本文通過查詢、關聯分析、統計分析等場景介紹如何使用日志服務對程序日志進行查詢和分析。
背景信息
程序日志內容全、存在一定共性,它是運維程序的重要信息,但程序日志具有如下不便于存儲與分析的特性:
格式隨意:不同開發者的代碼風格不同,對應的日志風格也不同,難以統一。
數據量大:程序日志一般比訪問日志大1個數量級。
分布的服務器多:大部分應用為無狀態模式,運行在不同框架中,例如云服務器、容器服務等,對應的實例數從幾個到數千個,需要有一種跨服務器的日志采集方案。
運行環境復雜:程序運行在不同的環境中,產生的日志也保存在不同的環境中,例如應用相關的日志在容器中、API相關日志在FunctionCompute中、舊系統日志在本地IDC中、移動端相關日志在用戶處、網頁端日志在瀏覽器中等。
為了能夠獲得全量日志,必須把所有日志統一存儲。針對該場景,日志服務提供多樣化的日志采集方式及一站式分析功能,您可通過查詢+SQL92語法對日志進行實時分析,并以圖表形式直觀展示分析結果。和開源方案對比,日志服務提供的解決方案在查詢分析成本上僅是開源方案的25%。
查詢程序日志
例如某App出現訂單錯誤或請求延時等問題,您可以通過查詢語句在TB級數據量的日志中快速(1s內)定位問題。還可以根據業務需求,設置時間范圍、查詢關鍵字等信息,更精準地返回查詢結果。
查詢延時大于1s,并且請求方法是以Post開頭的請求數據。
Latency > 1000000 and Method=Post*查找包含error關鍵詞但不包含merge關鍵詞的日志。
error not merge
關聯分析程序日志
關聯分析包括進程內關聯與跨進程關聯,區別如下:
進程內關聯:一般比較簡單,因為同一個進程前后日志都在一個文件中。在多線程環境中,只需根據線程ID進行過濾即可。
跨進程關聯:跨進程的請求一般沒有明確線索,一般通過RPC中傳入的TracerId來進行關聯。

進程內關聯
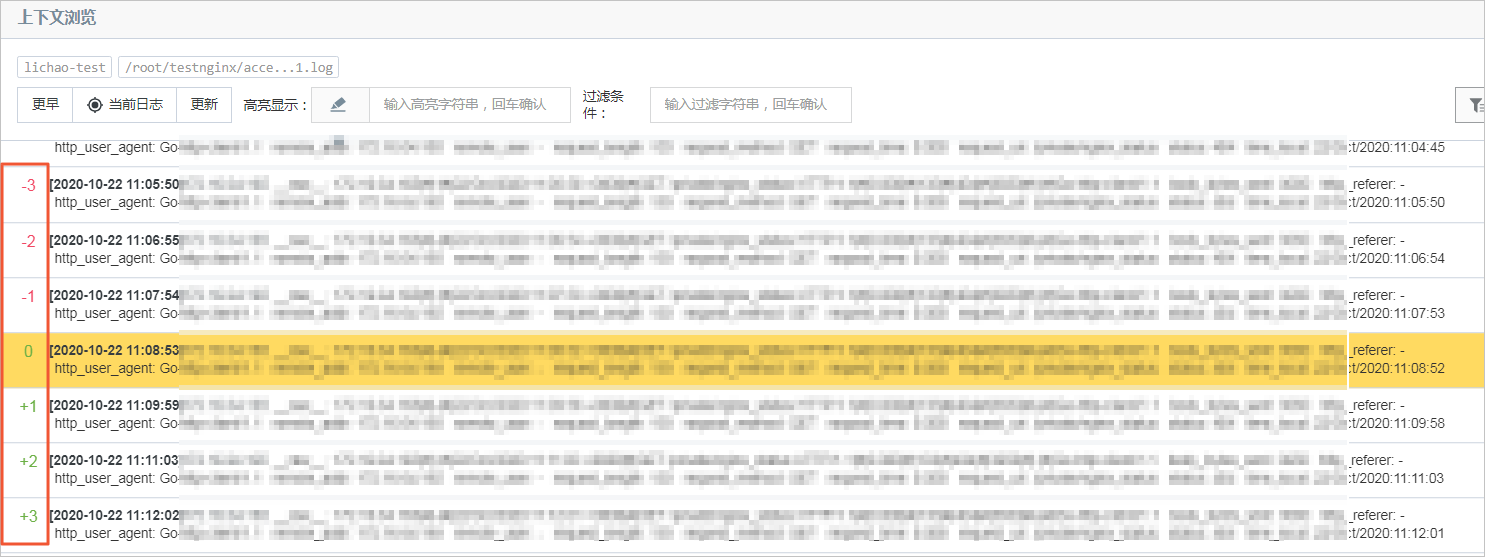
通過上下文查詢查看關聯日志。例如通過關鍵詞查詢定位到一個異常日志,然后單擊上下文瀏覽,查看該日志前后N條日志,操作步驟請參見上下文查詢。

上下文查詢結果如下所示:
跨進程關聯
跨進程關聯也叫Tracing,比較常見的工具有鷹眼、Dapper、StackDriver Trace、Zipkin、Appdash、X-ray等。
此處基于日志服務,實現基本的Tracing功能。您可以在各模塊日志中輸出Request_id、OrderId等可以關聯的標識字段,通過在不同的日志庫中查找,獲取所有相關日志。
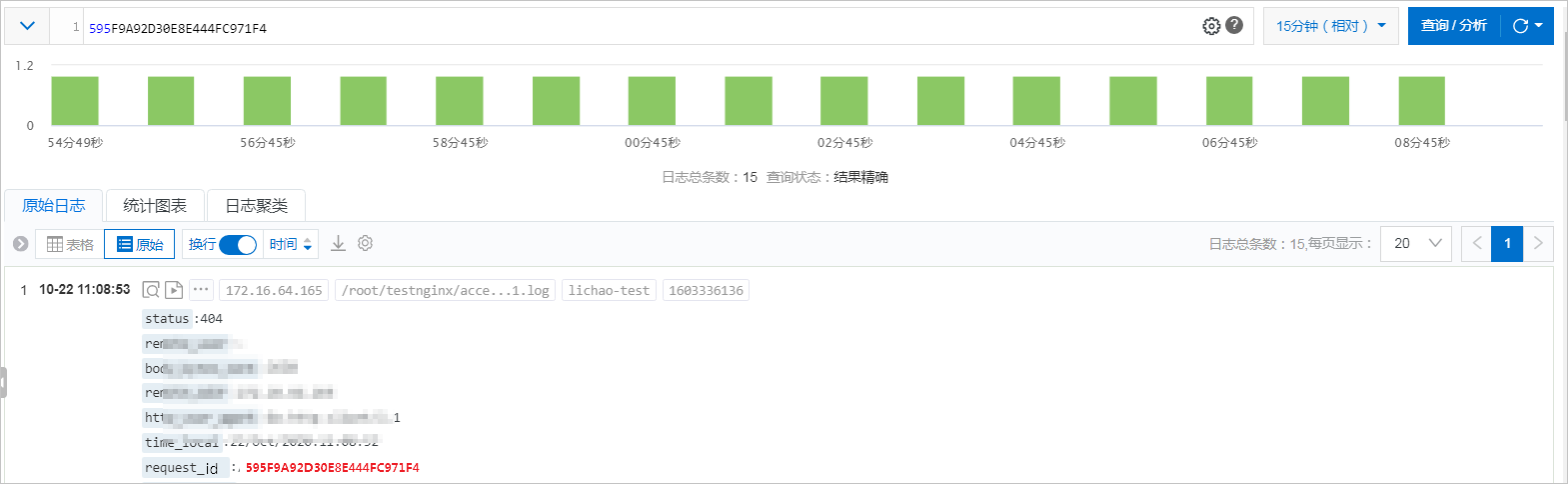
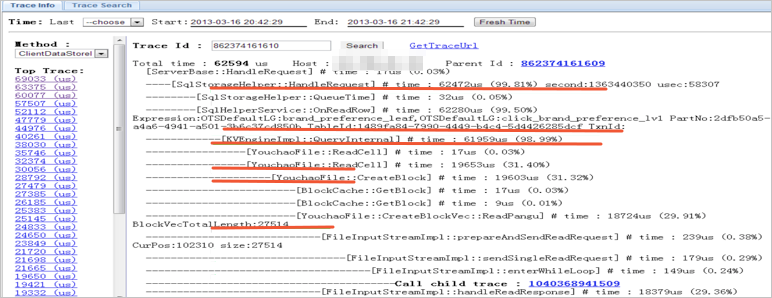
例如通過SDK查詢前端機、后端機、支付系統、訂單系統等日志。獲得結果后,制作一個前端頁面將跨進程分析關聯起來,如下圖所示。
統計分析程序日志
查詢到日志后,您還可以做進一步統計分析。
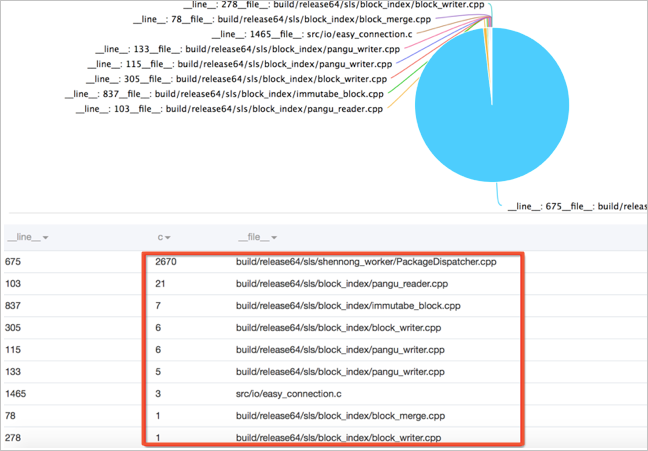
執行如下查詢分析語句,統計所有錯誤發生的類型和位置的分布。
__level__:error | select __file__, __line__, count(*) as c group by __file__, __line__ order by c desc