估算函數(shù)
本文介紹估算函數(shù)的基本語法及示例。
日志服務支持如下估算函數(shù)。
函數(shù)名稱 | 語法 | 說明 | 支持SQL | 支持SPL |
approx_distinct(x) | 估算x中不重復值的個數(shù),默認存在2.3%的標準誤差。 | √ | × | |
approx_distinct(x, e) | 估算x中不重復值的個數(shù),支持自定義標準誤差。 | √ | × | |
approx_percentile(x, percentage) | 對x進行正序排列,返回大約處于percentage位置的x。 | √ | × | |
approx_percentile(x, array[percentage01, percentage02...]) | 對x進行正序排列,返回大約處于percentage01、percentage02位置的x。 | √ | × | |
approx_percentile(x, weight, percentage) | 對x和權(quán)重的乘積進行正序排列,返回大約處于percentage位置的x。 | √ | × | |
approx_percentile(x, weight, array[percentage01, percentage02...]) | 對x和權(quán)重的乘積進行正序排列,返回大約處于percentage01、percentage02位置的x。 | √ | × | |
approx_percentile(x, weight, percentage, accuracy) | 對x和權(quán)重的乘積進行正序排列,返回大約處于percentage位置的x。支持設置返回結(jié)果的準確度。 | √ | × | |
numeric_histogram(bucket, x) | 按照bucket數(shù)量(直方圖列數(shù)),統(tǒng)計x的近似直方圖,返回結(jié)果為JSON類型。 | √ | × | |
numeric_histogram(bucket, x, weight) | 按照bucket數(shù)量(直方圖列數(shù)),統(tǒng)計x的近似直方圖,返回結(jié)果為JSON類型。支持對x設置權(quán)重。 | √ | × | |
numeric_histogram_u(bucket, x) | 按照bucket數(shù)量(直方圖列數(shù)),統(tǒng)計x的近似直方圖,返回結(jié)果為多行多列格式。 | √ | × |
approx_distinct函數(shù)
approx_distinct函數(shù)用于估算x中不重復值的個數(shù)。
語法
估算x中不重復值的個數(shù),默認存在2.3%的標準誤差。
approx_distinct(x)估算x中不重復值的個數(shù),支持自定義標準誤差。
approx_distinct(x, e)
參數(shù)說明
參數(shù) | 說明 |
x | 參數(shù)值為任意數(shù)據(jù)類型。 |
e | 自定義標準誤差,取值為[0.0115, 0.26]。 |
返回值類型
bigint類型。
示例
示例1:使用count函數(shù)計算PV,使用approx_distinct函數(shù)估算不重復的client_ip字段值作為UV,標準誤差為2.3%。
查詢和分析語句
* |SELECT count(*) AS PV, approx_distinct(client_ip) AS UV查詢和分析結(jié)果

示例2:使用count函數(shù)計算PV,使用approx_distinct函數(shù)估算不重復的client_ip字段值作為UV,自定義標準誤差為10%。
查詢和分析語句
* |SELECT count(*) AS PV, approx_distinct(client_ip,0.1) AS UV查詢和分析結(jié)果

approx_percentile函數(shù)
approx_percentile函數(shù)用于對x進行正序排列,返回大約處于percentage位置的數(shù)值。
語法
對x進行正序排列,返回處于percentage位置的x,返回結(jié)果為double類型。
approx_percentile(x, percentage)對x進行正序排列,返回處于percentage01、percentage02位置的x,返回結(jié)果為array(double,double)類型。
approx_percentile(x, array[percentage01, percentage02...])對x和權(quán)重的乘積進行正序排列,返回大約處于percentage位置的x,返回結(jié)果為double類型。
approx_percentile(x, weight, percentage)對x和權(quán)重的乘積進行正序排列,返回處于percentage01、percentage02位置的x,返回結(jié)果為array(double,double)類型。
approx_percentile(x, weight, array[percentage01, percentage02...])對x和權(quán)重的乘積進行正序排列,返回大約處于percentage位置的x,返回結(jié)果為double類型。支持設置返回結(jié)果的準確度。
approx_percentile(x, weight, percentage, accuracy)
參數(shù)說明
參數(shù) | 說明 |
x | 參數(shù)值為double類型。 |
percentage | 百分比值,取值范圍為[0,1]。 |
accuracy | 準確度,取值范圍為(0,1)。 |
weight | 權(quán)重,大于1的整數(shù)。 設置權(quán)重后,系統(tǒng)根據(jù)x與權(quán)重的乘積進行排序。 |
返回值類型
double類型或array(double,double)類型。
示例
示例1:對request_time列進行排序后,返回大約處于50%位置的request_time字段的值。
查詢和分析語句
*| SELECT approx_percentile(request_time,0.5)查詢和分析結(jié)果

示例2:對request_time列進行排序后,返回處于10%、20%及70%位置的request_time字段的值。
查詢和分析語句
*| SELECT approx_percentile(request_time,array[0.1,0.2,0.7])查詢和分析結(jié)果

示例3:根據(jù)request_time與權(quán)重的乘積對request_time列進行排序后,返回大約處于50%位置的request_time字段的值。其中,request_time<20時權(quán)重為100,否則權(quán)重為10。
查詢和分析語句
* | SELECT approx_percentile( request_time,case when request_time < 20 then 100 else 10 end, 0.5 )查詢和分析結(jié)果

示例4:根據(jù)request_time與權(quán)重的乘積對request_time列進行排序后,返回大約處于80%和90%位置的request_time字段的值。其中,request_time<20時權(quán)重為100,否則權(quán)重為10。
查詢和分析語句
* | SELECT approx_percentile( request_time,case when request_time < 20 then 100 else 10 end, array [0.8,0.9] )查詢和分析結(jié)果

示例5:根據(jù)request_time與權(quán)重的乘積對request_time列進行排序后,返回大約處于50%位置的request_time字段的值,準確度為0.2。其中,request_time<20時權(quán)重為100,否則權(quán)重為10。
查詢和分析語句
* | SELECT approx_percentile( request_time,case when request_time < 20 then 100 else 10 end, 0.5, 0.2 )查詢和分析結(jié)果
numeric_histogram函數(shù)
numeric_histogram函數(shù)按照bucket數(shù)量(直方圖列數(shù)),統(tǒng)計x的近似直方圖。返回結(jié)果為JSON類型。
語法
按照bucket數(shù)量(直方圖列數(shù)),統(tǒng)計x的近似直方圖。
numeric_histogram(bucket, x)按照bucket數(shù)量(直方圖列數(shù)),統(tǒng)計x的近似直方圖。支持為x設置權(quán)重。
numeric_histogram(bucket, x, weight)
參數(shù)說明
參數(shù) | 說明 |
bucket | 直方圖中列的個數(shù),bigint類型。 |
x | 參數(shù)值為double類型。 |
weight | 權(quán)重,大于0的整數(shù)。 設置權(quán)重后,系統(tǒng)根據(jù)x與權(quán)重的乘積進行分組。 |
返回值類型
JSON類型。
示例
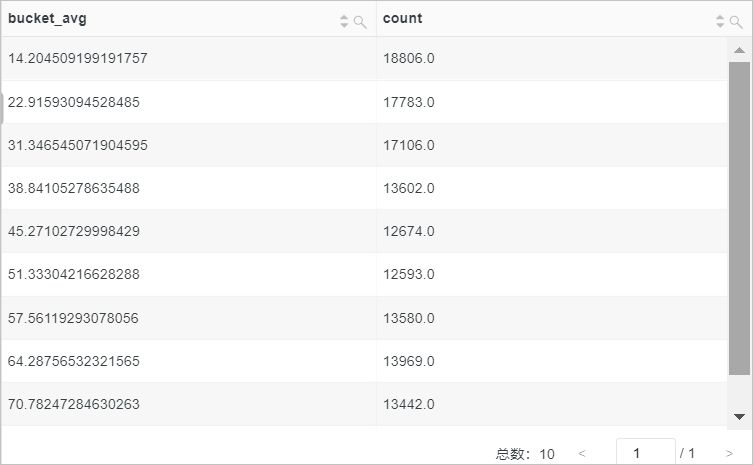
示例1:統(tǒng)計POST方法對應的請求時長的近似直方圖。
查詢和分析語句
request_method:POST | SELECT numeric_histogram(10,request_time)查詢和分析結(jié)果
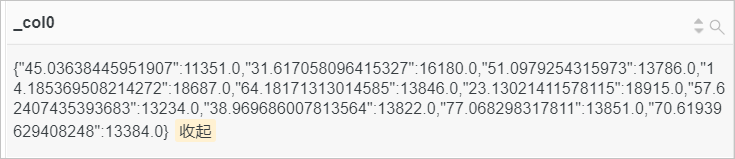
示例2:根據(jù)request_time與權(quán)重的乘積對請求時長進行分組,從而統(tǒng)計POST方法對應的請求時長的近似直方圖。
查詢和分析語句
request_method:POST| SELECT numeric_histogram(10, request_time,case when request_time<20 then 100 else 10 end)查詢和分析結(jié)果

numeric_histogram_u函數(shù)
numeric_histogram_u函數(shù)按照bucket數(shù)量(直方圖列數(shù)),統(tǒng)計x的近似直方圖。返回結(jié)果為多行多列格式。
語法
numeric_histogram_u(bucket, x)參數(shù)說明
參數(shù) | 說明 |
bucket | 直方圖中列的個數(shù),bigint類型。 |
x | 參數(shù)值為double類型。 |
返回值類型
double類型。
示例
統(tǒng)計POST方法對應的請求時長的近似直方圖。
查詢和分析語句
request_method:POST | select numeric_histogram_u(10,request_time)查詢和分析結(jié)果