在使用Spring Boot應用過程中,為了對系統的狀態進行持續地觀測,您可以將Spring Boot應用接入Prometheus監控。本文介紹如何將Spring Boot應用快速接入Prometheus監控。
背景信息
對于開發者而言,大部分傳統SSM結構的MVC應用背后的糟糕體驗都是來自于搭建項目時的大量配置,稍有不慎就可能導致配置出錯。為了解決這個問題,Spring Boot應運而生。Spring Boot的核心價值就是自動配置,只要存在相應Jar包,Spring Boot可以自動配置,如果默認配置不能滿足需求,您還可以替換掉自動配置類,使用自定義配置快速構建企業級應用程序。
構建Spring Boot應用以及該應用上線之后,您需要對該應用進行監測。一般來說,搭建一套完整易用的監測系統主要包含以下幾個關鍵部分。
收集監測數據
目前,行業常見的收集監測數據方式主要分為推送(Push)和抓取(Pull)兩個模式。以越來越廣泛應用的Prometheus監測體系舉例,可觀測監控 Prometheus 版就是以抓取(Pull)模式運行的典型系統。應用及基礎設施的監測數據以OpenMetrics標準接口的形式暴露給可觀測監控 Prometheus 版,然后由可觀測監控 Prometheus 版進行定期抓取并長期存儲。
OpenMetrics,是云原生、高度可擴展的指標協議。 OpenMetrics定義了大規模上報云原生指標的事實標準,并支持文本表示協議和Protocol Buffers協議,文本表示協議在其中更為常見,也是在可觀測監控 Prometheus 版進行數據抓取時默認采用的協議。下圖是一個基于OpenMetrics格式的指標表示格式樣例。
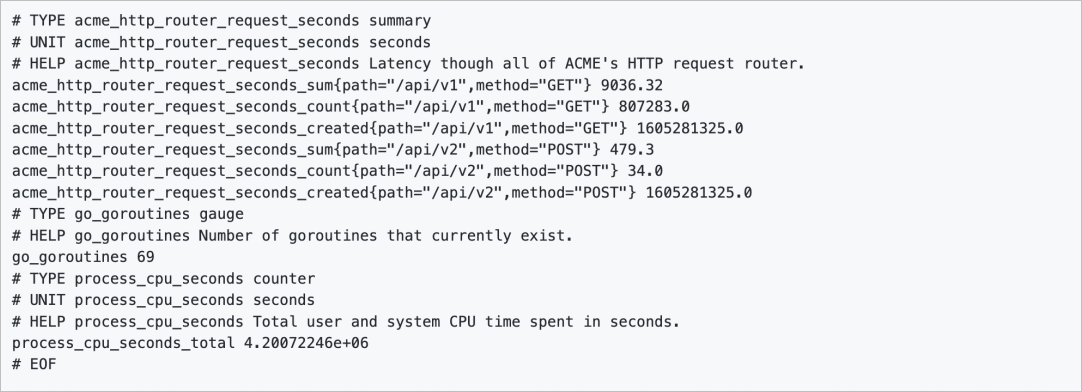
指標的數據模型由指標(Metric)名,以及一組Key/Value標簽(Label)定義的,具有相同的度量名稱以及標簽屬于相同時序集合。例如acme_http_router_request_seconds_sum{path="/api/v1",method="GET"} 可以表示指標名為acme_http_router_request_seconds_sum,標簽method值為GET的一次采樣點數據。采樣點內包含一個Float64值和一個毫秒級的UNIX時間戳。隨著時間推移,這些收集起來的采樣點數據將在圖表上實時繪制動態變化的線條。
目前,對于云原生體系下的絕大多數基礎組件能夠支持OpenMetrics的文本協議格式暴露指標,對于暫不能支持自身暴露指標的組件, Prometheus社區也存在極其豐富的Prometheus Exporter供開發及運維人員使用。這些組件(或Exporter)通過響應來自可觀測監控 Prometheus 版的定期抓取請求來及時地將自身的運行狀況記錄到可觀測監控 Prometheus 版以便后續的處理及分析。對于應用開發者,您還可以通過可觀測監控 Prometheus 版的多語言SDK,進行代碼埋點,將自身的業務指標也接入到上述的Prometheus生態當中。
數據可視化及分析
在獲取應用或基礎設施運行狀態、資源使用情況,以及服務運行狀態等直觀信息后,通過查詢和分析多類型、多維度信息能夠方便地對節點進行跟蹤和比較。同時,通過標準易用的可視化大盤去獲知當前系統的運行狀態。比較常見的解決方案就是Grafana,作為開源社區中目前熱度很高的數據可視化解決方案,Grafana提供了豐富的圖表形式與模板。在可觀測監控 Prometheus 版中,也為您提供了基于Grafana全托管版的監測數據查詢、分析及可視化。
及時的告警和應急管理
當業務即將出現故障時,監測系統需要迅速反應并通知管理員,從而能夠對問題進行快速的處理或者提前預防問題的發生,避免出現對業務的影響。當問題發生后,管理員需要對問題進行認領和處理。通過對不同監測指標以及歷史數據的分析,能夠找到并解決根源問題。
接入流程概述
針對Spring Boot應用,社區提供了開箱即用的Spring Boot Actuator框架,方便Java開發者進行代碼埋點和監測數據收集、輸出。從Spring Boot 2.0開始,Actuator將底層改為Micrometer,同時提供了更強、更靈活的監測能力。Micrometer是一個監測門面,可以類比成監測界的Slf4j ,借助Micrometer,應用則能夠對接各種監測系統。例如,AppOptics、Datadog、Elastic、InfluxDB以及可觀測監控 Prometheus 版等。
Micrometer在將可觀測監控 Prometheus 版指標對接到Java應用的指標時,支持應用開發者用三個類型的語義來映射:
Micrometer指標類型 | 可觀測監控 Prometheus 版監控的指標類型 | 典型用途 |
Counter | Counter | 計數器,單調遞增場景。例如,統計PV和UV,接口調用次數等。 |
Gauge | Gauge | 持續波動的變量。例如,資源使用率、系統負載、請求隊列長度等。 |
Timer | Histogram | 統計數據分布。例如,統計某接口調用延時的P50、P90、P99等。 |
DistributionSummary | Summary | 統計數據分布,與Histogram用途類似。 |
Micrometer中的Counter指標類型對應于可觀測監控 Prometheus 版中的Counter指標類型,用來描述一個單調遞增的變量。如某個接口的訪問次數、緩存命中或者訪問總次數等。Timer在邏輯上蘊含了Counter,即如果使用Timer采集每個接口的響應時間,必然也會采集訪問次數。因此無需為某個接口同時指定Timer與Counter兩個指標。
MicroMeter中的Gauge指標類型對應于可觀測監控 Prometheus 版中的Gauge指標類型,用來描述在一個范圍內持續波動的變量。如CPU使用率、線程池任務隊列數等。
MicroMeter中的Timer指標類型對應于可觀測監控 Prometheus 版中的Histogram,用來描述與時間相關的數據。如某個接口RT時間分布等。
Micrometer中的DistributionSummary指標類型對應可觀測監控 Prometheus 版中的Summary指標類型 ,與Histogram類似,Summary也是用于統計數據分布的,但由于數據的分布情況是在客戶端計算完成后再傳入可觀測監控 Prometheus 版進行存儲,因此Summary的結果無法在多個機器之間進行數據聚合,無法統計全局視圖的數據分布,使用起來有一定局限性。
接入流程
當您需要把部署在Kubernetes集群中的Spring Boot應用接入到可觀測監控 Prometheus 版時,需要按照代碼埋點>部署應用>服務發現這個流程來進行。

首先,您需要在代碼中引入Spring Boot Actuator相關Maven依賴,并對您需要監測的數據進行注冊,或對Controller內的方法打上相應的注解。
其次,您需要將埋點后的應用部署在Kubernetes中,并向可觀測監控 Prometheus 版注冊向應用拉取監測數據的端點(即可觀測監控 Prometheus 版的服務發現)。阿里云Prometheus服務提供了使用ServiceMonitor CRD進行服務發現的方法。
最后,在目標應用的監測采集端點被可觀測監控 Prometheus 版成功發現后,您就可以在Grafana上配置數據源及相應的大盤。同時您也可以根據某些關鍵指標進行對應的告警配置。
最終目標
通過將部署在Kubernetes集群中的Spring Boot應用接入到可觀測監控 Prometheus 版,希望能夠實現以下幾點目標:
監測系統的入口:Frontend服務是一個基于SpringMVC開發的入口應用,承接外部的客戶流量,這里主要關注的是外部接口的關鍵RED指標。例如,調用率Rate、失敗數Error、請求耗時Duration。
監測系統的關鍵鏈路:對后端服務critical path上的對象進行監測。例如,線程池的隊列情況、進程內Guava Cache緩存的命中情況。
實現對業務強相關的自定義指標進行監測。例如,某個接口的UV等。
實現對JVM GC及內存使用情況進行監測。
實現對上述指標進行統一匯聚展示,以及配置關鍵指標的告警。
步驟一:引入Spring Boot Actuator依賴,進行初始配置
這里選取一個基于Spring Boot和Spring Cloud Alibaba構建的云原生微服務應用,為您介紹部署在Kubernetes集群上的Spring Boot微服務應用如何進行Prometheus接入的具體接入流程。
執行如下代碼段,引入Spring Boot Actuator的相關依賴。
<!-- spring-boot-actuator依賴 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> <!-- prometheus依賴 --> <dependency> <groupId>io.micrometer</groupId> <artifactId>micrometer-registry-prometheus</artifactId> </dependency>在application.properties中添加相關配置暴露監測數據端口。例如,端口為8091。
# application.properties添加以下配置用于暴露指標 spring.application.name=frontend management.server.port=8091 management.endpoints.web.exposure.include=* management.metrics.tags.application=${spring.application.name}配置成功后,即可訪問該應用的8091端口,然后您可以在該端口的/actuator/prometheus路徑中獲取OpenMetrics標準的監測數據。
步驟二:代碼埋點及改造
若要獲取某個API接口的RED指標,您需要在對應的接口方法上打@Timed注解。這里以index頁面接口為例打@Timed注解,如下代碼段所示。
@Timed(value = "main_page_request_duration", description = "Time taken to return main page", histogram = true)
@ApiOperation(value = "首頁", tags = {"首頁操作頁面"})
@GetMapping("/")
public String index(Model model) {
model.addAttribute("products", productDAO.getProductList());
model.addAttribute("FRONTEND_APP_NAME", Application.APP_NAME);
model.addAttribute("FRONTEND_SERVICE_TAG", Application.SERVICE_TAG);
model.addAttribute("FRONTEND_IP", registration.getHost());
model.addAttribute("PRODUCT_APP_NAME", PRODUCT_APP_NAME);
model.addAttribute("PRODUCT_SERVICE_TAG", PRODUCT_SERVICE_TAG);
model.addAttribute("PRODUCT_IP", PRODUCT_IP);
model.addAttribute("new_version", StringUtils.isBlank(env));
return "index.html";
}其中value即為暴露到/actuator/prometheus中的指標名字,histogram=true表示暴露這個接口請求時長的histogram直方圖類型指標,便于您后續計算P90、P99等請求時間分布情況。
若您的應用中使用了進程內緩存庫(例如,最常見的Guava Cache庫等)且需要追蹤進程內緩存的運行狀況,您可以按照Micrometer提供的修飾方法,對于待監測的關鍵對象進行封裝。
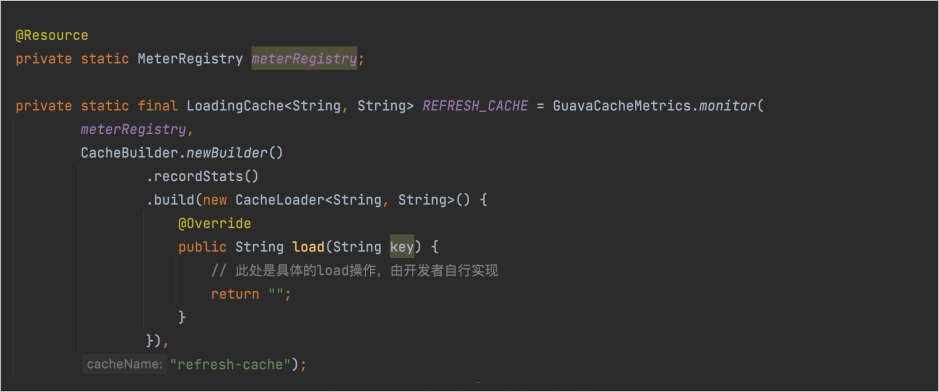
Guava Cache改造
注入MeterRegistry,這里注入的具體實現是PrometheusMeterRegistry,由Spring Boot自行注入即可。
使用工具類API包裝本地緩存,即如下圖中的GuavaCacheMetrics.monitor。
開啟緩存數據記錄,即調用.recordStats()方法。
為Cache對象命名,用于生成對應的指標。
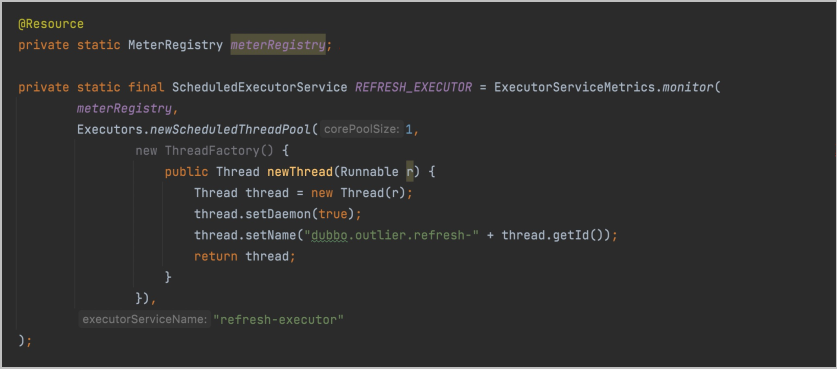
線程池改造
注入MeterRegistry,這里注入的具體實現是PrometheusMeterRegistry。
使用工具類API包裝線程池。
為線程池命名,用于生成對應的指標。
在開發過程中還會涉及許多業務強相關的自定義指標,為了監測這些指標,在往Bean中注入MeterRegistry后,您還需要按照需求和對應場景構造Counter、Gauge或Timer來進行數據統計,并將其注冊到MeterRegistry進行指標暴露,示例如下。
@Service
public class DemoService {
Counter visitCounter;
public DemoService(MeterRegistry registry) {
visitCounter = Counter.builder("visit_counter")
.description("Number of visits to the site")
.register(registry);
}
public String visit() {
visitCounter.increment();
return "Hello World!";
}
}至此,您對應用的代碼改造工作已全部完成。然后您需要將應用鏡像重新構建并部署到已安裝可觀測監控 Prometheus 版的Kubernetes集群中,并在可觀測監控 Prometheus 版控制臺中配置ServiceMonitor,進行服務發現。更多信息,請參見Prometheus實例 for 容器服務和管理Kubernetes集群服務發現。
ServiceMonitor配置完成后,您可以在Targets列表中查看到剛注冊的Service應用。
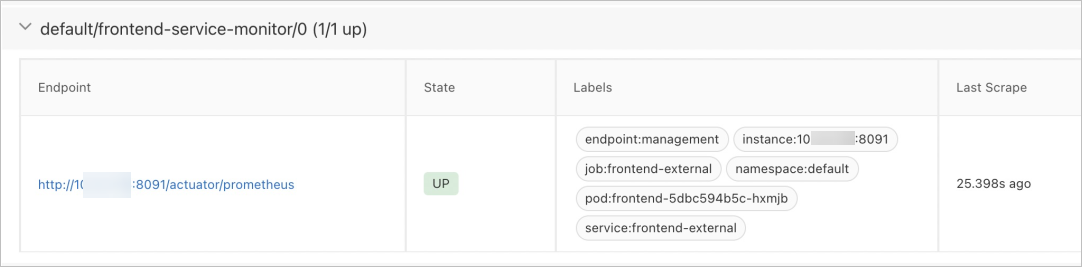
步驟三:看板配置
應用的監測數據已成功收集并存儲到可觀測監控 Prometheus 版,因此您可以配置相應的大盤及告警來查看監控到的數據。這里,為您提供以下兩個Grafana社區中的開源大盤模板來構建您自己的業務監測模板。
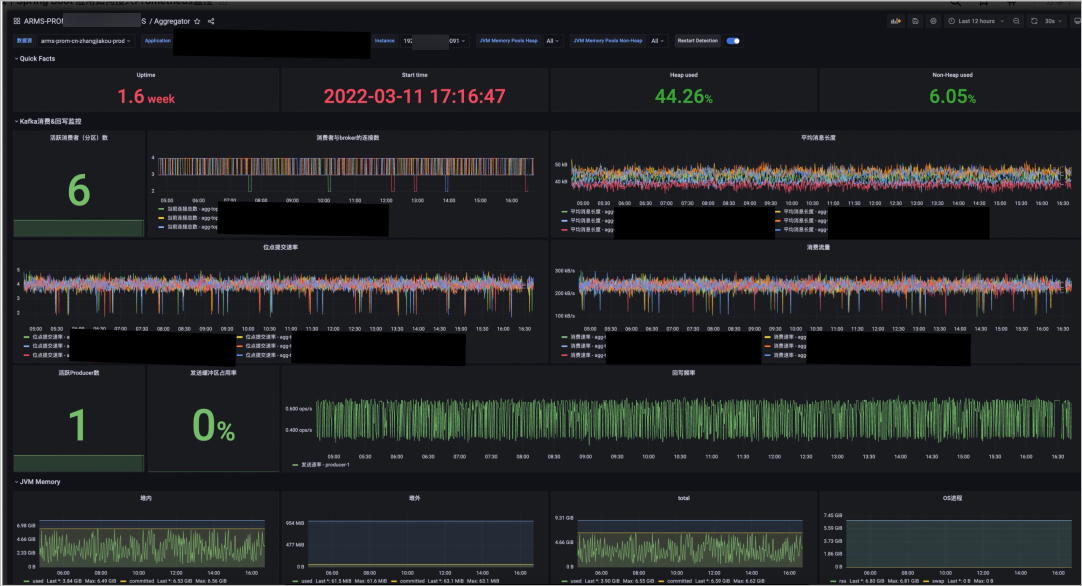
借助以上模板以及可觀測監控 Prometheus 版內置的Grafana服務,您可以根據自己的需求,將日常開發和運維過程中需要重點關注的指標展示在同一個Grafana Dashboard頁面上,創建屬于您的個性化大盤,便于日常監測。例如,這里基于上述模板和自身業務構建了一個真實的大盤,包含總覽、組件運行時間,內存使用率、堆內堆外內存、分代GC情況等。