PolarDB MySQL版通過數據庫內核與RDMA網絡的深度融合,提供全局一致性(高性能模式),簡稱SCC。在保證全局數據一致性的前提下,實現高性能數據讀寫。與最終一致性方案相比,開啟全局一致性(高性能模式)后集群性能損失保持在10%以內。本文將詳細介紹全局一致性(高性能模式)的使用限制、技術原理、開啟方式以及性能測試結果對比。
版本要求
若要開啟全局一致性(高性能模式),PolarDB MySQL版企業版集群需為以下版本之一:
8.0.2版本且內核小版本需為8.0.2.2.19及以上。
8.0.1版本且內核小版本需為8.0.1.1.29及以上。
5.7版本且內核小版本需為5.7.1.0.26及以上。
如何確認集群版本,請參見查詢版本號。
注意事項
Serverless集群的所有只讀節點默認開啟全局一致性(高性能模式)。
全球數據庫網絡GDN中的從集群的只讀節點不支持開啟全局一致性(高性能模式)。
全局一致性(高性能模式)與Fast Query Cache功能兼容。若此前全局一致性(高性能模式)打開了分層的細粒度的修改跟蹤(MTT)優化功能。當同時開啟Fast Query Cache功能和全局一致性(高性能模式)功能時,全局一致性(高性能模式)的MTT優化功能將失效。
全局一致性(高性能模式)技術方案
PolarDB MySQL版全局一致性(高性能模式)是以PolarTrans為基礎,這是一套全新設計的基于時間戳的事務系統,旨在重構原生MySQL中基于活躍事務數組的傳統事務管理方式。該系統不僅支持分布式事務的擴展,更顯著提升了單機的性能表現。
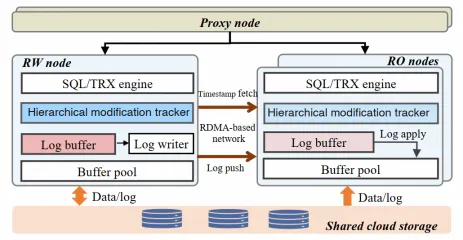
PolarDB全局一致性(高性能模式)的具體實現如下圖所示,利用高速RDMA網絡構建交互式多維度主從信息同步機制,取代了傳統的主從日志復制架構,并通過線性Lamport時間戳算法,減少RO節點獲取時間戳的次數,同時避免了不必要的日志回放等待。
線性Lamport時間戳:為了優化讀操作(RO)節點獲取最新修改時間戳的效率,我們引入了線性Lamport時間戳機制。傳統方法中,RO節點需要在處理每個請求時都從寫操作(RW)節點獲取時間戳,即使網絡速度很快,在高負載情況下也會產生顯著開銷。線性Lamport時間戳的優勢在于,RO節點可以將從RW節點獲取的時間戳存儲在本地。對于早于本地存儲的時間戳的請求,RO節點可以直接使用本地時間戳,無需再次向RW節點獲取。這種機制有效減少了高負載下頻繁獲取時間戳的開銷,提高了RO節點的性能。
分層的細粒度的修改跟蹤:為了優化讀操作(RO)的性能,RW引入了多級時間戳機制:全局、表級和頁面級。當RO處理請求時,首先會獲取全局時間戳。如果全局時間戳小于RO回放日志的時間戳,RO不會立即進入等待狀態,而是會繼續檢查請求訪問的表和頁面時間戳。只有當訪問的頁面時間戳仍然不滿足時,RO才會等待日志回放完成。這種機制可以有效避免一些不必要的日志回放等待,提高RO的響應速度。
基于RDMA的日志傳輸:PolarDB全局一致性(高性能模式)采用了單邊RDMA的接口來實現RW到RO的日志傳輸,極大地提高了日志傳輸速度,同時減少了日志傳輸時帶來的CPU開銷。
線性Lamport時間戳
為了降低讀請求的延遲和帶寬消耗,RO節點可以利用線性Lamport時間戳機制。當一個請求到達RO節點時,如果發現其他請求已經從RW節點獲取了時間戳,它可以直接重用該時間戳,從而避免重復請求,保證強一致性的同時提升性能。
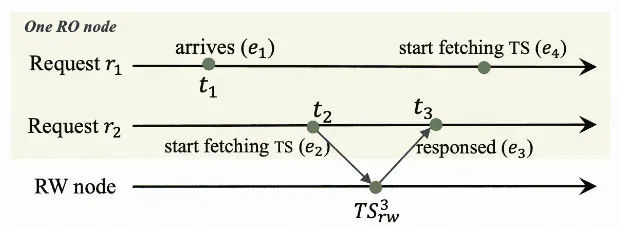
上圖中一個RO上有兩個并發的讀請求r1和r2。r2在t2時向RW發送讀取時間戳的請求,在t3時刻拿到了RW的時間戳TS3rw。我們可以得到這幾個事件的關系:e2TS3rwe3。r1在t1時刻到達。通過在RO給每個事件分配一個時間戳,可以確定同一個RO上不同事件的先后關系。如果t1在t2之前,我們可以得到e1e2TS3rwe3。也就是說r2拿到的時間戳,其實已經反映了r1到達之前的所有更新,所以r1可以直接使用r2的時間戳,而不必去拿新的時間戳。基于這個原則,RO每次拿到RW的時間戳時,都會把這個時間戳保存在本地,并且會記錄獲取到該時間戳的時間,如果某個請求的到達時間早于本地緩存時間戳的獲取時間,則該請求可以直接使用該時間戳。
分層的細粒度的修改跟蹤
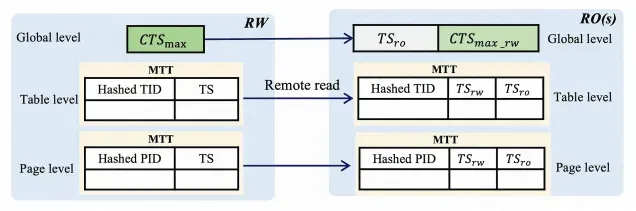
為了實現強一致讀,RO需要首先獲取RW當前事務的最新提交時間戳,并等待RO上的日志回放到該時間戳才能處理讀請求。然而,在等待日志回放期間,當前請求的數據可能已經是最新的,無需等待。為了避免不必要的等待時間。PolarDB全局一致性(高性能模式)采用了更加細粒度的修改追蹤。在RW上維護三層修改信息:全局的最新修改的時間戳,表級的時間戳和頁面(page)級別的時間戳。
在處理讀請求時,RO首先獲取全局時間戳,以判斷數據一致性。如果全局時間戳不滿足條件,RO會進一步獲取目標表的本地時間戳,進行更細粒度的校驗。如果仍不滿足,RO會繼續檢查目標頁面的時間戳,進行更精確的判斷。只有當頁面時間戳仍然大于RO日志回放時間戳時,RO才需要等待日志回放,以確保讀取到最新的數據。
在RW上,為了降低內存消耗,三種層級的時間戳都保存在內存哈希表中。為了進一步優化內存使用,多個表或頁的時間戳可能被映射到同一個哈希表位置。為了保證一致性,僅允許較大的時間戳替換較小的。這種設計確保即使RO獲取到較大的時間戳也不會破壞一致性。具體實現如圖所示,TID和PID分別表示表和頁的ID。RO獲取到的時間戳會按照線性Lamport時間戳的設計緩存到本地,方便其他符合條件的請求使用。
基于RDMA的日志傳輸
在PolarDB全局一致性(高性能模式)中。RW通過單邊RDMA的方式遠程將日志寫入到RO緩存,該過程不需要RO的CPU參與,同時延遲也很低。具體實現如下圖所示,RO和RW都維護了相同大小的log buffer。RW的后臺線程會將RW的log buffer通過RDMA寫入到RO的log buffer,RO通過讀取本地log buffer替代讀取文件, 加快復制同步效率。
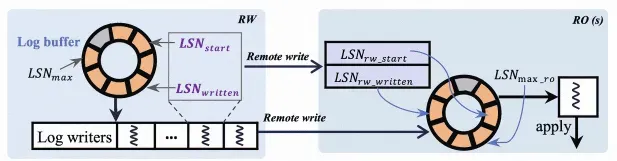
如需了解RDMA日志傳輸的更多說明,請參見RDMA日志傳輸。
如何開啟全局一致性(高性能模式)
登錄PolarDB控制臺,在目標集群的基本信息頁面的數據庫連接區域,選中需要開啟全局一致性(高性能模式)功能的連接地址,單擊配置。詳細操作步驟請參見配置數據庫代理。

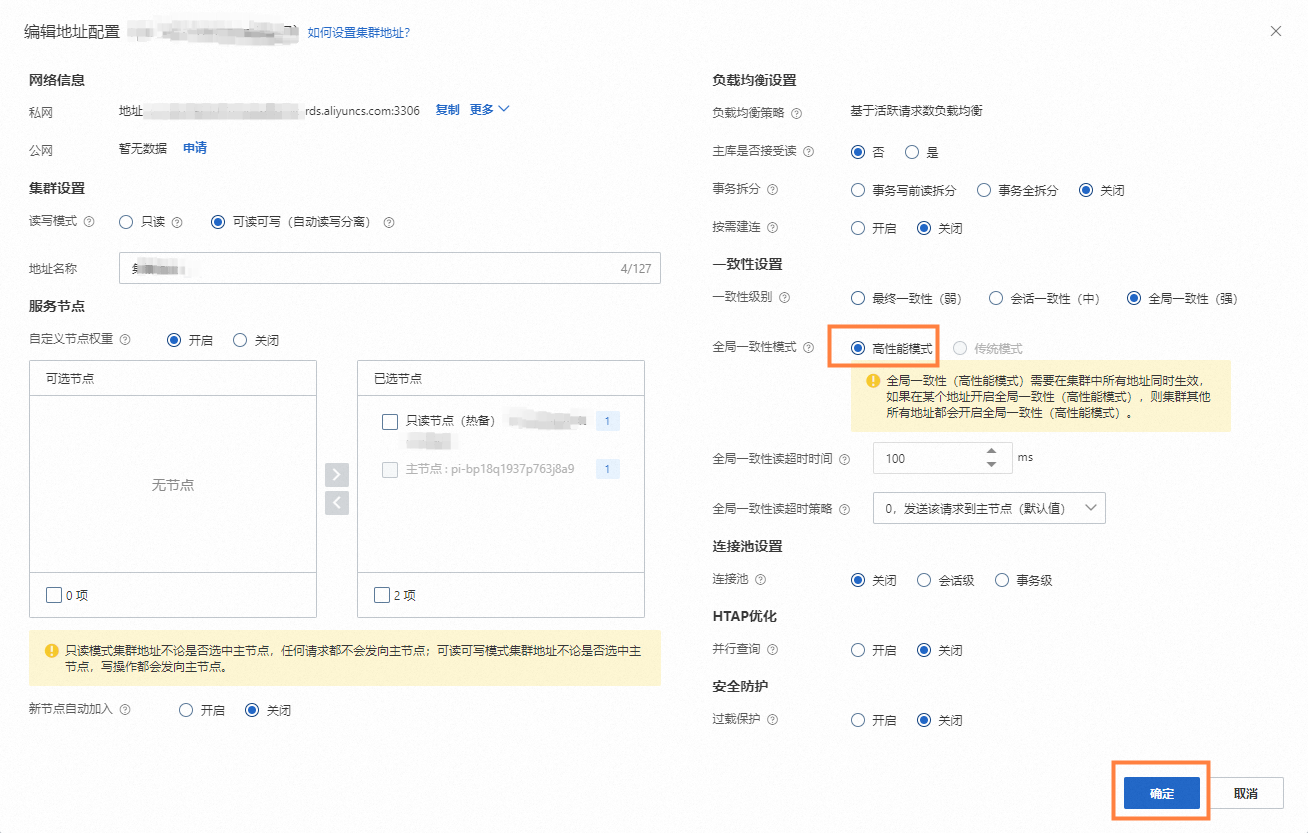
全局一致性(高性能模式)需要在集群中所有地址同時生效,如果在某個地址開啟全局一致性(高性能模式),則集群其他所有地址都會開啟全局一致性(高性能模式)。
性能對比
測試環境
一個規格為8核32 GB的PolarDB MySQL版8.0版本集群版。
測試工具
Sysbench
測試數據量
25張表,每張表250000行數據。
測試結果及說明
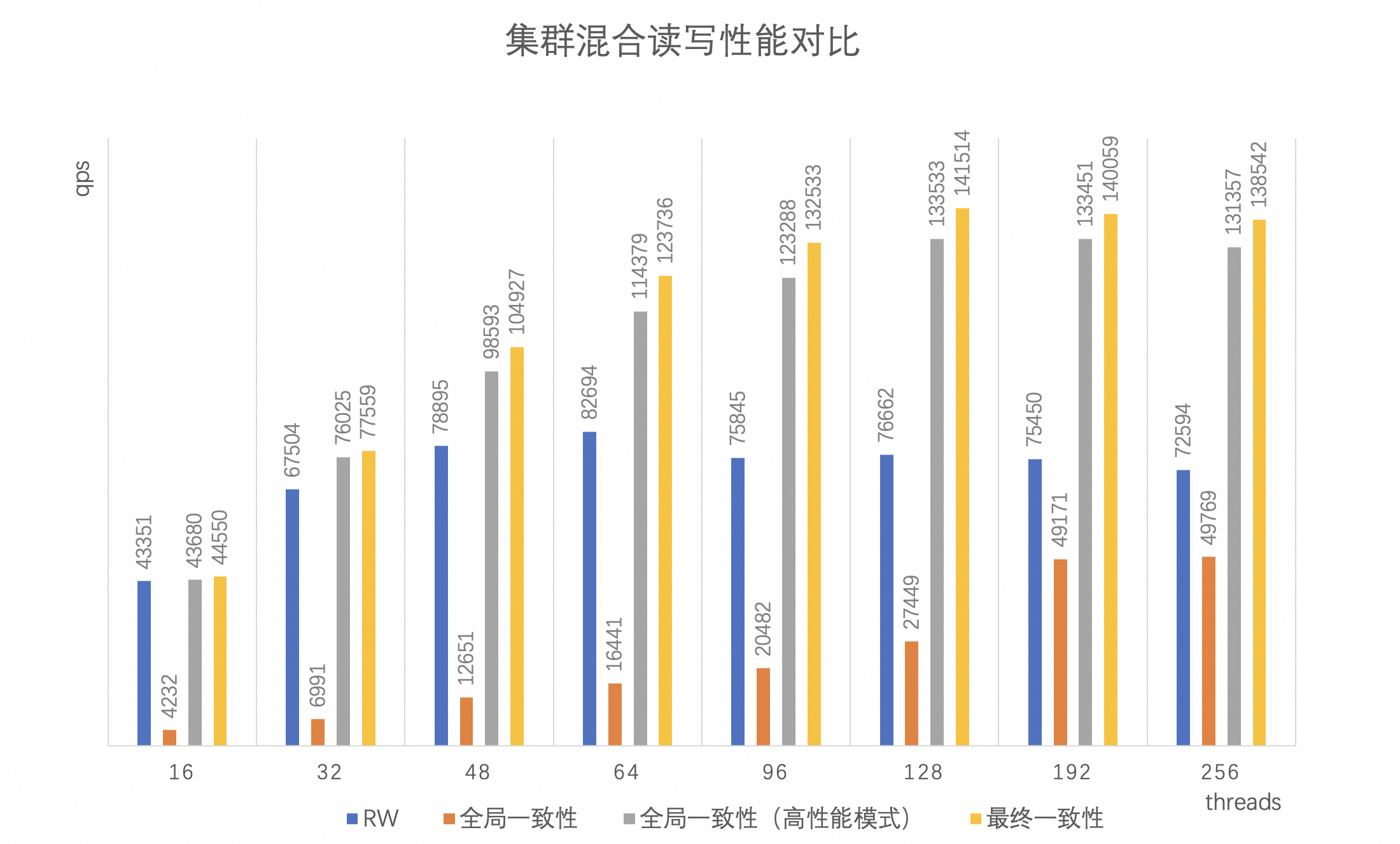
全局一致性(高性能模式)集群混合讀寫性能對比
圖表說明:
縱坐標qps:表示sysbench測試結果。
橫坐標threads:表示測試時使用的sysbench并發線程數。
RW:表示假設RO無法提供全局一致性讀,所有的讀寫請求均發往RW節點。
全局一致性:表示由代理提供的全局一致性功能。
全局一致性(高性能模式):表示打開內核提供的全局一致性(高性能模式)代理設置最終一致性。
最終一致性:表示代理設置為最終一致性讀,并且關閉內核提供的全局一致性(高性能模式)。
在
sysbench oltp_read_write場景中,全局一致性(高性能模式)相比較于最終一致性,集群整體性能損耗控制在10%以內。