本文著重介紹PolarDB-X 1.0執行計劃中各個操作符的含義,以便用戶通過查詢計劃了解SQL執行流程,從而有針對性的進行SQL調優。
執行計劃介紹
與多數數據庫系統類似,PolarDB-X 1.0在處理SQL時,會通過優化器生成執行計劃,該執行計劃由關系操作符構成一個樹形結構,反映PolarDB-X 1.0如何執行SQL語句。不同的是,PolarDB-X 1.0本身不存儲數據,更側重考慮分布式環境中的網絡IO開銷,將運算下推到各個分庫(如RDS/MySQL)執行,從而提升SQL執行效率。用戶可通過EXPLAIN命令查看SQL的執行計劃。
文中示例均基于如下表結構:
CREATE TABLE `sbtest1` (
`id` INT(10) UNSIGNED NOT NULL,
`k` INT(10) UNSIGNED NOT NULL DEFAULT '0',
`c` CHAR(120) NOT NULL DEFAULT '',
`pad` CHAR(60) NOT NULL DEFAULT '',
KEY `xid` (`id`),
KEY `k_1` (`k`)
) dbpartition BY HASH (`id`) tbpartition BY HASH (`id`) tbpartitions 4
如下示例展示了PolarDB-X 1.0執行計劃的樹形結構。
explain select a.k, count(*) cnt from sbtest1 a, sbtest1 b where a.id = b.k and a.id > 1000 group by k having cnt > 1300 order by cnt limit 5, 10;
+---------------------------------------------------------------------------------------------------------------------------------------------------+
| LOGICAL PLAN |
+---------------------------------------------------------------------------------------------------------------------------------------------------+
| TmpSort(sort="cnt ASC", offset=?2, fetch=?3) |
| Filter(condition="cnt > ?1") |
| Aggregate(group="k", cnt="COUNT()") |
| BKAJoin(id="id", k="k", c="c", pad="pad", id0="id0", k0="k0", c0="c0", pad0="pad0", condition="id = k", type="inner") |
| Gather(sort="k ASC") |
| LogicalView(tables="[0000-0031].sbtest1_[000-127]", shardCount=128, sql="SELECT * FROM `sbtest1` WHERE (`id` > ?) ORDER BY `k`") |
| Gather(concurrent=true) |
| LogicalView(tables="[0000-0031].sbtest1_[000-127]", shardCount=128, sql="SELECT * FROM `sbtest1` WHERE ((`k` > ?) AND (`k` IN ('?')))") |
| HitCache:false |
+---------------------------------------------------------------------------------------------------------------------------------------------------+
9 rows in set (0.01 sec)
PolarDB-X 1.0 EXPLAIN的結果總體分為兩部分:執行計劃和其他信息。
- 執行計劃:以縮進形式表示操作符之間的 "父-子" 關系。示例中,Filter是TmpSort的子操作符,同時是Aggregate的父操作符。從真正執行的角度看,每個操作符均從其子操作符中獲取數據,經當前操作符處理,輸出給其父操作符。為方便理解,將以上執行計劃轉換為更加直觀的樹形結構:
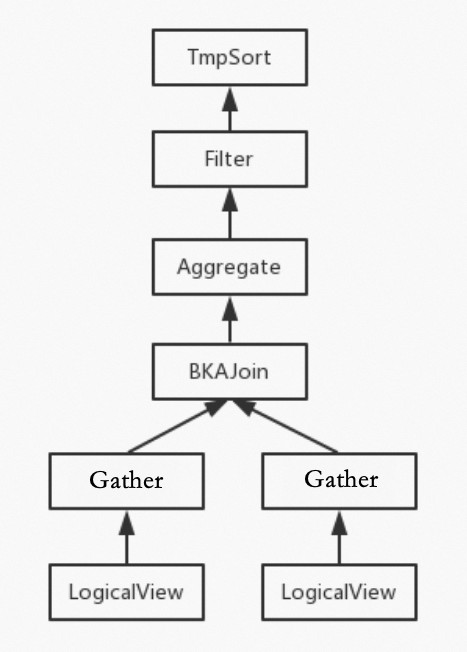
- 其他信息:除執行計劃外,EXPLAIN結果中還會有一些額外信息,目前僅有一項
HitCache。需要說明的是,PolarDB-X 1.0會默認開啟PlanCache功能,HitCache表示當前SQL是否命中PlanCache。 開啟PlanCache后,PolarDB-X 1.0會對SQL做參數化處理,參數化會將SQL中的大部分常量用?替換,并構建一個參數列表。在執行計劃中的體現就是,LogicalView的SQL中會有?,在部分操作符中會有類似?2的字樣,這里的2表示其在參數列表中的下標,后續會結合具體的例子進一步闡述。
EXPLAIN語法
EXPLAIN用于查看SQL語句的執行計劃,語法如下:
EXPLAIN
{LOGICALVIEW | LOGIC | SIMPLE | DETAIL | EXECUTE | PHYSICAL | OPTIMIZER | SHARDING
| COST | ANALYZE | BASELINE | JSON_PLAN | ADVISOR}
{SELECT statement | DELETE statement | INSERT statement | REPLACE statement| UPDATE statement} 操作符介紹
LogicalViewLogicalView是從底層數據源獲取數據的操作符。從數據庫的角度來看,使用TableScan命名更符合常規,但考慮到PolarDB-X 1.0本身不存儲數據,而是通過SQL從底層數據源獲取,因此,該操作符中會記錄下推的SQL語句和數據源信息,這更像一個 "視圖"。該 "視圖" 中的SQL,通過優化器的下推,可能包含多種操作,如投影、過濾、聚合、排序、連接和子查詢等。
以下通過示例說明EXPLAIN中LogicalView的輸出信息及其含義:
explain select * From sbtest1 where id > 1000;
+-----------------------------------------------------------------------------------------------------------------------+
| LOGICAL PLAN |
+-----------------------------------------------------------------------------------------------------------------------+
| UnionAll(concurrent=true) |
| LogicalView(tables="[0000-0031].sbtest1_[000-127]", shardCount=128, sql="SELECT * FROM `sbtest1` WHERE (`id` > ?)") |
| HitCache:false |
+-----------------------------------------------------------------------------------------------------------------------+
3 rows in set (0.00 sec)
LogicalView的信息由三部分構成:
- tables:底層數據源對應的表名,以
.分割,其前是分庫對應的編號,其后是表名及其編號,對于連續的編號,會做簡寫,如[000-127],表示表名編號從000到127的所有表。 - shardCount:需要訪問的分表總數,該示例中會訪問從
000到127共128張分表。 - sql:下發至底層數據源的SQL模板。這里顯示的并非真正下發的SQL語句,PolarDB-X 1.0在執行時會將表名替換為物理表名;另外,SQL中的常量
10被?替換,這是因為PolarDB-X 1.0默認開啟了PlanCache功能,對SQL做了參數化處理。
UnionAll是UNION ALL對應的操作符,該操作符通常有多個輸入,表示將多個輸入的數據UNION在一起。以上示例中,LogicalView之上的UnionAll表示將所有分表中的數據進行UNION。
UnionAll中的concurrent表示是否并行執行其子操作符,默認為true。
與UnionAll類似,UnionDistinct是UNION DISTINCT對應的操作符。示例如下:
explain select * From sbtest1 where id > 1000 union distinct select * From sbtest1 where id < 200;
+-------------------------------------------------------------------------------------------------------------------------+
| LOGICAL PLAN |
+-------------------------------------------------------------------------------------------------------------------------+
| UnionDistinct(concurrent=true) |
| UnionAll(concurrent=true) |
| LogicalView(tables="[0000-0031].sbtest1_[000-127]", shardCount=128, sql="SELECT * FROM `sbtest1` WHERE (`id` > ?)") |
| UnionAll(concurrent=true) |
| LogicalView(tables="[0000-0031].sbtest1_[000-127]", shardCount=128, sql="SELECT * FROM `sbtest1` WHERE (`id` < ?)") |
| HitCache:false |
+-------------------------------------------------------------------------------------------------------------------------+
6 rows in set (0.02 sec)
MergeSort,歸并排序操作符,通常有多個子操作符。PolarDB-X 1.0中實現了兩種排序:基于有序數據的歸并排序和對無序數據的內存排序。示例如下:
explain select *from sbtest1 where id > 1000 order by id limit 5,10;
+---------------------------------------------------------------------------------------------------------------------------------------------------+
| LOGICAL PLAN |
+---------------------------------------------------------------------------------------------------------------------------------------------------+
| MergeSort(sort="id ASC", offset=?1, fetch=?2) |
| LogicalView(tables="[0000-0031].sbtest1_[000-127]", shardCount=128, sql="SELECT * FROM `sbtest1` WHERE (`id` > ?) ORDER BY `id` LIMIT (? + ?)") |
| HitCache:false |
+---------------------------------------------------------------------------------------------------------------------------------------------------+
3 rows in set (0.00 sec)
MergeSort操作符包含三部分內容:
- sort:表示排序字段以及排列順序,
id ASC表示按照id字段遞增排序,DESC表示遞減排序。 - offset:表示獲取結果集時的偏移量,同樣由于對SQL做了參數化,示例中的
offset表示為?1,其中?表示這是一個動態參數,其后的數字對應參數列表的下標。示例中SQL對應的參數為[1000, 5, 10],因此,?1實際對應的值為5。 - fetch:表示最多返回的數據行數。與
offset類似,同樣是參數化的表示,實際對應的值為10。
Aggregate是聚合操作符,通常包含兩部分內容:Group By字段和聚合函數。示例如下:
explain select k, count(*) from sbtest1 where id > 1000 group by k;
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| LOGICAL PLAN |
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Aggregate(group="k", count(*)="SUM(count(*))") |
| MergeSort(sort="k ASC") |
| LogicalView(tables="[0000-0031].sbtest1_[000-127]", shardCount=128, sql="SELECT `k`, COUNT(*) AS `count(*)` FROM `sbtest1` WHERE (`id` > ?) GROUP BY `k` ORDER BY `k`") |
| HitCache:true |
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
4 rows in set (0.00 sec)
Aggregate 包含兩部分內容:
- group:表示GROUP BY字段,示例中為
k。 - 聚合函數:
=前為聚合函數對應的輸出列名,其后為對應的計算方法。示例中的count(*)="SUM(count(*))",第一個count(*)對應輸出的列名,隨后的SUM(count(*))表示對其輸入數據中的count(*)列進行SUM運算得到最終的count(*)。
由此可見,PolarDB-X 1.0將聚合操作分為兩部分,首先將聚合操作下推至底層數據源做局部聚合,最終在PolarDB-X 1.0層面對局部聚合的結果做全局聚合。另外,PolarDB-X 1.0的最終聚合是基于排序做的,因此,會在優化器階段為其添加一個Sort子操作符,而Sort操作符又進一步通過下推Sort轉換為MergeSort。
如下為AVG聚合函數的例子:
explain select k, avg(id) avg_id from sbtest1 where id > 1000 group by k;
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| LOGICAL PLAN|
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Project(k="k", avg_id="sum_pushed_sum / sum_pushed_count")|
| Aggregate(group="k", sum_pushed_sum="SUM(pushed_sum)", sum_pushed_count="SUM(pushed_count)")|
| MergeSort(sort="k ASC")|
| LogicalView(tables="[0000-0031].sbtest1_[000-127]", shardCount=128, sql="SELECT `k`, SUM(`id`) AS `pushed_sum`, COUNT(`id`) AS `pushed_count` FROM `sbtest1` WHERE (`id` > ?) GROUP BY `k` ORDER BY `k`")|
| HitCache:false|
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
5 rows in set (0.01 sec)
PolarDB-X 1.0會將AVG聚合函數轉換為SUM / COUNT,再分別根據SUM和COUNT的下推規則,將其轉換為局部聚合和全局聚合。您可自行嘗試了解其他聚合函數的執行計劃。
DISTINCT操作轉換為
GROUP操作,示例如下:
explain select distinct k from sbtest1 where id > 1000;
+-----------------------------------------------------------------------------------------------------------------------------------------------------+
| LOGICAL PLAN |
+-----------------------------------------------------------------------------------------------------------------------------------------------------+
| Aggregate(group="k") |
| MergeSort(sort="k ASC") |
| LogicalView(tables="[0000-0031].sbtest1_[000-127]", shardCount=128, sql="SELECT `k` FROM `sbtest1` WHERE (`id` > ?) GROUP BY `k` ORDER BY `k`") |
| HitCache:false |
+-----------------------------------------------------------------------------------------------------------------------------------------------------+
4 rows in set (0.02 sec)
TmpSort,表示在內存中對數據進行排序。與MergeSort的區別在于,MergeSort可以有多個子操作符,且每個子操作符返回的數據都已經排序。TmpSort僅有一個子操作符。
TmpSort對應的查詢計劃信息與MergeSort一致,請參考MergeSort。
ProjectProject表示投影操作,即從輸入數據中選擇部分列輸出,或者對某些列進行轉換(通過函數或者表達式計算)后輸出,當然,也可以包含常量。以上AVG的示例中,最頂層就是一個Project,其輸出k和sum_pushed_sum / sum_pushed_count ,后者對應的列名為avg_id 。
explain select '你好, DRDS', 1 / 2, CURTIME();
+-------------------------------------------------------------------------------------+
| LOGICAL PLAN |
+-------------------------------------------------------------------------------------+
| Project(你好, DRDS="_UTF-16'你好, DRDS'", 1 / 2="1 / 2", CURTIME()="CURTIME()") |
| |
| HitCache:false |
+-------------------------------------------------------------------------------------+
3 rows in set (0.00 sec)
可見,Project的計劃中包括每列的列名及其對應的列、值、函數或者表達式。
FilterFilter表示過濾操作,其中包含一些過濾條件。該操作符對輸入數據進行過濾,若滿足條件,則輸出,否則丟棄。如下是一個較復雜的例子,包含了以上介紹的大部分操作符。
explain select k, avg(id) avg_id from sbtest1 where id > 1000 group by k having avg_id > 1300;
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| LOGICAL PLAN |
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Filter(condition="avg_id > ?1") |
| Project(k="k", avg_id="sum_pushed_sum / sum_pushed_count") |
| Aggregate(group="k", sum_pushed_sum="SUM(pushed_sum)", sum_pushed_count="SUM(pushed_count)") |
| MergeSort(sort="k ASC") |
| LogicalView(tables="[0000-0031].sbtest1_[000-127]", shardCount=128, sql="SELECT `k`, SUM(`id`) AS `pushed_sum`, COUNT(`id`) AS `pushed_count` FROM `sbtest1` WHERE (`id` > ?) GROUP BY `k` ORDER BY `k`") |
| HitCache:false |
+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
6 rows in set (0.01 sec)
在以上AVG示例的SQL基礎上添加了having avg_id > 1300,執行計劃最上層添加了一個Filter操作符,用于過濾所有滿足avg_id > 1300的數據。
有讀者可能會問,WHERE中的條件為什么沒有對應的Filter操作符呢?在PolarDB-X 1.0優化器的某個階段,WHERE條件的Filter操作符的確是存在的,只是最終將其下推到了LogiacalView中,因此可以在LogicalView的sql中看到id > 1000 。
NlJoin,表示NestLoop Join操作符,即使用NestLoop方法進行兩表Join。PolarDB-X 1.0中實現了兩種JOIN策略:NlJoin和BKAJoin,后者表示Batched Key Access Join,批量鍵值查詢,會從左表取一批數據,構建一個IN條件拼接在訪問右表的SQL中,從右表一次獲取一批數據。
explain select a.* from sbtest1 a, sbtest1 b where a.id = b.k and a.id > 1000;
+----------------------------------------------------------------------------------------------------------------------------+
| LOGICAL PLAN |
+----------------------------------------------------------------------------------------------------------------------------+
| Project(id="id", k="k", c="c", pad="pad") |
| NlJoin(id="id", k="k", c="c", pad="pad", k0="k0", condition="id = k", type="inner") |
| UnionAll(concurrent=true) |
| LogicalView(tables="[0000-0031].sbtest1_[000-127]", shardCount=128, sql="SELECT * FROM `sbtest1` WHERE (`id` > ?)") |
| UnionAll(concurrent=true) |
| LogicalView(tables="[0000-0031].sbtest1_[000-127]", shardCount=128, sql="SELECT `k` FROM `sbtest1` WHERE (`k` > ?)") |
| HitCache:false |
+----------------------------------------------------------------------------------------------------------------------------+
7 rows in set (0.03 sec)
NlJOIN的計劃包括三部分內容:
- 輸出列信息:輸出的列名,示例中的JOIN會輸出5列
id="id", k="k", c="c", pad="pad", k0="k0"。 - condition:連接條件,示例中連接條件為
id = k。 - type:連接類型,示例中是INNER JOIN,因此其連接類型為
inner。
BKAJoin(Batched Key Access Join),表示通過批量鍵值查詢的方式進行JOIN,即從左表取一批數據,構建一個IN條件拼接在訪問右表的SQL中,從右表一次獲取一批數據進行JOIN。
explain select a.* from sbtest1 a, sbtest1 b where a.id = b.k order by a.id;
+-------------------------------------------------------------------------------------------------------------------------------+
| LOGICAL PLAN |
+-------------------------------------------------------------------------------------------------------------------------------+
| Project(id="id", k="k", c="c", pad="pad") |
| BKAJoin(id="id", k="k", c="c", pad="pad", id0="id0", k0="k0", c0="c0", pad0="pad0", condition="id = k", type="inner") |
| MergeSort(sort="id ASC") |
| LogicalView(tables="[0000-0031].sbtest1_[000-127]", shardCount=128, sql="SELECT * FROM `sbtest1` ORDER BY `id`") |
| UnionAll(concurrent=true) |
| LogicalView(tables="[0000-0031].sbtest1_[000-127]", shardCount=128, sql="SELECT * FROM `sbtest1` WHERE (`k` IN ('?'))") |
| HitCache:false |
+-------------------------------------------------------------------------------------------------------------------------------+
7 rows in set (0.01 sec)
BKAJoin的計劃內容與NlJoin相同,這兩個操作符命名不同,旨在告知執行器以何種方法執行JOIN操作。另外,以上執行計劃中右表的LogicalView中'k' IN ('?')是優化器構建出來的對右表的IN查詢模板。
如上文介紹,LogicalView表示從底層數據源獲取數據的操作符,與之對應的,LogicalModifyView表示對底層數據源的修改操作符,其中也會記錄一個SQL語句,該SQL可能是INSERT、UPDATE或者DELETE。
explain update sbtest1 set c='Hello, DRDS' where id > 1000;
+--------------------------------------------------------------------------------------------------------------------------------+
| LOGICAL PLAN |
+--------------------------------------------------------------------------------------------------------------------------------+
| LogicalModifyView(tables="[0000-0031].sbtest1_[000-127]", shardCount=128, sql="UPDATE `sbtest1` SET `c` = ? WHERE (`id` > ?)") |
| HitCache:false |
+--------------------------------------------------------------------------------------------------------------------------------+
2 rows in set (0.03 sec)
explain delete from sbtest1 where id > 1000;
+-------------------------------------------------------------------------------------------------------------------------+
| LOGICAL PLAN |
+-------------------------------------------------------------------------------------------------------------------------+
| LogicalModifyView(tables="[0000-0031].sbtest1_[000-127]", shardCount=128, sql="DELETE FROM `sbtest1` WHERE (`id` > ?)") |
| HitCache:false |
+-------------------------------------------------------------------------------------------------------------------------+
2 rows in set (0.03 sec)
LogicalModifyView查詢計劃的內容與LogicalView類似,包括下發的物理分表,分表數以及SQL模板。同樣,由于開啟了PlanCache,對SQL做了參數化處理,SQL模板中的常量會用?替換。
PhyTableOperation表示對某個物理分表執行一個操作。該操作符目前僅用于INSERT INTO ... VALUES ...。
explain insert into sbtest1 values(1, 1, '1', '1'),(2, 2, '2', '2');
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| LOGICAL PLAN |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| PhyTableOperation(tables="SYSBENCH_CORONADB_1526954857179TGMMSYSBENCH_CORONADB_VGOC_0000_RDS.[sbtest1_001]", sql="INSERT INTO ? (`id`, `k`, `c`, `pad`) VALUES(?, ?, ?, ?)", params="`sbtest1_001`,1,1,1,1") |
| PhyTableOperation(tables="SYSBENCH_CORONADB_1526954857179TGMMSYSBENCH_CORONADB_VGOC_0000_RDS.[sbtest1_002]", sql="INSERT INTO ? (`id`, `k`, `c`, `pad`) VALUES(?, ?, ?, ?)", params="`sbtest1_002`,2,2,2,2") |
| |
| HitCache:false |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
4 rows in set (0.00 sec)
示例中,INSERT插入兩行數據,每行數據對應一個PhyTableOperation操作符,PhyTableOperation操作符的內容包括三部分:
- tables:物理表名,僅有唯一一個物理表名。
- sql:SQL模板,該SQL模板中表名和常量均被參數化,用
?替換,對應的參數在隨后的params中給出。 - params:SQL模板對應的參數,包括表名和常量。
其他信息
HitCachePolarDB-X 1.0會默認開PlanCache 功能,HitCache用于告知用戶當前查詢是否命中PlanCache。如下示例,第一次運行HitCache為false,第二次運行為true。
explain select * From sbtest1 where id > 1000;
+-----------------------------------------------------------------------------------------------------------------------+
| LOGICAL PLAN |
+-----------------------------------------------------------------------------------------------------------------------+
| UnionAll(concurrent=true) |
| LogicalView(tables="[0000-0031].sbtest1_[000-127]", shardCount=128, sql="SELECT * FROM `sbtest1` WHERE (`id` > ?)") |
| HitCache:false |
+-----------------------------------------------------------------------------------------------------------------------+
3 rows in set (0.01 sec)
explain select * From sbtest1 where id > 1000;
+-----------------------------------------------------------------------------------------------------------------------+
| LOGICAL PLAN |
+-----------------------------------------------------------------------------------------------------------------------+
| UnionAll(concurrent=true) |
| LogicalView(tables="[0000-0031].sbtest1_[000-127]", shardCount=128, sql="SELECT * FROM `sbtest1` WHERE (`id` > ?)") |
| HitCache:true |
+-----------------------------------------------------------------------------------------------------------------------+
3 rows in set (0.00 sec)