負載均衡通過健康檢查來判斷后端服務器的業務可用性。開啟健康檢查功能后,當某臺后端服務器健康檢查出現異常時,負載均衡會自動將新的請求分發到其他健康檢查正常的后端服務器上;而當該后端服務器恢復正常運行時,負載均衡會將其自動恢復到負載均衡服務中進行流量轉發。健康檢查機制提高了用戶業務整體可用性,避免了局部后端服務器異常對總體服務的影響,是保證業務高可用的重點要素。
如果您的業務對負載敏感性高,高頻率的健康檢查探測可能會對正常業務訪問造成影響。您可以結合業務情況,通過降低健康檢查頻率、增大健康檢查間隔、七層檢查修改為四層檢查等方式,來降低對業務的影響。但為了保障業務的持續可用,不建議關閉健康檢查。
健康檢查過程
負載均衡采用集群部署。四層集群或七層集群內的相關節點服務器同時承載了數據轉發和健康檢查職責。
四層集群內不同服務器分別獨立、并行地根據負載均衡策略進行數據轉發和健康檢查操作。如果某一臺四層集群中的服務器對某一臺后端服務器健康檢查失敗,則該四層集群中的服務器將不會再將新的客戶端請求分發給相應的異常的后端服務器。四層集群內所有服務器同步進行該操作。
如下圖所示,傳統型負載均衡CLB健康檢查使用的地址段是100.64.0.0/10,后端服務器務必不能屏蔽該地址段。您無需在ECS安全組中額外針對該地址段配置放行策略,但如有配置iptables等安全策略,請務必放行(100.64.0.0/10 是阿里云保留地址,其他用戶無法分配到該網段內,不會存在安全風險)。

HTTP/HTTPS監聽健康檢查機制
針對七層(HTTP或HTTPS協議)監聽,健康檢查通過HEAD或GET探測來獲取狀態信息,如下圖所示。
對于HTTPS監聽,證書在負載均衡系統中進行管理。負載均衡與后端服務器之間的數據交互(包括健康檢查數據和業務交互數據)使用HTTP,不再通過HTTPS進行傳輸,以提高系統性能。

七層監聽的檢查機制如下:
七層集群中的服務器根據監聽的健康檢查配置,向后端服務器的內網IP+【健康檢查端口】+【檢查路徑】發送HTTP HEAD請求(包含設置的【域名】)。
后端服務器收到請求后,根據相應服務的運行情況,返回HTTP狀態碼。
如果在【響應超時時間】之內,七層集群中的服務器沒有收到后端服務器返回的信息,則認為服務無響應,判定健康檢查失敗。
如果在【響應超時時間】之內,七層集群中的服務器成功接收到后端服務器返回的信息,則將該返回信息與配置的狀態碼進行比對。如果匹配則判定健康檢查成功,反之則判定健康檢查失敗。
TCP監聽健康檢查機制
針對四層TCP監聽,為了提高健康檢查效率,健康檢查通過定制的TCP探測來獲取狀態信息,如下圖所示。

TCP監聽的檢查機制如下:
四層集群中的服務器根據監聽的健康檢查配置,向后端服務器的內網IP+【健康檢查端口】發送TCP SYN數據包。
后端服務器收到請求后,如果相應端口正在正常監聽,則會返回SYN+ACK數據包。
如果在【響應超時時間】之內,四層集群中的服務器沒有收到后端服務器返回的數據包,則認為服務無響應,判定健康檢查失敗,并向后端服務器發送RST數據包中斷TCP連接。
如果在【響應超時時間】之內,四層集群中的服務器成功收到后端服務器返回的數據包,則認為服務正常運行,判定健康檢查成功,而后向后端服務器發送RST數據包中斷TCP連接。
正常的TCP三次握手,四層集群中的服務器在收到后端服務器返回的SYN+ACK數據包后,會進一步發送ACK數據包,隨后立即發送RST數據包中斷TCP連接。
該實現機制可能會導致后端服務器認為相關TCP連接出現異常(非正常退出),并在業務軟件如Java連接池等日志中拋出相應的錯誤信息,如Connection reset by peer。
解決方案:
TCP監聽采用HTTP方式進行健康檢查。
在后端服務器配置了獲取客戶端真實IP后,忽略來自前述負載均衡服務地址段相關訪問導致的連接錯誤。
UDP監聽健康檢查
針對四層UDP監聽,健康檢查通過UDP報文探測來獲取狀態信息,如下圖所示。

UDP監聽的檢查機制如下:
四層集群中的服務器根據監聽的健康檢查配置,向后端服務器的內網IP+【健康檢查端口】發送UDP報文。
如果后端服務器相應端口未正常監聽,則系統會返回類似
port XX unreachable的ICMP報錯信息,反之不做任何處理。如果在【響應超時時間】之內,四層集群中的服務器收到了后端服務器返回的上述錯誤信息,則認為服務異常,判定健康檢查失敗。
如果在【響應超時時間】之內,四層集群中的服務器沒有收到后端服務器返回的任何信息,則認為服務正常,判定健康檢查成功。
當前UDP協議服務健康檢查可能存在服務真實狀態與健康檢查不一致的問題:
如果后端服務器是Linux服務器,在大并發場景下,由于Linux的防ICMP攻擊保護機制,會限制服務器發送ICMP的速度。此時,即便服務已經出現異常,但由于無法向前端返回port XX unreachable報錯信息,會導致負載均衡由于沒收到ICMP應答進而判定健康檢查成功,最終導致服務真實狀態與健康檢查不一致。
解決方案:
負載均衡通過發送您指定的字符串到后端服務器,必須得到指定應答后才認為檢查成功。但該實現機制需要客戶端程序配合應答。
健康檢查時間窗
健康檢查機制的引入,有效提高了業務服務的可用性。但是,為了避免頻繁的健康檢查失敗引起的切換對系統可用性的沖擊,健康檢查只有在健康檢查時間窗內連續多次檢查成功或失敗后,才會進行狀態切換。健康檢查時間窗由以下三個因素決定:
健康檢查間隔(每隔多久進行一次健康檢查)
響應超時時間 (等待服務器返回健康檢查的時間)
檢查閾值(健康檢查連續成功或失敗的次數)
健康檢查時間窗口的計算方法如下:
健康檢查失敗時間窗口=響應超時時間×不健康閾值+檢查間隔×(不健康閾值-1)
健康檢查成功時間窗口= (健康檢查成功響應時間x健康閾值)+檢查間隔x(健康閾值-1)
說明健康檢查成功響應時間是一次健康檢查請求從發出到響應的時間。當采用TCP方式健康檢查時,由于僅探測端口是否存活,因此該時間非常短,幾乎可以忽略不計。當采用HTTP方式健康檢查時,該時間取決于應用服務器的性能和負載,但通常都在秒級以內。

健康檢查狀態對請求轉發的影響如下:
如果目標后端服務器的健康檢查失敗,新的請求不會再分發到相應后端服務器上,所以對前端訪問沒有影響。
如果目標后端服務器的健康檢查成功,新的請求會分發到該后端服務器上,前端訪問正常。
如果目標后端服務器存在異常,正處于健康檢查失敗時間窗,而健康檢查還未達到檢查失敗判定次數(默認為三次),則相應請求還是會被分發到該后端服務器,進而導致前端訪問請求失敗。

健康檢查響應超時和健康檢查間隔示例
以如下健康檢查配置為例:
響應超時時間:5秒
健康檢查間隔:2秒
健康閾值:3次
不健康閾值:3次
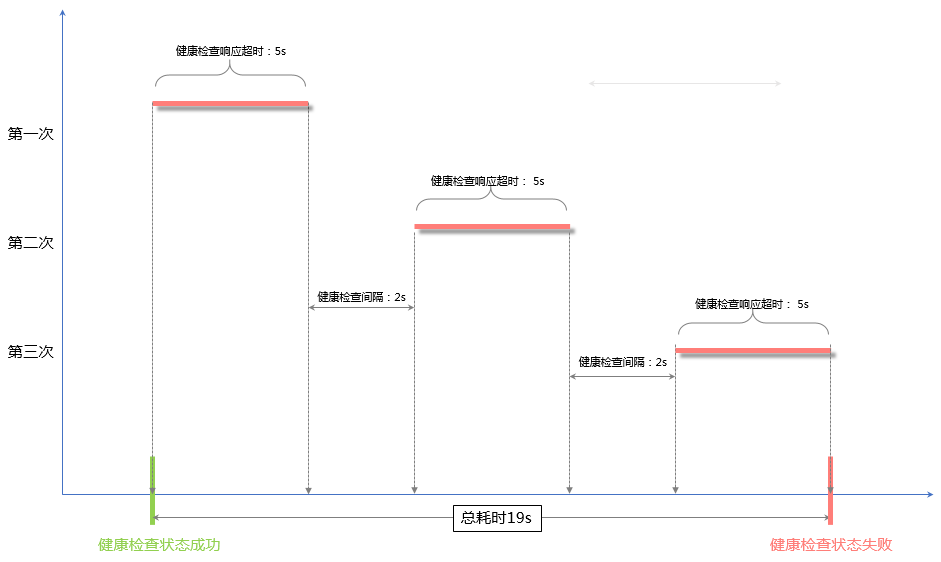
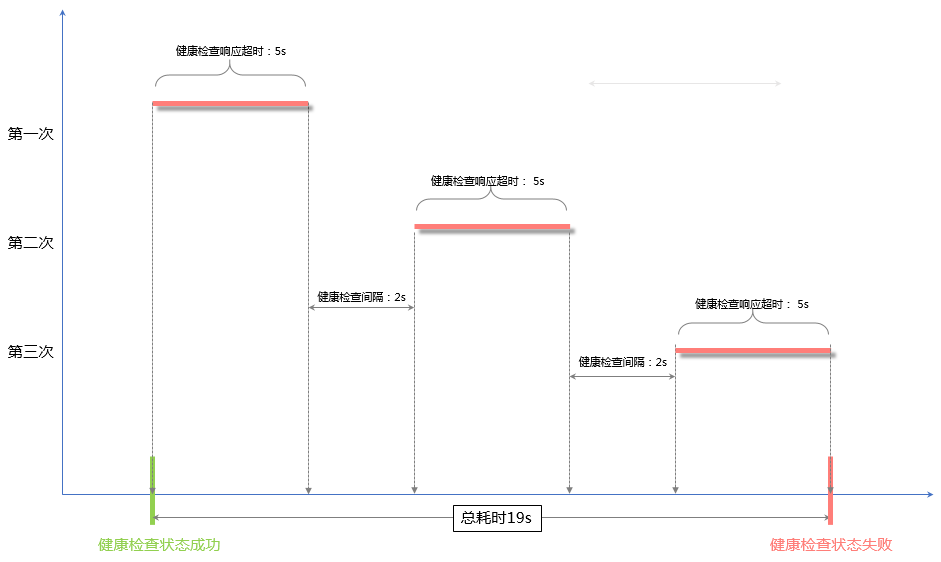
健康檢查失敗時間窗口=響應超時時間×不健康閾值+檢查間隔×(不健康閾值-1),5×3+2×(3-1)=19s,即以19s為一個時間窗,健康檢查響應時間超過19s,健康檢查狀態為不健康。
從健康狀態到不健康狀態的檢查過程如下圖所示:
健康檢查成功時間窗口= (健康檢查成功響應時間×健康閾值)+檢查間隔×(健康閾值-1),(1×3)+2×(3-1)=7s,即以7s為一個時間窗,健康檢查成功響應時間低于7s,健康檢查狀態為健康。
健康檢查成功響應時間是一次健康檢查請求從發出到響應的時間。當采用TCP方式健康檢查時,由于僅探測端口是否存活,因此該時間非常短,幾乎可以忽略不計。當采用HTTP方式健康檢查時,該時間取決于應用服務器的性能和負載,但通常都在秒級以內。
從不健康狀態到健康的狀態檢查過程如下圖所示(假設服務器響應健康檢查請求需要耗時1s):

HTTP健康檢查中域名的設置
當使用HTTP方式進行健康檢查時,可以設置健康檢查的域名,但并非強制選項。因為有些應用服務器會對請求中的host字段做校驗,即要求請求頭中必須存在host字段。如果在健康檢查中配置了域名,則SLB會將域名配置到host字段中去,反之,如果沒有配置域名,CLB則不會在請求中附帶host字段,因此健康檢查請求就會被服務器拒絕,可能導致健康檢查失敗。
綜上原因,如果您的應用服務器需要校驗請求的host字段,那么則需要配置相關的域名,確保健康檢查正常工作。