本文介紹容器事件監控如何接入可觀測監控 Prometheus 版以及如何查看監控大盤和設置告警規則。事件監控是Kubernetes中的一種監控方式,可以彌補資源監控在實時性、準確性和場景上的不足。您可以通過使用NPD(node-problem-detector),結合SLS的Kubernetes事件中心,配置NPD集群檢查項以及異常事件離線功能,使用釘釘、SLS離線Kubernetes事件及EventBridge離線Kubernetes事件,實時監控集群的異常與問題。
前提條件
步驟一:接入容器事件監控
登錄Prometheus控制臺,在左側導航欄單擊接入中心。
單擊容器事件監控卡片,選擇待接入的容器服務集群,然后根據控制臺指引完成組件接入。
說明Prometheus服務接入容器事件監控后,完整的數據接入大概需要1~2分鐘左右。數據未完整接入前,監控大盤不顯示數據。
步驟二:查看監控大盤
可觀測監控 Prometheus 版默認內置了很多容器監控大盤,包括集群概覽、核心組件、Node、Pod等監控能力,在容器服務控制臺、ARMS控制臺、Prometheus控制臺都有透出。您可以通過以下方式查看監控大盤。
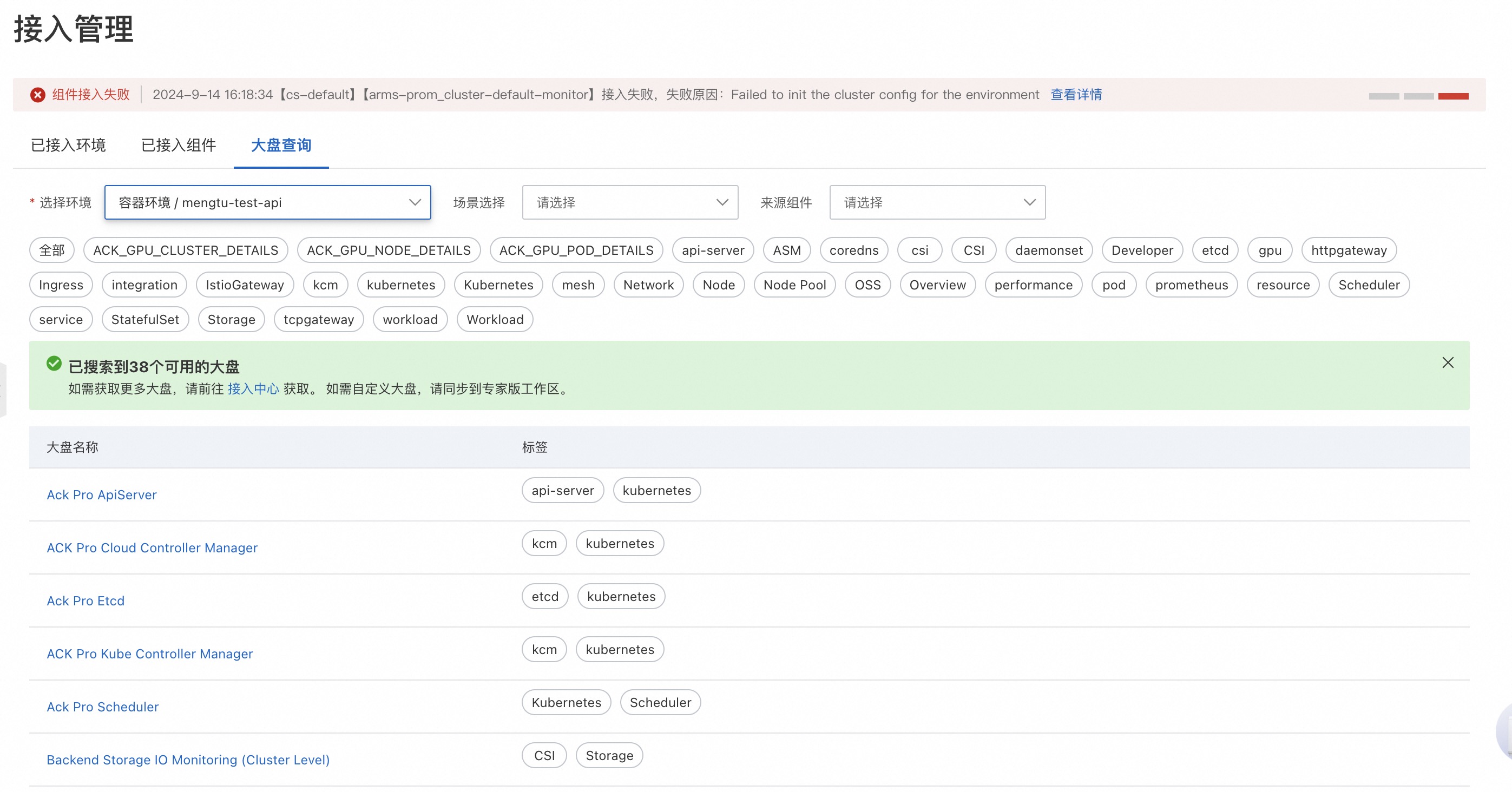
登錄Prometheus控制臺,在左側導航欄單擊接入管理。
在接入管理頁面,單擊大盤查詢頁簽。在容器環境中選擇待查看的集群,即可查看對應的監控大盤。
步驟三:設置告警
登錄Prometheus控制臺,在左側導航欄單擊接入管理。
在接入管理頁面,單擊已接入環境頁簽。選擇容器環境,然后單擊目標環境名稱,進入容器環境詳情頁面。
在組件管理頁簽,查看Prometheus內置的告警通知。
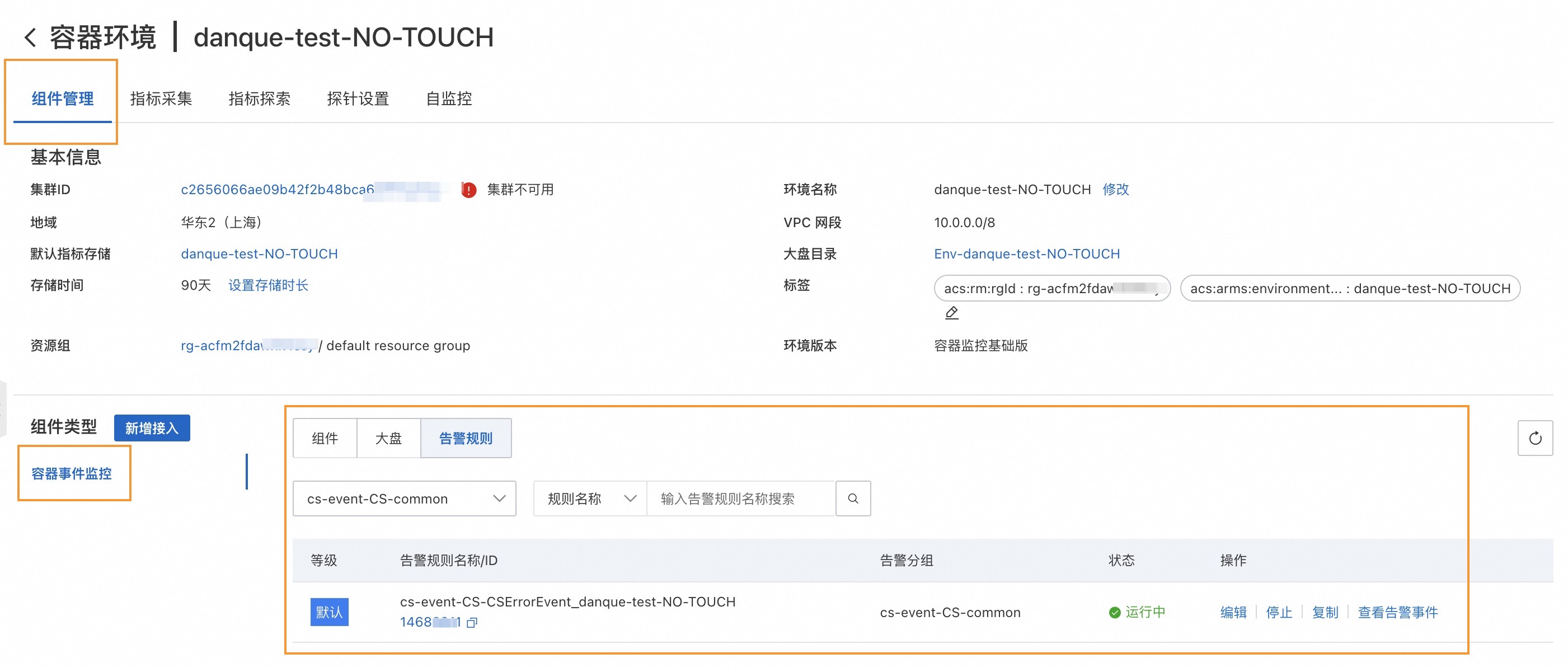
內置的告警規則會產生告警事件,但是不會進行告警通知。如果您希望將告警通知發送到郵件或其他平臺,可以單擊編輯配置通知方式。
在告警配置頁面,您也可以自定義告警閾值、持續時間、告警內容等,告警詳細配置,請參見創建Prometheus告警規則。

采集指標說明
指標名稱 | 類型 | 指標描述 |
eventer_events_error_total | COUNTER | 錯誤類型的事件 |
eventer_events_normal_total | COUNTER | 正常類型的事件 |
eventer_events_warning_total | COUNTER | 異常類型的事件 |
eventer_exporter_duration_milliseconds | SUMMARY | 導出事件以毫秒為單位的時間。 |
eventer_manager_last_time_seconds | GAUGE | 自Unix時代以來,eventer housekeep的最后一次時間(以秒為單位)。 |
eventer_scraper_duration_milliseconds | SUMMARY | 抓取事件所花費的時間(以毫秒為單位)。 |
eventer_scraper_events_total_number | COUNTER | 事件總數 |
eventer_scraper_last_time_seconds | GAUGE | 自Unix時代以來的最后一次事件時間(以秒為單位)。 |