子串。
語法
提取并返回目標字符串中符合正則表達式的第一個子串。
regexp_extract(x, regular expression)提取目標字符串中符合正則表達式的子串,然后返回與目標捕獲組匹配的第一個子串。
regexp_extract(x, regular expression, n)
參數說明
參數 | 說明 |
x | 參數值為varchar類型。 |
regular expression | 包含捕獲組的正則表達式。例如 |
n | 第n個捕獲組。n為從1開始的整數。 |
返回值類型
varchar類型。
示例
SQL
示例1:提取
server_protocol字段值中的第一個數字。字段樣例
server_protocol:HTTP/2.0查詢和分析語句(調試)
*|SELECT regexp_extract(server_protocol, '\d+')查詢和分析結果

示例2:提取
request_uri字段值中的文件部分,然后統計各個文件的訪問次數。字段樣例
request_uri:/request/path-3/file-5查詢和分析語句(調試)
* | SELECT regexp_extract(request_uri, '.*\/(file.*)', 1) AS file, count(*) AS count GROUP BY file查詢和分析結果

示例3:提取
message字段值中的單引號(')和數字部分。字段樣例
message:error'1232查詢和分析語句
* | SELECT regexp_extract(message, '''\d+')說明使用正則式函數提取字符串中的單引號(')時,需要在正則表達式中再添加一個單引號(')。
查詢和分析結果

SPL
示例1:提取server_protocol字段值中的第一個數字。
字段樣例
server_protocol:HTTP/2.0查詢和分析語句
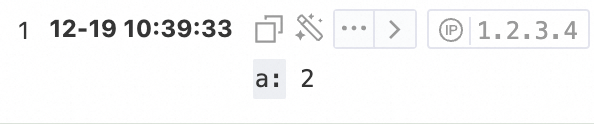
* | extend a = regexp_extract(server_protocol, '\d+')查詢和分析結果
示例2:提取
request_uri字段值中的文件部分。字段樣例
request_uri:/request/path-3/file-5查詢和分析語句
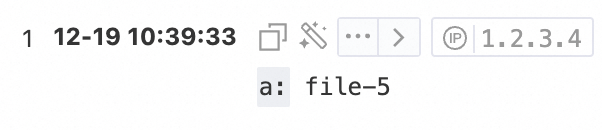
* | extend a = regexp_extract(request_uri, '.*\/(file.*)',1)查詢和分析結果
示例3:提取
message字段值中的單引號(')和數字部分。字段樣例
message:error'1232查詢和分析語句
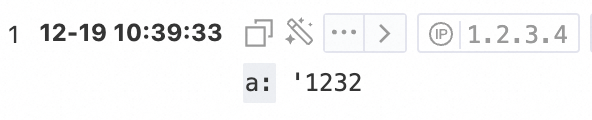
* | extend a = regexp_extract(message, '''\d+') 說明
使用正則表達式函數提取字符串中的單引號(')時,需要在正則表達式中再添加一個單引號(')。
查詢和分析結果
regexp_extract_bool函數
regexp_extract_bool函數用于提取目標字符串中符合正則表達式的子串,并轉換成boolean類型,轉換失敗返回null。當該子串為"true"或"false"(不區分大小寫)時才轉換成功。
語法
提取并返回目標字符串中符合正則表達式的子串,并轉換為boolean類型,轉換失敗返回
null。regexp_extract_bool(x, regular expression)提取目標字符串中符合正則表達式的子串,然后返回與指定捕獲組匹配的子串,并轉換為boolean類型,轉換失敗返回
null。regexp_extract_bool(x, regular expression, n)
參數說明
參數 | 說明 |
x | 參數值為varchar類型。 |
regular expression | 包含捕獲組的正則表達式。例如 |
n | 第n個捕獲組。n為從1開始的整數。 |
返回值類型
boolean類型。
示例
提取字段值中的boolean值。
字段樣例
false查詢和分析語句(調試)
*| select regexp_extract_bool('false', '[a-zA-Z]+')查詢和分析結果

regexp_extract_long函數
regexp_extract_long函數用于提取目標字符串中符合正則表達式的子串,并轉換成bigint類型,轉換失敗返回null。
語法
提取并返回目標字符串中符合正則表達式的子串,并轉換成bigint類型,轉換失敗返回
null。regexp_extract_long(x, regular expression)提取目標字符串中符合正則表達式的子串,然后返回與目標捕獲組匹配的子串,并轉換成bigint類型,轉換失敗返回
null。regexp_extract_long(x, regular expression, n)
參數說明
參數 | 說明 |
x | 參數值為varchar類型。 |
regular expression | 包含捕獲組的正則表達式。例如 |
n | 第n個捕獲組。n為從1開始的整數。 |
返回值類型
bigint類型。
示例
提取
time字段中的數字。字段樣例
time:19/Dec/2024:06:16:06查詢和分析語句(調試)
*|SELECT regexp_extract_long(time, '(\d{2})/', 1)查詢和分析結果

regexp_extract_double函數
regexp_extract_double函數用于提取目標字符串中符合正則表達式的子串,并轉換成double類型,轉換失敗返回null。
語法
提取并返回目標字符串中符合正則表達式的子串,并轉換成double類型,轉換失敗返回
null。regexp_extract_double(x, regular expression)提取目標字符串中符合正則表達式的子串,返回與目標捕獲組匹配的子串,并轉換成double類型,轉換失敗返回
null。regexp_extract_double(x, regular expression, n)
參數說明
參數 | 說明 |
x | 參數值為varchar類型。 |
regular expression | 包含捕獲組的正則表達式。例如 |
n | 第n個捕獲組。n為從1開始的整數。 |
返回值類型
double類型。
示例
提取
server_protocol字段中的數字。字段樣例
server_protocol:HTTP/1.1查詢和分析語句(調試)
*|SELECT regexp_extract_double(server_protocol, '\d+')查詢和分析結果

regexp_like函數
regexp_like函數用于判斷目標字符串是否符合正則表達式。
語法
regexp_like(x, regular expression)參數說明
參數 | 說明 |
x | 參數值為varchar類型。 |
regular expression | 正則表達式。 |
返回值類型
boolean類型。
示例
SQL
判斷server_protocol字段值中是否包含數字。
字段樣例
server_protocol:HTTP/2.0查詢和分析語句(調試)
*| select regexp_like(server_protocol, '\d+')查詢和分析結果

SPL
判斷server_protocol字段值中是否包含數字
字段樣例
server_protocol:HTTP/2.0查詢和分析語句
* |extend a = regexp_like(server_protocol, '\d+')查詢和分析結果

regexp_replace函數
刪除或替換目標字符串中符合正則表達式的子串。
語法
刪除目標字符串中符合正則表達式的子串,返回未被刪除的子串。
regexp_replace(x, regular expression)替換目標字符串中符合正則表達式的子串,返回被替換后的字符串。
regexp_replace(x, regular expression, replace string)
參數說明
參數 | 說明 |
x | 參數值為varchar類型。 |
regular expression | 正則表達式。 |
replace string | 用于替換的子串。 |
返回值類型
varchar類型。
示例
SQL
示例1:將
region字段值中以cn開頭的地域名都替換為中國,然后統計來自中國的請求數量。字段樣例
region:cn-shanghai查詢和分析語句(調試)
* | select regexp_replace(region, 'cn.*','中國') AS region, count(*) AS count GROUP BY region查詢和分析結果

示例2:刪除
server_protocol字段值中的版本號部分,然后統計不同通信協議對應的請求數量。字段樣例
server_protocol:HTTP/2.0查詢和分析語句(調試)
*| select regexp_replace(server_protocol, '.\d+') AS server_protocol, count(*) AS count GROUP BY server_protocol查詢和分析結果

SPL
示例1:將
region字段值中以cn開頭的地域名都替換為中國。字段樣例
region:cn-shanghai查詢和分析語句
* | extend a = regexp_replace(region, 'cn.*','中國')查詢和分析結果

示例2:刪除
server_protocol字段值中的版本號部分。字段樣例
server_protocol:HTTP/2.0查詢和分析語句(調試)
* | extend a = regexp_replace(server_protocol, '.\d+')查詢和分析結果

regexp_split函數
regexp_split函數用于分割目標字符串,返回被分割后的子串集合。
語法
regexp_split(x, regular expression)參數說明
參數 | 說明 |
x | 參數值為varchar類型。 |
regular expression | 正則表達式。 |
返回值類型
array類型。
示例
使用正斜線(/)分割request_uri字段的值。
字段樣例
request_uri:/request/path-0/file-7查詢和分析語句(調試)
* | SELECT regexp_split(request_uri,'/')查詢和分析結果
