本文介紹如何使用Jaeger客戶端對接日志服務。
背景信息
容器、Serverless編程方式提升了軟件交付與部署的效率。在架構的演化過程中,可以看到以下變化。
應用架構從單體系統逐步轉變為微服務,其中業務邏輯變為微服務之間的調用與請求。
資源角度來看,傳統服務器這個物理單位逐漸淡化,變為了虛擬資源模式。
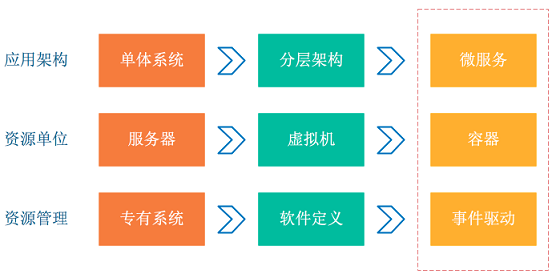
從以上兩個變化可以看到這種彈性、標準化的架構背后,原本運維與診斷的需求也變得復雜。為應對這種變化趨勢,誕生了一系列面向DevOps的診斷與分析系統,包括集中式日志系統(Logging)、集中式度量系統(Metrics)和分布式追蹤系統(Tracing)。
除Jaeger外,阿里云還提供支持OpenTracing鏈路追蹤產品XTrace。更多信息,請參見XTrace。
Logging,Metrics和Tracing的特點
Logging用于記錄離散的事件
例如,應用程序的調試信息或錯誤信息,Logging是我們診斷問題的依據。
Metrics用于記錄可聚合的數據
例如,隊列的當前深度可被定義為一個度量值,在元素入隊或出隊時被更新;HTTP請求個數可被定義為一個計數器,新請求到來時進行累加。
Tracing用于記錄請求范圍內的信息
例如,一次遠程方法調用的執行過程和耗時。Tracing是我們排查系統性能問題的利器。
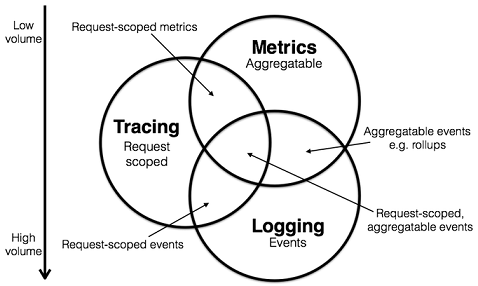
該圖片來自于Peter Bourgon網站。
通過以上信息,可以對已有系統進行分類。例如,Zipkin專注于Tracing領域;Prometheus開始專注于Metrics,隨著時間推移可能會集成更多的Tracing功能,但不太可能深入Logging領域;ELK、阿里云日志服務專注于Logging領域,但同時也不斷地集成其他領域的特性到系統中來,正向上圖中的圓心靠近。
更多三者關系詳細信息請參見Peter Bourgon。下面為您重點介紹Tracing。
Tracing
流行的Tracing軟件有:
Dapper(Google):各Tracer的基礎
StackDriver Trace(Google)
Zipkin(Twitter)
Appdash(golang)
鷹眼(Taobao)
諦聽(盤古,阿里云云產品使用的Trace系統)
云圖(螞蟻Trace系統)
sTrace(神馬)
X-ray(AWS)
分布式追蹤系統發展快,種類多,核心步驟一般有三個:
代碼埋點
數據存儲
查詢展示
下圖是一個分布式調用的例子,客戶端發起請求,請求首先到達負載均衡器,接著經過認證服務,計費服務,然后請求資源,最后返回結果。 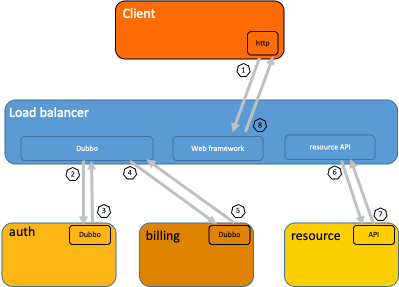 數據被采集存儲后,分布式追蹤系統一般會選擇使用包含時間軸的時序圖來呈現這個調用鏈。但在數據采集過程中,由于采集日志業務邏輯和用戶代碼深度融合,并且不同系統的API并不兼容,導致如果切換追蹤系統,會有較大改動。
數據被采集存儲后,分布式追蹤系統一般會選擇使用包含時間軸的時序圖來呈現這個調用鏈。但在數據采集過程中,由于采集日志業務邏輯和用戶代碼深度融合,并且不同系統的API并不兼容,導致如果切換追蹤系統,會有較大改動。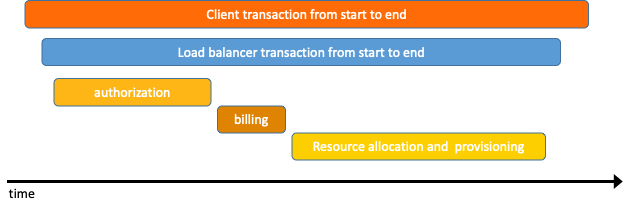
OpenTracing
為了解決不同的分布式追蹤系統API不兼容的問題,誕生了OpenTracing規范。OpenTracing是一個輕量級的標準化層,它位于應用程序/類庫和追蹤或日志分析程序之間。更多信息,請參見OpenTracing。
OpenTracing優勢:
OpenTracing已進入CNCF,為全球的分布式追蹤,提供統一的概念和數據標準。
OpenTracing通過提供平臺無關、廠商無關的API,使開發人員能夠方便的添加或更換追蹤系統。
OpenTracing數據模型:
OpenTracing中的Trace通過歸屬于此調用鏈的Span來隱性的定義。特別說明,一條Trace可以被認為是一個由多個Span組成的有向無環圖(DAG圖),Span與Span的關系被命名為References。如下示例,調用鏈就是由8個Span組成的。
單個 Trace 中,span 間的因果關系 [Span A] ←←←(the root span) | +------+------+ | | [Span B] [Span C] ←←←(Span C是Span A的孩子節點, ChildOf) | | [Span D] +---+-------+ | | [Span E] [Span F] >>> [Span G] >>> [Span H] ↑ ↑ ↑ (Span G在Span F后被調用, FollowsFrom)另外,基于時間軸的時序圖可以更好的展現Trace,可以使用以下示例如下:
單個Trace中,span間的時間關系 ––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–> time [Span A···················································] [Span B··············································] [Span D··········································] [Span C········································] [Span E·······] [Span F··] [Span G··] [Span H··]每個Span包含以下對象:
An operation name:操作名稱。
A start timestamp:起始時間。
A finish timestamp:結束時間。
Span Tag:一組鍵值對構成的Span標簽集合。鍵值對中,鍵必須為string,值可以是字符串、布爾、或者數字類型。
Span Log:一組span的日志集合。每次log操作包含一個鍵值對,以及一個時間戳。鍵值對中,鍵類型必須為string,值可以是任意類型。不是所有的支持OpenTracing的Tracer,都需要支持所有的值類型。
SpanContext:Span上下文對象。每個SpanContext包含以下狀態:
任何一個OpenTracing的實現,都需要將當前調用鏈的狀態(例如:Trace和Span的ID),依賴一個獨特的Span去跨進程邊界傳輸。
Baggage Items是Trace的隨行數據,是一個鍵值對集合,存在于Trace中,也需要跨進程邊界傳輸。
References(Span間關系):相關的零個或者多個Span(Span間通過SpanContext建立這種關系)。
更多關于OpenTracing數據模型的知識,請參見OpenTracing數據模型。
關于所有的OpenTracing實現,請參見OpenTracing。在這些實現中,比較流行的為Jaeger和Zipkin。更多信息,請參見Jaeger和Zipkin。
Jaeger
Jaeger是Uber推出的一款開源分布式追蹤系統,兼容OpenTracing API。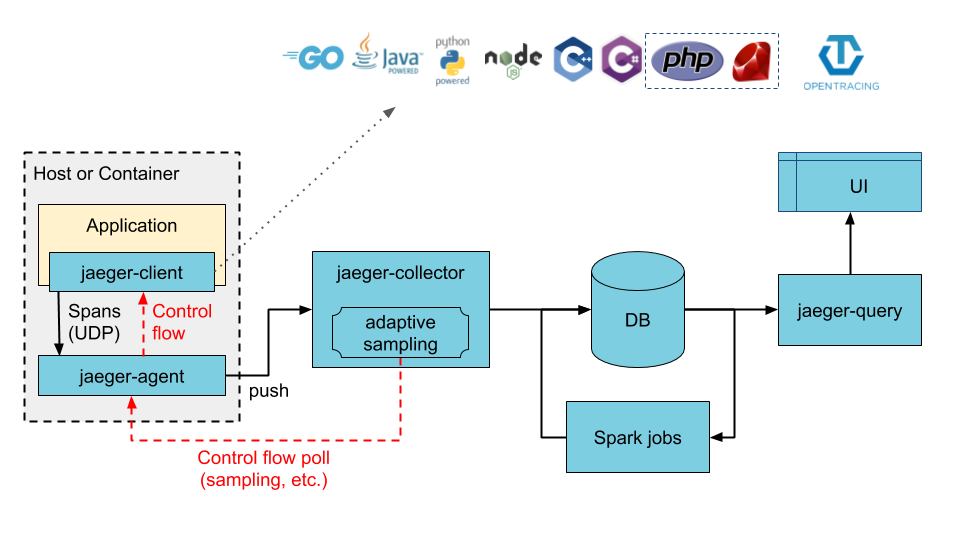
該圖片來自于JAEGER網站。
如上圖所示,Jaeger主要由以下幾部分組成。
Jaeger Client:為不同語言實現了符合OpenTracing標準的SDK。應用程序通過API寫入數據,client library把Trace信息按照應用程序指定的采樣策略傳遞給jaeger-agent。
Agent:它是一個監聽在UDP端口上接收span數據的網絡守護進程,它會將數據批量發送給collector。它被設計成一個基礎組件,部署到所有的宿主機上。Agent將client library和collector解耦,為client library屏蔽了路由和發現collector的細節。
Collector:接收jaeger-agent發送來的數據,然后將數據寫入后端存儲。Collector被設計成無狀態的組件,因此您可以同時運行任意數量的jaeger-collector。
Data Store:后端存儲被設計成一個可插拔的組件,支持將數據寫入cassandra、elastic search。
Query:接收查詢請求,然后從后端存儲系統中檢索Trace并通過UI進行展示。Query是無狀態的,您可以啟動多個實例,把它們部署在Nginx負載均衡器后面。
Jaeger on Alibaba Cloud Log Service
Jaeger on Alibaba Cloud Log Service是基于Jaeger開發的分布式追蹤系統,支持將采集到的追蹤數據持久化到日志服務中,并通過Jaeger的原生接口進行查詢和展示。 更多信息,請參見Jaeger on Alibaba Cloud Log Service。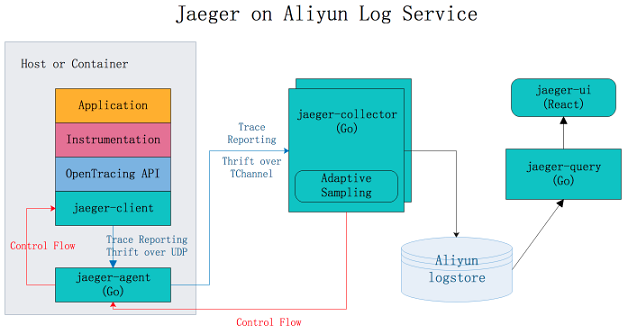
Jaeger的優勢:
原生Jaeger僅支持將數據持久化到cassandra和Elasticsearch中,您需要自行維護后端存儲系統的穩定性,調節存儲容量。Jaeger on Alibaba Cloud Log Service借助阿里云日志服務的海量數據處理能力,讓您享受Jaeger在分布式追蹤領域給您帶來便捷的同時無需過多關注后端存儲系統的問題。
Jaeger UI部分僅提供查詢、展示Trace的功能,對分析問題、排查問題支持不足。使用Jaeger on Alibaba Cloud Log Service,您可以借助日志服務強大的查詢分析能力,助您更快分析出系統中存在的問題。
Jaeger on Alibaba Cloud Log Service配置步驟請參見GitHub。
Jaeger配置示例
HotROD是由多個微服務組成的應用程序,它使用了OpenTracing API記錄Trace信息。
下面通過一段視頻向您展示如何使用Jaeger on Alibaba Cloud Log Service診斷HotROD出現的問題。視頻包含以下內容:
配置日志服務
通過docker-compose運行Jaeger。
運行HotROD。
通過Jaeger UI檢索特定的Trace。
通過Jaeger UI查看Trace的詳細信息。
通過Jaeger UI定位應用的性能瓶頸。
通過日志服務管理控制臺,定位應用的性能瓶頸。
應用程序調用OpenTracing API。
示例中使用的query語句及其含義如下:
以分鐘為單位統計frontend服務的HTTP GET/dispatch操作的平均延遲以及請求個數。
process.serviceName: "frontend" and operationName: "HTTP GET /dispatch" | select from_unixtime( __time__ - __time__ % 60) as time, truncate(avg(duration)/1000/1000) as avg_duration_ms, count(1) as count group by __time__ - __time__ % 60 order by time desc limit 60比較兩條Trace各個操作的耗時。
TraceID: "Trace1" or TraceID: "Trace2" | select operationName, (max(duration)-min(duration))/1000/1000 as duration_diff_ms group by operationName order by duration_diff_ms desc統計延遲大于1.5 s的Trace的IP情況。
process.serviceName: "frontend" and operationName: "HTTP GET /dispatch" and duration > 1500000000 | select "process.tags.ip" as IP, truncate(avg(duration)/1000/1000) as avg_duration_ms, count(1) as count group by "process.tags.ip"