頻繁模式統計函數可以在給定的多屬性字段樣本中,挖掘出具有一定代表性的屬性組合,用來歸納當前日志。
pattern_stat
函數格式:
select pattern_stat(array[col1, col2, col3], array['col1_name', 'col2_name', 'col3_name'], array[col5, col6], array['col5_name', 'col6_name'], support_score, sample_ratio) 參數說明如下:
參數 | 說明 | 取值 |
array[col1, col2, col3] | 字符型數據的輸入列。 | 數組形式,例如:array[clientIP, sourceIP, path, logstore]。 |
array['col1_name', 'col2_name', 'col3_name'] | 字符型數據的輸入列的對應名稱。 | 數組形式,例如:array['clientIP', 'sourceIP', 'path', 'logstore']。 |
array[col5, col6] | 數值型數據的輸入列。 | 數組形式,例如:array[Inflow, OutFlow]。 |
array['col5_name', 'col6_name'] | 數值型數據的輸入列的對應名稱。 | 數組形式,例如array['Inflow', 'OutFlow']。 |
support_score | 樣本在進行模式挖掘時的支持度。 | double類型,取值為(0,1]。 |
sample_ratio | 采樣比率,默認為0.1,表示只拿10%全量集合。 | double類型,取值為(0,1]。 |
示例:
查詢分析:
* | select pattern_stat(array[ Category, ClientIP, ProjectName, LogStore, Method, Source, UserAgent ], array[ 'Category', 'ClientIP', 'ProjectName', 'LogStore', 'Method', 'Source', 'UserAgent' ], array[ InFlow, OutFlow ], array[ 'InFlow', 'OutFlow' ], 0.45, 0.3) limit 1000輸出結果:
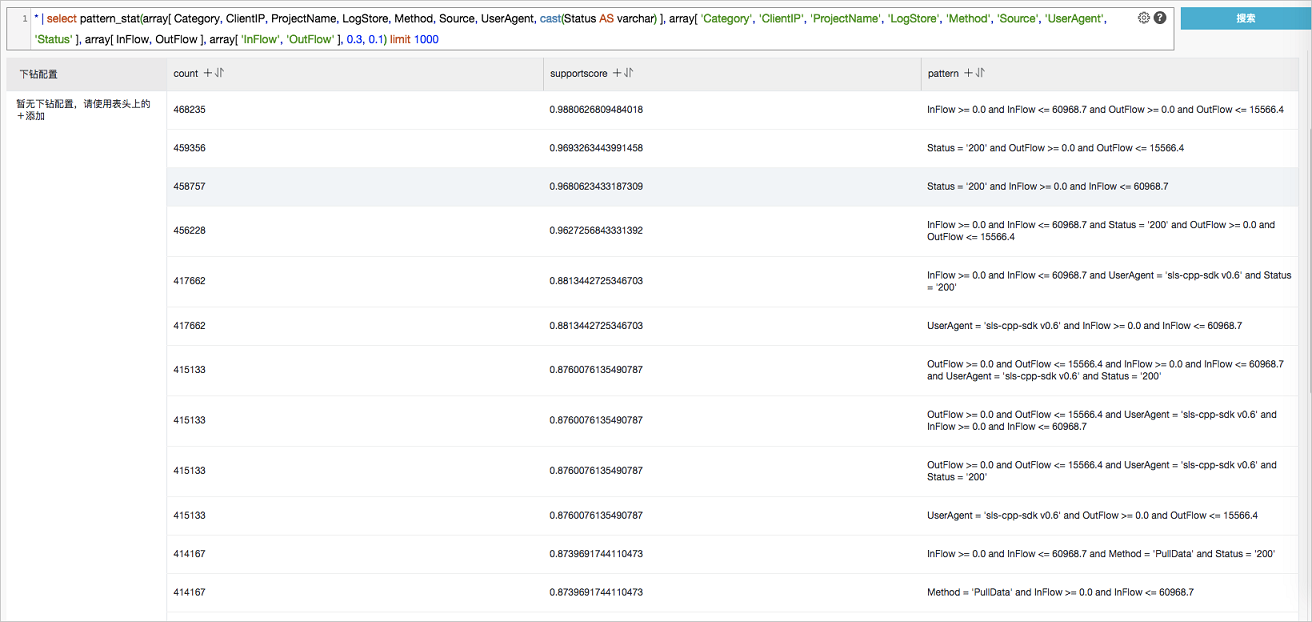
顯示項如下:
顯示項 | 說明 |
count | 當前模式所含樣本的數量。 |
support_score | 當前模式的支持度。 |
pattern | 模式的具體內容,按照條件查詢的形式組織。 |
文檔內容是否對您有幫助?