本文檔介紹了PolarDB-X對超大事務的支持情況。
在分布式數據庫中,超大事務一般滿足以下條件中的一個或多個:
事務修改的數據涉及多個分片;
事務修改的數據量比較大;
事務執行的SQL語句比較多。
下面通過以下場景的測試,以這三個維度為切入點,介紹PolarDB-X對超大事務的支持情況。
測試所用實例規格
使用以下PolarDB-X實例進行測試:
PolarDB-X版本 | polarx-kernel_5.4.11-16301083_xcluster-20210805 |
節點規格 | 4核16GB |
節點個數 | 4 |
創建一個規格為4C16G的ECS連接實例進行測試,該ECS與實例位于同一網段下,由同一個虛擬交換機連接。
執行以下命令,創建如下表:
CREATE TABLE `tb` (
`id` bigint(20) NOT NULL,
`c` longblob/char(255)/char(1),
PRIMARY KEY (`id`)
);該表只有兩列,一列為id(bigint類型,主鍵),一列為c(在不同的場景下,分別為longblob/char(255)/char(1)類型)。針對分片數,主要考慮以下三種設定:
1分片,即單庫單表的情形,PolarDB-X對于單分片上的事務提交會優化為一階段提交;
8分片,以ID為拆分鍵將上述實驗表拆分成8個分片,每個存儲節點(DN)2 個分片;
16分片,以ID為拆分鍵將上述實驗表拆分成16個分片,每個存儲節點(DN)4 個分片;
場景一
在該場景下,執行SQL語句數量中等,每條語句攜帶數據量較大,事務寫入數據量較大。
執行SQL語句數量 | 2048 |
每條語句攜帶的數據量 | 約256 KB~8 MB |
數據修改總量 | 512 MB~16 GB |
數據修改條數 | 2048 |
測試過程
測試中,每一條SQL語句形如:
INSERT INTO `tb` VALUES (id, c)數據表中c列的數據類型為longblob,c的大小從256 KB到8 MB不等。即每個事務寫入2048條數據時,數據寫入總量從512 MB到16 GB不等。實際的寫入量比這個值稍大,因為bigint類型的ID也占用一定的空間。
受計算節點(CN)的參數MAX_ALLOWED_PACKET的影響,每個查詢的請求包大小不應超過MAX_ALLOWED_PACKET個字節。該值默認為16 MB,可通過參數設置修改,即每條SQL語句攜帶的數據量應小于參數MAX_ALLOWED_PACKET。如果您通過JDBC連接PolarDB-X數據庫,在發送的包大于MAX_ALLOWED_PACKET個字節時,會收到CommunicationsException: Communications link failure的報錯。
在單表的情況下,當c的大小為1 MB,事務總寫入量略大于2 GB 時,執行該事務會報錯:
ERR-CODE: [TDDL-4614][ERR_EXECUTE_ON_MYSQL] Error occurs when execute on GROUP ...: Multi-statement transaction required more than 'max_binlog_cache_size' bytes of storage; increase this mysqld variable and try again 受DN的參數MAX_BINLOG_CACHE_SIZE的限制,事務執行過程中,引起的binlog寫入量不應超過該值。對于分布式事務,每個分片對應一個分支事務,每個分支事務引起的binlog寫入量不應超過該值。以本測試場景為例,如果事務的每條語句都是INSERT語句,那么每個分片的數據寫入量不應超過2 GB,事務總的數據寫入量不能超過:分片數量×2 GB,例如8分片的情況下,寫入總量在16 GB時也會觸發這個報錯。但是,上述討論并不意味著只要您的事務數據寫入量小于:分片數量×2 GB,就一定能執行成功。
DN的參數MAX_BINLOG_CACHE_SIZE無法修改,默認值為2147483648,即2 GB。實際上,由于DN受MySQL的限制,即使這個參數可以修改,MAX_BINLOG_CACHE_SIZE最大也不應超過4 GB。
測試結果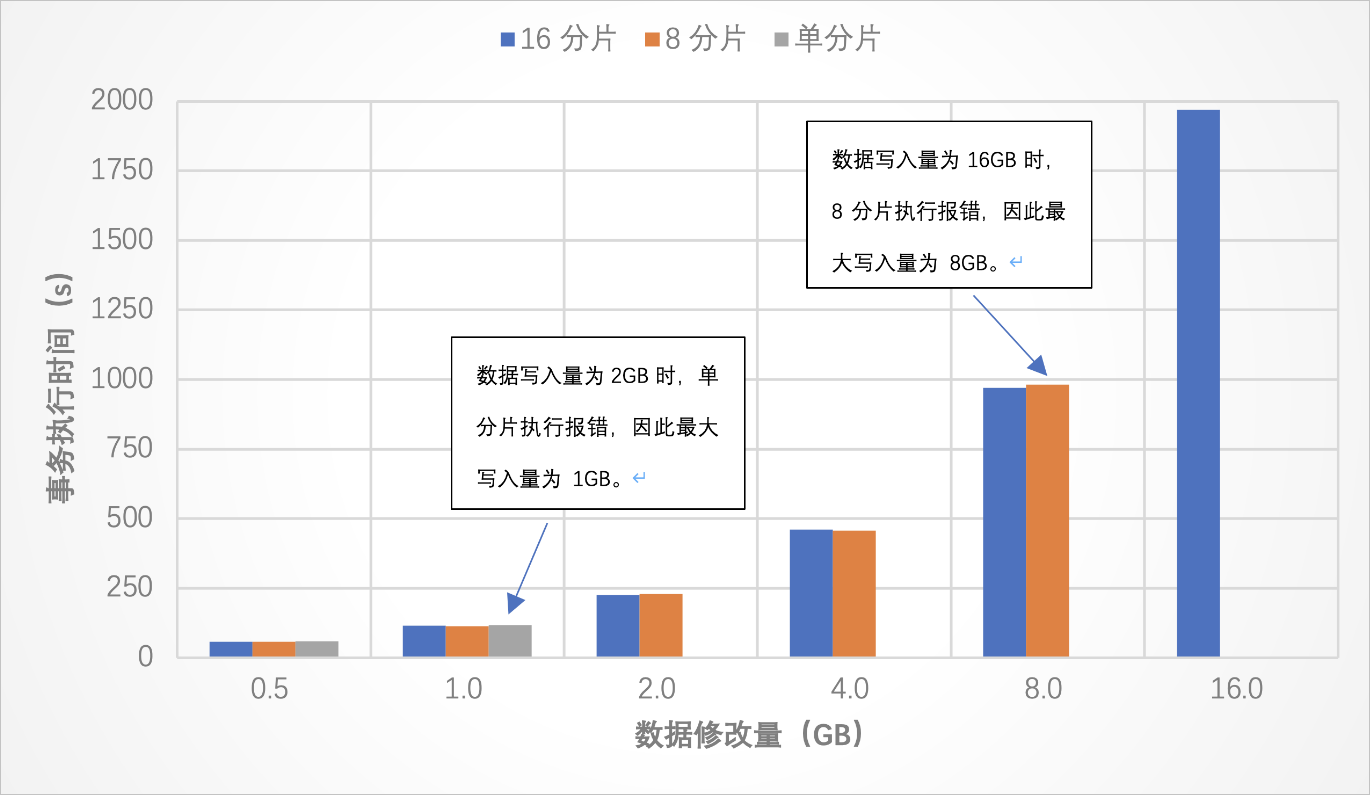 測試結論
測試結論
無論是否開啟事務,每條SQL語句攜帶的數據量受CN的參數MAX_ALLOWED_PACKET的限制,不能超過該值。
對于每個事務,在每個分片上執行的語句所引起的binlog寫入量受DN的參數MAX_BINLOG_CACHE_SIZE的影響,不能超過該值。例如,在INSERT場景下,binlog需要記錄插入的值,則事務對每個分片插入的數據量不應超過該值。
如果想支持更大的事務,比如在一個事務中插入更多的數據,請把數據表劃分到更多的分片上。
場景二
在該場景下,執行SQL語句數量較少,每條語句攜帶數據量較小,事務修改數據量較大。
執行SQL語句數量 | 1 |
每條語句攜帶的數據量 | 約256 KB |
數據修改總量 | 256 MB~8 GB |
數據修改條數 | 2^20~2^25 |
測試過程
在本測試中,數據表中c列的數據類型為char(255)。首先在數據表中導入2^25條數據,數據的id為0, 1, 2, ..., 2^26-1,每條數據的c列值為 "aa...aa"(255個a的字符串)。然后開啟事務,執行以下語句:
UPDATE `tb` SET c = “bb...bbb” (255個b的字符串) where id < ?假設語句中的?為x,則會修改共x條數據,每條數據修改約256字節的數據,數據總修改量為x * 2^8字節。本測試中x取值從2^20到2^25不等,數據修改總量從512 MB到8 GB不等。
在單表的情況下,當x為2^22,事務修改的數據量約為1 GB時,執行該事務會和場景一樣報錯:
ERR-CODE: [TDDL-4614][ERR_EXECUTE_ON_MYSQL] Error occurs when execute on GROUP ...: Multi-statement transaction required more than 'max_binlog_cache_size' bytes of storage; increase this mysqld variable and try again 對于UPDATE語句,binlog需要記錄修改前和修改后的值,即每條數據修改了256字節的數據,binlog需記錄至少512字節的數據。在單表情況下,事務修改量約為1 GB時,引起binlog寫入量超過了2 GB,就觸發了這個報錯。同理,對于分布式事務,如果事務執行的都是UPDATE語句,那么每個分片上的數據修改量不應超過1 GB。例如,在本測試中,8分片的場景下,在一個事務中UPDATE的數據為8 GB時,也會觸發此報錯。
測試結果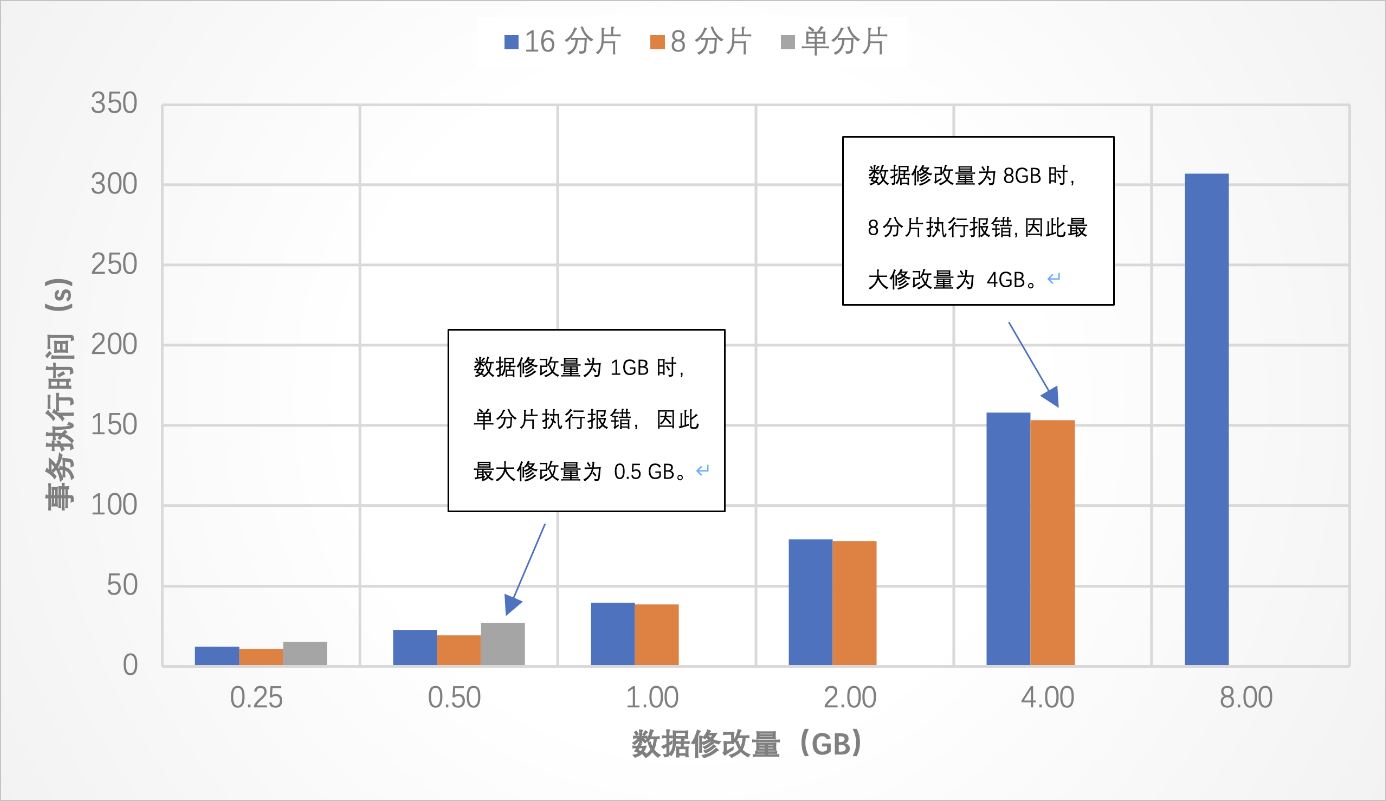 測試結論
測試結論
與場景一類似,對于每個事務,在每個分片上所引起的binlog寫入量受DN的參數MAX_BINLOG_CACHE_SIZE的影響,不能超過該值。例如,在事務語句全為UPDATE的場景下,binlog需要記錄修改前的值和修改后的值,則事務在每個分片上修改的數據量不應超過該值的一半。在本場景下,單分片的事務修改的數據量最多不應超過1 GB,8分片的事務修改的數據量最多不應超過4 GB。
如果想支持更大的事務,比如在一個事務中修改更多的數據,請把數據表劃分到更多的分片上。
場景三
在該場景下,執行SQL語句數量較多,每條語句攜帶數據量較小,事務寫入數據量較小。
執行SQL語句數量 | 64,000~1,280,000 |
每條語句攜帶的數據量 | 若干字節 |
數據修改總量 | 32 B |
數據修改條數 | 32 |
測試過程
在本測試中,數據表中c列的數據類型為char(1)。首先往數據表插入32條數據,數據的id為0~31,c為 "a"。然后開啟事務,反復執行以下語句x次,即每個事務會執行64x條SQL:
UPDATE `tb` SET c = “b” where id = 0;
UPDATE `tb` SET c = “a” where id = 0;
UPDATE `tb` SET c = “b” where id = 1;
UPDATE `tb` SET c = “a” where id = 1;
...
UPDATE `tb` SET c = “b” where id = 31;
UPDATE `tb` SET c = “a” where id = 31;測試結果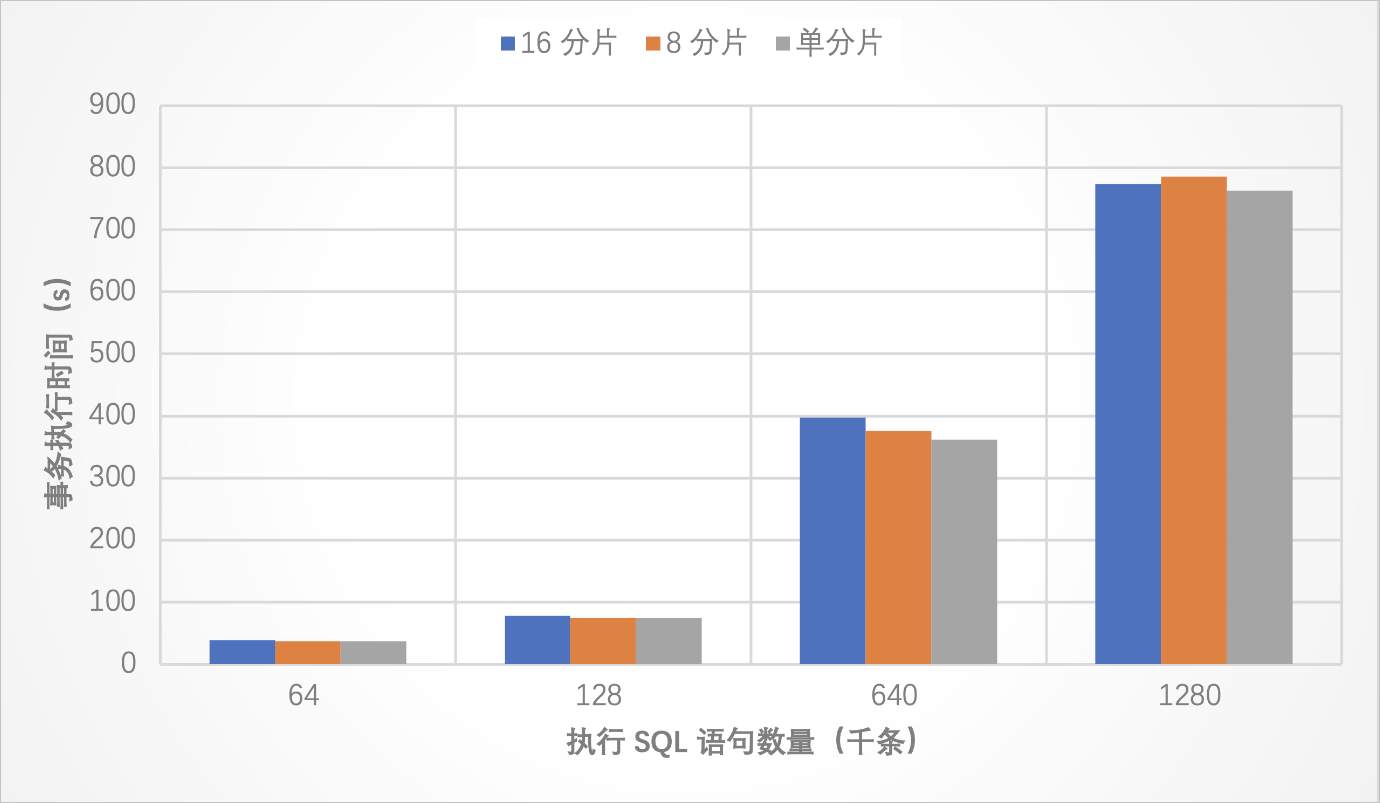
測試結論
本場景下,一個事務內執行128萬條SQL仍未達到瓶頸,不同分片設定下都能正常執行。因此,在多數情況下,首先觸發事務瓶頸的更可能是事務數據寫入、刪除、修改量。
場景四
在該場景下,測試分片數對事務的性能影響。
執行SQL語句數量 | 1 |
每條語句攜帶的數據量 | 若干字節 |
數據修改總量 | 8 KB~8 MB |
數據修改條數 | 8 KB~8MB |
分片數 | 1~2048 |
測試過程
在本場景中,數據表中c列的數據類型為char(1)。首先往數據表插入x條數據,數據的id為0~x,c為 "a"。然后開啟事務,執行以下語句,即每個事務會修改x條記錄,修改x字節數據:
UPDATE `tb` SET c = “b” where id < x每個事務執行一次該SQL,數據修改量為x字節,數據修改條數為x。考慮x=8 KB和8 MB的情況。
測試結果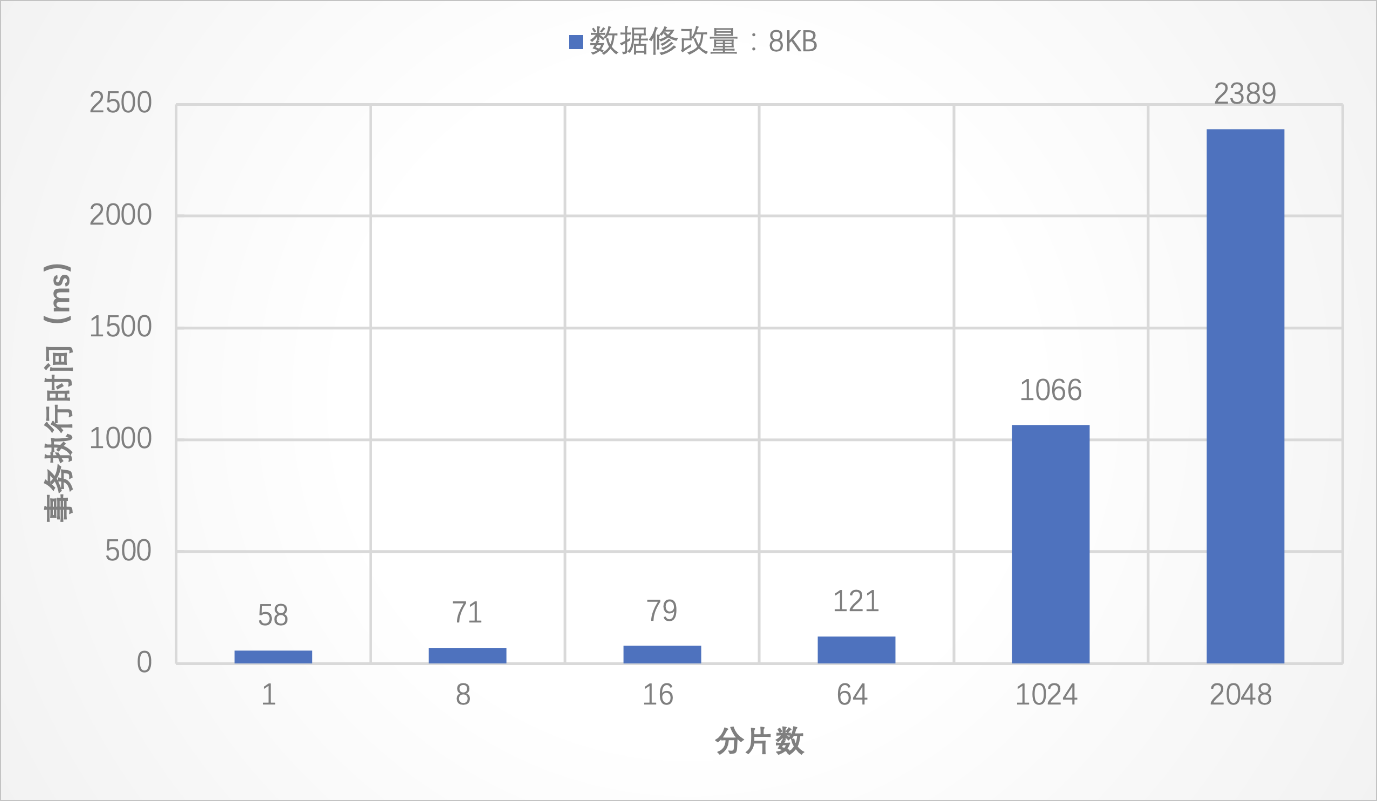
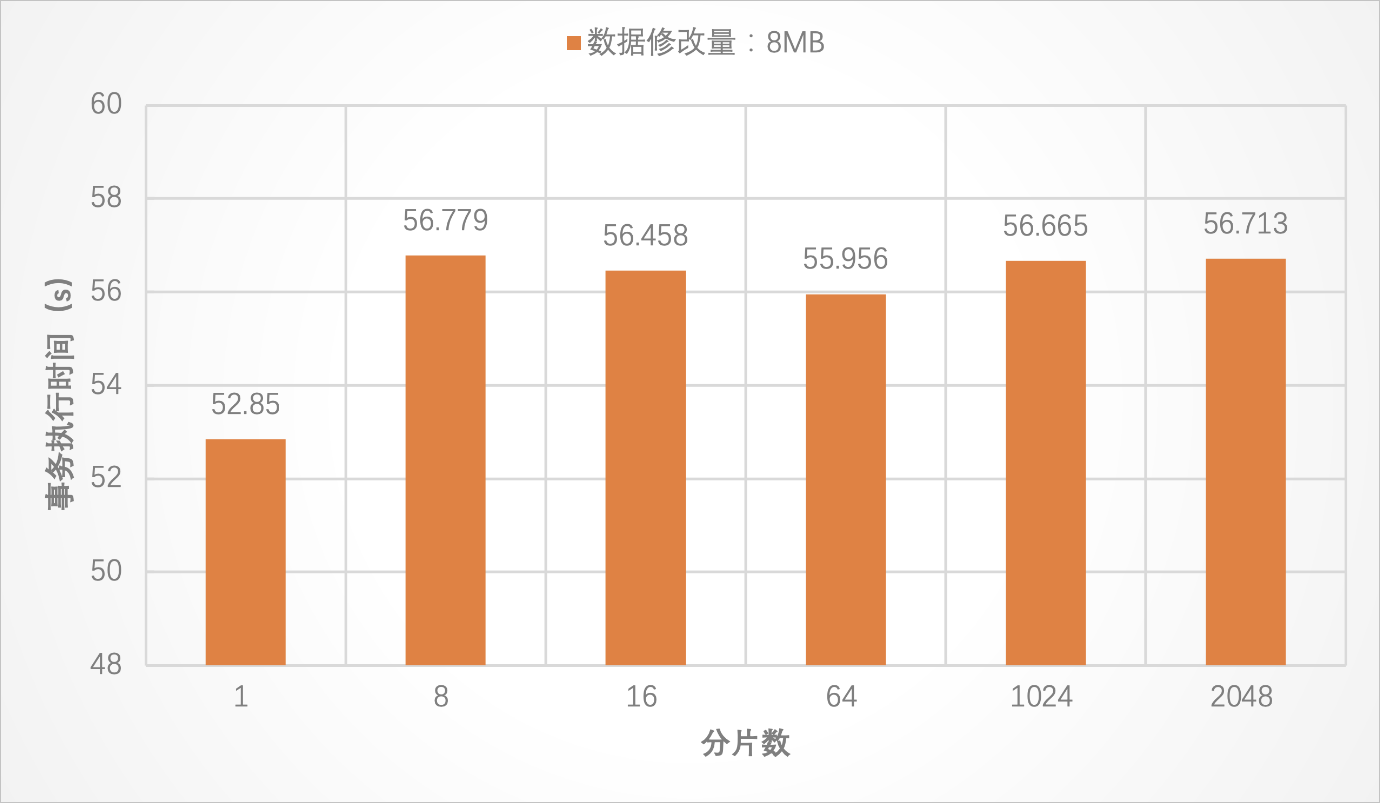
測試結論
當數據修改量在8 KB時,由于事務修改的數據量較小,SQL語句的執行時間較短,事務的執行時間受事務提交時間的影響較大。在該場景下,事務執行時間隨分片數增多而增大。具體而言,在分片數為1~64時,當分片數增長為原來的n倍時,事務執行的時間比原來的n倍少得多。這是因為分片數較少時,雖然事務提交時間有一定的影響,但事務內DML語句的執行也占用了較多的時間。而當分片數在1024~2048的情況下,事務執行時間則基本全部由事務提交時間構成。相比之下,DML語句的執行時間可以忽略不計。因此,此時事務執行時間與分片數近似成倍數增加的關系。
當數據修改量在8 MB時,事務執行時間則不再隨分片數增多而明顯增大,這時事務執行時間主要由DML的執行時間組成,事務提交時間可以忽略不計。
總而言之,根據前文的結論,當要支持更大的事務時,建議將表劃分到更多的分片上。但分片數越多,事務提交的時間也會越長。在多分片小事務的場景下,事務執行時間甚至主要由事務提交時間組成。因此,您可以參考本文在不同場景下的結論,根據具體的業務場景,選擇合適的分片數,以獲取更好的事務性能。
場景五
該場景下測試CN的計算壓力較大的時候,對事務的影響。
測試過程
在本場景中,將數據表tb劃分到16個分片進行實驗。數據表中,c列的數據類型為char(255)。首先往數據表插入2^26條數據,數據的id為0~2^26-1,c和id相同。接著,創建另一個表tb2,表結構和數據與tb完全一致。此時,每個表的大小約為16 GB。最后,創建一個臨時表tmp,其表結構和tb也相同,然后開啟事務,執行下面的語句:
INSERT INTO tmp
SELECT tb.id, tb.c
FROM tb, tb2
WHERE tb.c = tb2.c AND tb.id > x AND tb2.id > x通過explain語句可以看到這條SQL的執行計劃:
LogicalInsert(table="tmp", columns=RecordType(BIGINT id, CHAR c))
Project(id="id", c="c")
HashJoin(condition="c = c", type="inner")
Gather(concurrent=true)
LogicalView(tables="[000000-000015].tb_VjuI", shardCount=16, sql="SELECT `id`, `c` FROM `tb` AS `tb` WHERE (`id` > ?)")
Gather(concurrent=true)
LogicalView(tables="[000000-000015].tb2_IfrZ", shardCount=16, sql="SELECT `c` FROM `tb2` AS `tb2` WHERE (`id` > ?)")即把兩個表id>x的部分拉到CN做hash join。通過x來控制拉取的數據量,即CN需要計算的數據量。當x=0,會拉取所有的數據到CN做hash join,此時CN總共需要處理約32 GB的數據,并且單個CN節點的內存只有16 GB。
測試結果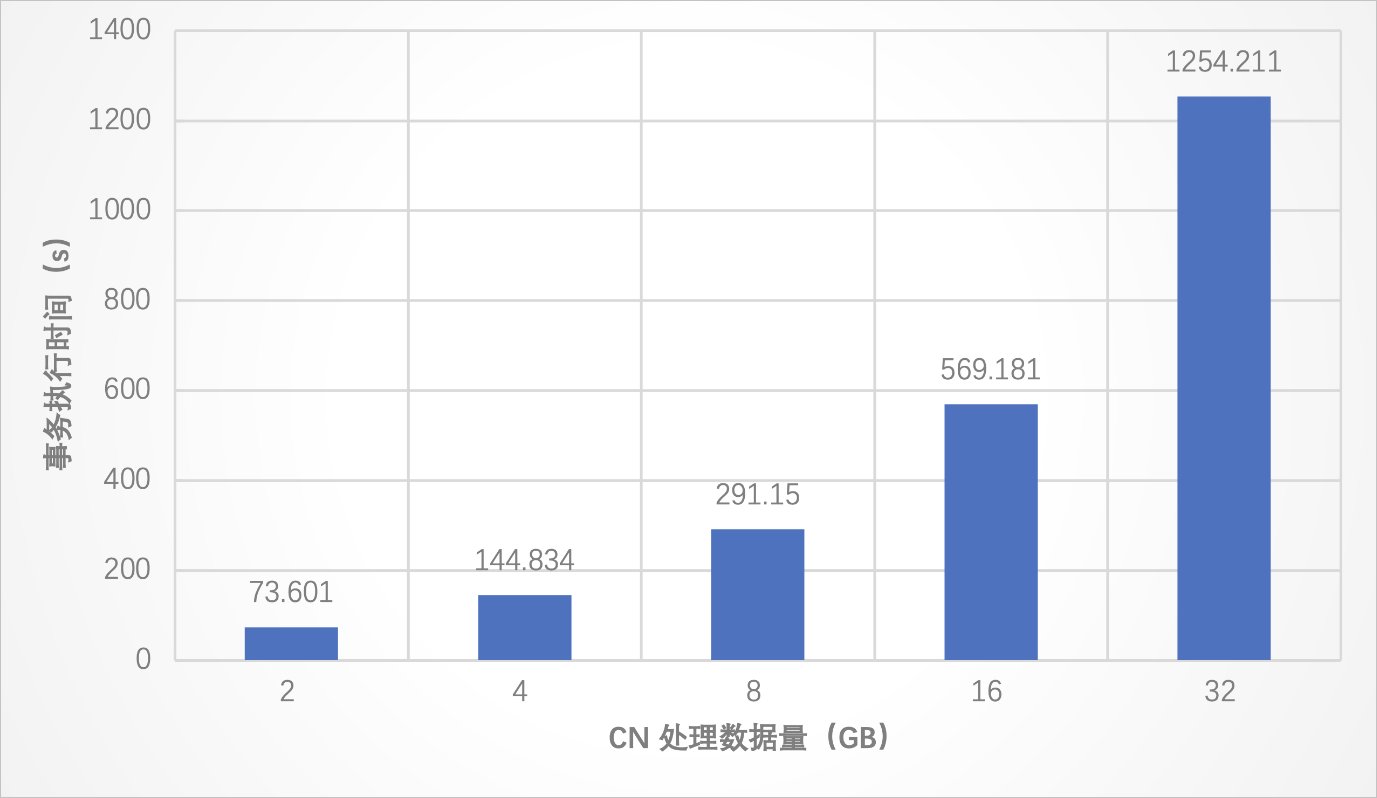
測試結論
單個事務導致CN端的計算壓力較大、計算量較多時(比如事務內有復雜的join且這些join無法下推,必須要在CN處理的場景),PolarDB-X對大事務的支持仍然穩定。具體表現為,在需要處理的數據量呈倍數增長時,事務執行不報錯,且執行時間也呈線性增長。
總結
無論是否開啟事務,每條SQL語句自身攜帶的數據量受CN的參數MAX_ALLOWED_PACKET的限制,不能超過該值。
對于每個事務,在每個分片上執行的語句所引起的binlog寫入量受DN的參數MAX_BINLOG_CACHE_SIZE的影響,不能超過該值。
該參數值默認為2 GB,受MySQL的限制,最大值為4 GB,以INSERT為例,如果一個事務中全是INSERT語句,由于binlog需要記錄插入的值,數據寫入總量最大不超過:分片數×4 GB。
如果想支持更大的事務,比如在一個事務中插入/刪除/修改更多的數據,請把數據表劃分到更多的分片上。
在事務修改數據量較少的情況下,分片數對事務執行時間的影響較大;在事務修改數據量較多的情況下,分片數對事務執行時間的影響則不大。因此,您可以參考本文在不同場景下的結論,根據具體的業務場景,選擇合適的分片數,以獲取更好的事務性能。
單個事務導致CN端的計算壓力較大、計算量較多時,PolarDB-X對大事務的支持仍然穩定。