實(shí)踐案例
本文介紹向量化引擎實(shí)踐案例與常見問題。
實(shí)踐案例
以下所有案例,需要在指定的數(shù)據(jù)庫中創(chuàng)建插件(polar_csi)并啟用向量化引擎功能,詳細(xì)的功能開啟及語法說明請(qǐng)參考開啟和使用向量化引擎。
案例一:寬表模式中對(duì)指定列的統(tǒng)計(jì)分析
寬表模式下,一張表擁有數(shù)十個(gè)列甚至上百個(gè)列,但查詢負(fù)載中只需要統(tǒng)計(jì)/分析部分列,此時(shí)可以使用加速索引進(jìn)行加速。
以一張包含24個(gè)列的widecolumntable表為例,包含BIGINT、DECIMAL、TEXT、JSONB、TEXT[]等類型,現(xiàn)要對(duì)其中的id_1,domain,consumption,start_time和end_time等五個(gè)列進(jìn)行統(tǒng)計(jì)分析,統(tǒng)計(jì)每個(gè)客戶在過去一年多個(gè)domain里消費(fèi)的金額。
創(chuàng)建一張名為widecolumntable表,表格結(jié)構(gòu)定義如下,然后按照您的需求插入測(cè)試數(shù)據(jù)。
CREATE TABLE widecolumntable ( id_1 BIGINT NOT NULL PRIMARY KEY, id_2 BIGINT, id_3 BIGINT, id_4 BIGINT, id_5 BIGINT, id_6 BIGINT, version INT, domain TEXT, consumption DECIMAL(18,3), c_level CHARACTER varying(1) NOT NULL, priority BIGINT, operator TEXT, notify_policy TEXT, call_id UUID NOT NULL, provider_id BIGINT NOT NULL, name_1 TEXT NOT NULL, name_2 TEXT NOT NULL, name_3 TEXT, start_time TIMESTAMP WITH TIME ZONE NOT NULL, end_time TIMESTAMP WITH TIME ZONE NOT NULL, comment JSONB NOT NULL, description TEXT[] NOT NULL, created_at TIMESTAMP WITH TIME ZONE DEFAULT now() NOT NULL, updated_at TIMESTAMP WITH TIME ZONE DEFAULT now() NOT NULL );將id_1,domain,consumption,start_time和end_time列加入到加速索引中。
CREATE INDEX idx_wide_csi ON widecolumntable USING CSI(id_1, domain, consumption, start_time, end_time);統(tǒng)計(jì)過去一年客戶在不同domain中消費(fèi)金額,并按消費(fèi)額進(jìn)行排序。
SET polar_csi.exec_parallel to 4; SET polar_csi.scan_parallel to 4; SELECT id_1, domain,SUM(consumption) FROM widecolumntable WHERE start_time > '20230101' and end_time < '20240101' GROUP BY id_1, domain Order By SUM(consumption);測(cè)試結(jié)果:在一億條數(shù)據(jù)規(guī)模和4并行度模式下,采用向量化引擎+加速索引方式的性能為PostgreSQL原生并行執(zhí)行的30倍。
查詢語句
PostgreSQL原生并行
向量化引擎+加速索引
Q1
243 s
7.9 s
案例二:為分區(qū)表創(chuàng)建加速索引
在PostgreSQL中,分區(qū)表是應(yīng)對(duì)數(shù)據(jù)不斷增長(zhǎng)的有效手段,會(huì)通過分區(qū)裁剪來加速查詢。PolarDB PostgreSQL版向量化引擎也支持分區(qū)表,能夠進(jìn)一步應(yīng)對(duì)分區(qū)表的統(tǒng)計(jì)和分析需求。
本案例中,會(huì)創(chuàng)建一個(gè)多級(jí)分區(qū)表,并模擬插入3.2億條數(shù)據(jù)(約16 GB),之后根據(jù)分區(qū)條件進(jìn)行統(tǒng)計(jì)分析。
創(chuàng)建名為sales的多級(jí)分區(qū)表,以時(shí)間列sale_date作為分區(qū)鍵,定義如下。
CREATE TABLE sales ( sale_id serial, product_id int NOT NULL, sale_date date NOT NULL, amount numeric(10,2) NOT NULL, primary key(sale_id, sale_date) ) PARTITION BY RANGE (sale_date); CREATE TABLE sales_2023 PARTITION OF sales FOR VALUES FROM ('2023-1-1') TO ('2024-1-1') PARTITION BY RANGE (sale_date); CREATE TABLE sales_2023_a PARTITION OF sales_2023 FOR VALUES FROM ('2023-1-1') TO ('2023-7-1'); CREATE TABLE sales_2023_b PARTITION OF sales_2023 FOR VALUES FROM ('2023-7-1') TO ('2024-1-1'); CREATE TABLE sales_2024 PARTITION OF sales FOR VALUES FROM ('2024-1-1') TO ('2025-1-1') PARTITION BY RANGE (sale_date); CREATE TABLE sales_2024_a PARTITION OF sales_2024 FOR VALUES FROM ('2024-1-1') TO ('2024-7-1'); CREATE TABLE sales_2024_b PARTITION OF sales_2024 FOR VALUES FROM ('2024-7-1') TO ('2025-1-1');生成數(shù)據(jù)并寫入到分區(qū)表,約16 GB。
INSERT INTO sales (product_id, sale_date, amount) SELECT (random()*100)::int AS product_id, '2023-01-1'::date + i/3200000*7 AS sale_date, (random()*1000)::numeric(10,2) AS amount FROM generate_series(1, 320000000) i;為表創(chuàng)建加速索引,將sale_id,product_id,sale_date和amount字段加入到加速索引。
CREATE INDEX ON sales USING CSI(sale_id, product_id, sale_date, amount);查詢。根據(jù)不同的分區(qū)條件生成三條查詢語句,為Q1,Q2和Q3。
SET polar_csi.enable_query to on; SET polar_csi.exec_parallel to 4; SET polar_csi.scan_parallel to 4; SET max_parallel_workers_per_gather to 4; -- Q1 EXPLAIN ANALYZE SELECT sale_date, COUNT(*) FROM sales WHERE sale_date BETWEEN '2023-1-1' and '2023-3-1' AND amount > 100 GROUP BY sale_date; -- Q2 EXPLAIN ANALYZE SELECT sale_date, COUNT(*) FROM sales WHERE sale_date BETWEEN '2023-1-1' and '2023-9-1' AND amount > 100 GROUP BY sale_date; -- Q3 EXPLAIN ANALYZE SELECT sale_date, COUNT(*) FROM sales WHERE sale_date BETWEEN '2023-1-1' and '2024-3-1' AND amount > 100 GROUP BY sale_date;測(cè)試結(jié)果:4并行度模式下,向量化引擎在三條查詢語句中都比原生PostgreSQL并行執(zhí)行快25倍以上。
查詢語句
PostgreSQL原生并行
向量化引擎+加速索引
Q1
9.29 s
0.26 s
Q2
29.19 s
1.03 s
Q2
48.30 s
2.02 s
案例三:與 OSS 結(jié)合構(gòu)建低成本歷史數(shù)據(jù)查詢與分析方案
PolarDB PostgreSQL版冷熱分層存儲(chǔ)可以將歷史數(shù)據(jù)轉(zhuǎn)儲(chǔ)到OSS中,這類數(shù)據(jù)每天訪問頻次較低,主要用于數(shù)據(jù)歸檔與分析使用。PolarDB PostgreSQL版向量化引擎支持與冷熱分層存儲(chǔ)的結(jié)合,用戶可以方便地分析存儲(chǔ)在OSS中的冷數(shù)據(jù)。
本案例在案例二的基礎(chǔ)上,展示如何將分區(qū)表以及對(duì)應(yīng)的加速索引轉(zhuǎn)儲(chǔ)到冷存中。
使用前提:集群已經(jīng)開啟冷數(shù)據(jù)分層存儲(chǔ)功能,開啟冷數(shù)據(jù)分層存儲(chǔ)功能請(qǐng)參考開啟和使用冷數(shù)據(jù)分層存儲(chǔ)。
創(chuàng)建polar_osfs_toolkit插件。
CREATE EXTENSION IF NOT EXISTS polar_osfs_toolkit;將sales表的所有子分區(qū)以及對(duì)應(yīng)的加速索引都轉(zhuǎn)儲(chǔ)到OSS中。
SELECT polar_alter_subpartition_to_oss_with_indexes('sales',0);查看子分區(qū)表sales_2023_a的信息,表空間為OSS。
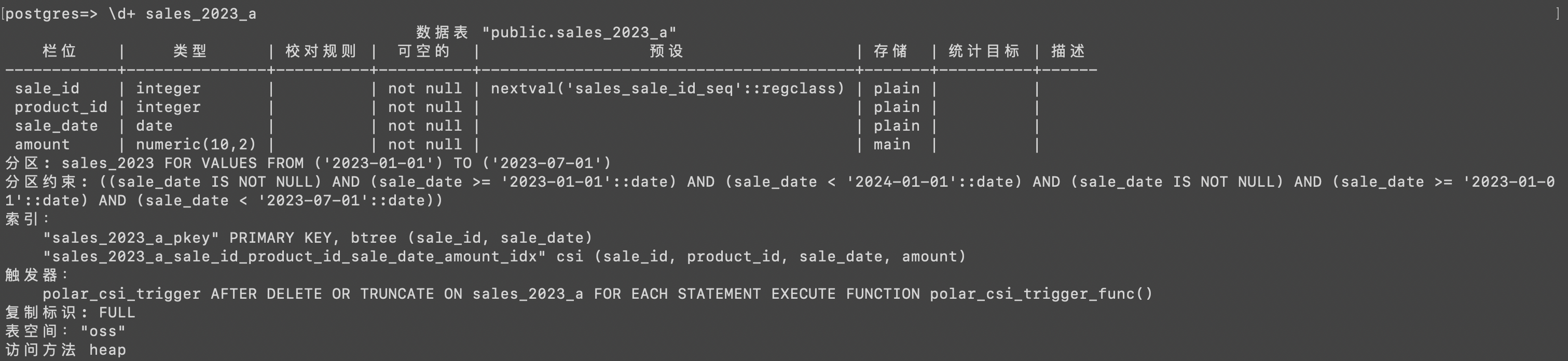
查詢,無需更改查詢語句。
SET polar_csi.enable_query to on; SET polar_csi.exec_parallel to 4; SET polar_csi.scan_parallel to 4; SET max_parallel_workers_per_gather to 4; -- Q1 EXPLAIN ANALYZE SELECT sale_date, COUNT(*) FROM sales WHERE sale_date BETWEEN '2023-1-1' and '2023-3-1' AND amount > 100 GROUP BY sale_date; -- Q2 EXPLAIN ANALYZE SELECT sale_date, COUNT(*) FROM sales WHERE sale_date BETWEEN '2023-1-1' and '2023-9-1' AND amount > 100 GROUP BY sale_date; -- Q3 EXPLAIN ANALYZE SELECT sale_date, COUNT(*) FROM sales WHERE sale_date BETWEEN '2023-1-1' and '2024-3-1' AND amount > 100 GROUP BY sale_date;除了手動(dòng)將分區(qū)表數(shù)據(jù)轉(zhuǎn)儲(chǔ)到OSS之外,還可以結(jié)合pg_cron插件自動(dòng)化將歷史分區(qū)表數(shù)據(jù)轉(zhuǎn)儲(chǔ)到OSS。詳細(xì)案例請(qǐng)參考分區(qū)表按時(shí)間線自動(dòng)冷存。
案例四:將分析后的數(shù)據(jù)寫入到新的表
在很多統(tǒng)計(jì)類的查詢負(fù)載中,會(huì)將分析后的數(shù)據(jù)保存到其他結(jié)果表中。
PolarDB PostgreSQL版向量化引擎支持INSERT INTO SELECT和CREATE TABLE AS SELECT語句,可以在一條SQL語句中,利用向量化引擎高效分析并將結(jié)果寫入到結(jié)果表中。
利用
CREATE TABLE AS SELECT將案例一的統(tǒng)計(jì)結(jié)果轉(zhuǎn)到新的表中。SET polar_csi.exec_parallel to 4; SET polar_csi.scan_parallel to 4; CREATE TABLE result_table AS SELECT id_1, domain,SUM(consumption) FROM widecolumntable WHERE start_time > '20230101' and end_time < '20240101' GROUP BY id_1, domain Order By SUM(consumption);利用
INSERT INTO SELECT將案例一的統(tǒng)計(jì)結(jié)果插入到已有的表中。CREATE TABLE result_table(id_1 BIGINT, domain TEXT, sum DECIMAL(18,3)); INSERT INTO result_table SELECT id_1, domain,SUM(consumption) as sum FROM widecolumntable WHERE start_time > '20230101' and end_time < '20240101' GROUP BY id_1, domain Order By SUM(consumption);
常見問題
與PolarDB ePQ的關(guān)系
PolarDB PostgreSQL版的ePQ是基于云原生一寫多讀架構(gòu)下,為了充分利用所有RO節(jié)點(diǎn)的計(jì)算資源而研發(fā)的跨機(jī)并行能力。其能夠?qū)⒁粋€(gè)查詢語句分發(fā)到所有的RO節(jié)點(diǎn)執(zhí)行,而開源PostgreSQL的并行能力只能使用一個(gè)節(jié)點(diǎn)的計(jì)算資源,因此PolarDB PostgreSQL版的ePQ比開源PostgreSQL具有更好的scale out能力。
PolarDB PostgreSQL版的向量化引擎與ePQ并非同一種技術(shù),向量化引擎的目標(biāo)是在同樣的硬件資源下算得更快,而ePQ的目標(biāo)是能充分利用數(shù)據(jù)庫集群的所有資源,二者是相互補(bǔ)充的關(guān)系。
與開源PostgreSQL的關(guān)系
向量化引擎不侵入開源PostgreSQL,只是作為PostgreSQL的一個(gè)索引,如果不需要性能加速,刪除索引即可,不影響PostgreSQL中已有的基礎(chǔ)數(shù)據(jù)。后續(xù)會(huì)納入到PolarDB PostgreSQL版開源版本中。
查詢無法使用向量化引擎加速
請(qǐng)按如下步驟檢查:
查看表是否創(chuàng)建加速索引。
查看所涉及的列是否都在加速索引中。
是否開啟向量化查詢,執(zhí)行
SET polar_csi.enable_query = ON開啟向量化引擎功能。polar_csi.cost_threshold過大,查詢語句會(huì)被PostgreSQL原生執(zhí)行引擎處理,可以將該值調(diào)小。如果還無法使用向量化引擎加速,可執(zhí)行
SET client_min_messages = debug5來進(jìn)一步排查。
創(chuàng)建索引時(shí)的錯(cuò)誤消息
錯(cuò)誤一: ERROR: access method "csi" does not exist
需要?jiǎng)?chuàng)建polar_csi插件,請(qǐng)執(zhí)行以下指令。
CREATE EXTENSION polar_csi;錯(cuò)誤二: ERROR: function polar_csi_trigger_func() does not exist
search_path設(shè)置錯(cuò)誤導(dǎo)致無法創(chuàng)建polar_csi_trigger_func,請(qǐng)執(zhí)行以下指令。
SET search_path = 'public';