設(shè)置優(yōu)化器的Join Reorder
為了提高列存索引(IMCI)處理復(fù)雜查詢的能力,列存索引優(yōu)化器通過結(jié)合變換規(guī)則與表中各個列的統(tǒng)計信息,基于代價生成高效的執(zhí)行計劃,以此來增強自身的優(yōu)化器能力。本文介紹列存索引查詢優(yōu)化功能的工作原理、使用方法以及使用限制等內(nèi)容。
工作原理
SQL是聲明式查詢語言,不會具體的描述SQL語句的查詢計劃,獲取一條SQL語句的正確結(jié)果時,可能存在若干個可行的查詢計劃。示例如下:
SELECT * FROM t0, t1, t2, t3 WHERE t0.a = t1.a AND t1.a = t2.a AND t2.a = t3.a AND t3.b = t1.b;對于上述SQL語句,通過以下兩種查詢計劃均可以獲取到正確的查詢結(jié)果。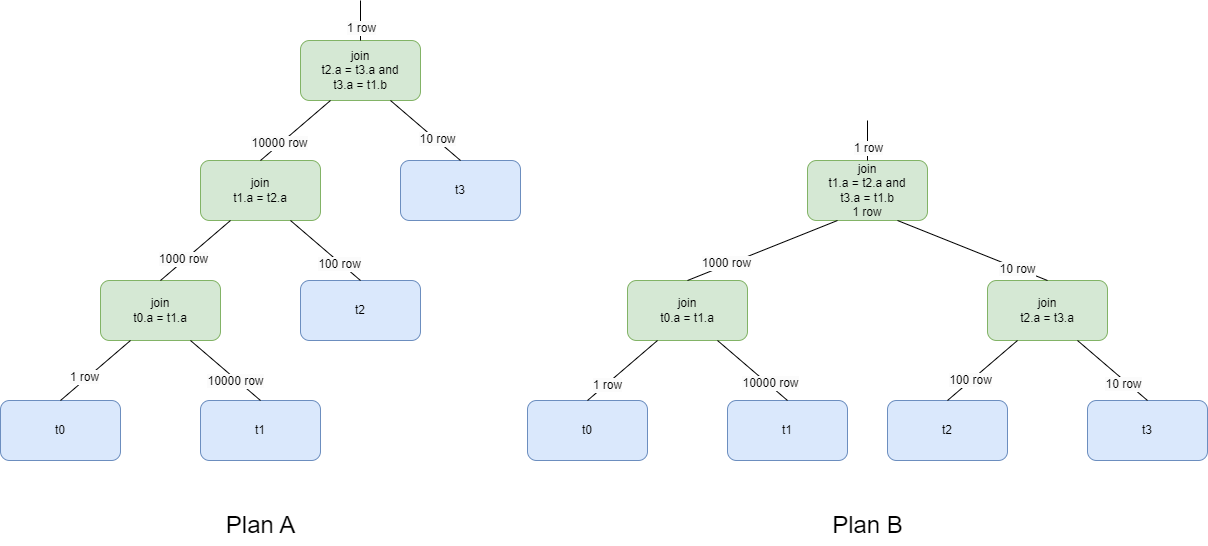 Plan A與Plan B稱之為等價查詢計劃。查詢優(yōu)化器作為一個搜索框架,其會通過從一個查詢計劃到另一個等價查詢計劃的變換,來搜索與當前SQL語句對應(yīng)的等價查詢計劃。例如:
Plan A與Plan B稱之為等價查詢計劃。查詢優(yōu)化器作為一個搜索框架,其會通過從一個查詢計劃到另一個等價查詢計劃的變換,來搜索與當前SQL語句對應(yīng)的等價查詢計劃。例如:t1 INNER JOIN t2與t2 INNER JOIN t1為一對等價查詢計劃,t1 INNER JOIN t2可以通過等價查詢變換生成t2 INNER JOIN t1。優(yōu)化器的這類變換稱之為查詢變換規(guī)則。
查詢優(yōu)化器工作流程如下:
輸入由數(shù)據(jù)庫解析SQL語句獲得的初始查詢計劃。
通過應(yīng)用查詢變換規(guī)則,由初始狀態(tài)的查詢計劃生成等價查詢計劃。
優(yōu)化器通過結(jié)合統(tǒng)計信息與代價模型,從等價查詢計劃中選擇出執(zhí)行代價最小的查詢計劃,作為最終的執(zhí)行計劃交由執(zhí)行層執(zhí)行。
查詢優(yōu)化功能需要依靠統(tǒng)計信息進行基數(shù)估算和代價計算以判別查詢計劃的優(yōu)劣,在列存索引中,表的統(tǒng)計信息包括以下內(nèi)容:
直方圖。描述對應(yīng)列的值的分布范圍,主要用于估算單張表上的取值范圍及等值謂詞的選擇率。
對應(yīng)列的特殊值的個數(shù)。主要用于估算
Group By中的分組個數(shù),也可用于輔助估計等值謂詞的選擇率。其他約束。如該列是否存在唯一索引,該列是否與其他列存在外鍵約束等。
查詢優(yōu)化器通過以下兩方面來計算查詢計劃中各個節(jié)點操作符的代價:
查詢計劃中操作符處理的總行數(shù),可以通過統(tǒng)計信息進行估算。
查詢計劃中各個操作符使用的算法復(fù)雜度。
其中,查詢計劃中操作符處理的總行數(shù)為算法復(fù)雜度函數(shù)的參數(shù)。各個節(jié)點的操作符代價和就是整個查詢計劃的執(zhí)行代價。如上圖中的兩個查詢計劃,假設(shè)采用hash join作為join的執(zhí)行算法,其代價公式為:
Costjoin=Cardinner+Cardouter
兩個執(zhí)行計劃的代價分別為:
CostA==10000+1+1000+100+10000+10=21111
CostB==10000+1+100+10+1000+10=11121
由執(zhí)行計劃的代價可以看出,Plan B的執(zhí)行代價更低。因此,優(yōu)化器將選擇Plan B作為最終的執(zhí)行計劃。
前提條件
PolarDB集群版本需滿足以下條件之一:
PolarDB MySQL版8.0.1版本,且修訂版本為8.0.1.1.31及以上。
PolarDB MySQL版8.0.2版本,且修訂版本為8.0.2.2.12及以上。
您可以通過查詢版本號來確認集群版本。
使用限制
以下情形可能會導(dǎo)致基數(shù)估算出現(xiàn)較大誤差,從而導(dǎo)致優(yōu)化器選擇次優(yōu)查詢計劃。您可以通過HINT語法指導(dǎo)優(yōu)化器生成理想的查詢計劃。
帶謂詞的查詢,查詢同一張表的不同列時使用了比較運算符。如
t1.c1>t1.c2。帶謂詞的查詢,查詢語句中使用的運算符不能使用統(tǒng)計信息進行估算。如
t1.c1 MOD 2=1、t1.c2 LIKE '%ABC%'。帶謂詞的查詢,查詢語句中存在表達式,且無法在使用優(yōu)化功能時進行計算。如
t1.c1+t1.c3>100。查詢語句中運算符所涉及的列沒有用于估算謂詞選擇率的統(tǒng)計信息。如
SELECT a, SUM(b) FROM t1 HAVING SUM(b) > 10。多個謂詞之間使用
AND操作符連接。如t1.c1>10 AND t1.c3<5。查詢語句的查詢層次太深。
查詢語句中join的表太多。您可以通過修改參數(shù)
loose_imci_max_enum_join_pairs的值,來調(diào)整列存索引優(yōu)化器搜索的join數(shù)量。
參數(shù)說明
您可以在控制臺上設(shè)置以下參數(shù),來開啟和使用列存索引優(yōu)化功能。在控制臺上設(shè)置參數(shù)的操作步驟請參見設(shè)置集群參數(shù)和節(jié)點參數(shù)。
參數(shù) | 說明 |
loose_imci_optimizer_switch | 列存索引查詢優(yōu)化功能控制開關(guān)。取值如下:
|
loose_imci_auto_update_statistic | 當統(tǒng)計信息過舊時,列存索引(IMCI)優(yōu)化器是否重新收集統(tǒng)計信息。取值如下:
|
loose_imci_max_enum_join_pairs | 在使用列存索引功能并開啟連接重排序時,允許列存索引優(yōu)化器搜索的等價執(zhí)行計劃數(shù)量。 取值范圍:0~4294967295。默認值為2000。 |
使用說明
使用列存索引優(yōu)化功能,您需要先根據(jù)選擇的信息采集策略采集統(tǒng)計信息,信息采集完成后,再開啟列存索引查詢優(yōu)化功能,并執(zhí)行查詢語句。
采集統(tǒng)計信息。
您可以根據(jù)以下兩種信息采集策略來采集統(tǒng)計信息。
在數(shù)據(jù)庫中定期對需要使用列存索引優(yōu)化功能的表執(zhí)行
ANALYZE TABLE命令,來構(gòu)建最新的統(tǒng)計信息。(推薦)對于新添加列存索引的表,在只讀節(jié)點上執(zhí)行
ANALYZE TABLE命令構(gòu)建初始的統(tǒng)計信息,再將參數(shù)loose_imci_auto_update_statistic的值設(shè)置為ASYNC來自動更新統(tǒng)計信息。
開啟列存索引查詢優(yōu)化功能。
您可以在控制臺上設(shè)置參數(shù)
loose_imci_optimizer_switch的值來開啟列存索引查詢優(yōu)化功能。執(zhí)行查詢語句。
查詢效果對比
以TPCH-Q8為例,該查詢語句涉及多張表,且在查詢語句中使用了聚合函數(shù)。
SELECT
o_year,
SUM(
CASE
WHEN nation = 'BRAZIL' THEN volume
ELSE 0
END
) / SUM(volume) AS mkt_share
FROM
(
SELECT
EXTRACT(
year
FROM
o_orderdate
) AS o_year,
l_extendedprice * (1 - l_discount) AS volume,
n2.n_name AS nation
FROM
lineitem,
orders,
part,
supplier,
customer,
nation n1,
nation n2,
region
WHERE
p_partkey = l_partkey
AND s_suppkey = l_suppkey
AND l_orderkey = o_orderkey
AND o_custkey = c_custkey
AND c_nationkey = n1.n_nationkey
AND n1.n_regionkey = r_regionkey
AND r_name = 'AMERICA'
AND s_nationkey = n2.n_nationkey
AND o_orderdate BETWEEN DATE '1995-01-01'
AND DATE '1996-12-31'
AND p_type = 'ECONOMY ANODIZED STEEL'
) AS all_nations
GROUP By
o_year
ORDER BY
o_year;未開啟列存索引優(yōu)化功能的查詢計劃如下:
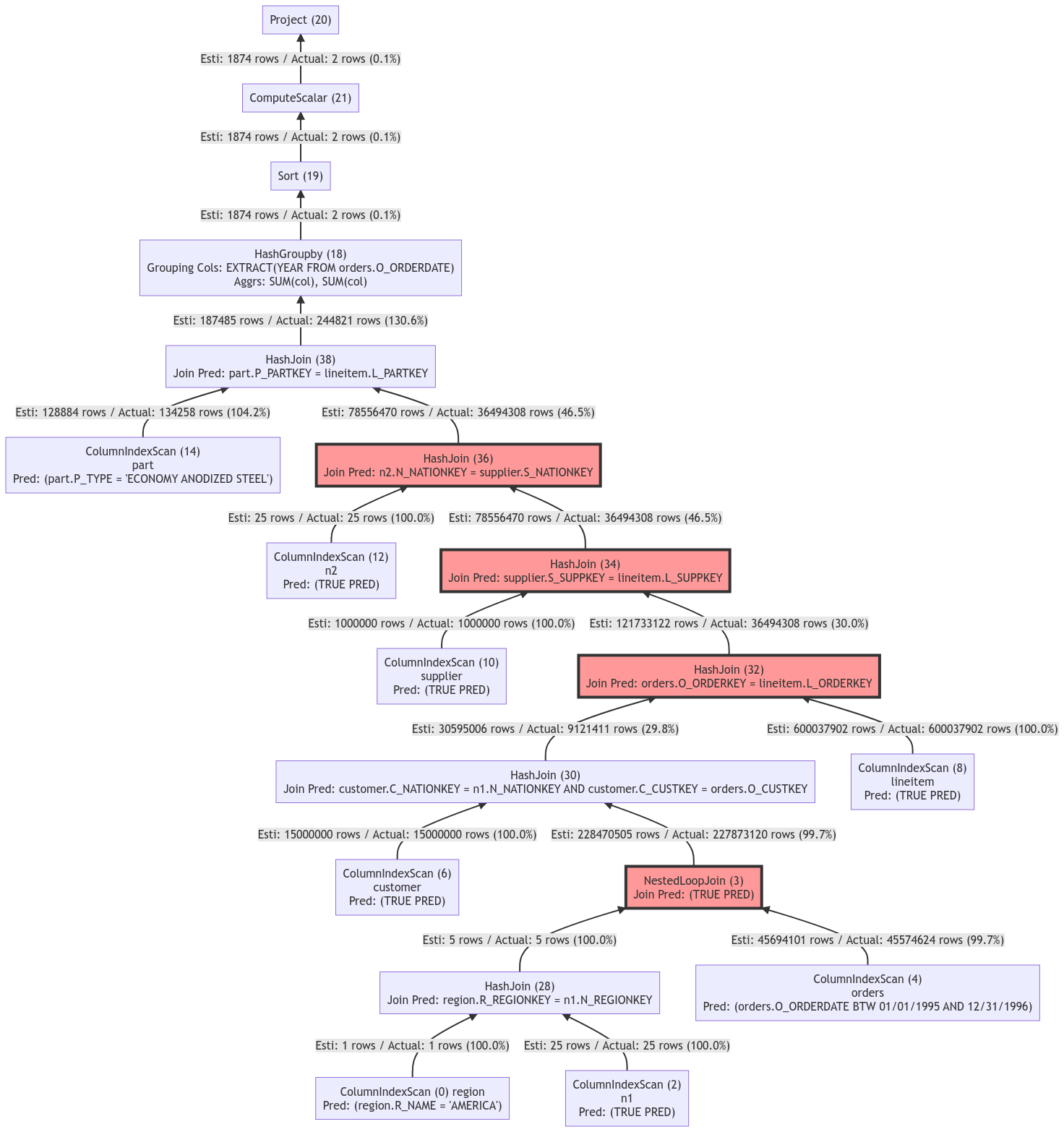 該查詢計劃中大量的join查詢生成了較大的結(jié)果集,導(dǎo)致后續(xù)由操作符處理的數(shù)據(jù)與處理成本隨之增加,查詢時延延長。該查詢計劃在TPCH SF100規(guī)模的數(shù)據(jù)下,使用32C機器進行測試,該語句的查詢耗時為7017ms。
該查詢計劃中大量的join查詢生成了較大的結(jié)果集,導(dǎo)致后續(xù)由操作符處理的數(shù)據(jù)與處理成本隨之增加,查詢時延延長。該查詢計劃在TPCH SF100規(guī)模的數(shù)據(jù)下,使用32C機器進行測試,該語句的查詢耗時為7017ms。開啟列存索引優(yōu)化功能的查詢計劃如下:
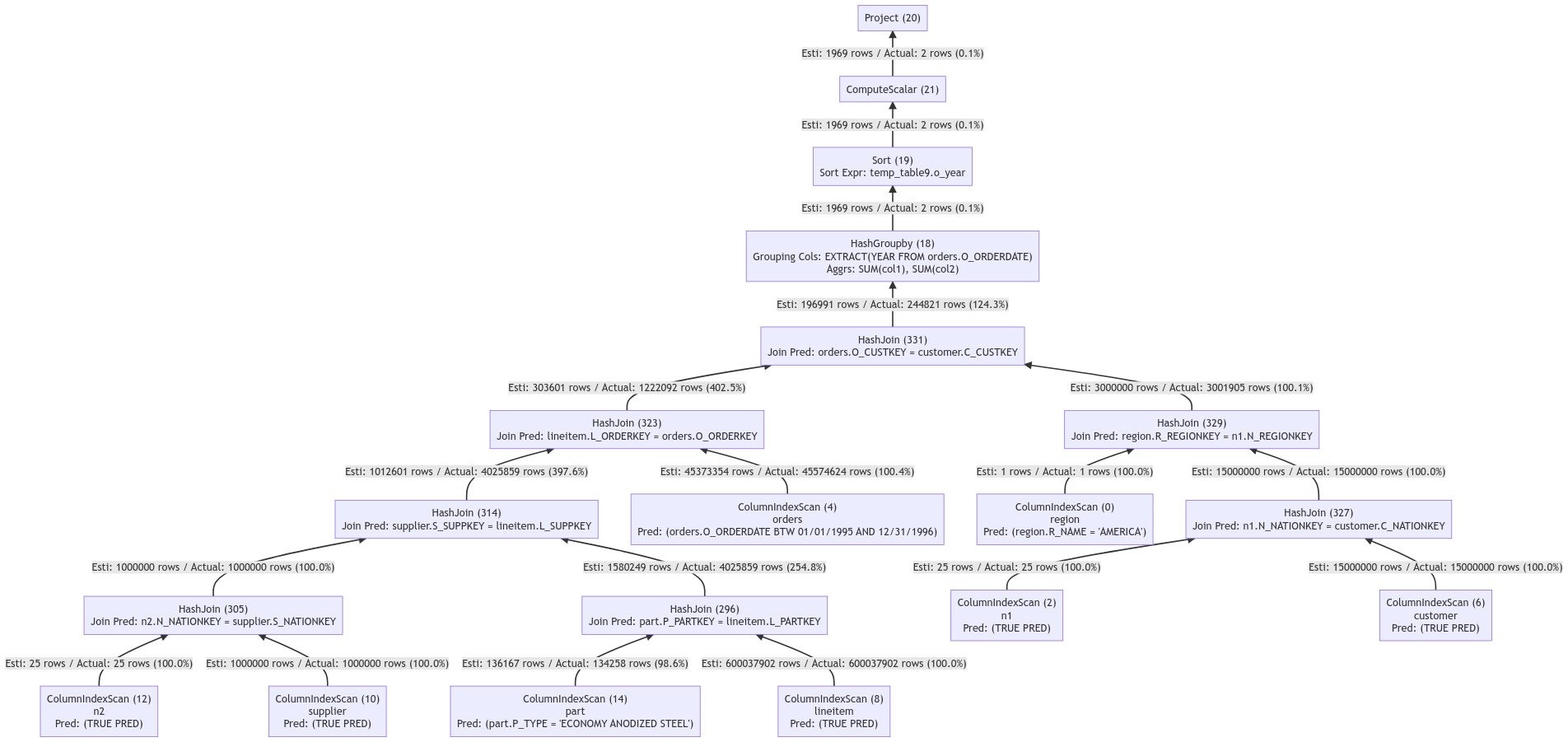 列存索引優(yōu)化器通過對join查詢進行重排序,使得幾乎所有join操作符的輸出結(jié)果數(shù)據(jù)量降到百萬級別,有效地減少了后續(xù)各個操作符的處理成本。該查詢計劃在TPCH SF100規(guī)模的數(shù)據(jù)下,使用32C機器進行測試,該語句的查詢耗時為1900ms。較未開啟查詢優(yōu)化功能的查詢耗時縮短了73%。
列存索引優(yōu)化器通過對join查詢進行重排序,使得幾乎所有join操作符的輸出結(jié)果數(shù)據(jù)量降到百萬級別,有效地減少了后續(xù)各個操作符的處理成本。該查詢計劃在TPCH SF100規(guī)模的數(shù)據(jù)下,使用32C機器進行測試,該語句的查詢耗時為1900ms。較未開啟查詢優(yōu)化功能的查詢耗時縮短了73%。