本文介紹PolarDB-X的SQL執行器的概念、執行模型和執行模式。
基本概念
SQL執行器是PolarDB-X中執行計算層算子的組件。對于簡單的點查SQL,往往可以整體下推存儲層MySQL執行,因而感覺不到執行器的存在,MySQL的結果經過簡單的解包封包又被回傳給用戶。但是對于較復雜的SQL,往往無法將SQL中的算子全部下推,這時候就需要PolarDB-X執行器執行無法下推的計算。
SELECT l_orderkey, sum(l_extendedprice *(1 - l_discount)) AS revenue
FROM CUSTOMER, ORDERS, LINEITEM
WHERE c_mktsegment = 'AUTOMOBILE'
and c_custkey = o_custkey
and l_orderkey = o_orderkey
and o_orderdate < '1995-03-13'
and l_shipdate > '1995-03-13'
GROUP BY l_orderkey;通過EXPLAIN命令看到PolarDB-X的執行計劃如下:
HashAgg(group="l_orderkey", revenue="SUM(*)")
HashJoin(condition="o_custkey = c_custkey", type="inner")
Gather(concurrent=true)
LogicalView(tables="ORDERS_[0-7],LINEITEM_[0-7]", shardCount=8, sql="SELECT `ORDERS`.`o_custkey`, `LINEITEM`.`l_orderkey`, (`LINEITEM`.`l_extendedprice` * (? - `LINEITEM`.`l_discount`)) AS `x` FROM `ORDERS` AS `ORDERS` INNER JOIN `LINEITEM` AS `LINEITEM` ON (((`ORDERS`.`o_orderkey` = `LINEITEM`.`l_orderkey`) AND (`ORDERS`.`o_orderdate` < ?)) AND (`LINEITEM`.`l_shipdate` > ?))")
Gather(concurrent=true)
LogicalView(tables="CUSTOMER_[0-7]", shardCount=8, sql="SELECT `c_custkey` FROM `CUSTOMER` AS `CUSTOMER` WHERE (`c_mktsegment` = ?)")如下圖所示,LogicalView的SQL在執行時被下發給MySQL,而不能下推的部分(除LogicalView以外的算子)由PolarDB-X執行器進行計算,得到最終用戶SQL需要的結果。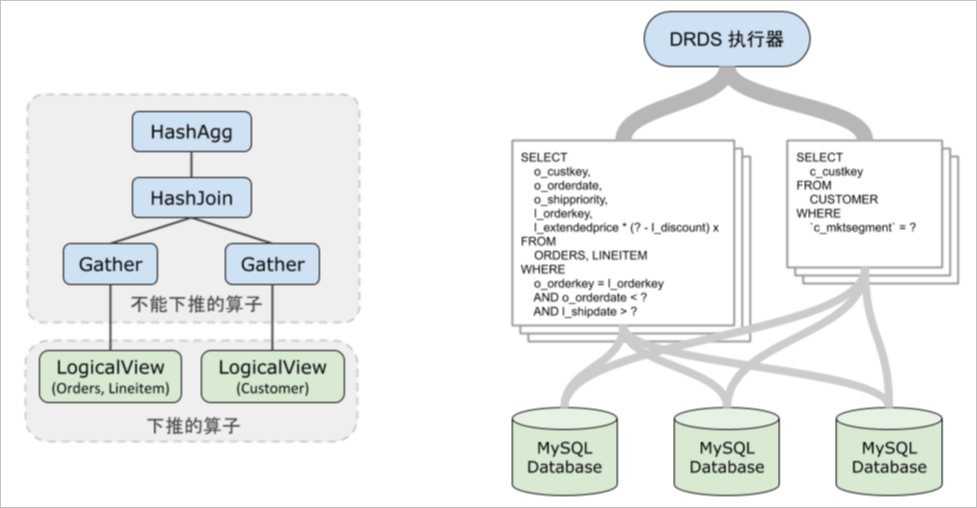
執行模型
與傳統數據庫采用Volcano執行模型不同,PolarDB-X采用的是Pull~Push混合執行模型。所有算子按照計算過程中是否需要緩存臨時表,將執行過程切分成多個pipeline,pipeline內部采用next()接口,按批獲取數據完成在pipeline內部的計算。pipeline間采用push接口,上游pipeline在計算完成后,會將數據源源不斷推送給下游pipeline做計算。
如下示例中,計算被切分成兩個pipeline,在pipeline-A中掃描Table-A數據,完成構建哈希表。Pipeline-B掃描Table-B的數據,然后在HashJoin算子內部做關聯得到JOIN結果,再返回客戶端。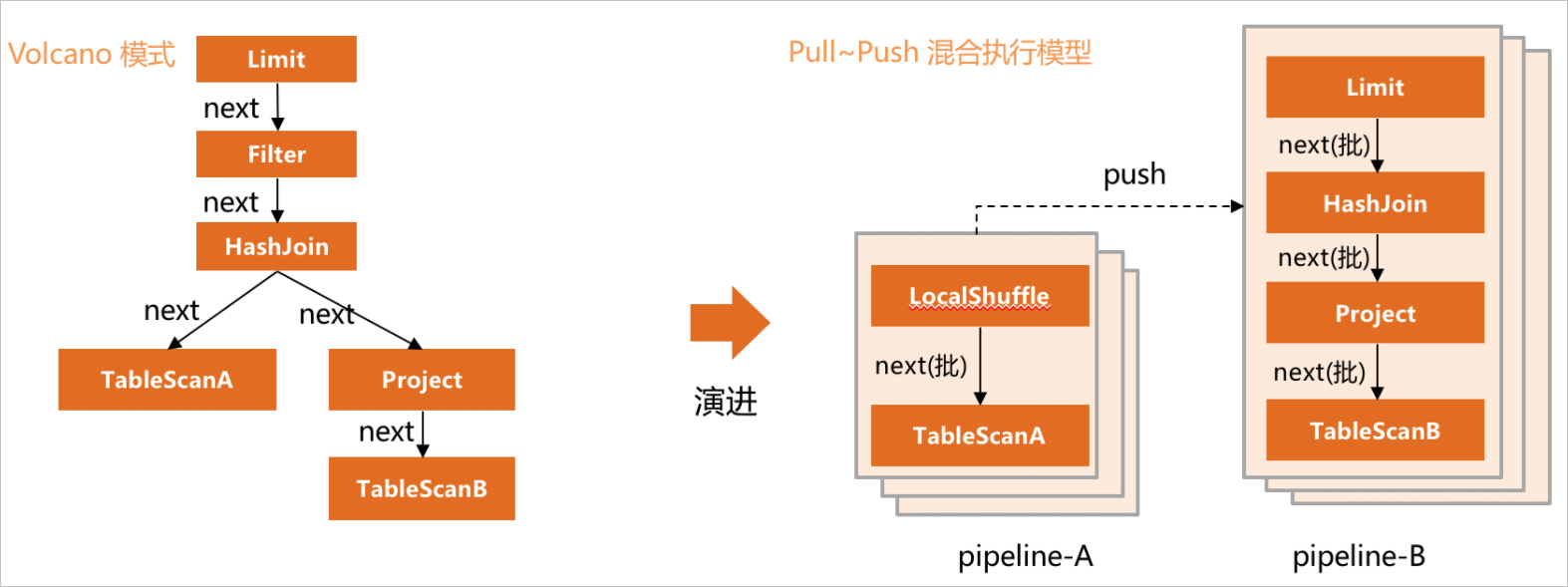
執行模式
目前PolarDB-X支持了三種執行模式:
單機單線程(TP_LOCAL):查詢過程是單線程計算,TP負載的查詢涉及到的掃描行數比較少,往往會采用這種執行模式,比如基于主鍵的點查。
單機并行(AP_LOCAL):查詢過程中會利用節點的多核資源做并行計算,如果您沒有配置只讀實例,針對AP負載的查詢,往往會采用這種執行模式,一般也稱之為Parallel Query模式。
多機并行(MPP):您如果配置了只讀實例,針對AP負載的查詢,可以協調只讀實例上多個節點的多核做分布式多機并行加速。
為了準確查看執行模式,在原有EXPLAIN和執行計劃的基礎上,擴展了 EXPLAIN PHYSICAL,例如以下查詢,在返回信息中可以查看當前查詢采用的是MPP模式,此外還可以獲取到每個執行片段的并發數。
explain physical select a.k, count(*) cnt from sbtest1 a, sbtest1 b where a.id = b.k and a.id > 1000 group by k having cnt > 1300 or
der by cnt limit 5, 10;返回執行計劃信息如下:
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| PLAN |
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| ExecutorType: MPP |
| The Query's MaxConcurrentParallelism: 2 |
| Fragment 1 |
| Shuffle Output layout: [BIGINT, BIGINT] Output layout: [BIGINT, BIGINT] |
| Output partitioning: SINGLE [] Parallelism: 1 |
| TopN(sort="cnt ASC", offset=?2, fetch=?3) |
| Filter(condition="cnt > ?1") |
| HashAgg(group="k", cnt="COUNT()") |
| BKAJoin(condition="k = id", type="inner") |
| RemoteSource(sourceFragmentIds=[0], type=RecordType(INTEGER_UNSIGNED id, INTEGER_UNSIGNED k)) |
| Gather(concurrent=true) |
| LogicalView(tables="[000000-000003].sbtest1_[00-15]", shardCount=16, sql="SELECT `k` FROM `sbtest1` AS `sbtest1` WHERE ((`k` > ?) AND (`k` IN (...)))") |
| Fragment 0 |
| Shuffle Output layout: [BIGINT, BIGINT] Output layout: [BIGINT, BIGINT] |
| Output partitioning: SINGLE [] Parallelism: 1 Splits: 16 |
| LogicalView(tables="[000000-000003].sbtest1_[00-15]", shardCount=16, sql="SELECT `id`, `k` FROM `sbtest1` AS `sbtest1` WHERE (`id` > ?)") |
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------+同樣的也允許您通過HINT EXECUTOR_MODE語句指定執行模式。例如主實例空閑資源很多,可以考慮強制設置為單機或者多機并行模式來加速。
explain physical /*+TDDL:EXECUTOR_MODE=AP_LOCAL*/select a.k, count(*) cnt from sbtest1 a, sbtest1 b where a.id = b.k and a.id > 1000 group by k having cnt > 1300 order by cnt limit 5, 10; 返回執行計劃信息如下:
+-------------------------------------------------------------------------------------------------------------------------------------------------------------+
| ExecutorMode: AP_LOCAL |
| Fragment 0 dependency: [] parallelism: 4 |
| BKAJoin(condition="k = id", type="inner") |
| Gather(concurrent=true) |
| LogicalView(tables="[000000-000003].sbtest1_[00-15]", shardCount=16, sql="SELECT `id`, `k` FROM `sbtest1` AS `sbtest1` WHERE (`id` > ?)") |
| Gather(concurrent=true) |
| LogicalView(tables="[000000-000003].sbtest1_[00-15]", shardCount=16, sql="SELECT `k` FROM `sbtest1` AS `sbtest1` WHERE ((`k` > ?) AND (`k` IN (...)))") |
| Fragment 1 dependency: [] parallelism: 8 |
| LocalBuffer |
| RemoteSource(sourceFragmentIds=[0], type=RecordType(INTEGER_UNSIGNED id, INTEGER_UNSIGNED k, INTEGER_UNSIGNED k0)) |
| Fragment 2 dependency: [0, 1] parallelism: 8 |
| Filter(condition="cnt > ?1") |
| HashAgg(group="k", cnt="COUNT()") |
| RemoteSource(sourceFragmentIds=[1], type=RecordType(INTEGER_UNSIGNED id, INTEGER_UNSIGNED k, INTEGER_UNSIGNED k0)) |
| Fragment 3 dependency: [0, 1] parallelism: 1 |
| LocalBuffer |
| RemoteSource(sourceFragmentIds=[2], type=RecordType(INTEGER_UNSIGNED k, BIGINT cnt)) |
| Fragment 4 dependency: [2, 3] parallelism: 1 |
| TopN(sort="cnt ASC", offset=?2, fetch=?3) |
| RemoteSource(sourceFragmentIds=[3], type=RecordType(INTEGER_UNSIGNED k, BIGINT cnt)) |
+-------------------------------------------------------------------------------------------------------------------------------------------------------------+多機并行執行模式的并發度是根據物理掃描行數、實例規格和計算所涉及到表的分表數計算得出的,整體的并行度要考慮高并發場景,所以并行度的計算會偏保守,您可以通過上述EXPLAIN PHYSICAL指令查看并行度。也同樣支持HINT MPP_PARALLELISM強制指定并行度。
/*+TDDL:EXECUTOR_MODE=MPP MPP_PARALLELISM=8*/select a.k, count(*) cnt from sbtest1 a, sbtest1 b where a.id = b.k and a.id > 1000 group by k having cnt > 1300 order by cnt limit 5, 10;