日志服務提供基于規則的數據實時消費功能,通過SPL可以實現在服務端的數據處理后進行消費。本文介紹基于規則消費功能的概念、功能優勢、應用場景、計費規則、消費目標等信息。
工作原理
基于規則消費是指第三方軟件、多語言應用、云產品、流式計算框架等通過設置SPL實時消費日志服務的數據。SPL是SLS推出的一款針對日志弱結構化特點進行高性能數據處理的語言。基于規則消費的原理是在服務端使用SPL對日志中的弱結構化數據進行預處理和數據清洗,例如行過濾、列裁剪、正則提取、JSON字段提取等操作,在數據到達客戶端時已經是規整后的數據格式,SPL語法詳情請參見SPL概述。
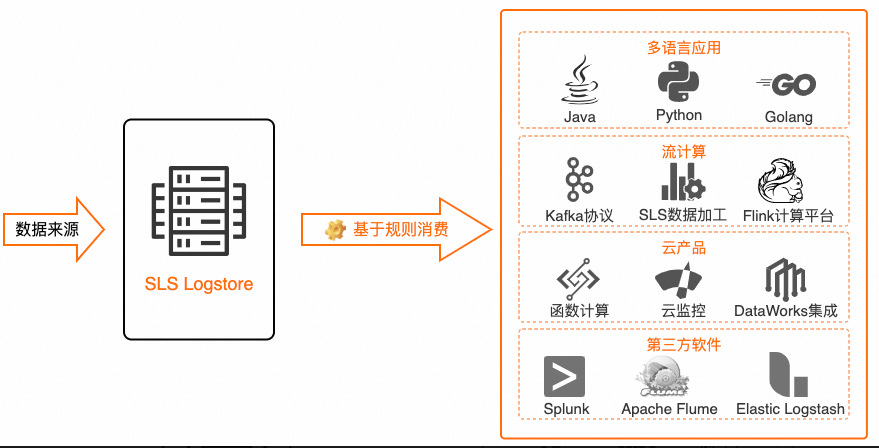
基于規則消費和查詢與分析都是讀取數據。關于兩者的區別,請參見日志消費與查詢區別。
應用場景
基于規則消費功能適用于流計算和實時計算中需要數據預處理的場景,例如在消費日志數據前,可能需要進行行過濾、列裁剪、正則提取、JSON字段提取等操作。基于規則消費的實時性較強,通常為秒級。您可以自定義存儲時間。
功能優勢
通過公網消費,節省流量費用。
某客戶想把日志寫入到日志服務后,再通過公網消費日志,過濾后再分發給內部系統。基于SPL消費功能,該客戶可以直接在日志服務中實現日志規則過濾,避免將大量無效日志投遞給消費者,節省網絡流量費用。
節省本地CPU資源,加速計算進程。
某客戶想把日志寫入到日志服務后,再消費日志到本地機器進行計算。基于SPL消費功能,該客戶可以直接在日志服務中實現SPL計算,降低本地資源消耗。
計費規則
若Logstore的計費模式為按寫入數據量計費,基于規則消費將不產生費用,僅從日志服務公網域名所在接口拉取數據時,會產生外網讀取流量(按照壓縮后的數據量計算)。具體內容,可參見按寫入數據量計費模式計費項。
若Logstore的計費模式為按使用功能計費,基于規則消費服務會產生服務端計算費用,使用日志服務公網域名可能產生公網流量費用。更多信息,請參見按使用功能計費模式計費項。
消費目標
日志服務支持的基于規則消費目標如下表所示。
類型 | 目標 | 說明 |
多語言應用 | 多語言應用 | 基于Java、Python、Go等語言的應用基于規則消費組消費日志服務的數據。具體操作,請參見通過API消費和通過消費組消費日志。 最佳實踐: |
云產品 | 阿里云Flink | 您可以通過阿里云Flink實時計算消費日志服務的數據。具體操作,請參見日志服務SLS。 最佳實踐: |
流式計算 | Kafka | 您可以通過流式計算框架Kafka實時消費日志服務的數據。具體操作,請參見基于SPL的Kafka消費。 |
注意事項
基于規則消費需要在服務端進行復雜計算。由于SPL計算復雜度及數據特征的差異,數據讀取的服務端延遲可能會略有增加(例如處理5MB數據,延遲增加10~100ms之間)。然而,一般情況下,盡管服務端延遲有所增加,但整體端到端延遲(即從數據拉取到本地計算完成的總時間)通常會減少。
基于規則消費在SPL語法錯誤、源數據字段缺失等情況下,可能會導致獲取到的數據缺失或失敗,具體說明可以參考錯誤處理。
基于規則消費在配置SPL語句時,SPL語句長度(字符串長度)最大為4KB。