本文將介紹如何在PolarDB-X 1.0中做IN查詢時,選擇最佳的Values個數(shù)。
功能介紹
實(shí)際場景中經(jīng)常需要根據(jù)一些常量指標(biāo)做IN查詢,其中IN的字段是分區(qū)鍵。例如在電商場景中,所有訂單都會記錄到訂單表Order,此表按照訂單ID進(jìn)行拆分,一個買家經(jīng)常會根據(jù)已購買的訂單列表,查詢這些訂單的具體信息。假設(shè)用戶已購買的訂單數(shù)是2,那么會產(chǎn)生2個值的IN條件查詢,理論上查詢會路由到兩個2分片。查詢SQL示例:
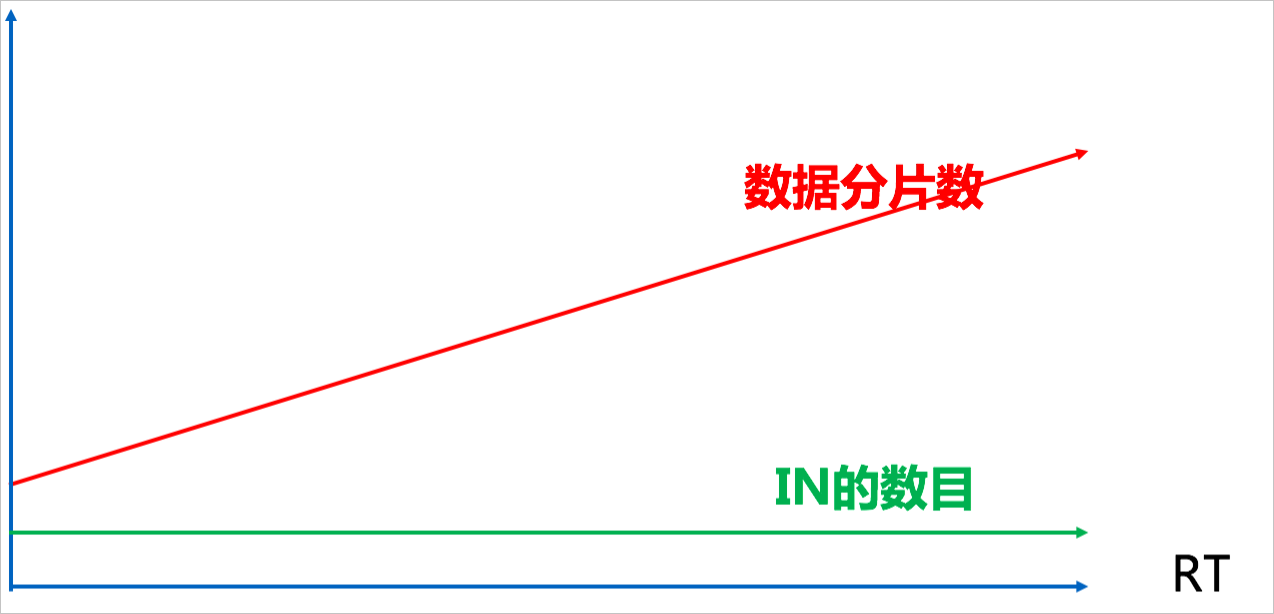
SELECT * FROM ORDER WHERE ORDER_ID IN (id1,id2)隨著用戶購買的訂單數(shù)增加,查詢訂單信息的IN值數(shù)量也會增加,這樣一次查詢很可能會路由到所有的分片,導(dǎo)致RT變高。下圖展示了IN值數(shù)量、掃描分片數(shù)和RT之間的關(guān)系。

為了盡可能避免隨著IN值數(shù)量增加,導(dǎo)致物理SQL膨脹和掃描壓力,PolarDB-X 1.0在內(nèi)核版本5.4.8-16069335(包含)之后引入了基于IN值做動態(tài)分區(qū)裁剪的能力。
繼續(xù)以上述場景為例假設(shè)Order表分片數(shù)量是128,IN查詢的數(shù)量128個,那么一次查詢的SQL為:
SELECT * FROM ORDER WHERE ORDER_ID IN (id1,id2,id3....id128)如果ID足夠離散,可能會分散到所有的分片,需要查詢最多128個分片,每個分片的物理查詢沒有做IN值的裁剪,每個物理查詢都會攜帶128個IN值條件下推給MySQL,過多的IN條件也會加大MySQL執(zhí)行壓力。查詢示例如下:
SELECT * FROM ORDER WHERE ORDER_ID_1 IN (id1,id2,id3....id128);
SELECT * FROM ORDER WHERE ORDER_ID_2 IN (id1,id2,id3....id128);
SELECT * FROM ORDER WHERE ORDER_ID_3 IN (id1,id2,id3....id128);
.....
SELECT * FROM ORDER WHERE ORDER_ID_128 IN (id1,id2,id3....id128);在支持IN分區(qū)裁剪的版本上,首先計算層會根據(jù)條件計算分片,引入IN值的動態(tài)分片裁剪,下發(fā)給MySQL的物理查詢上就會只包含屬于該分片的ID條件,裁剪掉了多余的IN值條件,因此IN查詢的RT和吞吐都會有一定的提升。查詢示例如下:
SELECT * FROM ORDER WHERE ORDER_ID_1 IN (id1);
SELECT * FROM ORDER WHERE ORDER_ID_2 IN (id2,id12);
SELECT * FROM ORDER WHERE ORDER_ID_3 IN (id3,id4,id5);
.....
SELECT * FROM ORDER WHERE ORDER_ID_32 IN (id100....id128);另外,PolarDB-X 1.0內(nèi)部針對跨分片的查詢會有一個Parallel Query執(zhí)行,例如涉及32個分片,針對每個用戶查詢,會有節(jié)點(diǎn)CPU內(nèi)核數(shù)大小的并發(fā)度,例如分布式下單個節(jié)點(diǎn)規(guī)格為16core時,默認(rèn)并發(fā)數(shù)就是16個,即32個分片會分成2批才能執(zhí)行完成。
- IN的值的數(shù)目遠(yuǎn)小于分片數(shù),這樣可以避免每次都做全分片查詢;
- IN的值的數(shù)目不會隨著業(yè)務(wù)的發(fā)展而增長,這樣可以避免隨著業(yè)務(wù)變化而導(dǎo)致性能下降;
- 兼顧RT和吞吐的話,建議IN的值的數(shù)量在8~32之間。
滿足上述最佳經(jīng)驗(yàn)后,涉及到IN查詢的業(yè)務(wù)可以做到面向并發(fā)場景下的線性擴(kuò)展,而RT也不會有明顯抖動。線性擴(kuò)展舉例:例如分布式16core能跑1萬個IN并發(fā),擴(kuò)展到32core之后就能跑2萬個并發(fā)。
比對測試
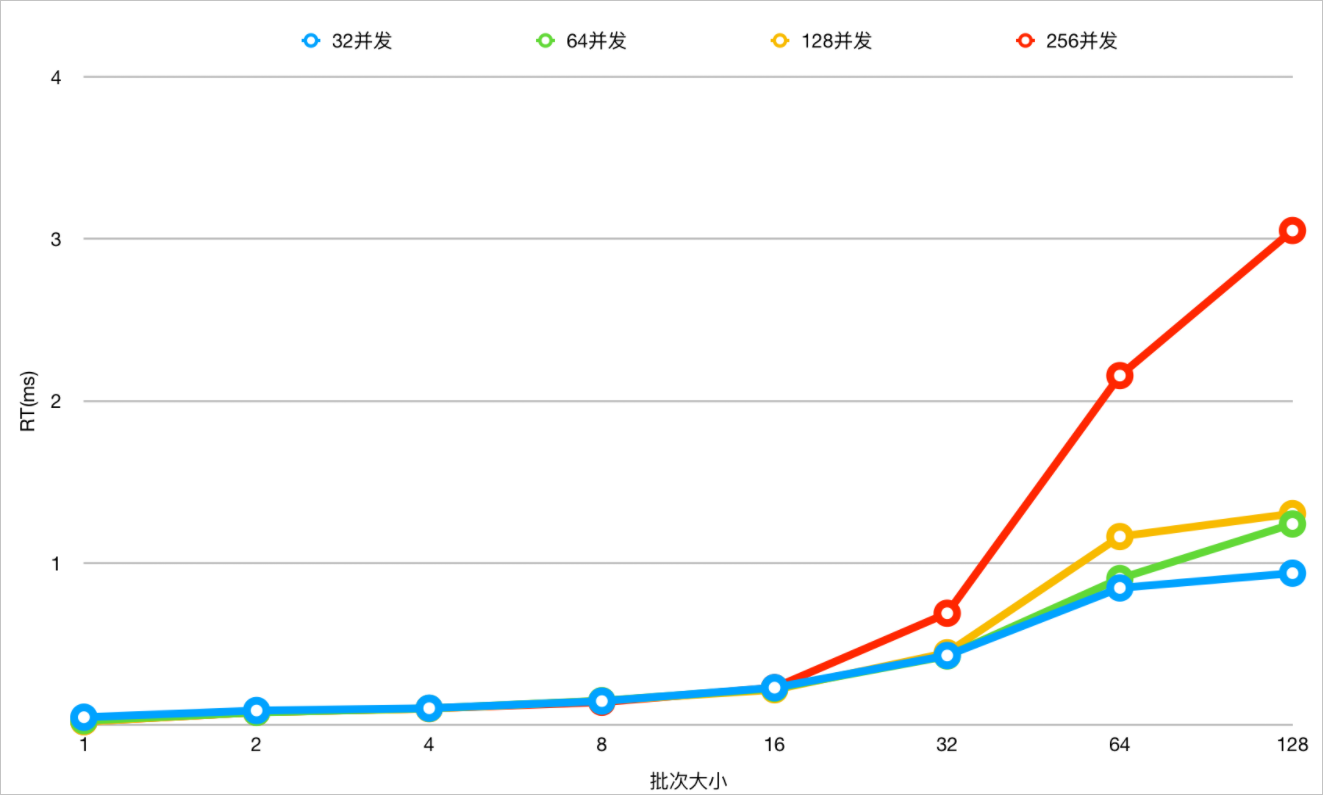
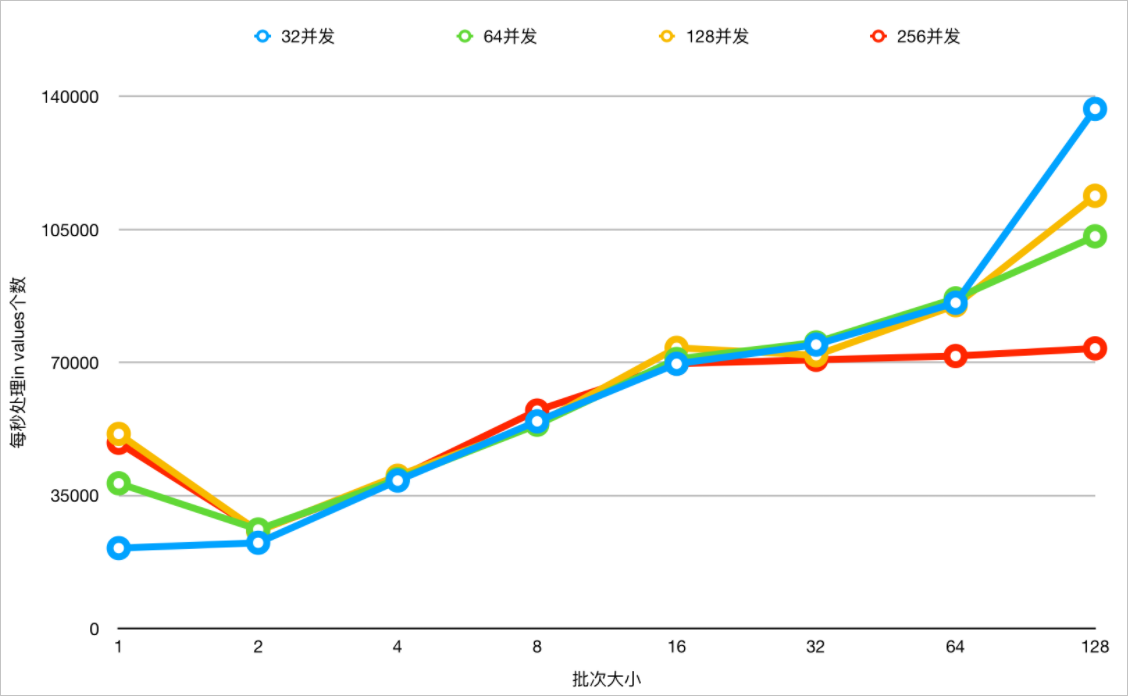
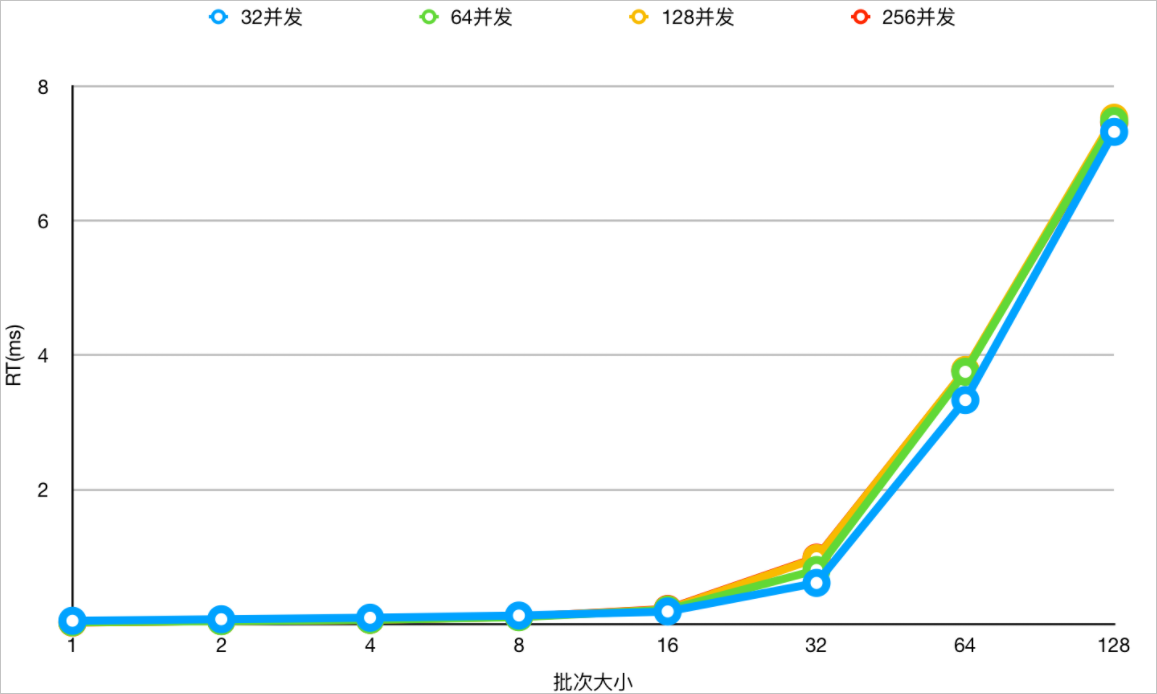
在兼顧RT和吞吐的場景下,確定合理的IN查詢的值的數(shù)量。在規(guī)格2×16C64G的節(jié)點(diǎn),針對一張分表數(shù)量為64,分表記錄數(shù)為百萬級別的表在不同值數(shù)量、不同并發(fā)下做測試。在內(nèi)核版本5.4.8-16069335(包含)之后針對IN查詢進(jìn)一步完善了動態(tài)裁剪分表的能力,下發(fā)的物理SQL也會裁剪掉多余的Values,下面是比對測試的結(jié)果。
- 在不同并發(fā)下,不同Values值數(shù)量下測試,開啟IN查詢動態(tài)裁剪能力下,查看RT變化。
- 在不同并發(fā)下,不同Values值數(shù)量下測試,開啟IN查詢動態(tài)裁剪能力下,查看吞吐變化。
- 在不同并發(fā)下,不同Values值數(shù)量下測試,關(guān)閉IN查詢動態(tài)裁剪能力下,查看RT變化。
- 在不同并發(fā)下,不同Values值數(shù)量下測試,關(guān)閉IN查詢動態(tài)裁剪能力下,查看吞吐變化。
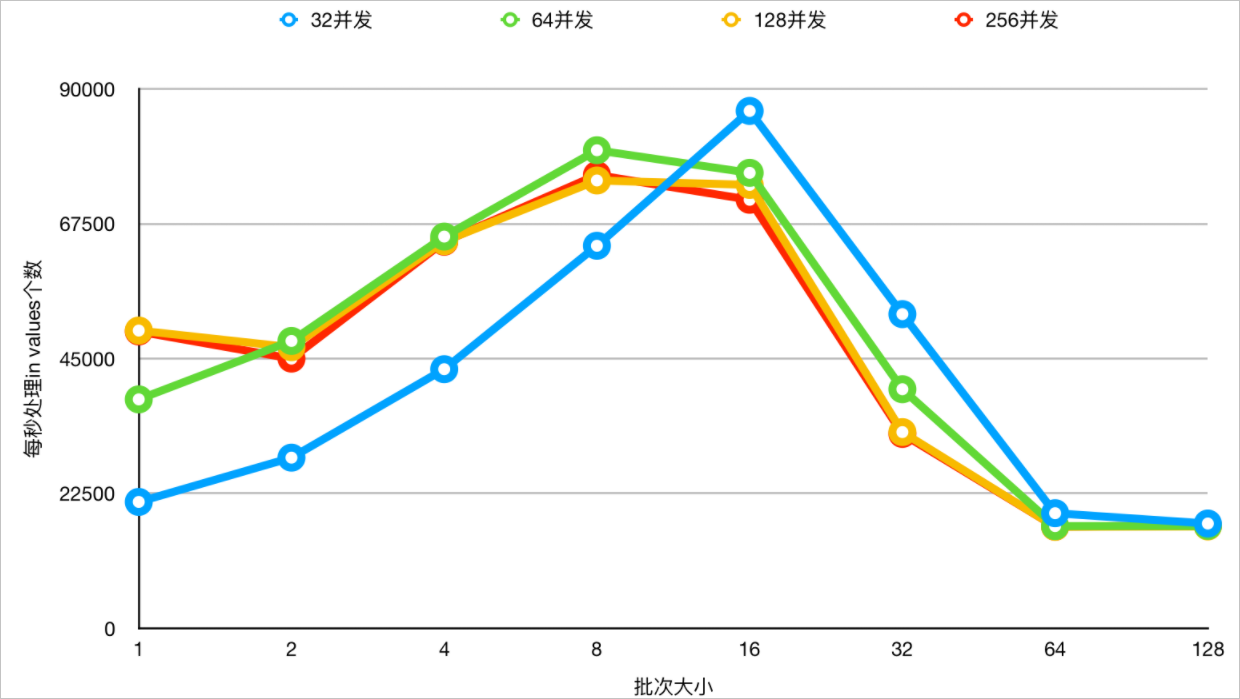
- 兼顧RT和吞吐時,建議IN的值的數(shù)量在8~32之間,基本對齊分布式Parallel Query的默認(rèn)并發(fā)度(單節(jié)點(diǎn)的CPU內(nèi)核數(shù))。
- 在內(nèi)核版本5.4.8-16069335(包含)之后,在開啟IN查詢的動態(tài)裁剪能力下,吞吐和RT都有明顯的優(yōu)勢,推薦您將內(nèi)核版本升級至5.4.8及以上版本。