正則表達式是一種強大的文本匹配工具,可以用于在文本中查找特定的模式。本文將提供簡單且實用的正則表達式快速上手教程,幫助您快速掌握其基本用法。?
本文檔可能包含第三方產品信息,該信息僅供參考。阿里云對第三方產品的性能、可靠性以及操作可能帶來的潛在影響,不做任何暗示或其他形式的承諾。
如果您對正則表達式不夠熟悉,可以使用Regex101等工具進行練習和調試。這些工具支持直觀展示正則表達式和文本的匹配過程。本文以Regex101為例,介紹各個示例。
基本語法
正則表達式由不同類型的字符組成,包括普通字符、元字符、分隔符和轉義字符等。其中:
普通字符:用于匹配文本中出現的相同字符。
元字符:用于匹配特定的字符或字符集合。例如
.表示匹配任意字符,\d表示匹配數字等。分隔符:用于標記正則表達式的開始和結束,通常為
/或者#。轉義字符:使用
\將有特殊作用的字符(元字符、分隔符等)轉義為普通字符。例如\.表示匹配半角句號。
如下圖所示,Regex101工具默認在正則表達式a.\d\.前添加了分隔符/。其中,a表示匹配字母a,.表示匹配一個任意字符,\d表示匹配一個任意數字,\.表示匹配半角句號。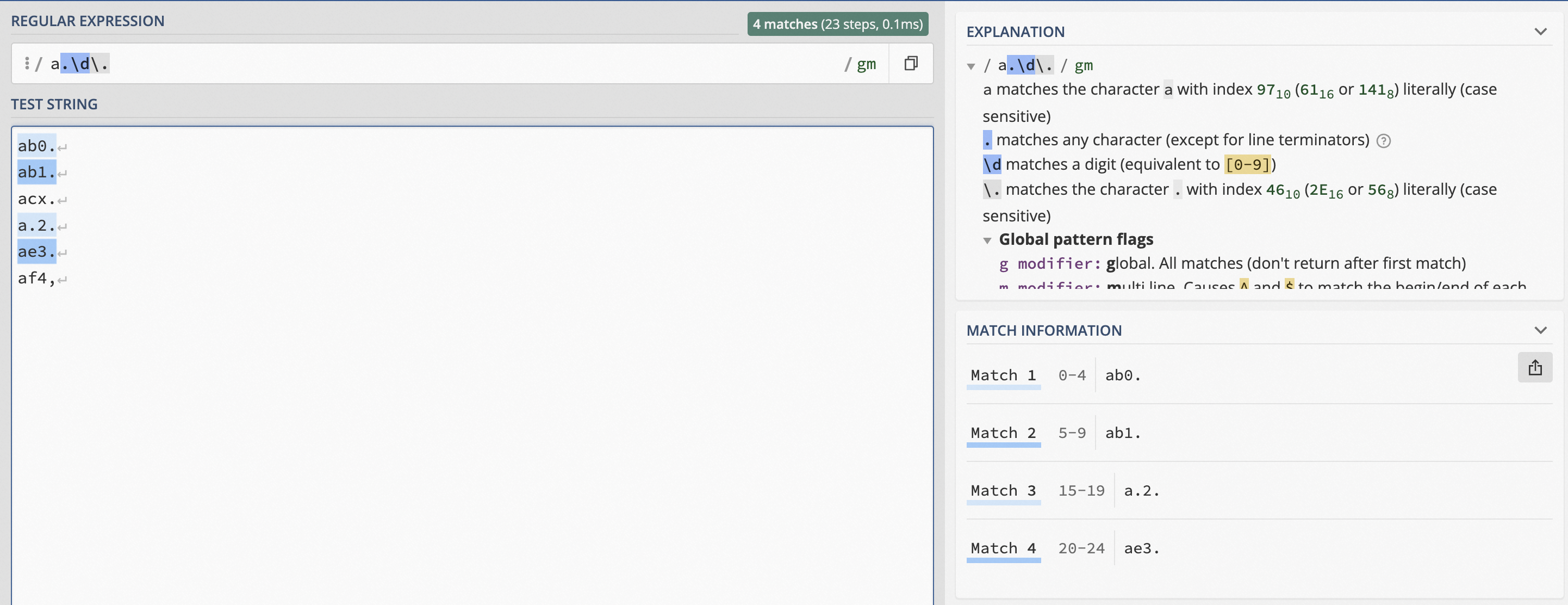
下表羅列了常用的特殊字符及其含義。
在不同的編程語言和正則表達式引擎中,支持的符號和語法可能有所差異。在實際編程中,需要結合具體的語言和工具了解其支持的正則表達式語法。
符號 | 含義 |
| 匹配任意一個字符,除了換行符。 |
| 匹配任意一個數字字符,等價于[0-9]。 |
| 匹配除數字字符之外的任意字符,等價于[^0-9]。 |
| 匹配任意一個字母、數字或下劃線字符,等價于[A-Za-z0-9_]。 |
| 匹配除字母、數字和下劃線字符之外的任意字符,等價于[^A-Za-z0-9_]。 |
| 匹配任意一個空白字符,包括空格、制表符、換行符等。 |
| 匹配除空白字符之外的任意字符。 |
| 匹配單詞邊界,即單詞字符和非單詞字符的交界處。 |
| 匹配非單詞邊界。 |
| 匹配前面的字符0次或多次。 |
| 匹配前面的字符1次或多次。 |
| 匹配前面的字符0次或1次。 |
| 將兩個匹配邏輯進行或運算。 |
| 匹配前面的字符n次。 |
| 匹配前面的字符至少n次。 |
| 匹配前面的字符至少n次,但不超過m次。 |
| 匹配字符集中的任意一個字符。 |
| 匹配除字符集中的字符之外的任意字符。 |
| 匹配字符串的開頭。 |
| 匹配字符串的結尾。 |
| 分組,將括號內的一組字符看作一個整體。 |
| 常用分隔符,用于標記正則表達式的開頭和結尾。 |
| 轉義字符,使用 |
示例
示例一:匹配含有某個關鍵詞的字符串
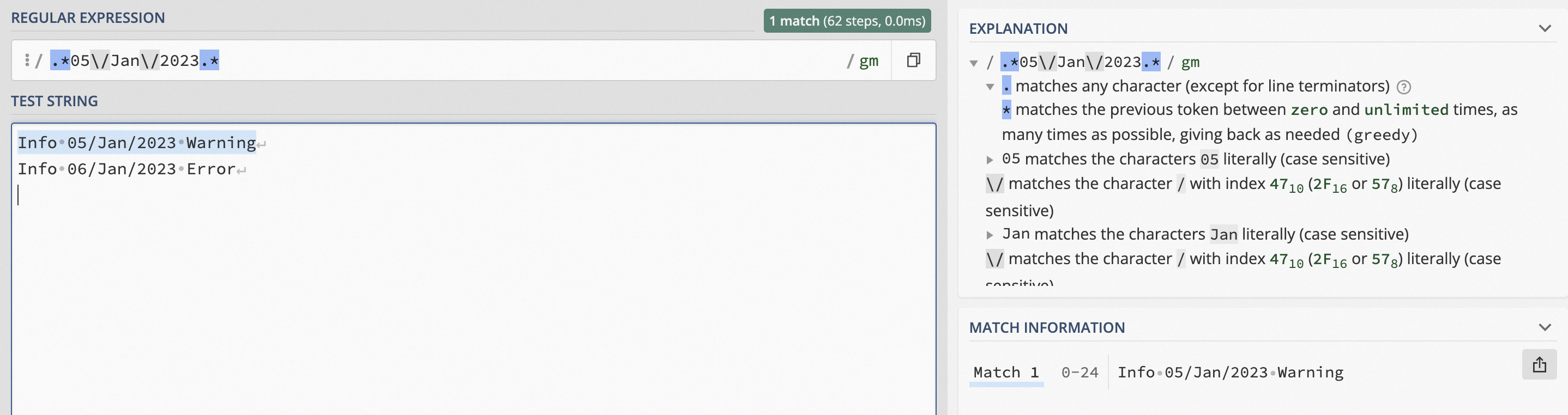
篩選出包含關鍵詞05/Jan/2023的日志。
日志樣例:Info 05/Jan/2023 Warning、Info 06/Jan/2023 Error
正則表達式:
.*05\/Jan\/2023.*.*表示匹配任意零個或多個字符,即05/Jan/2023前后可以有任意字符。05\/Jan\/2023表示匹配關鍵詞05/Jan/2023。因為Logtail所支持的正則表達式以
/作為分隔符,因此需要使用轉義字符\將其轉變為普通字符,即需要在/前增加轉義字符\。
示例二:匹配手機號碼
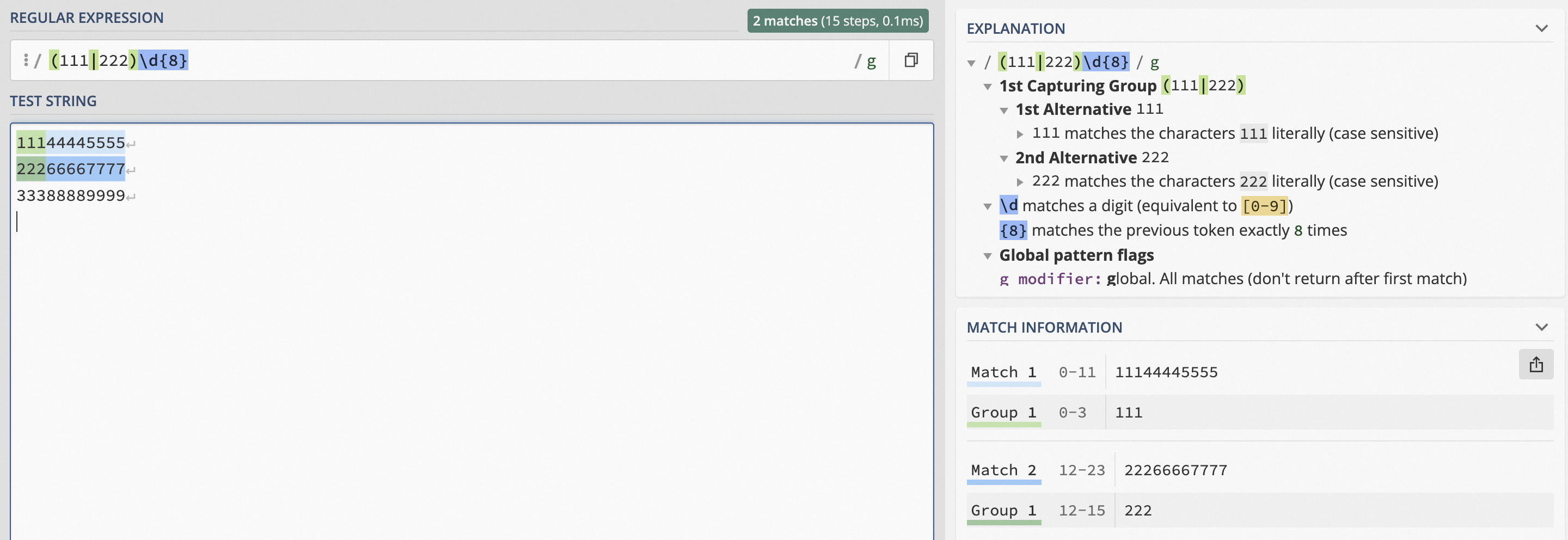
篩選出包含以111或222開頭的11位手機號碼的日志。
樣例:11144445555、22266667777、33388889999
正則表達式:
(111|222)\d{8}手機號碼前三位是運營商號碼,中間四位是地區編碼,后四位則是任意數字。假設運營商號碼只有111和222,地區編碼為任意數字。
(111|222)表示一個分組,包含了兩個可能的值,即111或222。\d表示匹配一個數字。{8}表示前面的\d需要匹配8次,即匹配8個數字。
示例三:匹配一個完整字符串
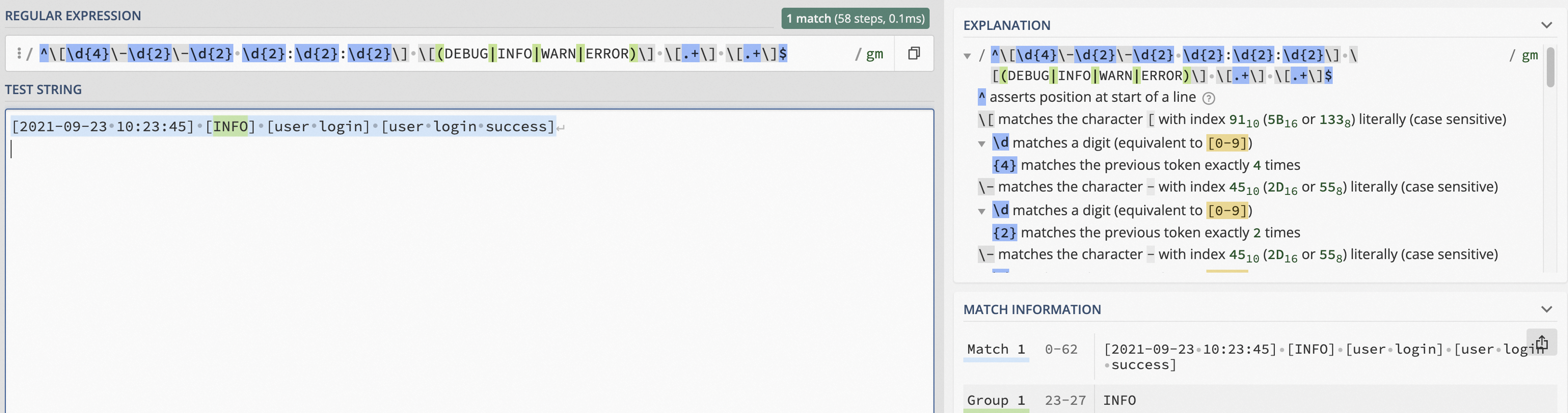
篩選出格式為[時間] [級別] [模塊] [信息]的日志,其中時間為yyyy-mm-dd hh:mm:ss格式,級別包括DEBUG、INFO、WARN和ERROR,模塊和信息為任意的字符串。
日志樣例:[2021-09-23 10:23:45] [INFO] [user login] [user login success]
正則表達式:
^\[\d{4}\-\d{2}\-\d{2} \d{2}:\d{2}:\d{2}\] \[(DEBUG|INFO|WARN|ERROR)\] \[.+\] \[.+\]$\[、\]表示匹配[]字符,因為[]在正則語法中有特殊含義,因此需要添加轉義字符\。\[\d{4}\-\d{2}\-\d{2} \d{2}:\d{2}:\d{2}\]表示匹配日期和時間。\[(DEBUG|INFO|WARN|ERROR)\]表示匹配各個日志級別。\[.+\] \[.+\]$表示匹配任意的非空字符串。
示例四:匹配不以某關鍵詞開頭的字符串
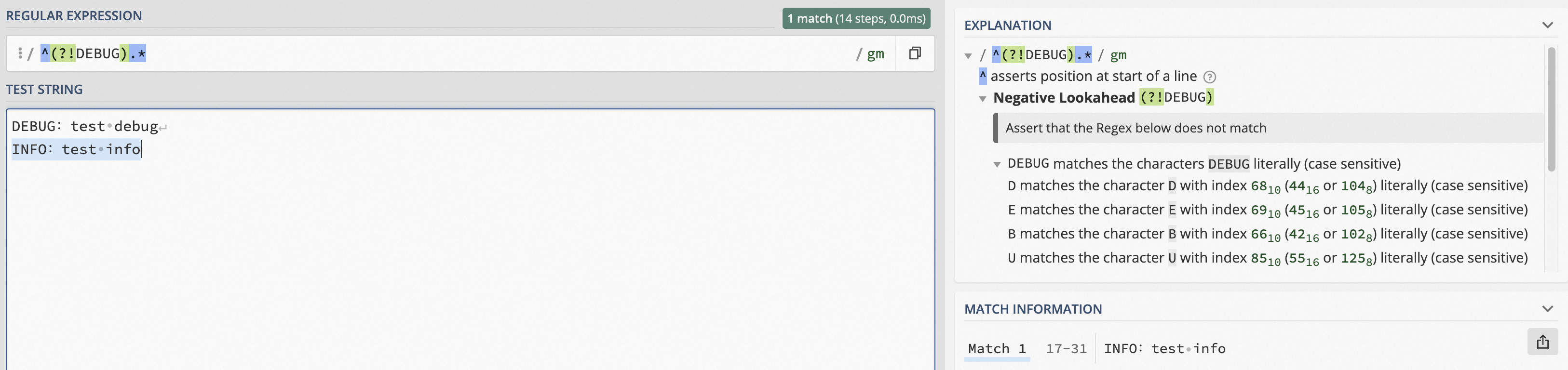
篩選出不以DEBUG開頭的日志。
日志樣例:DEBUG: test debug、INFO: test info
正則表達式:
^(?!DEBUG).*^表示字符串的開始位置,即DEBUG是處于字符串的開頭位置。(?!DEBUG)表示排除包含DEBUG的日志。(?!DEBUG)為正向否定預查,格式為(?!<pattern>),其中<pattern>為需要排除的內容。.*表示匹配任意字符,直到該行日志結束。
示例五:匹配不包含關鍵詞的字符串
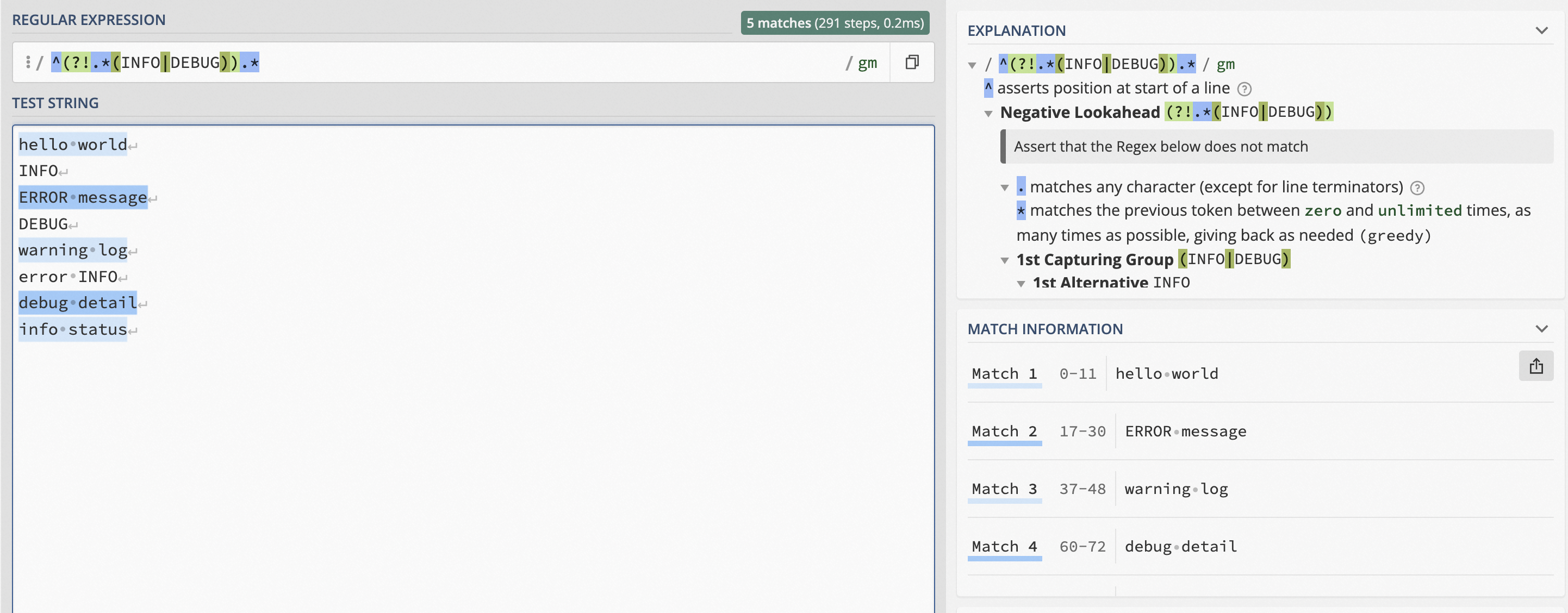
篩選出不包含INFO或DEBUG的日志。
日志樣例:hello world、INFO、ERROR message、DEBUG、warning log、error INFO、debug detail、info status
正則表達式:
^(?!.*(INFO|DEBUG)).*^表示字符串的開始位置,即INFO或DEBUG是處于字符串的開頭位置。(?!.*(INFO|DEBUG))表示排除包含INFO或DEBUG的日志。.*用于匹配任意字符,直到該行日志結束。